
PlantNet-300K:具有高标签模糊度和长尾分布的植物图像数据集
对于每个物种,80%的图像被放置在训练集中(ntrain = 243,916),10%的图像被放置在验证集中(nval = 31,118),10%的图像被放置在测试集中(ntest = 31,112),每个集合中的每个物种至少有一个图像。我们强调了数据集的两个特殊特征,这是图像获取方式和植物形态内在多样性所固有的:(I)数据集具有很强的类别不平衡性,即少数物种占图像的大部分,以及(ii)许多物种在
Pl@ntNet-300K:具有高标签模糊度和长尾分布的植物图像数据集
这篇论文的核心创新点是提出了一个新的植物图像数据集,名为Pl@ntNet-300K。这个数据集具有以下几个特点:
-
高内在歧义性(High Intrinsic Ambiguity):数据集中的植物图像在视觉上具有很高的相似性,即使是专家也很难仅凭肉眼进行准确识别,这增加了分类任务的难度。
-
长尾分布(Long-tailed Distribution):数据集中的类别呈现长尾分布,即少数物种的图像数量占据了大部分,而许多物种的图像数量很少,这导致了类别之间的不平衡。
-
大规模和多样性:Pl@ntNet-300K包含306,146张植物图像,涵盖了1,081个物种,这为评估集合值分类方法和算法提供了丰富的样本。
-
数据集构建方法:作者通过从Pl@ntNet数据库中随机选择部分属(genera),并保留这些属中的所有物种来构建数据集,这种方法保留了原始数据库中固有的歧义性。
-
评估指标:论文推荐了两种与数据集相关的集合值评估指标:宏观平均top-k准确率(macro-average top-k accuracy)和宏观平均average-k准确率(macro-average average-k accuracy),这些指标更适合评估集合值分类器的性能。
-
基线结果:作者提供了使用交叉熵损失训练的深度神经网络的基线结果,这为后续研究提供了一个起点。
-
实际应用背景:Pl@ntNet-300K数据集是从Pl@ntNet项目中收集的现实世界图像中提取的,该项目是一个大规模的公民科学观测项目,致力于通过基于图像的植物识别收集植物发生数据。
-
数据验证和清洗:论文描述了一种基于加权多数投票算法的标签验证方法,以及数据清洗流程,包括自动化过滤不适当或不相关内容以及基于用户评估的图像质量过滤。
这些特点使得Pl@ntNet-300K数据集非常适合评估集合值分类方法,并且可以作为研究长尾分类和细粒度视觉分类(Fine-Grained Visual Categorization, FGVC)的新基准。
高标签模糊性是什么意思

高标签模糊性(High Label Ambiguity)指的是在数据集中,某些类别(或物种)在视觉上非常相似,以至于很难仅通过观察图像来区分它们。这种模糊性可能源于多种因素,包括但不限于:
-
进化相似性:一些物种可能在进化过程中有共同的祖先,因此在形态上具有相似的特征,如相似的花朵或叶子形状。
-
生长条件:植物在不同的生长条件下可能表现出不同的外观,例如季节变化可能导致植物在开花时间的外观与其他时间不同。
-
观察角度和部分:用户可能只拍摄到植物的某一部分,如仅拍摄花朵或叶片,这可能导致难以区分属于不同物种但部分相似的植物。
-
图像质量:图像的质量也会影响标签的确定性。例如,模糊、过曝或欠曝的图片可能难以进行准确的分类。
-
物种内部变异:即使是同一物种,其个体之间也可能存在显著的变异,如花朵的颜色变化,增加了分类的难度。
在Pl@ntNet-300K数据集中,高标签模糊性是一个特意保留的特征,用以模拟现实世界中植物分类的复杂性。这种模糊性要求分类算法不仅要能够处理类别不平衡问题,还要能够处理由于视觉相似性带来的不确定性,这对于评估和开发鲁棒的分类模型具有重要意义。
复制再试一次分享
摘要
本文提出了一种新的图像数据集,它具有很高的固有模糊度和长尾分布,是从Pl@ntNet公民天文台的数据库中构建的。它由306,146幅植物图像组成,涵盖1,081个物种。我们强调了数据集的两个特殊特征,这是图像获取方式和植物形态内在多样性所固有的:
(I)数据集具有很强的类别不平衡性,即少数物种占图像的大部分,以及
(ii)许多物种在视觉上是相似的,即使对于专家的眼睛也很难识别。这两个特征使得当前数据集非常适合于集值分类方法和算法的评估。因此,我们推荐与数据集相关联的两个集值评估度量(宏平均top-k准确性和宏平均average-k准确性),并且我们提供通过使用交叉熵损失训练深度神经网络而建立的基线结果。
