Amazon SageMaker Endpoint for built-in TFS 模型推理优化
点击上方【凌云驭势 重塑未来】一起共赴年度科技盛宴!Tensorflow Serving(简称 TFS) 是一个很常用的模型推理开源框架,Amazon SageMaker 内建了 TFS 推理容器以支持 TensorFlow SavedModel 模型进行高效推理,因此 Amazon SageMaker 内建的 TFS 推理容器能够进行在线推理(比如通过 SageMaker Inference .


点击上方【凌云驭势 重塑未来】
一起共赴年度科技盛宴!
Tensorflow Serving (简称 TFS) 是一个很常用的模型推理开源框架,Amazon SageMaker 内建了 TFS 推理容器以支持 TensorFlow SavedModel 模型进行高效推理,因此 Amazon SageMaker 内建的 TFS 推理容器能够进行在线推理(比如通过 SageMaker Inference Endpoint),也可以做离线推理(比如通过 SageMaker Batch Transform)。本文只讨论内建的 TFS 的在线推理,但其实对于内建的 TFS 的推理加速优化和吞吐量优化的思路,离线推理场景完全可以参考。诚然,您可以通过自定义推理容器的方式来部署开源的 TFS,但是一般情况下使用 SageMaker 内建的 TFS 就已经足够了。
接下来,我们详细地介绍一下 SageMaker 内建的 TFS 的一些细节,最后用一个真实的案例来看一下如何借助内建的 TFS 做推理的加速和吞吐量的提升。
01
SageMaker 内建的
TFS 容器概览
内建的 TFS 容器本身的拓扑是
Nginx—–>Gunicorn (optional)—–>TFS。
如果从 SageMaker 外面看并且使用内建 TFS 做在线推理的话,拓扑是这样的(这里不考虑 SageMaker inference pipeline,inference pipeline 的拓扑会更复杂):
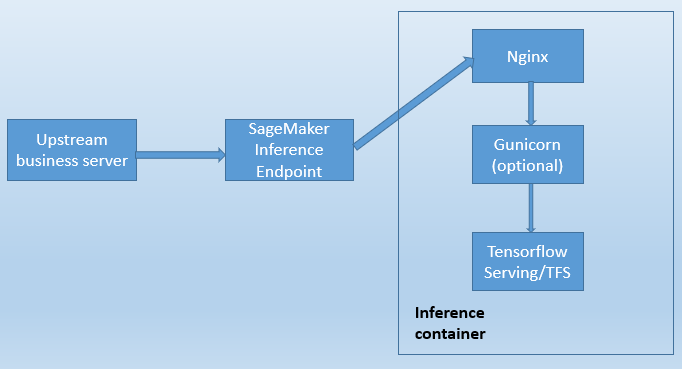
是否启用 Gunicorn 进程取决于是否设置了定制的 inference.py 脚本用于数据预处理和后处理,或者是否启用了 SageMaker Multi-Model Endpoint。
不管有没有启动 Gunicorn,SageMaker 发给 Nginx 的 /ping REST API 健康检查,Nginx 都会把 /ping 转为某种 TFS 可以接受的 REST API(比如 /v1/models/${MODEL_NAME} )后直接发给 TFS 进程。
拓扑之所以如此复杂的原因是:TFS 不支持 /ping REST API,TFS 不支持钩子函数 /hook(尽管在保存模型的时候可以使用 serving_input_receiver_fn 来让 TFS 在接收到请求后做数据预处理,但是没有办法做后处理)。
02
SageMaker 内建的 TFS
与推理加速和吞吐量优化相关的配置
1.Server side batch 相关配置
通过设置 Server side batch,可以提升吞吐量,如下表格中提到的离线推理均指 SageMaker Batch Transform 功能,在线推理均指 SageMaker 在线实时推理功能。
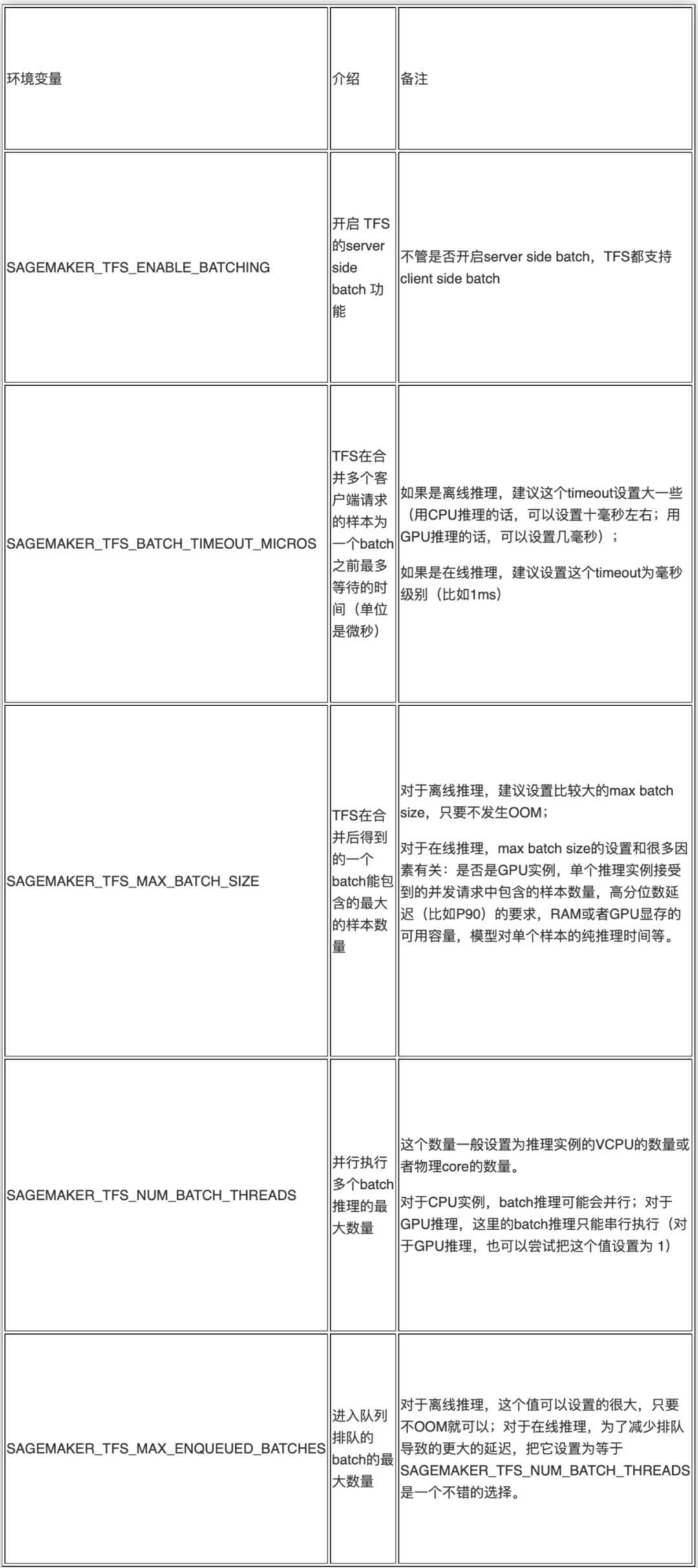
上面这些参数的设置可以参考 TFS 的官网。这些参数没有适合所有场景的最佳设置,一般都是根据业务场景、模型、推理设备以及吞吐量和高分位数延迟需求来调试的,参考上表中的备注来进行尝试通常是一个好的起点。
TFS 的官网:
https://github.com/tensorflow/serving/blob/r2.0/tensorflow_serving/batching/README.md
