多元回归分析数据集_TED演讲数据集探索之可视化分析
介绍TED由Richard Saulman创立于1984年,是一家旨在将技术(technology),娱乐(entertainment)和设计(design)领域的专家聚集在一起的非盈利组织。Ted的口号是"Ideas worth spreading",也就是“值得传播的思想”。每年2-3月,TED大会在北美召集众多领域的杰出人物,为他们提供了一个平台,将多年的工作和研究提炼为简短有力的演讲(通常

介绍
TED由Richard Saulman创立于1984年,是一家旨在将技术(technology),娱乐(entertainment)和设计(design)领域的专家聚集在一起的非盈利组织。Ted的口号是"Ideas worth spreading",也就是“值得传播的思想”。每年2-3月,TED大会在北美召集众多领域的杰出人物,为他们提供了一个平台,将多年的工作和研究提炼为简短有力的演讲(通常少于18分钟),并上传到TED官网供观众免费收看。同时,独立运行的TEDx鼓励各地的TED粉丝自发组织TED风格的活动,在世界各地的社区分享想法。
和鲸社区 - Kesci.comwww.kesci.com#加载库
%matplotlib inline
import pandas as pd
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns本研究首先针对ted_main.csv数据集,该数据集包含了2017年9月21日之前上传到官方网站http://TED.com的所有TED Talks演讲录制信息。
另一个数据集transcripts.csv包含了具体的演讲文本信息,我们稍晚一些时候再进行分析。
首先,让我们简单看一下ted_main.csv数据集的概况,并对数据集进行初步调整,看看有什么值得探索的方向。
#加载数据集
ted = pd.read_csv("../input/tedtalk/ted_main.csv")
#查看数据集行列数
print("该数据集共有 {} 行 {} 列".format(ted.shape[0],ted.shape[1])) 该数据集共有 2550 行 17 列
#调整特征顺序
ted = ted[['name', 'title', 'description', 'main_speaker', 'speaker_occupation', 'num_speaker', 'duration', 'event', 'film_date', 'published_date', 'comments', 'tags', 'languages', 'ratings', 'related_talks', 'url', 'views']]#查看数据集的列
ted.columnsIndex(['name', 'title', 'description', 'main_speaker', 'speaker_occupation',
'num_speaker', 'duration', 'event', 'film_date', 'published_date',
'comments', 'tags', 'languages', 'ratings', 'related_talks', 'url',
'views'],
dtype='object')
数据集有17列特征,具体解释如下:

原数据集中的film_date和published_date是用Unix timestamp表示的,我们使用datetime库,将其转换为可读的日期形式。
#调整拍摄日期&发布日期
import datetime
ted['film_date'] = ted['film_date'].apply(lambda x: datetime.datetime.fromtimestamp(int(x)).strftime('%d-%m-%Y'))
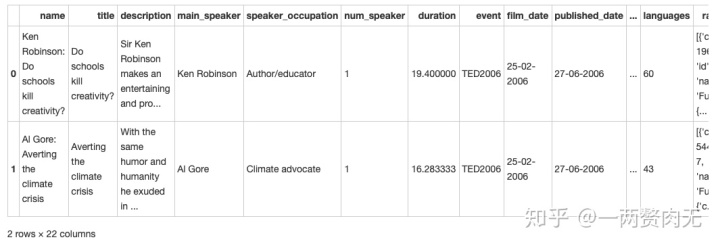
ted['published_date'] = ted['published_date'].apply(lambda x: datetime.datetime.fromtimestamp(int(x)).strftime('%d-%m-%Y'))进过初步微调的数据集如下:
#显示调整后的数据集前两行
ted.head(2)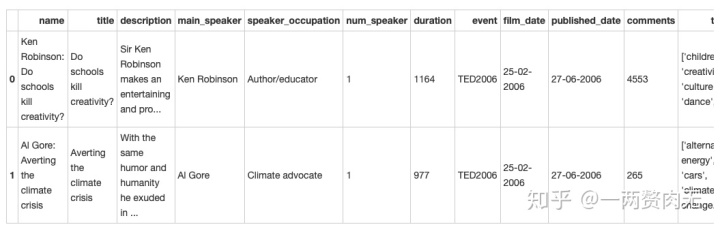