当对图像进行分类时,我们面临两种主要的不确定性[Der Kiureghian andDitlevsen,2009]: (i)由底层过程的内在随机性产生的随机不确定性,这种不确定性被认为是不可约的,以及(ii)由知识的缺乏引起的认知不确定性,这种认知不确定性被认为可以通过额外的训练数据来减少。在现代现实应用中,这两种类型的不确定性尤其难以处理。不断增长的要区分的类的数量往往会增加类的重叠(从而增加任意的不确定性),另一方面,长尾分布使得难以学习人口较少的类(从而增加认知的不确定性)。这两种不确定性的存在是使用集值分类器的主要动机,即分类器返回一组每个图像的候选类别[Chzhen et al.,2021].尽管文献中有几个数据集具有视觉上相似的类[Nilsback and Zisserman,2008,Maji et al.,2013,Yanget al.,2015,Russakovsky et al.,2015],它们中的大多数并不旨在保留现实世界数据中存在的认知模糊性和任意模糊性。
在本文中,我们提出了一个数据集,旨在保持现实生活中的模糊性的代表性,使其非常适合集值分类方法的评估。这个数据集是从作为Pl@ntNet项目的一部分收集的真实世界图像中提取的[Affouard et al.,2017],这是一个大型市民观测站,致力于通过基于图像的植物识别来收集植物出现数据。Pl@ntNet的关键功能是一个移动应用程序,它允许公民发送他们遇到的一种植物的照片,并作为回报获得该照片最可能的物种列表。该应用程序在大约170个国家有1000多万用户使用,是GBIF的主要数据发布者之一1,这是一个由世界上许多国家的政府资助的国际平台,提供免费和开放的生物多样性数据访问。Pl@ntNet的另一个重要特性是,用于训练分类器的训练集是协作丰富和修订的。如今,Pl@ntNet覆盖了超过35,000个物种,由近1,200万张经过验证的图像进行了说明。
整个Pl@ntNet数据库是评估集值分类方法的理想选择。然而,它太大了,不允许机器学习社区广泛使用。从其中提取子样本必须小心谨慎,因为我们希望保留整个数据库中自然存在的不确定性。本文中给出的数据集是通过仅保留整个Pl@ntNet数据库(随机均匀采样)的属的子集来构建的。属于所选属的所有物种都被保留下来。这样做保持了原始的模糊性,因为同一属中的物种很可能在视觉上相似,并具有共同的视觉特征。
本文的其余部分组织如下。我们首先在中介绍集值分类框架Section 2,重点介绍两种特殊情况:top-k分类和average-k分类。在…里Section 3,我们描述了Pl@ntNet-300K数据集的构造过程,并表明它包含大量的歧义。接下来,我们介绍Section 4 数据集感兴趣的度量,并为这些度量提出基准结果,这些结果是通过训练几个神经网络体系结构获得的。在…里Section 5,我们将Pl@ntNet-300K与几个现有的数据集进行比较。在…里Section 6,我们讨论Pl@ntNet-300K的可能用途。最后,我们在中提供了数据集的链接Section 7 在结束之前。
- 集值分类我们采用经典的多类分类统计设置。设L是类的数量。我们用[L]表示集合1,.。。,L和由输入空格。假设图像和标签(X,Y ) [L]的随机对是由未知的联合分布p生成的。请注意,每个图像仅关联一个标签,这不同于多标签设置[Zhangand Zhou,2014]: P@ntNet-300K由包含一个植物的单个标本的图像组成,所以每个图像只有一个真正的标签。对于一些植物图像,预测正确的类别标签(正确的物种)并不存在太大的困难(例如,考虑一个与其他物种非常不同的普通物种)。然而,对于其他图像,以高置信度对拍摄的标本进行分类是一项非常困难的任务,因为一些物种仅在细微的视觉特征上有所不同(参见Figure 4).在这些情况下,希望向用户提供对应于图像的可能物种的列表。因此,我们需要一个能够产生类别集的分类器,在文献中也称为集值分类器[Chzhen et al.,2021].集值分类器γ是将特征空间映射到[L](我们用2[L]表示)的所有子集的集合的函数。使用这些符号,我们就有了γ: 2[L]代替γ: [L]对于预测器只能预测单个类的经典设置。我们的目标是建立一个低风险的分类器,定义为
p(Y∈/γ(X))。然而,简单地最小化风险是不可取的:集值分类器
总是返回所有类实现零风险,但没有用。另一方面,如果给定一个查询图像,分类器只返回最可能的类,那么它是最有用的。因此,给定图像x ∈ X,感兴趣的量将是|γ(x)|,即由分类器γ返回的类的数量。
一GBIF
在这一节中,我们将研究导致不同集值分类器的两个优化问题。这两种方法都旨在最小化风险,但是它们在约束集合基数的方式上有所不同:要么是逐点的,要么是平均的。
