通过puppet hiera配置bigtop大数据集群
Puppet Hiera是一个puppet内置的键值对配置以及数据查询系统,通过hiera可以配置puppet main manifect的参数。率先理解了上面这个概念,我们就能理解bigtop原生的部署代码在部署bigtop大数据组件的时候发生了什么。若需要覆盖一些配置的话,可以在site.yaml中直接覆盖,因为在hiera.yaml之中,site的解析优先级在cluster之前。/目录之下的
Puppet Hiera是一个puppet内置的键值对配置以及数据查询系统,通过hiera可以配置puppet main manifect的参数。率先理解了上面这个概念,我们就能理解bigtop原生的部署代码在部署bigtop大数据组件的时候发生了什么。
我们进入apache bigtop的代码仓,点进去bigtop-deploy/puppet目录,就可以看到如下layout的代码:

hiera.yaml这个配置文件指定hiera data的路径,并且决定配置文件的读取顺序以及配置文件的路径,hieradata目录里面存放的是hiera 的配置文件,点进去hieradata目录,我们可以看一下它的模板配置文件:
---
### This is very important to make sure this file doesn't contain any TAB
### symbols instead of spaces: the hiera YAML parser will choke to death with
### uncomprehensive error message and you'll waste a lot of time debugging it.
# 总控制bigtop hadoop集群的头节点
bigtop::hadoop_head_node: "head.node.fqdn"
# 指定bigtop hadoop hdfs ha模式的standby namenode
#bigtop::standby_head_node: "standby.head.node.fqdn"
# hadoop的配置
hadoop::hadoop_storage_dirs:
- /data/1
- /data/2
- /data/3
- /data/4
# 部署的集群节点,注意这是components模式的,可以开启role模式
#hadoop_cluster_node::cluster_components:
# - alluxio
# - ambari
# - flink
# - gpdb
# - hbase
# - hcat
# - hive
# - httpfs
# - mapred-app
# - oozie
# - solrcloud
# - spark
# - spark-standalone
# - tez
# - yarn
# - ycsb
# - zookeeper
#bigtop::roles_enabled: false
# 若开启role模式,那么其配置将会如下所示
bigtop::roles:
- namenode
- resourcemanager
- secondarynamenode
- journalnode
## You can specify one (or more) repositories. It is convenient if
## you provide hotfix repo separately from the stable release, etc.
#bigtop::bigtop_repo_uri:
# - "http://mirror1.example.com/path/to/mirror/"
# - "http://mirror2.example.com/path/to/mirror/"通用的hadoop集群配置在hieradata/bigtop目录之下的cluster.yaml之中
若需要覆盖一些配置的话,可以在site.yaml中直接覆盖,因为在hiera.yaml之中,site的解析优先级在cluster之前
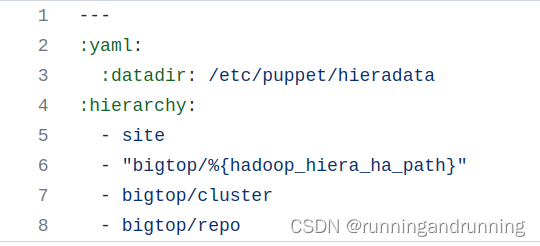
按照我们的所需配置完成之后,就可以运行测试并且部署了
部署的主要命令是:
puppet apply -d --parser future --modulepath="bigtop-deploy/puppet/modules:/etc/puppet/modules" bigtop-deploy/puppet/manifests以上就是hiera配置bigtop大数据集群部署的所关注的最重要的几个关键点。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)