如何创建用于对象检测的自定义COCO数据集
文章目录1 简介2 Pascal VOC和COCOs annotations 的区别3 将 Pascal VOC 转换为 COCO annotation4 VGG Image Annotator to COCO annotation5 coco数据可视化6 结论和进一步阅读1 简介以前,我们使用Pascal VOC数据格式使用自定义带annotated(注释)的数据集训练了mmdetection模
文章目录
1 简介
以前,我们使用Pascal VOC数据格式使用自定义带annotated(注释)的数据集训练了mmdetection模型。如果您的对象检测的训练需要COCO数据格式,那么您很不走运,因为我们使用的labelImg工具不支持COCO注释格式。如果您仍然想使用注释工具,以后再将VOC注释转换为COCO格式。
我们将首先简要介绍这两种注释格式,然后介绍将VOC转换为COCO格式的转换脚本,最后,我们将通过绘制边界框和类标签来验证转换后的结果。
2 Pascal VOC和COCOs annotations 的区别
Pascal VOC批注保存为XML文件,每个图像一个XML文件。由labelImg工具生成的XML文件 。它在<path>元素中包含图像的路径。每个边界框都存储在<object>元素中,示例如下所示。
<object>
<name>fig</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>256</xmin>
<ymin>27</ymin>
<xmax>381</xmax>
<ymax>192</ymax>
</bndbox>
</object>
如您所见,边界框由两个点定义,即左上角和右下角。
对于COCO数据格式,首先,对于数据集中的所有注释只有一个JSON文件,对于数据集的每个拆分(Train/Val/Test)都只有一个JSON文件。
边界框表示为左上起始坐标以及框的宽度和高度,例如
"bbox" :[x,y,width,height]
这是一个COCO数据格式JSON文件的示例,该文件仅包含一个图像(在顶级"images"元素中可见),总共3个唯一的类别/类(在顶级"categories"元素中可见)和2个带注释的边框在顶级"annotations"(“注释”)元素中看到的图像。
{
"type": "instances",
"images": [
{
"file_name": "0.jpg",
"height": 600,
"width": 800,
"id": 0
}
],
"categories": [
{
"supercategory": "none",
"name": "date",
"id": 0
},
{
"supercategory": "none",
"name": "hazelnut",
"id": 2
},
{
"supercategory": "none",
"name": "fig",
"id": 1
}
],
"annotations": [
{
"id": 1,
"bbox": [
100,
116,
140,
170
],
"image_id": 0,
"segmentation": [],
"ignore": 0,
"area": 23800,
"iscrowd": 0,
"category_id": 0
},
{
"id": 2,
"bbox": [
321,
320,
142,
102
],
"image_id": 0,
"segmentation": [],
"ignore": 0,
"area": 14484,
"iscrowd": 0,
"category_id": 0
}
]
}
3 将 Pascal VOC 转换为 COCO annotation
获得带注释的XML和图像文件后,将它们放入以下与下面类似的文件夹结构中,
rawdata
└── 20210131181727
├── Annotations
│ ├── 1.xml
│ ├── ...
│ └── 20.xml
└── JPEGImages
├── 1.jpg
├── ...
└── 20.jpg
然后,您可以像这样从我的GitHub运行voc2coco.py脚本,它将为您生成COCO数据格式的JSON文件。
$vocFolderName = 20210131181727
$cocoFolderName = format(datetime.now(), "%Y%m%d%H%M%S")
python voc2coco.py ./rawdata/voc/$FolderName/Annotations ./convertedData/coco/$FolderName/annotations/instances_train$FolderName.json
COCO目录如下,其中你要手动将
./rawdata/20210131181727/JPEGImages 目录下所有*.jpg文件拷贝到
./convertedData/20210131224630/images
convertedData
└── 20210131224630
├── annotations
│ ├── instances_train20210131224630.json
│
│
└── images
├── 1.jpg
├── ...
└── 20.jpg
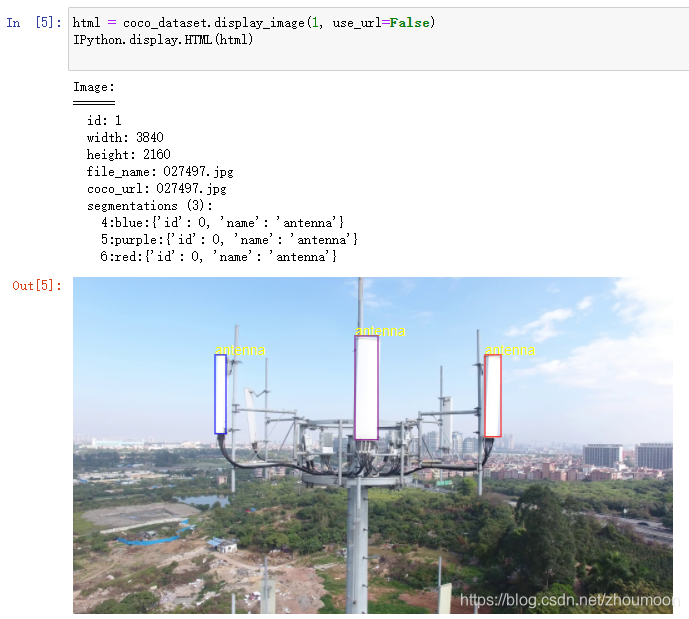
有了JSON文件后,我们可以通过将边界框和类标签绘制为图像的叠加层来可视化COCO注释。在Jupyter Notebook打开COCO_Image_Viewer.ipynb。在COCO_Image_Viewer.ipynb中找到以下单元格,该单元格在display_image生成SVG图形的方法。
html = coco_dataset.display_image(0, use_url=False)
IPython.display.HTML(html)
第一个参数是图像ID,对于我们的演示数据集,总共有20张图像,因此您可以尝试将其设置为1到20。
4 VGG Image Annotator to COCO annotation
如果你的VOC数据集是使用VGG Image Annotator标注的话,就需要另外写新脚本将VGG Image Annotator 转换成 COCO annotation。
如果你想节省时间,可以在线使用VGG-Image-Annotator转换成符合coco格式的json文件,有可能会成功。
如果以上方法都无法解决你的问题,请尝试使用vgg2coco.py
5 coco数据可视化
6 结论和进一步阅读
COCO数据格式
Pascal VOC文档
下载 labelImg 作为边界框注释。
下载 labelme作为边界框注释。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)