2.与推理加速相关的配置
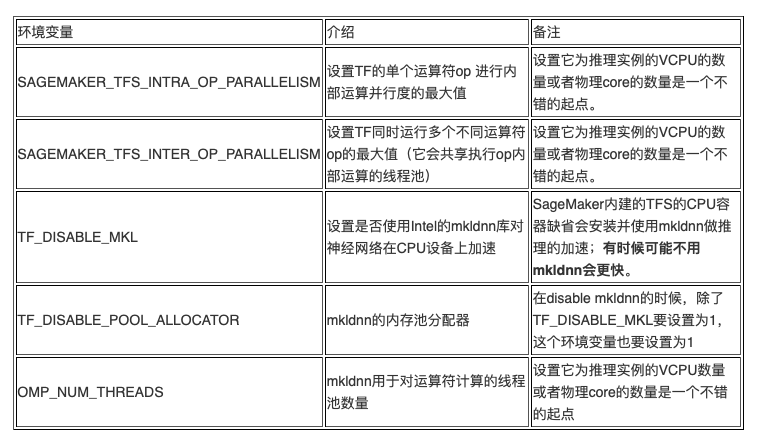
当使用 CPU 设备进行推理时,如果要启用 mkldnn,可以设置 OMP_NUM_THREADS。不管是否禁用 mkldnn,
设置 SAGEMAKER_TFS_INTRA_OP_PARALLELISM 和 SAGEMAKER_TFS_INTER_OP_PARALLELISM 对推理加速都有帮助。
当使用 GPU 设备推理时,模型前向推理的运算都是在 GPU 上进行,因此设置
SAGEMAKER_TFS_INTRA_OP_PARALLELISM 和 SAGEMAKER_TFS_INTER_OP_PARALLELISM 这两个环境变量的意义不大。如果在保存模型的时候手动设置了 serving_input_receiver_fn 做数据的预处理,并且这个预处理的运算比较复杂,那么即使在 GPU 设备做推理的情况下,
设置 SAGEMAKER_TFS_INTRA_OP_PARALLELISM 和 SAGEMAKER_TFS_INTER_OP_PARALLELISM 这两个环境变量对于 TFS 进行这个预处理也是很有帮助的,因为在数据的预处理中涉及到的 TFS OP 可以使用更多的 CPU 来加速。
03
案例分享
背景:
借助 SageMaker Inference Endpoint 内建的 TFS 对推荐系统中的排序模型做 serving。当前召回候选集的 itemid 数量是500个,单个 itemid 对应的样本/特征向量是 4KB。
需求:
从推荐服务器侧对500个特征向量从发送开始到收到打分结果在 50~100ms 以内。
经过如下一系列的优化过程,可以满足该客户的需求(从最开始的 470ms 减少到 100ms 以内):
1. 推理实例的机型选择
这里使用的排序模型是一个小型的 DNN 模型,用 GPU 做推理的性价比不高 ,因此考虑用 CPU 实例做推理。
该客户最开始使用的机型是 M5 系列,对于机器学习推理这样的计算消耗型的应用,用 CPU 来推理的话,更建议使用 C5 系列这样的计算优化型机型。
为了更好的适应自动扩容,一般不建议使用很大的机型做推理。同时考虑到单个请求的 payload 大小以及实例的带宽,使用 ml.c5.4xlarge 是一个不错的尝试起点(这里需要注意请求发起侧的实例的带宽不要成为性能瓶颈)。
2.启用 TFS server side batch
根据上文提到的内建的 TFS 的 server side batch 相关的参数来进行尝试。
由于参数的组合情况比较多,这个尝试需要进行多次,可参考 server side batch 表格的备注列。
3.TFS 的 op 并行度和 mkldnn 的相关设置
根据上文提到的 TFS 的 inter op 和 intra op 并行度以及 mkldnn 相关的环境变量来尝试。
在有些情况下,禁用 mkldnn 会有更快的推理速度(这个项目中正是 disable mkldnn 后推理速度更快)。一般建议还是对比禁用 mkldnn 与启用 mkldnn 并配置线程池的情况下,哪种推理速度更快。
4.通信 API 的选择
在 SageMaker for TFS 的推理容器中,缺省是使用 REST API 与 TFS 进程进行通信的。在推理容器内如果想使用 gRPC API 与 TFS 进行通信的话,需要借助 inference.py 来实现。
在实验时发现,当请求的 payload 比较小(比如 200KB)的时候,推理容器内使用 REST API 的整个延迟要比使用 gRPC API 的小,当请求的 payload 比较大(比如 4MB)的时候,gRPC API 会比 REST API 快很多。
5.序列化与反序列化的选择
