
逻辑强化学习让7B模型推理能力暴增125%,仅需5K训练数据
随着训练的进行,模型开始表现出更复杂的行为,如反思和探索替代解决方案。这种跨域泛化能力表明,RL训练的推理启发式方法发展了抽象的问题解决模式,而不是依赖于特定领域的模式匹配。这背后的秘密是什么?,通过精心设计的强化学习框架,也能够发展出复杂的推理能力。更令人惊讶的是,这种能力可以跨域泛化,从逻辑谜题迁移到复杂的数学问题上。特别是DeepSeek-R1,它引入了一种简单而有效的基于规则的强化学习方法
逻辑强化学习让7B模型推理能力暴增125%,仅需5K训练数据
原创 无影寺 AI帝国 2025年03月03日 09:08 广东

你有没有好奇过,为什么有些AI模型能够像人类一样进行复杂的推理?为什么DeepSeek-R1这样的模型能在数学和逻辑问题上表现出色?这背后的秘密是什么?今天,我们来揭秘一项突破性研究——Logic-RL,它通过基于规则的强化学习,让一个仅有7B参数的模型在推理能力上实现质的飞跃。
1、问题与挑战:为什么推理能力难以提升?
大型语言模型(LLMs)的后训练阶段近年来取得了快速进展,DeepSeek-R1、Kimi-K1.5和OpenAI-o1等模型展示了惊人的推理能力。特别是DeepSeek-R1,它引入了一种简单而有效的基于规则的强化学习方法,无需依赖传统的蒙特卡洛树搜索或过程奖励模型等技术,就能产生出色的推理模式。
但研究界面临几个关键问题:
(1)这种推理能力能否在较小规模的模型中出现?
(2)什么样的训练数据结构最适合培养这种能力?