数据质量检查
# 检查空值
ted.isnull().any()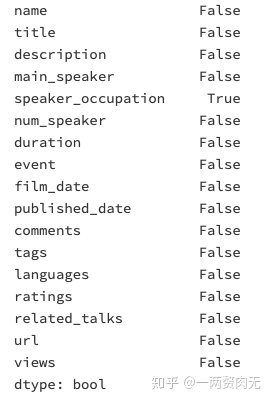
# 查看一下speaker_occupation缺失值的具体情况
ted[ted['speaker_occupation'].isnull()]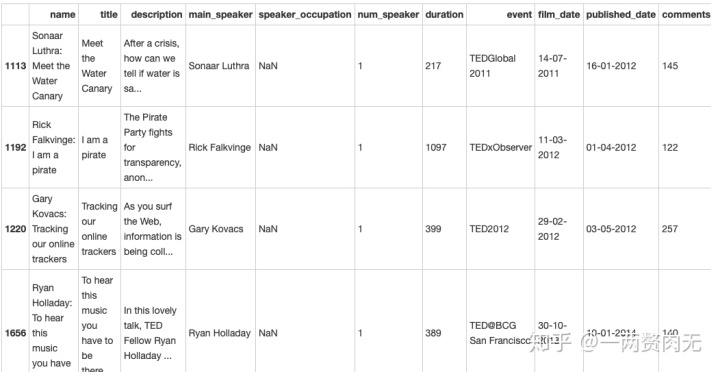
speaker occupation中有6行存在空值,其他栏不存在空值。目测对之后分析的影响不大。
数值型数据的描述性分析
# 各个column内容的描述性统计
ted.describe()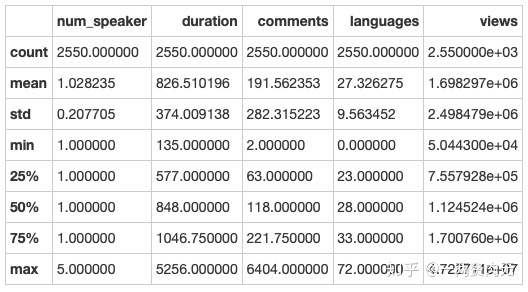
# 单人演讲的比例
print("单人演讲占所有演讲的比例为{}%".format(round(sum(ted["num_speaker"] == 1)*100/len(ted), 1)))
#演讲时长小于18分钟的比例
print("时长小于18分钟的演讲数占所有演讲总数的{}%".format(round(sum(ted["duration"] <= 18*60)*100/len(ted), 1)))单人演讲占所有演讲的比例为97.7% 时长小于18分钟的演讲数占所有演讲总数的79.1%
观察结论
- 演讲人数在1-5个人之间,大部分(97.7%)都是单人演讲;
- 演讲时长在135-5256秒之间,即2-88分钟之间,79.1%的演讲是小于18分钟以内的;
- 评论数在2-6404条之间,平均值在191.5条左右;
- 观看数在50,000-47,000,000次之间,平均值在1,700,000次左右;
- TED提供多种语言的选择,最多可以达到72种语言。
大家都在看什么?——浏览量最高的10个TED视频
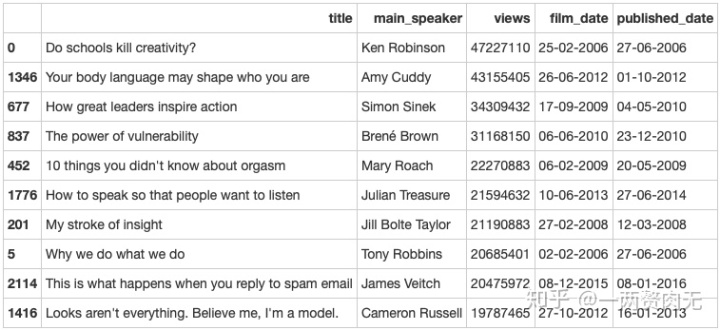
观察结论
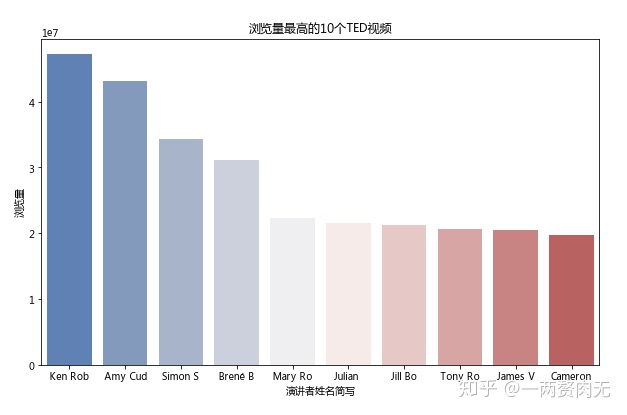
- Ken Robinson的演讲 Do Schools Kill Creativity? 是最受欢迎的TED演讲,有47 million个的浏览量,该演讲也是在2006年6月27日第一批被发布到TED官网上的演讲之一;
- Amy Cuddy的演讲 Your Body Language May Shape Who You Are 是第二受欢迎的TED演讲,有43 million个的浏览量;
- 前两名演讲的浏览量超过40 million,第3-4名的浏览量超过30 million,第5-10名的浏览量在20 million左右。
通过画条形图我们可以看的更直观:
看完了浏览量最高的10个视频,我们看一下浏览量的整体情况。
ted['views'].describe()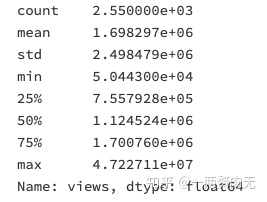
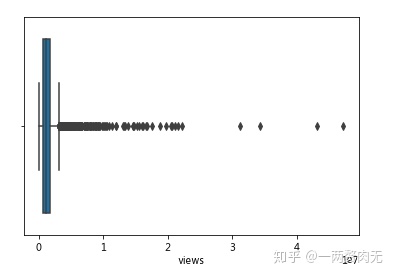
# 盒形图
sns.boxplot(ted['views'])<matplotlib.axes._subplots.AxesSubplot at 0x7f4b766529e8>
# 分布图
sns.distplot(ted['views'])<matplotlib.axes._subplots.AxesSubplot at 0x7f4b765fe9b0>
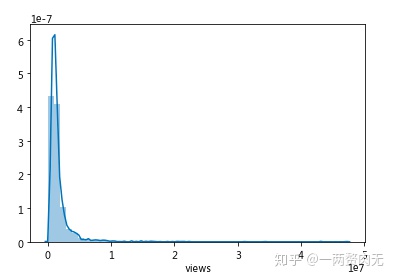
# 浏览量小于4 million的比例
print("浏览量小于4 million的演讲视频数占总数的" + str(round(sum(ted["views"] <= 4000000)*100/len(ted), 1)) + "%")浏览量小于4 million的演讲视频数占总数的93.5%
视频浏览量的平均值是1.7 million,中位数是1.1 million,说明TED视频的流行程度还是很高的。
93.5%的演讲浏览量是低于4 million的,因此将浏览量小于40 million的视频画出分布图,更能看清视频浏览量的分布情况。
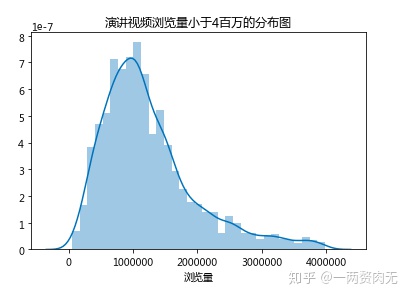
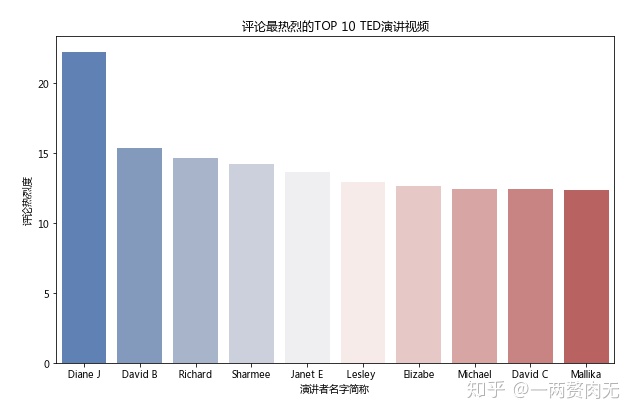
大家都在讨论什么?——讨论量最高的10个TED视频
刚刚看了浏览量最高的10个视频,现在我们来看看,哪些视频能够引起大家的热烈讨论呢?