对于x ∈ X和l ∈ [L],我们定义条件概率pl(x) := P(Y = l | X = x),这些量的估计量将用pˇl(x)表示。在下面,k ∈ [L]。最后,对于x ∈ X,我们定义topp(x,k)为包含对应于{pl(x)}l∈[L].的k个最大值的k个指数的集合
最简单的约束是要求每个输入返回的类的数量少于k。这会导致以下top-k错误[Lapin et al.,2015]最小化问题:
|γ(x)|≤k,∀x ∈ X。
的封闭形式解(1)存在并且等于[Lapin et al.,2017]:
γ÷top-k(x)= topp(x,k)。 (2)

然而,这是不实际的,因为我们不知道分布P和pl(x)。但是,如果我们有pl(x)的一个估计量pˇl(x ),我们就可以很自然地导出插入式估计量:γtop-k = toppˇ(x,k)。虽然top-k精度经常在基准测试中报告,但只有少数工作旨在直接优化
此指标[Lapin et al.,2015,2016,2017,Berrada et al.,2018].top- k分类的一个明显的局限性是,不管对样本进行分类的难度如何,都会为每个数据样本返回k个类。平均k分类允许更多的适应性。在该设置中,对预测集大小的约束限制较少,并且必须平均满足,这导致:
ex|γ(x)|≤k。
封闭形式的解决方案是在[Denis and Hebiri,2017]:
γ∫平均值-k(x) = {l ∈ [L] : pl(x) ≥ G−1(k)} (4)
其中函数g被定义为:∀t ∈ [0,1], G(t)=σL P(pl(X)≥t),G1指
g的广义逆,即G1(u)= inf{t∈[0,1] : G(t) ≤ u}.
注意,如果我们用:X,γt(X)= L[L],pl(x) t定义分类器γt,那么G(t)就是γt返回的类的平均数:G(t)= EXγt(X)。来自(4)我们看到,最佳分类器对应于阈值操作:返回条件概率大于G1(k)的所有类,选择阈值使得平均返回k个类。为了计算对应的插件,我们只需要估计校准集的阈值,这样
在该集合上,平均返回k个类。关于技术细节,我们请读者参考Denis andHebiri [2017].
标签验证基于加权多数投票算法,将Pl@ntNet用户提出的标签作为输入,根据用户的专业知识和承诺采用自适应加权原则。因此,一个受信任的注释器就足以验证一个图像标签。另一方面,其标签由几个新手用户提出的图像可能不会被验证,因为它们没有足够的权重。这个算法的技术细节可以在补充材料中找到。在构建Pl@ntNet-300K时,Pl@ntNet数据库中的注释器总数等于2,079,003。每幅图像的平均注释者数量等于2.03。
除了标签验证程序之外,Pl@ntNet的管道还包括其他数据清理程序:(I)自动过滤不适当或不相关的内容(人脸、人、动物、建筑物等)。)使用CNN和用户报告,以及(ii)根据图像质量过滤(由用户评估)。
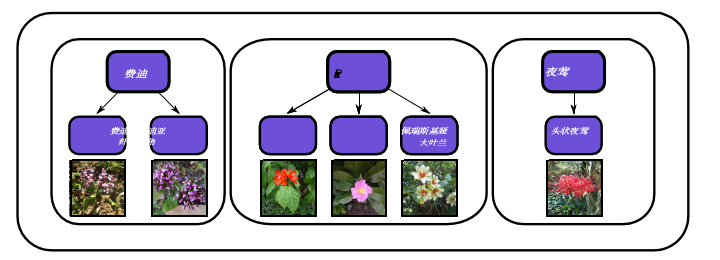
图1:属分类学:我们显示了建议的数据集中存在的三个属——Fedia,
Pereskia和nyctignia——分别包含两个、三个和一个物种。
-
- Pl@ntNet-300K的构建
在分类学中,物种被组织成属,每个属包含一个或多个物种,不同的属不重叠,如Figure 1。
我们选择保留随机选择的属,并保留属于这些属的所有物种,而不是保留从整个Pl@ntNet数据集中随机选择的物种或图像。这种选择旨在保留原始数据库中存在的大量模糊性,因为属于同一属的物种往往具有共同的视觉特征。本文给出的数据集是通过均匀随机抽样整个Pl@ntNet数据库的10%的属来构建的。
然后,我们只保留具有4个以上图像的物种,结果总共有303个属和L = 1,081个物种。图像被分成训练集、验证集和测试集。2对于每个物种,80%的图像被放置在训练集中(ntrain = 243,916),10%的图像被放置在验证集中(nval = 31,118),10%的图像被放置在测试集中(ntest = 31,112),每个集合中的每个物种至少有一个图像。更正式地说,给定一个包含nj幅图像的j类,nval,j = 0.1 nj,ntest,j= 0.1 njand ntrain,j= njnval,jntest,j .这表示总共有ntot= ntrain + nval + ntest = 306,146幅彩色图像。平均图像大小为(570,570,3),范围从(180,180,3)到(900,900,3)。数据集的构造保留了类不平衡。为了说明这一点,我们绘制了洛伦兹曲线[Gastwirth,1971]和Pl@ntNet-300K数据集的Figure 2。
-
- 认知(模型)不确定性