在使用 gRPC API 的时候,经过实验,对请求的 payload 使用 JSON 序列化与反序列化比使用 string 序列化和反序列化的性能差很多。
除了请求的 payload 的序列化与反序列化,响应的 payload 的序列化和反序列化也会影响性能。对于排序模型这个场景,把响应的 numpy array 作 string 序列化比把 numpy array 作 json 序列化或者作 binary byte 序列化要效率好。
6.推荐服务器侧的大 payload 请求的拆分
在推荐服务器侧把 payload 大的请求拆分为多个 payload 小的请求(每个拆分后的小请求用不同的线程来发送,不同的线程最好使用不同的 sagemaker-runtime client 对象。这种使用方式比拆分的所有小请求都使用同一个 sagemaker-runtime client 对象的延迟要小),并且发送给 SageMaker Endpoint,之后在推荐服务器侧把多个小的请求对应的打分结果合并做最后的整体排序。
在客户的这个项目中,当推理容器使用 gRPC API 并且使用一个大 payload 的单个请求时,通过上面这些优化可以把总的延迟控制到 150ms 左右;当推理容器内使用 REST API 的方式(且不使用 inference.py),把召回结果集对应的500个样本的大请求拆分为10个并发的小请求(每个小请求包含50个样本/特征向量),整个召回结果集的最终打分的总的延迟基本在 100ms 以内。
04
示例代码
下面先给出 inference.py 的参考代码片段:
import json
import numpy as np
import grpc
from tensorflow.compat.v1 import make_tensor_proto
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
import os
import time
# default to use of GRPC
PREDICT_USING_GRPC = os.environ.get('PREDICT_USING_GRPC', 'true')
print('PREDICT_USING_GRPC')
print(PREDICT_USING_GRPC)
if PREDICT_USING_GRPC == 'true':
USE_GRPC = True
else:
USE_GRPC = False
MAX_GRPC_MESSAGE_LENGTH = 512 * 1024 * 1024
options = [
('grpc.max_send_message_length', MAX_GRPC_MESSAGE_LENGTH),
('grpc.max_receive_message_length', MAX_GRPC_MESSAGE_LENGTH)
]
def handler(data, context):
if context.request_content_type == 'X-protobuf':
d = data.read()
channel = grpc.insecure_channel(f'0.0.0.0:{context.grpc_port}', options=options)
request = predict_pb2.PredictRequest()
#String Deserialization is faster than json Deserialization
request.ParseFromString(d)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
result_future = stub.Predict.future(request, 5)