(有什么方法可以可靠地复制这些结果?
传统数学数据集的局限性在于问题复杂度变化大,可能跨越各种逻辑归纳深度,难以控制实验变量。Logic-RL研究团队另辟蹊径,利用程序生成的"骑士与恶棍"(Knights and Knaves)逻辑谜题数据集,这种数据集允许控制难度级别,并且易于通过规则进行奖励验证,是研究推理动态的理想选择。
2、创新方法:如何让模型学会像人类一样思考?
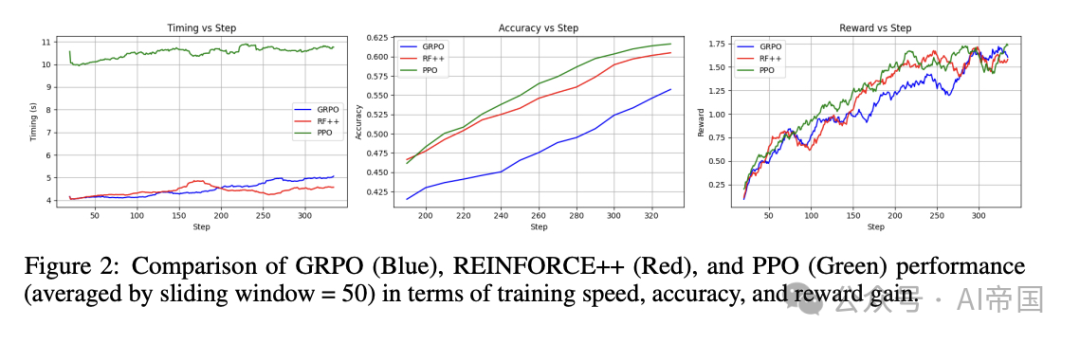
Logic-RL提出了一个基于规则的强化学习框架,通过逻辑谜题训练获得类似R1的推理模式。研究团队采用了REINFORCE++算法和DeepSeek-R1的奖励设计进行后训练,但简单的训练可能导致解决方案崩溃。为此,他们提出了三个关键技术贡献:
1. 系统提示词设计:强调思考和回答过程,引导模型进行深度推理而非简单猜测
2. 严格的格式奖励函数:惩罚输出走捷径的行为,如:
1>跳过<think></think>过程直接回答
2>将推理放在<answer></answer>标签内
3>没有适当推理就反复猜测答案
4>除了提供答案外,还包含不相关的内容
5>以错误的方式组织正确答案以进行提取
6>由于推理不足,在已经输出<answer>后重新访问思考阶段
7>重复原始问题或使用"思考过程在此"等短语来避免真正的推理
3. 训练方法:实现稳定收敛,让模型自然而然地分配更多训练步骤来推理
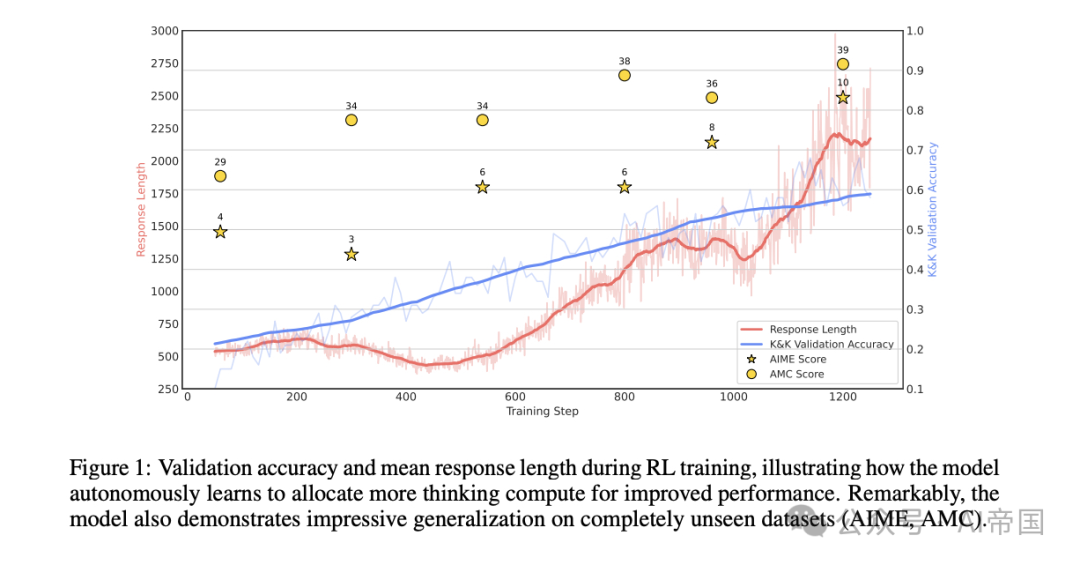