认知不确定性主要是指缺乏正确估计条件概率所需的数据。在Pl@ntNet中,用户在野外很容易观察到最常见的物种,因此这些物种占图像的很大一部分,而最稀有的物种较难找到,因此在数据库中出现的频率较低。在…里Figure 2,我们看到80%的物种(图像数量最少的物种)只占图像总数的11%。因此,对于这样的数据集来说,训练机器学习模型是具有挑战性的,因为对于许多类别来说,模型只有少量的图像来训练,这使得对这些物种的识别变得困难。
除了长尾分布问题,认知的不确定性也来自于物种内的高度变异性。植物可能会根据季节呈现不同的外观(例如,开花时间)。此外,应用程序的用户可以只拍摄植物的一部分(例如,树干而不是叶子)。作为最后一个例子,属于同一物种的花可以有不同的颜色。Figure 3 显示了这些现象的一些例子,这些现象导致了较高的类内变异性,使物种建模更具挑战性。
直立盾壳藻
玫瑰茄
小木麻黄
白小苍兰
图3:属于同一类的视觉上不同的图像的例子。
-
- 任意(数据)不确定性
在我们的例子中,随机不确定性的来源主要存在于我们在做决定时所得到的有限信息中(给一株植物贴上标签)。有些物种,尤其是属于同一属的物种,在视觉上可能非常相似。例如,考虑两个物种产生相同的花但不同的叶的情况,通常是因为它们从相同的亲本物种进化出不同的进化。如果一个人只拍摄两个物种之一的标本的花,那么即使是专家也不可能知道这花属于哪个物种。图像中不存在区别信息。
这种不可减少的模糊性与非最佳质量的图像(未适应的特写镜头、弱光条件等)的组合。)导致成对的图像属于不同的种类,但是很难或者甚至不可能区分,参见Figure 4 为了说明。在这个图中,我们显示了物种对之间的模糊性,但是我们可以找到涉及大量物种的类似例子。因此,即使是专业的植物学家也可能无法确定地给这些图片贴上标签。这由pl(x)体现:给定一个图像,多个类是可能的。





晚香蓟
角叶藻
四角形芋螺
蒜头腺柱
黄花景天
图4:属于两个不同类别的视觉上相似的图像的例子。


我们考虑两个主要的度量来评估Pl@ntNet-300K上的集值预测器:top- kaccuracy和average-kaccuracy。设SDE记下一组n(输入,标签)对:S = (x1,y1),(x2,y2),。。。,(xn,yn)。最高k精度[Lapin et al.,2016]是基准测试中广泛使用的度量标准。平均k精度是一个不太常见的指标,它来源于平均k分类[Denis and Hebiri,2017]:

平均k精度(秒)=1
n
(Xiσ,yi)∈S
[yi∈γ^average-k(Xi)]
第一册

n
(Xiσ,yi)∈S
|γ^average-k(xi)|≤k, (5)

其中γaverage-k是使用训练数据构建的集值分类器。
对于Pl@ntNet-300K,top-k精度和average-k精度主要反映了集值分类器在代表大部分图像的少数类上的性能。如果我们希望捕获集值分类器返回所有类的相关物种集的能力,我们将检查宏观平均top-k精度和宏平均average-k精度,这简单地包括分别计算每个类的top-k精度和average-k精度,然后计算所有类的平均值。对于宏平均的平均k精度,对集合平均大小的约束必须适用于整个集合。

要派生这两个分类器,可以首先获得条件概率pˇl(x)的估计值,然后派生插件分类器,如Section 2。我们希望Pl@ntNet- 300K数据集鼓励以新的方式导出集值分类器γtop-k和γaverage-k
分别优化top-k精度和mean-k精度。注意,一些作品已经提出了优化top-k精度的方法[Lapin et al.,2015,2016,2017,Berrada
本节提供插件分类器的基线评估。我们用交叉熵损失训练几个深度神经网络:ResNets [He et al.,2016],DenseNets,[Huang et al.,2017],InceptionResNet-v2 [Szegedy et al.,2017],MobileNetV2 [Sandler et al.,2018],MobileNetV3 [Howard et al.,2019],效率网[Tan and Le,2019],宽ResNetsZagoruyko and Ko-modakis,2016],AlexNet [Krizhevsky et al.,2012],Inception-v3 [Szegedy et al.,2016],Inception- v4 [Szegedy et al.,2017],ShuffleNet [Zhang et al.,2018],SqueezeNet [Iandola et al.,2016],VGG [Simonyan and Zisserman,2015]和视觉转换器[Dosovitskiy et al.,2021].