注:数据集中只收集了一级评论的数量,接下来的分析也以这个数量作为标准。我们假定,有更多一级评论的视频,讨论人数更多。
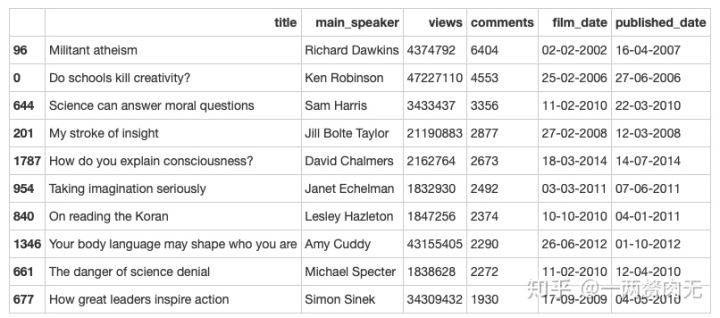
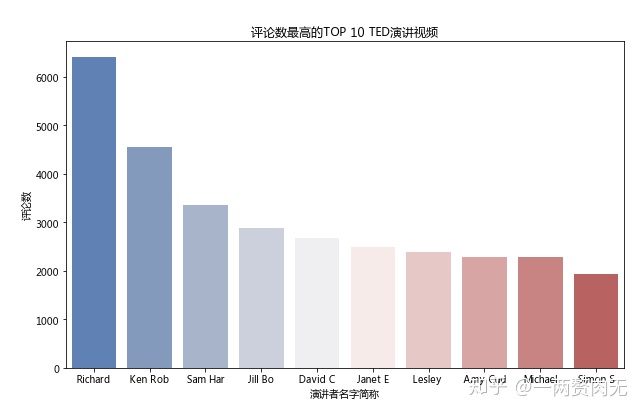
观察结论
- Richard Dawkins的演讲 Militant atheism 是讨论最热烈的TED演讲,一共有6404条一级评论,尽管其播放量仅是Ken Robinson的演讲 Do Schools Kill Creativity? 的十分之一;
- 之前浏览量第一的Ken Robinson的演讲 Do Schools Kill Creativity? 在这里取得了第二名,4553条一级评论;
- 之前浏览量第二、第三、第七的演讲分别取得了播放量第八、第十、第四的名次,因此,浏览榜和评论榜中有4个视频是同时上榜的,可谓是“叫好又叫座”了。
- 前三名的评论量分别超过了6000,4000和3000条,第4-7名的评论量在2000-3000左右。
通过画条形图我们可以看的更直观:
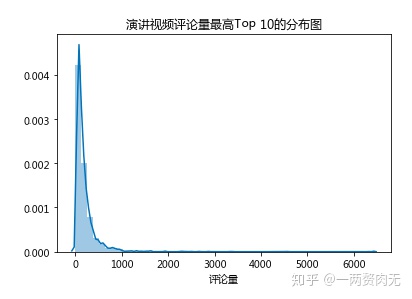
看完了评论量最高的10个视频,我们看一下评论量的整体情况。
ted['comments'].describe()
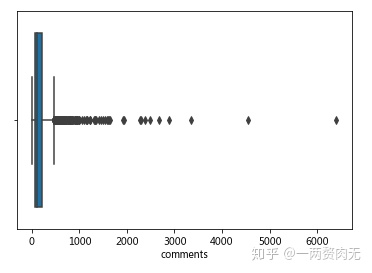
# 盒形图
sns.boxplot(ted['comments'])<matplotlib.axes._subplots.AxesSubplot at 0x7f4b7665cc88>
# 评论量小于500的比例
print("评论量小于500条:" + str(round(sum(ted["comments"] <= 500)*100/len(ted), 1)) + "%")评论量小于500条:93.3%
观察结论
视频评论量的平均值是191条,中位数是118条,说明了TED视频的讨论度还是很高的。
93.3%的评论是少于500条的,因此描述性统计的数据会受到outlier的影响。
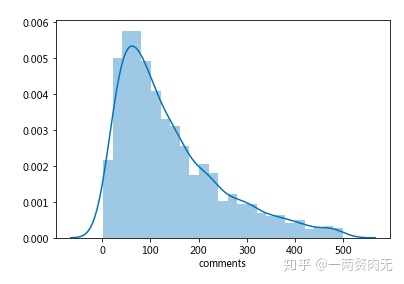
将小于500评论数的分布图画出来后,感觉更加能看出评论数的分布情况。
# 评论量小于500的分布图
sns.distplot(ted[ted['comments'] < 500]['comments'])<matplotlib.axes._subplots.AxesSubplot at 0x7f4b766cfac8>
浏览量vs评论量:相关关系?