output_tensor_proto = result_future.result().outputs['prob']
output_shape = [dim.size for dim in output_tensor_proto.tensor_shape.dim]
output_np = np.array(output_tensor_proto.float_val).reshape(output_shape)
prediction_json = json.dumps({'prob': output_np.tolist()})
response_content_type = context.accept_header
return prediction_json, response_content_type左滑查看更多
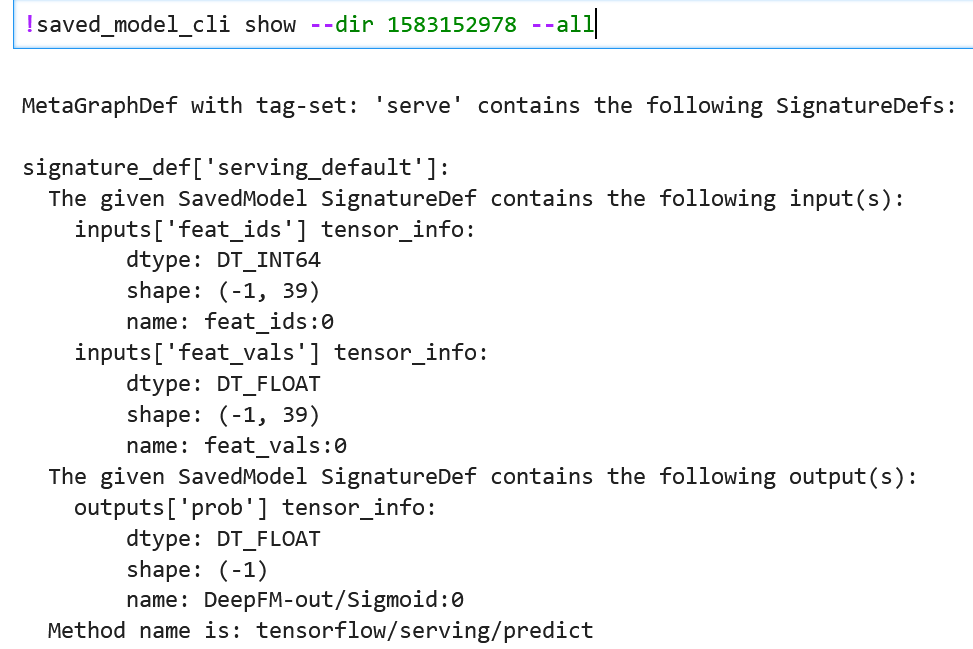
上面代码中对 protocol buffer request 使用了 string 反序列化(因为在客户端对请求进行了 string 序列化)。代码中出现的“prob”需要修改为使用 saved_model_cli 命令行查看你的模型的某个 output tensor 的名字。我这里用的模型的 output tensor 的名字是“prob”,如下所示:
上面代码使用的是对响应的 numpy array 序列化为 json,也可以尝试把 numpy array 序列化为 string 或者 binary byte,来看看哪个方式效率更高。这三种方式的区别反应在 inference.py 代码中就是最后几行不同:
-
对于 numpy array 序列化为 json,最后几行代码如下:

-
对于 numpy array 序列化为 binary byte,最后几行代码如下:

-
对于 numpy array 序列化为 string,最后几行代码如下:

下面是调用 SageMaker Python SDK 来部署模型并且简单测试在线推理的代码片段,供参考:
from sagemaker.tensorflow.serving import Model
import sagemaker
role = sagemaker.get_execution_role()
model = Model(
source_dir = "code",
entry_point='inference.py',
model_data='s3://YOUR_BUCKET/model.tar.gz', #change to your model s3 uri
role=role,
framework_version="2.3",
env = {
'SAGEMAKER_TFS_ENABLE_BATCHING': 'true',
'SAGEMAKER_TFS_BATCH_TIMEOUT_MICROS': '1000',
'SAGEMAKER_TFS_MAX_BATCH_SIZE': '128000',
'SAGEMAKER_TFS_NUM_BATCH_THREADS':'16',
'SAGEMAKER_TFS_MAX_ENQUEUED_BATCHES':'16',
'SAGEMAKER_TFS_INTER_OP_PARALLELISM':'16',
'SAGEMAKER_TFS_INTRA_OP_PARALLELISM':'16',
'TF_DISABLE_MKL':'1',
'TF_DISABLE_POOL_ALLOCATOR':'1',
"SAGEMAKER_GUNICORN_WORKERS":"8"
}
)
predictor = model.deploy(initial_instance_count=1, instance_type='ml.c5.4xlarge')左滑查看更多