2021].
所有模型都在ImageNet上进行了预训练。在训练期间,图像被调整为256,并且提取大小为224 × 224的随机裁剪。在测试期间,我们选择居中的作物。
这些模型使用动量为0.9的SGD和内斯特罗夫加速度进行优化[Ruder,2016].我们对所有型号使用32的批量,重量衰减为1.104。用于每个模型的时期数、初始学习率和学习率计划可在中找到
补充材料。对于插件分类器γaverage-k,plug-in,我们计算验证集上的阈值λval,并使用相同的阈值来计算测试集上的average-k准确度。
4.3 Pl@ntNet-300K的难度
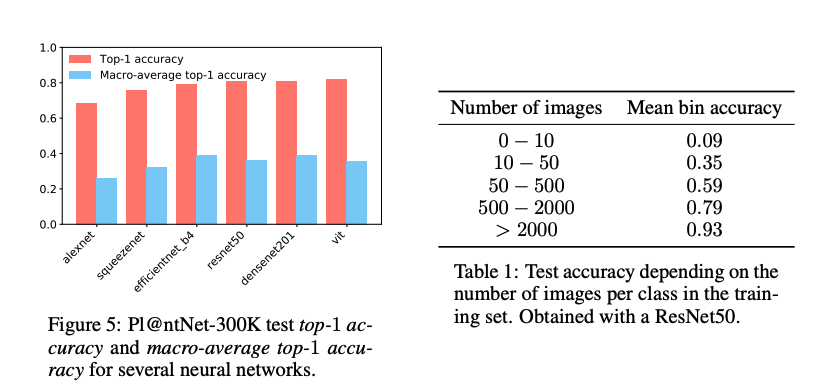
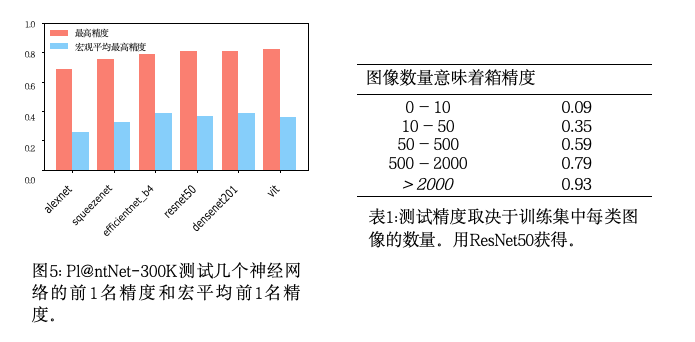
Figure 5突出了Pl@ntNet-300K top-1精度与宏观平均top-1精度之间的显著差距。这是长尾分布的结果:代表大多数图像的少数几个类很容易被识别,这导致高的top-1准确性。然而,这种看似高的top-1精度是误导性的,因为模型很难处理图像很少的类(图像占大多数,参见Figure 2).这种效果在中有所说明Table 1,这表明前1名的准确性强烈依赖于类中图像的数量。
Figure 8a显示了Pl@ntNet-300K宏平均top-1准确性和Im- ageNet宏平均top-1准确性之间的相关性(注意,由于ImageNet测试集是平衡的,top-1准确性和宏平均top-1准确性是一致的)。正如所料,这两个指标是正相关的:允许对复杂特性建模的深度网络在ImageNet和

Pl@ntNet-300K。有趣的是,由于两个数据集之间的差异(长尾分布,类别歧义,.。。),一些在ImageNet上表现相似的模型在Pl@ntNet-300K (inception v3,densenet201)上产生非常不同的结果,反之亦然。
在…里Figure 8a我们可以注意到,ImageNet宏观平均top-1精度和Pl@ntNet-300K宏观平均top-1精度在不同的尺度上有所不同:前者高达80%,而后者不超过40%,这使得Pl@ntNet-300K成为一个具有认知和随机不确定性的挑战性数据集。
这也可以在中看到Figure 6:对于ImageNet,一些模型达到了97%的宏观平均准确率,而对于Pl@ntNet-300K,该指标不超过80%,这表明可以通过适当的学习策略取得进展。
为了支持这一说法,我们请植物学家对从Pl@ntNet-300K测试集中提取的迷你数据集进行标记。数据集构建如下:我们从两组(猪屎豆属和羽扇豆属)中提取所有物种,并为每个物种选择最多5幅图像(随机采样)。这导致了83个图像。植物学家被要求为每张图片提供一组可能的物种。这导致返回的平均4,1个物种(范围从1到10)的误差率为20.5%。我们通过校准条件概率的阈值来比较植物学家与几个神经网络的性能,以在小型数据集上获得平均4,1个物种。结果报告在中Figure 7,并表明植物学家错误率和最佳表现模型之间的差距是

图6:几个模型的Pl@ntNet-300K与ImageNet宏观平均-5精度的比较(在测试集上评估)。
图7:与几个神经网络相比,专家的小型测试集的错误率。所有模型和专家在迷你测试集上平均重复4.1个物种。
大(从0.2到0.33),这表明平均k分类器的性能还有改进的空间。
4.4 top k与普通k
从等式(1)和(3),很明显贝叶斯平均k分类器比贝叶斯顶k分类器的风险更低。因此,精确估计条件概率的模型应该产生比top-k精度更好的平均k精度。这是可以在中观察到的Figure 8b其显示了宏平均前5名准确度和宏平均之间的相关性
平均-5精度。正如所料,这两个指标正相关。然而,这种关系
航运似乎不是微不足道的Figure 8b显示了具有相似宏平均前5位精度的模型具有非常不同的宏平均前5位精度,反之亦然。关于平均k分类和最高k分类的深入比较,我们请读者参考Lorieul[2020].这两种度量标准都有自己的利益,值得特别对待,因为它们捕获了两种不同的设置:top-k准确性评估系统地返回k个类的分类器的性能,而average-k准确性评估返回