另外一个感兴趣的问题就是,视频浏览量和评论量是否存在相关关系?浏览量更高的视频,是不是会有更多的评论呢?我们接下来进行更深入的研究。
#联合分布图
sns.jointplot(x = 'views', y = 'comments', data = ted)<seaborn.axisgrid.JointGrid at 0x7f4b76346278>
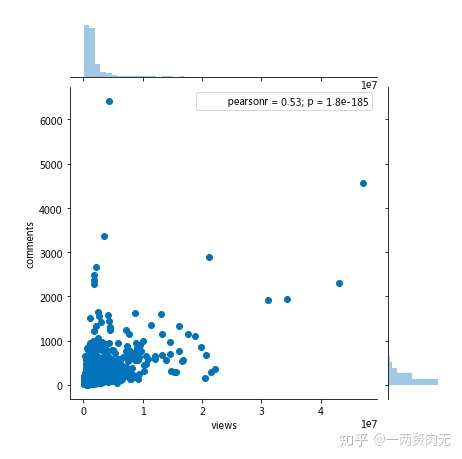
#相关矩阵
ted[['views', 'comments']].corr()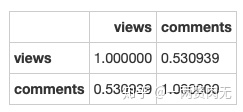
从联合分布图&相关矩阵可以看出,pearson相关系数为0.53,是中等到强相关的程度。因为之前两个top 10的名单有所重合,这个相关性在我们的预期之内。
头脑风暴:讨论最热烈的10个TED视频
以上对视频的浏览量、评论量的分析给了我们新的灵感:
- 哪些视频引起了更多观看者参与讨论呢?
我们在这里定义一个新特征:讨论指数(讨论指数 = 评论量/浏览量*10000),并列出讨论比例最高的10个视频。
#讨论指数
ted['dis_ind'] = round(ted['comments']/ted['views'] * 10000, 1)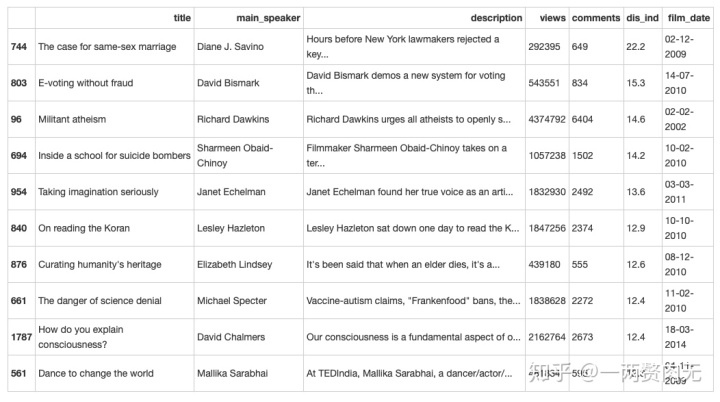
评论指数前10名的演讲,大部分含有“宗教”、“科学”或者“政治”的标签,可见相比于“文化”、“艺术”等话题,这些话题更容易引起人们的热烈探讨。
讨论指数最高的视频是 The Case for Same Sex Marriage,讨论美国关于婚姻平等立法的问题。同性婚姻往往与宗教、政治、人权等一系列容易引起争议的话题标签相连,因此引起热议并不令人惊奇。
根据时间段分析TED演讲
TED大会通常每年一次,但是TEDx及其他小型的活动发生更为频繁。这些演讲的时间是如何分布的,有没有什么举行演讲次数特别多的热门时间段?
按月分析
# 月份和星期的顺序
month_order = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
day_order = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']# 加一列月份
ted['month'] = ted['film_date'].apply(lambda x: month_order[int(x.split('-')[1]) - 1])
month_df = pd.DataFrame(ted['month'].value_counts()).reset_index()
month_df.columns = ['month', 'talks']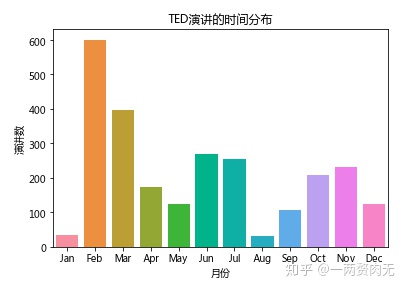
可以看出,二月是TED演讲产出最多的时候,可能跟TED大会的召开有关。一月和八月是产出最少的时候。
那如果只看TEDx(当地社区组织的非官方活动),情况是否有所变化呢?