除了提供 inference.py 代码,你还需要提供一个依赖包的 requirements.txt 文件,依赖的安装包是 tensorflow-serving-api 和 numpy。关于上面代码中的环境变量的设置具体参考前文相关章节(上面的环境变量设置 disable 了 mkldnn,对于客户的模型来说,enable mkldnn 并且设置 mkldnn 的线程池,推理速度比 disable mkldnn 的情况差很多)。
下面的代码用来构造 protocol buffer 请求(这里为了方便模拟 payload 比较大的请求,直接复制一个样本为500个样本;并且以 DeepFM 模型为例),并把请求作 string 序列化。
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
import numpy as np
from tensorflow.compat.v1 import make_tensor_proto
import time
t = [1,2,3,4,5,6,7,8,9,10,11,12,13,15,555,1078,17797,26190,26341,28570,35361,35613,35984,48424,51364,64053,65964,66206,71628,84088,84119,86889,88280,88283,100288,100300,102447,109932,111823]
f = [0.05,0.006633,0.05,0,0.021594,0.008,0.15,0.04,0.362,0.1,0.2,0,0.04,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
inputs = {}
inputs["feat_ids"] = [t for i in range(0,500)]
inputs["feat_vals"] = [f for i in range(0,500)]
features = ['feat_ids', 'feat_vals']
options = [
('grpc.max_send_message_length', 1024*1024*1024),
('grpc.max_receive_message_length', 1024*1024*1024)
]
request = predict_pb2.PredictRequest()
request.model_spec.name = 'model'
request.model_spec.signature_name = 'serving_default'
request.inputs["feat_ids"].CopyFrom(make_tensor_proto(np.array(inputs["feat_ids"], dtype="int64")))
request.inputs["feat_vals"].CopyFrom(make_tensor_proto(np.array(inputs["feat_vals"], dtype="float32")))
payload = request.SerializeToString()左滑查看更多
您可以按照上面的代码根据相应模型的 input tensor 来进行构造,上面使用的 signature_name 对应您在保存模型时设置的 signature,如果没有设置,缺省是“serving_default”。
接下来是三种不同的 response 的序列化方法对应的客户端反序列化的代码。
A.response 的 numpy array 序列化为 JSON 的情况,在客户端反序列化的时候使用 load() 的代码片段如下:
import boto3
import time
import json
client = boto3.client('sagemaker-runtime')
endpoint_name = 'your_endpoint_1'
