kaggle竞赛——入门(Titanic数据集)
比赛地址:https://www.kaggle.com/c/titanic"""__author__:shuangrui Guo__description__:"""import osimport sysimport warningsimport numpy as npimport pandas as pdfrom sklearn.preprocessing import LabelEncoder
·
比赛地址:https://www.kaggle.com/c/titanic
"""
__author__:shuangrui Guo
__description__:
"""
import os
import sys
import warnings
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier,RandomForestClassifier
from sklearn.metrics import accuracy_score
# for dirname,_,filenames in os.walk('./data'):
# print(dirname,filenames)
if __name__ == '__main__':
Train_df = pd.read_csv('./data/train.csv')
Test_df = pd.read_csv('./data/test.csv')
gender_df = pd.read_csv('./data/gender_submission.csv')
#创建不需要用到的属性,并在训练集与测试集中除去对应的列
not_need_colimns=['PassengerId','Cabin','Name']
Train_df = Train_df.drop(axis = 1,columns=not_need_colimns)
Test_df = Test_df.drop(axis=1,columns=not_need_colimns)
#创建labelEncoder()
le = LabelEncoder()
#训练集对Sex列与Embarked列进行转数值化操作
Train_df['Sex'] = le.fit_transform(Train_df['Sex'])
Train_df['Embarked'] = le.fit_transform(Train_df['Embarked'].astype(str))
Train_df['Age'] = Train_df['Age'].fillna(value=Train_df['Age'].mean())
#对测试集进行同样的处理
Test_df['Sex'] = le.fit_transform(Test_df['Sex'])
Test_df['Embarked'] = le.fit_transform(Test_df['Embarked'].astype(str))
Test_df['Age'] = Test_df['Age'].fillna(value=Test_df['Age'].mean())
#对训练集中的Ticket属性,使用str,使用split分割,
Tickits = Train_df['Ticket'].str.split()
tickits=[]
for tickit in Tickits:
if tickit[-1].isdigit():
tickits.append(int(tickit[-1]))
else:
tickits.append(9999999)
Train_df['Ticket'] = tickits
#对测试集的Ticket属性进行处理
Tickits = Test_df['Ticket'].str.split()
tickits = []
for tickit in Tickits:
if tickit[-1].isdigit():
tickits.append(int(tickit[-1]))
else:
tickits.append(9999999)
Test_df['Ticket'] = tickits
#判断某一列中是否有null值
#print(Test_df['Fare'].isnull().any())
Test_df['Fare'] = Test_df['Fare'].fillna(value=Test_df['Fare'].mean())
#设置训练集特征与标签
Y_Train = Train_df.loc[:,['Survived']]
X_Train = Train_df.drop(axis = 1,columns=['Survived'])
#设置训练集与测试集
x_train,x_test,y_train,y_test = train_test_split(X_Train,Y_Train,random_state=42)
#使用AdaBoost进行分类
adc = AdaBoostClassifier()
adc.fit(x_train,y_train)
Y_pred = adc.predict(x_test)
print(accuracy_score(Y_pred,y_test))
#使用决策树进行分类
tree = DecisionTreeClassifier()
tree.fit(x_train,y_train)
Y_pred = tree.predict(x_test)
print(accuracy_score(Y_pred,y_test))
#使用随机森林进行分类
rfc = RandomForestClassifier(n_estimators=25,max_depth=7,random_state=42)
rfc.fit(x_train,y_train)
Y_pred = rfc.predict(Test_df)
print(accuracy_score(Y_pred,gender_df.loc[:,['Survived']]))
#对给出的test.csv文件进行预测
submission = pd.DataFrame({
"PassengerId":gender_df["PassengerId"],
"Survived":Y_pred
})
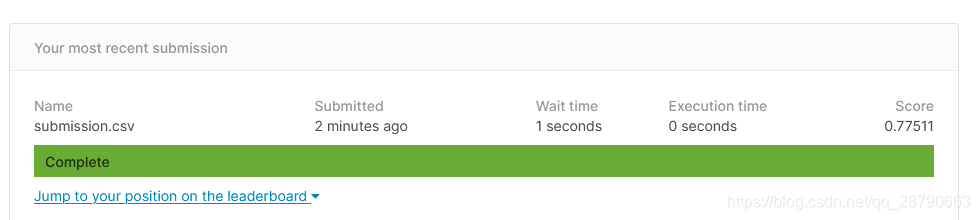
submission.to_csv('submission.csv', index=False)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)