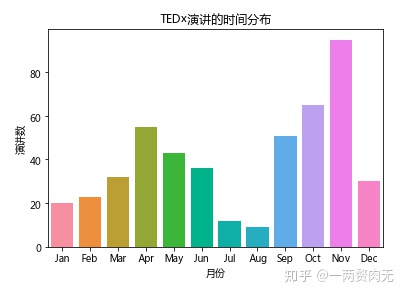
大部分TEDx的演讲都没有被上传到TED官网上,所以我们样本中的TEDx演讲不能代表整体的情况。
针对样本中的TEDx演讲,十一月的产出量最多,其次是十月,四月和九月。
按周分析
# 定义获取星期的函数
def getday(x):
day, month, year = (int(i) for i in x.split('-'))
answer = datetime.date(year, month, day).weekday()
return day_order[answer]# 加一列星期
ted['day'] = ted['film_date'].apply(getday)day_df = pd.DataFrame(ted['day'].value_counts()).reset_index()
day_df.columns = ['day', 'talks']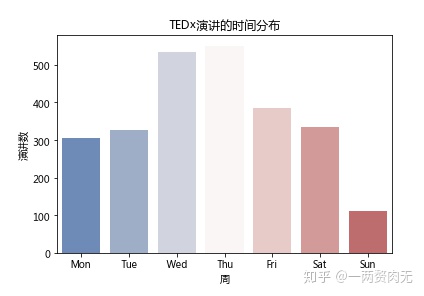
可以看出,周三和周四的演讲量是最多的,而周日的演讲量是最少的。这和之前的直觉“周末的演讲会比较多”相违背。
按年分析
# 添加年份列
ted['year'] = ted['film_date'].apply(lambda x: x.split('-')[2])
year_df = pd.DataFrame(ted['year'].value_counts().reset_index())
year_df.columns = ['year', 'talks']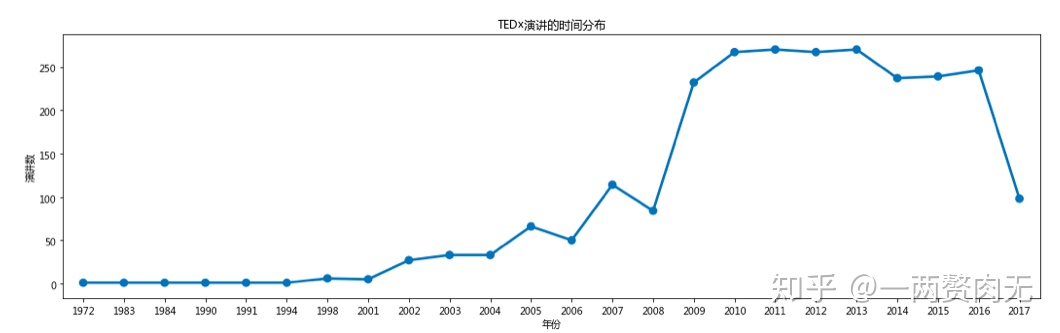
可以看出:
- 和预期一样,TED演讲的视频数量逐年上升;
- 2008年到2009年,视频数量急剧上升,涨了三倍;
- 2009年之后,每年的视频数量稳定在250个左右。
按年/月分析:热图
为了看清TED演讲视频的数量演变,我们选择Heatmap来展示:
<matplotlib.axes._subplots.AxesSubplot at 0x7f4b75dd5da0>
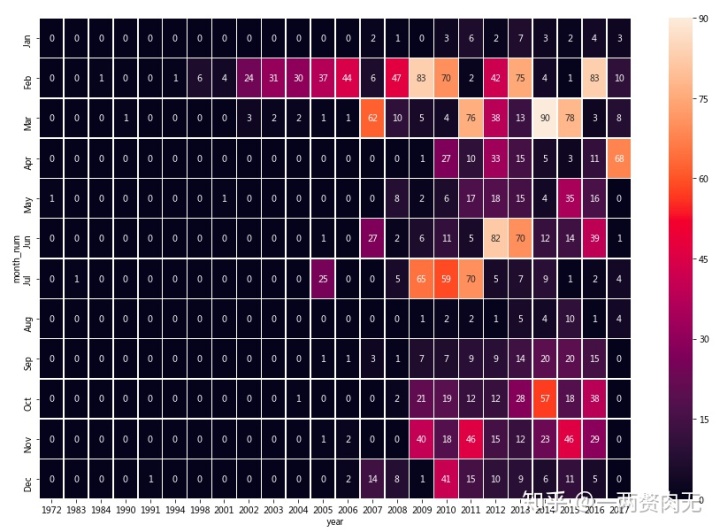
TED演讲的演讲者们
演讲者出场次数
分析完演讲视频的数量、浏览量和评论量后,我们把目光转向拥有杰出思想的演讲者们。哪位演讲者出场的次数最多呢?
speaker_df = ted.groupby('main_speaker').count().reset_index()[['main_speaker', 'comments']]
speaker_df.columns = ['主要演讲者', '演讲次数']
speaker_df = speaker_df.sort_values('演讲次数', ascending=False)
speaker_df.head(10)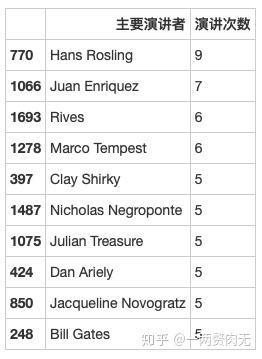
Hans Rosling 是来自瑞士的健康领域的专家。他显然是最受欢迎的TED演讲者,一共出现了9次;第二名是Juan Enriquez,出现了7次;并列第三名是Rives和Marco Tempest,出现了6次。
接下来看一下,什么职业的演讲者更容易被TED邀请呢?
