【Python】制作LMDB数据集文件(文件统一命名-数据增强-获取train.txt和test.txt)LMDB文件时会出现killed问题
学习点:制作LMDB数据集需要分类好的原始图像文件夹、对应的txt文件、还可能有mean均值文件,所以写了一个脚本文件生成LMDB数据集需要的train.txt和val.txt文件,并针对小样本进行了数据增强,平移旋转亮度等操作。1、原始数据源根据上图可知,我们需要将每个类的名称改称从0开始的,所以先保存类列表到word.txt中,根据.重命名类...
学习点:
制作LMDB数据集需要分类好的原始图像文件夹、对应的txt文件、还可能有mean均值文件,所以写了一个脚本文件生成LMDB数据集需要的train.txt和val.txt文件,并针对小样本进行了数据增强,平移旋转亮度等操作。
1、原始数据源
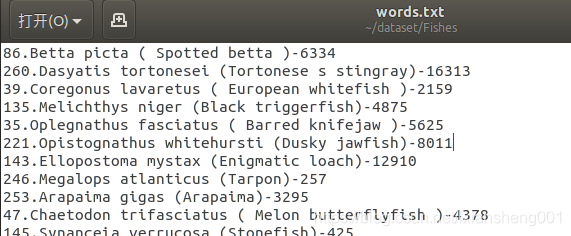
根据上图可知,我们需要将每个类的名称改称从0开始的,所以先保存类列表到word.txt中,根据.重命名类名称,修改后的文件类表如右图所示:对应的这部分代码为:
#将每个分类的名称写入word.txt 86.Betta picta ( Spotted betta )-6334,并以开头数字作为文件夹的新名称
def save_and_rename_file():
with open('./words.txt', 'w') as f:
#os.walk()根据你要遍历的总目录地址,返回:root 文件夹的本身地址;dirs:该文件夹内所有目录的名字-list
#files:该文件夹中所有的文件(不包括子目录)
for root, dirs, files in os.walk(data_dir):
for dir in dirs:
print(dir)
f.write(dir + "\n")
new_name = str(int(dir.split('.')[0]))
os.rename(os.path.join(data_dir, dir), os.path.join(data_dir, new_name))保存的word.txt内容为:
2、形成train.txt和al.txt文件
2.1 首先获得总目录下的所有文件,并写入到all_image.txt文件夹中,代码如下
#创建对应的数据集txt文档
def create_dataset(txt_file):
dirs = os.listdir(data_dir)
with open(txt_file, 'w') as f:
for dir in dirs:
#caffe标签从0开始,否则会出现错误
label = int(dir) - 1
#遍历子文件夹内容
for file in os.listdir(os.path.join(data_dir, dir)):
# check image format;取文件的属性一届
prefix = file.split('.')[-1]
#如果不是图像则进入下次判断
if prefix not in ['jpg', 'JPG', 'png', 'PNG']:
continue
# check is valid image
file_path = os.path.join(data_dir, dir, file)
if not is_valid_image(file_path):
continue
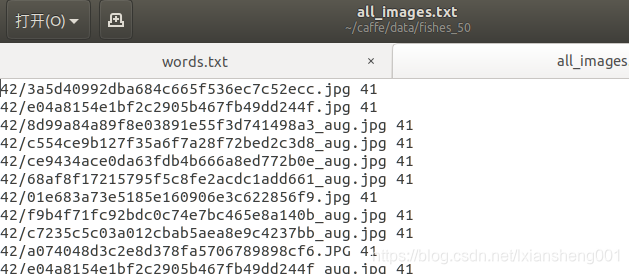
#打标签 42/3a5d40992dba684c665f536ec7c52ecc.jpg 41
f.write(dir+'/'+file + " " + str(label) + "\n")这样即形成了初始的txt文件,内容如下
2.2 数据增强
由于我们的样本比较少,这里我们对数据集进行了数据增强(旋转,亮度)代码如下,效果如下
#扩增数据集
def do_img_aument(txt_file):
images = list()
paths = list()
count = 0
with open(txt_file, 'r') as f:
for line in f:
file = line.split(" ")[0]
path = os.path.join(data_dir, file)
paths.append(path)
img = cv.imread(path)
images.append(img)
count = count + 1
#随机增强,每过20就对累计图像作一次扩增,相当于线程池
if count % 20 == 0:
print("do image augment")
new_images = img_aug(images)
for j in range(len(new_images)):
new_img = new_images[j]