可变大小(取决于输入),约束条件是平均返回k个类。
-
- 现有集值分类方法的评价
据我们所知,目前没有专门优化平均k精度的损失。对于top-k分类,为优化top-k精度而设计的最新损失是由Berrada et al.[2018].我们在补充材料中报告了通过在Pl@ntNet-300K上用k = 5训练这种损失而获得的前5名精度。结果与交叉熵损失得到的结果接近。然而,这个主题仍然是开放的研究,我们希望在发布Pl@ntNet-
300K正是为了鼓励优化这些指标的新方法。
细粒度视觉分类(FGVC)是关于区分视觉上相似的类。为了更好地学习细粒度的类,FGVC社区已经提出了几种方法,包括多阶段度量学习[Qian et al.,2015],高阶特征交互作用[Lin et al.,2015,Cui et al.,2017],以及不同的网络架构[Fu et al.,2017,Ge et al.,2016].然而,这些方法侧重于优化顶级精度。另一方面,集值分类包括返回多个类以降低错误率,并对返回的类的数量有限制。因此,FGVC和集值分类方法不是互斥的,而是互补的。
Pl@ntNet-300K宏观平均最高精度
- ImageNet宏观平均前1名精度与Pl@ntNet-300K宏观平均前1名精度(在测试集上评估)。
宏观平均前5名准确度
- Pl@ntNet-300K宏观平均平均-5精度与宏观平均前5精度(在测试集上评估)。
图8:几种流行的深度神经网络架构的基准3。
社区已经公开了几个FGVC数据集,它们展示了视觉上相似的类。它们涵盖多个领域:飞机[Maji et al.,2013],汽车(Compcars [Yang et al.,2015],人口普查车[Gebru et al.,2017])、鸟类(CUB200 [Welinder et al.,2010])、flow- ers(牛津花卉数据集[Nilsback and Zisserman,2008]).然而,这些数据集中的大部分只关注于提出视觉上相似的类(任意的不确定性),具有有限的认知不确定性。这是平衡数据集的情况,其每类具有大约相同数量的图像,或者具有小的类内可变性,例如飞机和汽车数据集,其中一个类内的大多数示例几乎相同,除了角度、闪电等。ImageNet [Russakovsky et al.,2015]有几个视觉上相似的类,组织成组:它包含许多鸟类和狗的品种。然而,这些类组是非常不同的:狗、车辆、电子设备等。此外,ImageNet没有表现出强烈的阶级不平衡。其中几个数据集是通过网络抓取构建的,这可能容易产生嘈杂的标签和低质量的图像。与我们的数据集最相似的是2017年的数据集[Horn et al.,2018].它包含了来自自然主义公民科学网站的图片。这些由博物学家发布的图片得到了多位公民科学家的验证。iNat2017数据集包含5000多个高度不平衡的类。然而,iNat2017不仅关注植物,还提出了其他几个“超类”,如真菌、爬行动物、昆虫纲等。此外,作者选择了观察数量大于20的所有类,而我们选择随机抽样整个Pl@ntNet数据库的10%的属,并保留属于这些观察数量大于4的组的所有物种。我们认为让所有的物种都属于同一个属最大化了随机不确定性,因为属于同一个属的物种倾向于共享视觉特征。最后,一个植物疾病数据集被介绍在[Sladojevic et al.,2016],包含4483张从网上下载的图片,分布在15个班级。这和Pl@ntNet-300K是非常不同的尺度。我们总结了中提到的数据集的属性Table 2。
尽管我们确信,由于需要区分的类越来越多,需要设计新的集值方法,但是在Section 3使其成为各种其他任务的理想候选。研究人员可以利用强烈的阶级不平衡来评估专门为解决阶级不平衡而设计的新算法[Zhou et al.,2020,Caoet al.,2019].Pl@ntNet-300K包含大量的随机不确定性,这是由许多视觉上相似的类造成的。因此,它可以用作FGVC数据集来评估旨在