随着RL训练的进行,研究人员观察到一个惊人的现象:模型自然地分配更多的计算步骤进行推理。这种计算扩展从生成数百个标记扩展到数千个标记,使模型能够更深入地探索和完善其思维过程。
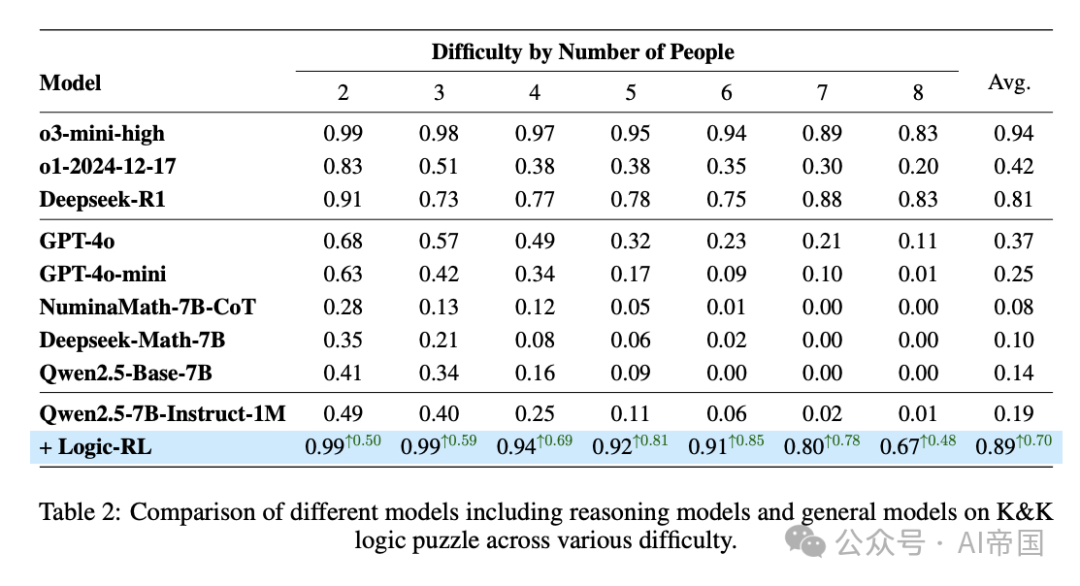
3、突破性成效:小模型也能有大智慧
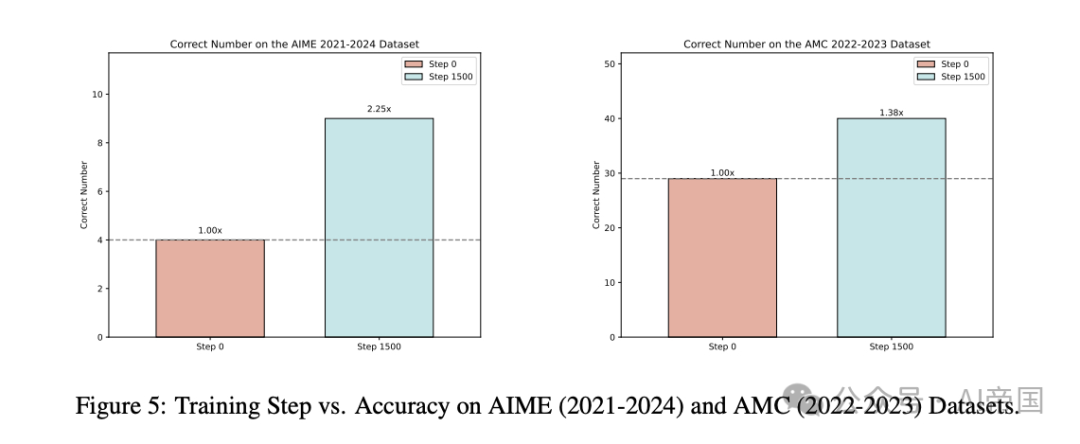
Logic-RL的实验结果令人惊叹。仅仅使用5,000个程序生成的逻辑谜题,他们的7B模型在AIME上提高了125%,在AMC上提高了38%,相比基础模型有了质的飞跃。这种跨域泛化能力表明,RL训练的推理启发式方法发展了抽象的问题解决模式,而不是依赖于特定领域的模式匹配。
研究团队还发现了几个有趣的现象:
(1)更长的回答不保证更好的推理:长度本身不是训练时间评估的有效指标。最有效的推理来自最短路径。
(2)语言混合阻碍推理:这一观察强调了在奖励建模中需要语言一致性惩罚。
(3)增加"思考"标记确实有帮助:RL训练自然地提高了与反思相关的单词的频率,表明某些标记的频率与性能之间存在相关性。
(4)SFT记忆;RL泛化:SFT严重依赖记忆,通常导致浅层捷径学习,而RL自我进化,对数据集结构的依赖性最小。
(5)冷启动是一种奖励,而不是必要条件:无论是从基础模型还是指令模型开始,训练动态都保持惊人的相似性,尽管后者表现略好。
(6)课程学习仍然重要:在固定的数据策划比例下,精心设计的课程学习方法总是优于随机打乱。

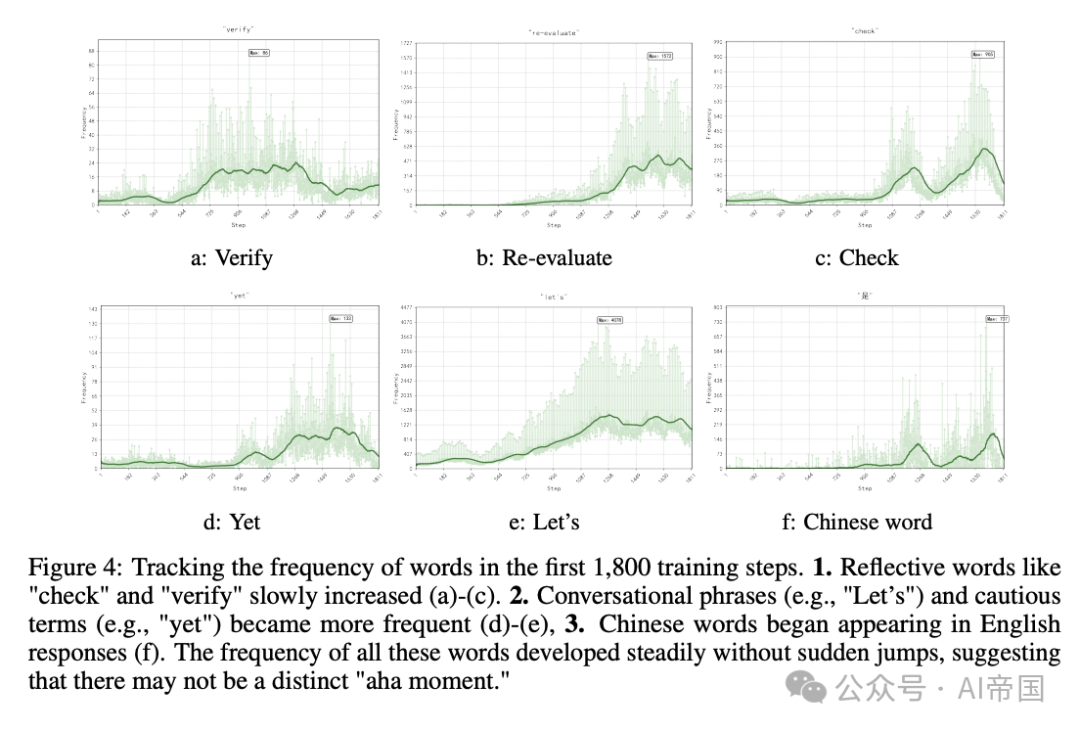
4、启示与未来:推理能力的进化之路
Logic-RL研究带来了深刻的启示。它证明了即使是相对较小的7B模型,通过精心设计的强化学习框架,也能够发展出复杂的推理能力。更令人惊讶的是,这种能力可以跨域泛化,从逻辑谜题迁移到复杂的数学问题上。
随着训练的进行,模型开始表现出更复杂的行为,如反思和探索替代解决方案。这些行为自然而然地出现,在训练集中没有相关数据,却增强了模型处理更复杂任务的能力。这种现象与DeepSeek-R1的结果高度一致。
我们可以预见,随着强化学习技术在大语言模型训练中的应用不断深入,AI的推理能力将会继续提升。这不仅对于解决数学和逻辑问题有重要意义,对于需要复杂推理的现实世界应用也有深远影响。
如果你对AI推理能力的未来发展感兴趣,不妨关注我们的后续报道。Logic-RL的成功只是一个开始,更多突破性的研究正在路上!
你对AI的推理能力有什么看法?欢迎在评论区留言分享你的观点!
论文标题:Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
论文链接:https://arxiv.org/abs/2502.14768
推荐阅读
突破性框架S*: 小模型也能写出大模型级别的代码!3B模型超越GPT-4o-mini性能

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 30
30 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)