new_path = paths[j].split(".")[0] + "_aug.jpg"
print(new_path)
cv.imwrite(new_path, new_img)
#清空池
images = []
paths = []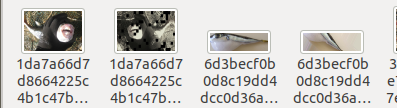
2.3 形成train.txt和val.txt文件
注意:这里需要将数据集打乱才能得到比较好的结果,我数据集和验证集的比例为[8:2],代码如下
#根据得到总的数据集,从中分离出一部分作为验证集[8:2]
def split_trainval(txt_file):
data_set = list()
with open(txt_file, 'r') as f:
for line in f:
data_set.append(line)
#打乱顺序
random.shuffle(data_set)
#得到总的大小
size = len(data_set)
train_size = int(size * 0.8)
train_set = data_set[0:train_size]
valid_set = data_set[train_size:]
# 将结果分别存入对应的训练集和测试集
with open('./train.txt', 'w') as f:
for data in train_set:
f.write(data)
with open('./val.txt', 'w') as f:
for data in valid_set:
f.write(data)效果如图所示:
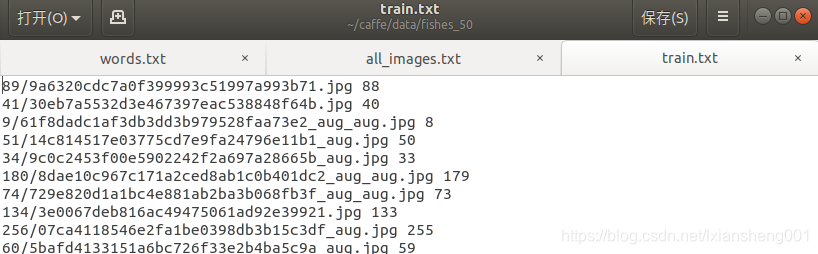
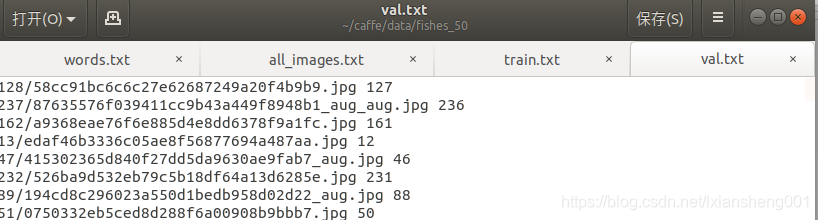
2.4label映射
根据第一部获取的word.txt,我们将label和Class进行映射,这样最后会方便我的寻找【0,1,2】表示的是什么类别,代码如下
#打标签 [0,1,2,3]-[XXX的种类]
def make_labels():
labels = list()
with open("./words.txt", 'r') as f:
for line in f:
class_numb = int(line.split('.')[0]) - 1
class_name = line.split('.')[-1].split(" ")[0]
labels.append(str(class_numb) + " " + class_name)
with open("./labels.txt", 'w') as f:
for label in labels:
f.write(label + "\n")3、制作均值文件
执行一段代码caffe代码就可以,比较简单,
#!/usr/bin/env sh
# Compute the mean image from the imagenet training lmdb
# N.B. this is available in data/ilsvrc12
EXAMPLE=examples/fishes
DATA=data/fishes
TOOLS=build/tools
$TOOLS/compute_image_mean $EXAMPLE/train_lmdb \
$DATA/imagenet_mean.binaryproto
echo "Done."
4、制作LMDB 文件
基本条件满足后,就开始制作LMDB文件了,制作也是比较简单,网上都有,这里简单说一下过程:
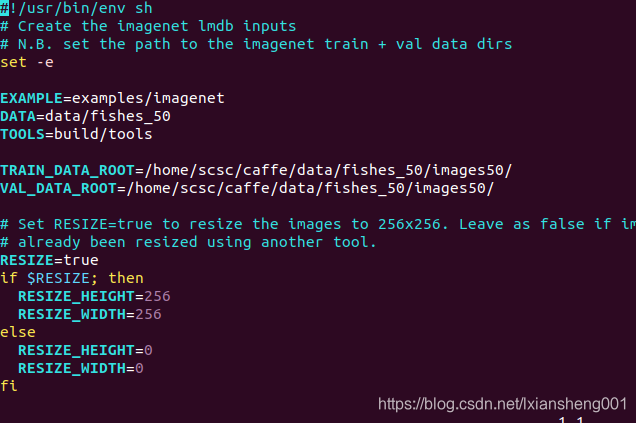
1、执行caffe-example文件下的create_imagenet.sh文件(创建均值文件是第二个)
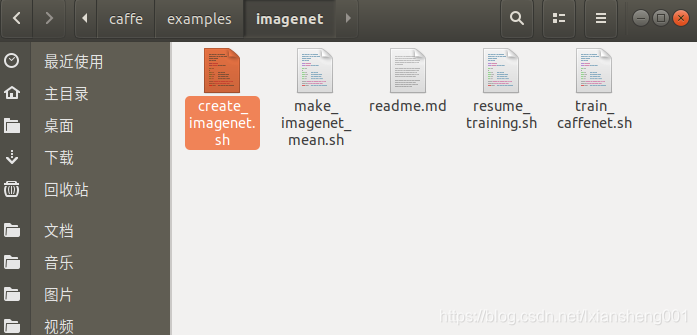
2、执行后就可以看到效果了。这里在说一下文件里面的内容
代码中resize一般要设置为Resize=true;不然制作LMDB文件时会出现killed,这并不是CNN要求,主要是最后连接层的原因,后面的图像就可以置为false。具体可以网上搜索一下:resize为什么需要设置为true?剩下的就是路径的问题了。我们可以用心去看看EXAMPLE-DATA-TOOLS对应的什么?其中tools比较好理解就是caffe的工具;data主要是你训练集的总目录和下面的TRAIN_DATA_ROOT /VAL_DATA_ROOT相关(可以从目录中看出存在父子关系);EXAMPLE就和LMDB文件的存放相关了。
原始的数据源名称是比较乱的,但是caffe分类需要从0开始,不然会报错,

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)