3选择的架构有:alexnet (1)、densenet121 (2)、densenet161 (3)、densenet169 (4)、densenet201(22),squeezenet (23),vgg11 (24),vit base patch16 224 (25),wide resnet101 2 (26),wide resnet50 2 (27)。
表2:用Pl@ntNet-300K比较几个数据集。“聚焦域”指示数据集是否由单个类别(即,汽车)组成,而“模糊保持采样”指示在数据集的构造中,属于类层次结构中同一父类的所有类是否被保持(在我们的情况下,父类对应于属级别)。
|
人在回路标签 |
长尾分布 |
类内可变性 |
聚焦域 |
模糊保持采样 |
|
|
植物疾病数据集 |
七 |
七 |
七 |
3 |
七 |
|
CUB200 |
七 |
七 |
七 |
3 |
七 |
|
牛津花卉数据集 |
七 |
七 |
3 |
3 |
七 |
|
飞机数据集 |
3 |
七 |
七 |
3 |
七 |
|
康普卡斯 |
七 |
七 |
七 |
3 |
3 |
|
人口普查车 |
七 |
七 |
七 |
3 |
3 |
|
ImageNet |
七 |
七 |
3 |
七 |
七 |
|
2017年 |
3 |
3 |
3 |
七 |
七 |
|
Pl@ntNet-300K |
3 |
3 |
3 |
3 |
3 |
要优化此类数据集的前1名准确性,请参见例如[Lin et al.,2015,Fu et al.,2017,Cuiet al.,2017].最后,在本文中,我们不使用类信息,因此没有利用问题的层次结构。从这个意义上说,我们采用了[Silla and Freitas,2011].这与ImageNet一致[Russakovsky et al.,2015]
或CIFAR-100 [Krizhevsky,2009],其中确实存在层次结构,但很少在基准测试中使用。但是,研究人员可以在Pl@ntNet-300K上自由使用属信息来评估层次分类方法。
Pl@ntNet-300K数据集可在以下位置找到:
它被组织在名为“train”、“val”和“test”的三个文件夹中。每个文件夹包含L = 1,081个子文件夹。我们在文件“plant net 300k species id 2 name . JSON”中提供了子文件夹名和类名之间的对应关系。我们还提供了一个名为“plantnet300K metadata.json”的元数据文件,其中包含了每张图片的以下信息:物种标识符(类)、植物的器官(花、叶、树皮等)。。。),作者的
名称、许可和分割(即训练、验证或测试集)。github存储库包含重现本文实验的代码(其中也可以报告与数据集相关的潜在问题),可从以下网址获得:https://github.com/plantnet/PlantNet-300K/。
在本文中,我们分享和讨论了一个新的植物图像数据集,称为Pl@ntNet-300K,作为整个Pl@ntNet数据库的子集获得,主要用于评估集值分类方法。与以前的数据集不同,Pl@ntNet-300K旨在保持初始真实世界数据集及其长尾分布的类之间的高度模糊性。为了评估Pl@ntNet-300K上的集值预测器,我们研究了两种不同的度量:宏平均top-k准确性和宏平均average-k准确性,这是一项更具挑战性的任务,需要预测各种大小的集,但平均仍等于k。我们的结果表明,新的集值预测方法有提高平均k分类器性能的空间。我们希望Pl@ntNet-300K可以作为这个问题的参考数据集,这是我们发布并与社区共享它的主要动机。我们还强调Pl@ntNet- 300K也可以用来评估长尾分类和FGVC的新方法。
感谢
这项工作是由ANR卡米洛ANR-20-CHIA-0001-01部分资助。它获得了欧盟地平线2020研究和创新计划的资助,资助协议号为863463 (Cos4Cloud项目)。
参考
安托万·阿夫瓦德、埃尔韦·戈·奥、皮埃尔·博内、让-克里斯托夫·伦巴多和亚历克西斯·乔利。
深度学习时代的Pl@ntnet app。在ICLR-2017年车间赛道。
伦纳德·贝拉达、安德鲁·齐塞曼和帕万·库马尔。深度top-k分类的平滑损失函数。2018.