content_type = "X-protobuf"
list_1 = []
for i in range(0,500):
time_start = time.time()
response = client.invoke_endpoint(
EndpointName=endpoint_name,
ContentType=content_type,
Body = payload
)
result = json.loads(response['Body'].read().decode())['prob']
time_end = time.time()
list_1.append(time_end-time_start)
print(sum(list_1)/len(list_1))左滑查看更多
因为这里我们会使用 inference.py 做数据的前处理和后处理,所以上面代码中的 content_type 可以随便写,只要和 inference.py 代码中期望的 content_type 保持一致即可。
B.response 的 numpy array 序列化为 binary byte 的情况,在客户端反序列化的时候使用 load(io.BytesIO()) 的代码片段如下:
import io
list_1 = []
for i in range(0,500):
time_start = time.time()
response = client.invoke_endpoint(
EndpointName='your_endpoint_2',
ContentType=content_type,
Body = payload
)
result = np.load(io.BytesIO(response['Body'].read()), allow_pickle=True)
#print(result)
time_end = time.time()
list_1.append(time_end-time_start)
print(sum(list_1)/len(list_1))左滑查看更多
C.response 的 numpy array 序列化为 string 的情况,在客户端反序列化的时候使用 frombuffer() 的代码如下:
import io
list_1 = []
for i in range(0,500):
time_start = time.time()
response = client.invoke_endpoint(
EndpointName='your_endpoint_3',
ContentType=content_type,
Body = payload
)
result = np.frombuffer(response['Body'].read())
#print(result)
time_end = time.time()
list_1.append(time_end-time_start)
print(sum(list_1)/len(list_1))左滑查看更多
05
总结
本文详细介绍了在 SageMaker 中的内建 TFS 推理容器的一些细节,并通过一个真实的项目讲解了加速推理的过程和思路,以及相关的参考代码,感谢大家的阅读。
本篇作者

梁宇辉
亚马逊云科技机器学习产品技术专家,负责基于亚马逊云科技的机器学习方案的咨询与设计,专注于机器学习的推广与应用,深度参与了很多真实客户的机器学习项目的构建以及优化。对于深度学习模型分布式训练,推荐系统和计算广告等领域具有丰富经验。
2022亚马逊云科技 re:Invent 全球大会
精彩视频现已上线!
👇👇👇点击下方图片立即观看👇👇👇


听说,点完下面4个按钮
就不会碰到bug了!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)