演讲者职业分布
occupation_df = ted.groupby('speaker_occupation').count().reset_index()[['speaker_occupation', 'comments']]
occupation_df.columns = ['演讲者职业', '演讲次数']
occupation_df = occupation_df.sort_values('演讲次数', ascending = False)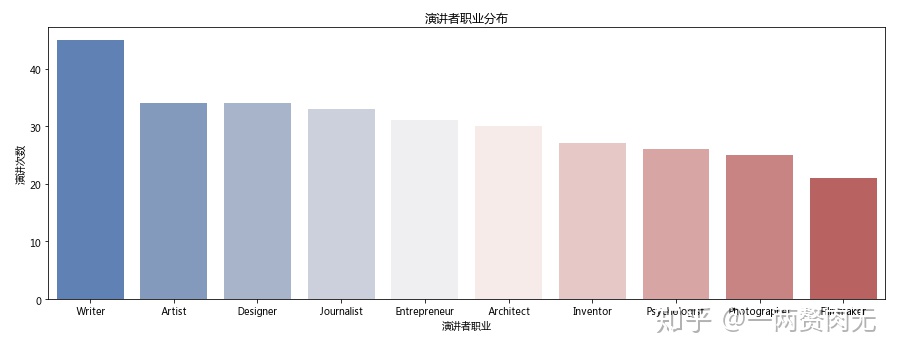
观察结论:
- 作家是最受欢迎的发言者,有超过45位演讲者把自己定义为“作家”这个职业;
- 艺术家 和 设计师 排在第二位,每个类别有35位左右;
- 分析可能存在不准确的地方,因为很多人为自己认证了多种职业,例如“作家/企业家”;
- 如果想要得到更准确的结果,需要对职业这一列进行数据清理,将多重职业拆分,方便进一步的分析。
某些特定职业的演讲是否会吸引更多的观众?我们选择前十名的职业并将演讲视频按职业分类,通过盒形图的方式,查看不同职业演讲者的演讲浏览量。
不同职业演讲者的视频浏览量
# 盒形图
fig, ax = plt.subplots(nrows = 1, ncols = 1, figsize = (15, 8))
ax = sns.boxplot(x = 'speaker_occupation', y = 'views',
data = ted[ted['speaker_occupation'].isin(occupation_df.head(10)['演讲者职业'])],
palette="vlag", ax = ax)
ax.set_title("不同职业演讲者的视频浏览量")
ax.set_xlabel("演讲者职业")
ax.set_ylabel("浏览量")
ax.set_ylim([0, 0.4e7])
plt.show()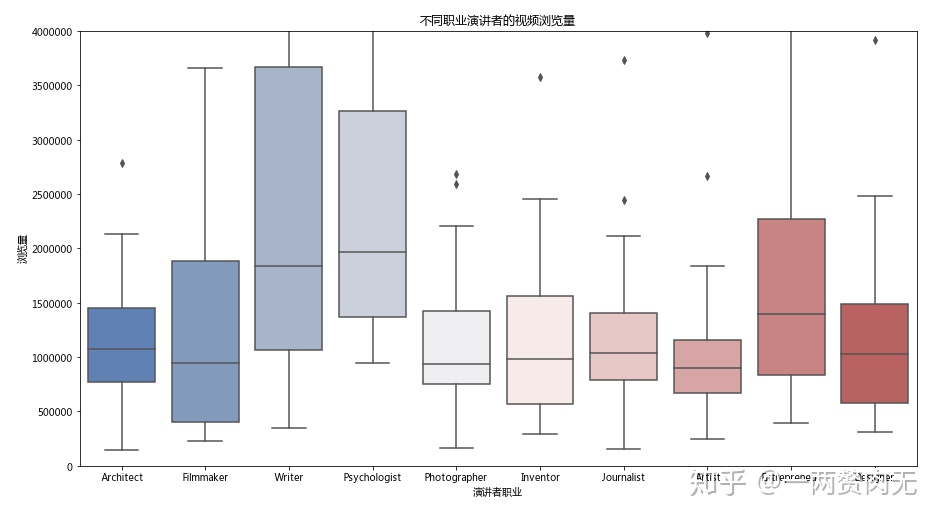
从盒形图得知,在10个最受欢迎的职业中,作家和心理学家的演讲视频获得了更多的浏览量。
最后,让我们来查看一下每个演讲的演讲嘉宾人数。
每场的演讲人数
# 每场演讲的嘉宾数量统计
ted['num_speaker'].value_counts()
# 查询嘉宾为5个的时候,具体的演讲信息
ted[ted['num_speaker'] == 5][['title', 'description', 'main_speaker', 'event']]
绝大部分演讲只有一位演讲嘉宾,49个演讲有两位演讲嘉宾。
数量最多的一次,演讲嘉宾达到了5个,查询后得知这是一场舞蹈表演,A dance to honor Mother Earth。
TED活动
哪类TED活动在TED官网上上传了最多的视频呢?在这里猜测一下应该是TED大会,因为这是举办时间最久,官方每年一次的活动。
让我们用数据来证明一下:
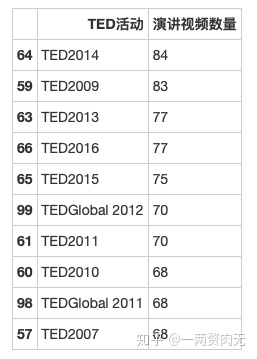
print("前10 TED活动贡献:" + str(round(sum(events_df.iloc[0:10, 1])*100/len(ted), 1)) + "%")前10 TED活动贡献:29.0%
正如我们预料的,TED官网平台发布的视频大多数由官方的TED活动占据。
其中,TED2014贡献了84个视频,位列第一,TED2009贡献了83个视频,紧随其后。
前十名的TED活动贡献了29%的演讲视频。
收看TED演讲的语言选择