曹,魏科林,阿德里安·盖登,尼科斯·奇加和马腾宇。利用标签分布感知的边际损失学习不平衡数据集。《神经信息处理系统进展》,第1565-1576页,2019年。
Evgenii Chzhen、Christophe Denis、Mohamed Hebiri和Titouan Lorieul。集值分类–通过统一框架进行概述。arXiv预印本arXiv:2102.12318,2021。
尹翠、冯舟、王江、小刘、林元庆和Serge J. Belongie。卷积神经网络的核池。在CVPR,第3049–3058页,2017。
克利斯朵夫·丹尼斯和穆罕默德·赫比里。多类分类的具有期望大小的置信集。j .马赫。学习。决议,18:102:1–102:28,2017。
Armen Der Kiureghian和Ove Ditlevsen。偶然的还是认知的?有关系吗?结构安全,31(2):105–112,2009。
Alexey Dosovitskiy、Lucas Beyer、Alexander、Dirk Weissenborn、翟晓华、Thomas Unterthiner、Mostafa Dehghani、Matthias Minderer、Georg Heigold、Sylvain Gelly、Jakob Uszko- reit和Neil Houlsby。一幅图像相当于16x16个字:大规模图像识别的变形金刚。在ICLR。OpenReview.net,2021年。
傅、郑、。仔细看看得更清楚:用于细粒度图像识别的递归注意卷积神经网络。在CVPR,第4476–4484页,2017。
约瑟夫·加斯特维斯。洛伦兹曲线的一般定义。计量经济学:经济计量学会杂志,1037-1039页,1971年。
葛宗元、亚历克斯·比雷、克里斯托弗·麦克库尔、彼得·I·考克、本·乌普克罗夫特和康拉德·桑德森。基于混合深度卷积神经网络的细粒度分类。在CVPR,第1–6页,2016。
Timnit Gebru,Jonathan Krause,,Duyun Chen,Jia Deng和。用于视觉普查估计的细粒度汽车检测。《在AAAI》,2017年第31期。
何、、、任、。用于图像识别的深度残差学习。在CVPR,第770–778页,2016。
格兰特·范·霍恩、奥辛·麦克·奥德哈、宋洋、尹翠、孙辰、亚历山大·谢泼德、哈特维格·亚当、彼得罗·佩罗娜和塞尔日·贝隆吉。非自然物种分类和检测数据集。在CVPR,第8769–8778页,2018。
、庞若明、哈特维格·亚当、郭维乐、马克·桑德勒、、、陈良杰、谭明星、朱慧敏、维贾伊·瓦苏德万和朱玉坤。正在搜索mobilenetv3。在ICCV,第1314-1324页,2019。
黄高、刘庄、劳伦斯·范·德·马滕和基利安·q·温伯格。密集连接的卷积网络。在CVPR,第2261–2269页,2017。
Forrest N. Iandola,Matthew W. Moskewicz,Khalid Ashraf,Song Han,William J. Dally和Kurt Keutzer。Squeezenet: Alexnet级精度,参数少50倍,模型大小< 0.5MB。更正,abs/1602.07360,2016。
亚历克斯·克里日夫斯基。从微小图像中学习多层特征。多伦多大学硕士论文,2009年。
亚历克斯·克里热夫斯基、伊利亚·苏茨基弗和杰弗里·e·辛顿。基于深度卷积神经网络的图像网分类。《神经信息处理系统进展》,第1106-1114页,2012年。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)