TED演讲提供了很多不同的语言选择(文稿),我们来看一下演讲都提供了多少种语言选择。
ted['languages'].describe()
平均来说,一个TED演讲视频拥有27种语言的文稿,最多的拥有72种语言的文稿,最少的没有文稿。
ted[ted['languages'] == 72]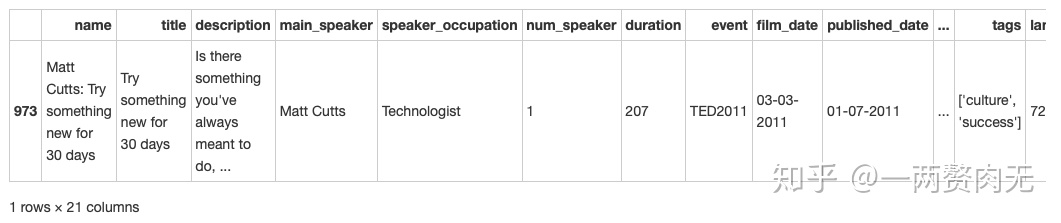
查找发现,唯一一个有72种语言选择的演讲视频是Matt Cutts的 Try something new for 30 days,长度207秒。这个视频的浏览量是8 million,超过了平均浏览量1.1 million,但距离最高浏览量47 million还有一定的差距。
接下来让我们检查一下提供的语言数量和浏览量的相关关系。我们认为这两者应该一定程度上正相关,因为如果一个演讲有更多的语言可以选择,那么她的受众也会更广泛。然而,根据Matt Cutts演讲视频的浏览量,这个相关性可能不是很强。
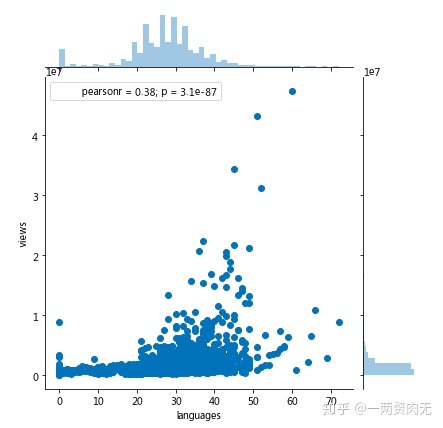
pearson相关系数是0.38,说明提供的语言数量和浏览量存在中度相关,符合我们之前的预测。
TED演讲的主题分析
在这部分,我们想要找出最受欢迎的TED演讲主题。尽管TED一开始专注于Technology,Entertainment和Design,发展到今天,其包含的主题已经非常多样化。
包含TED演讲主题信息的列是tags,以列表形式列出了每个演讲视频的若干标签。我们先对这一列数据进行清理,提取出标签信息。
# 将字符串型的list转变成list
import ast
ted['tags'] = ted['tags'].apply(lambda x: ast.literal_eval(x))# 原本的tag内容
ted['tags'].head()
# 将每个视频的标签拆开
s = ted.apply(lambda x: pd.Series(x['tags']),axis=1).stack().reset_index(level=1, drop=True)
s.name = 'theme'
s.head()
# 将拆分好的标签加回原数据集
theme_df = ted.drop('tags', axis = 1).join(s)
theme_df.head(2)
# 标签数量
print("标签数量:{}".format(len(theme_df['theme'].value_counts())))标签数量:416
在所有的演讲视频中,TED一共定义了416个不同标签,我们看一下哪个标签最受欢迎?
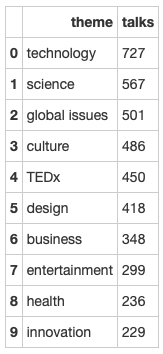
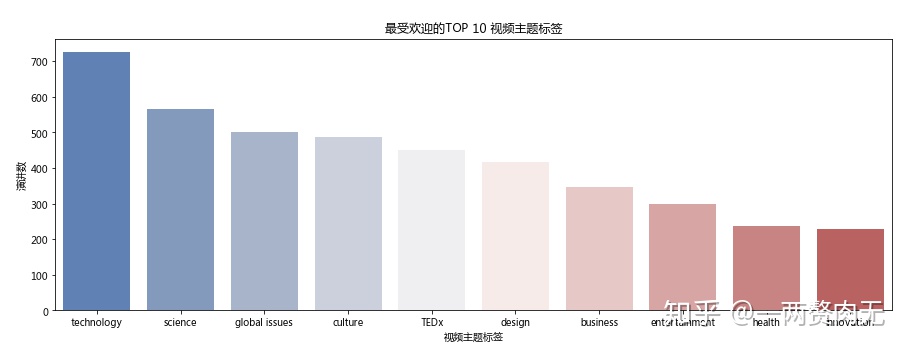
正如我们所料,“技术”是最流行的演讲主题,随后是“科学”、“全球问题”和“文化”。“娱乐”和“设计”也进入了前10名的主题,分别排在第八名和第六名。
那么近年来,这些流行主题的发展趋势如何?排除TEDx这个不相关的标签,我们选取了前7个演讲主题(技术、科学、全球问题、文化、设计、商业、娱乐),并分析2009-2017年间这些话题的占比,希望能看到流行话题的演变过程。
pop_theme_talks = theme_df[(theme_df['theme'].isin(pop_themes.head(8)['theme'])) & (theme_df['theme'] != 'TEDx')]
pop_theme_talks['year'] = pop_theme_talks['year'].astype('int')
pop_theme_talks = pop_theme_talks[pop_theme_talks['year'] > 2008]#条形图
themes = list(pop_themes.head(8)['theme'])
themes.remove('TEDx')
ctab = pd.crosstab([pop_theme_talks['year']], pop_theme_talks['theme']).apply(lambda x: x/x.sum(), axis=1)
ctab[themes].plot(kind='bar', stacked=True, colormap='rainbow', figsize=(12,8)).legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()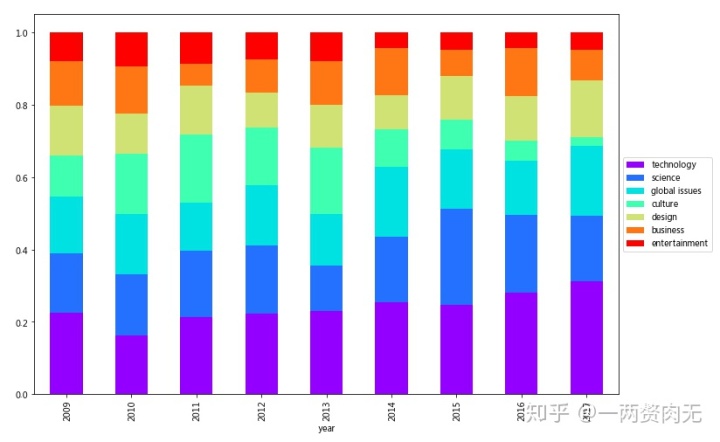
#折线图
ctab[themes].plot(kind='line', stacked=False, colormap='rainbow', figsize=(12,8)).legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()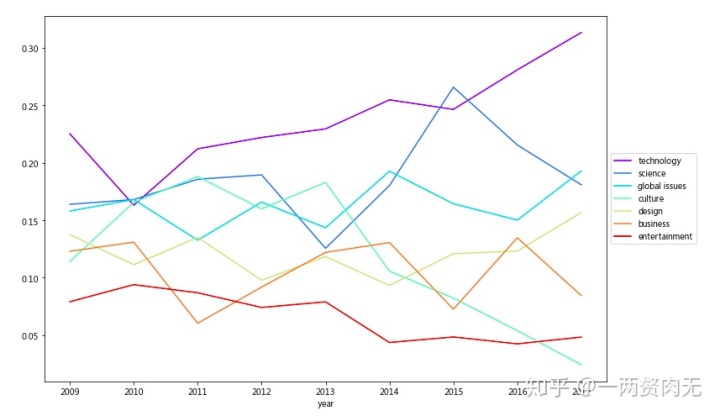
技术类话题的比例在过去几年稳步上升(除2010年略有下降),考虑到区块链,深度学习,AR等新技术的爆发,这是可以理解的;娱乐话题的比例也稳步下降;设计类话题占比稳定,2014年起有缓步提升;文化话题出现了波折,并在2013年后稳步下降,2017年,文化话题的比例已经降到最低。
下面调查一下哪些话题对观众的吸引力更强。我们筛选出含有前10名主题的演讲视频,按主题分类,并绘制盒形图观察不同类别的视频浏览量的分布情况。
# 筛选含有前十名主题的演讲视频
pop_theme_talks = theme_df[theme_df['theme'].isin(pop_themes.head(10)['theme'])]
# 盒形图(按主题分类,看浏览量分布)
fig, ax = plt.subplots(nrows=1, ncols=1,figsize=(15, 8))
sns.boxplot(x='theme', y='views', data=pop_theme_talks, palette="vlag", ax =ax)
ax.set_ylim([0, 0.4e7])(0, 4000000.0)
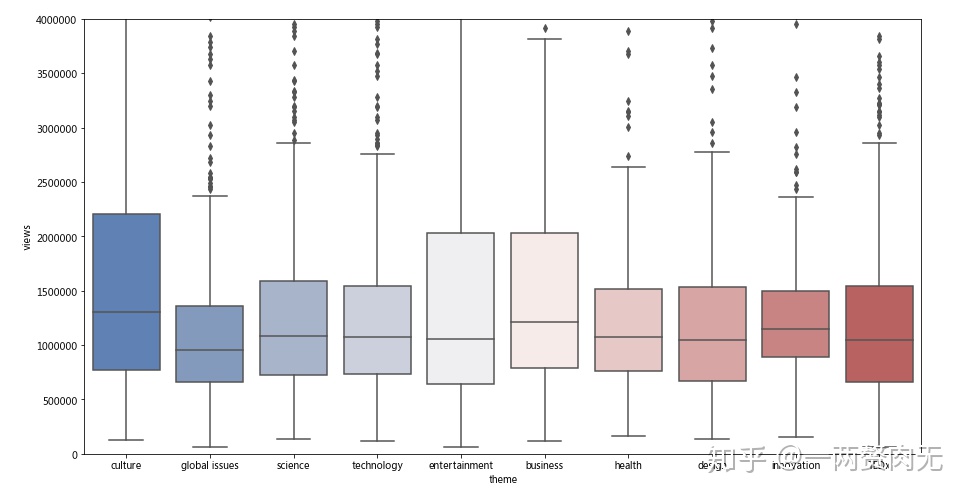
我们可以看出,尽管近年来“文化”主题在TED演讲视频的占比减少,这个主题还是很受欢迎的,其视频浏览量的中位数和上四分位数都高于其他主题。或许TED应该考虑适当增加一些文化类演讲的数量?
TED演讲的时长分析
这一部分,我们分析TED演讲的时长。TED的著名之处在于限制时间的短演讲,一般少于18分钟。
# 将秒转为分
ted['duration'] = ted['duration']/60
#描述性统计
ted['duration'].describe()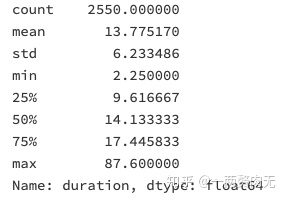
可以看出,TED演讲的平均时长为13.8分钟,最短的演讲为2.2分钟,最长的演讲为87.6分钟(怀疑可能不是TED自己的演讲)。
# 最短的演讲
ted[ted['duration'] == min(ted['duration'])]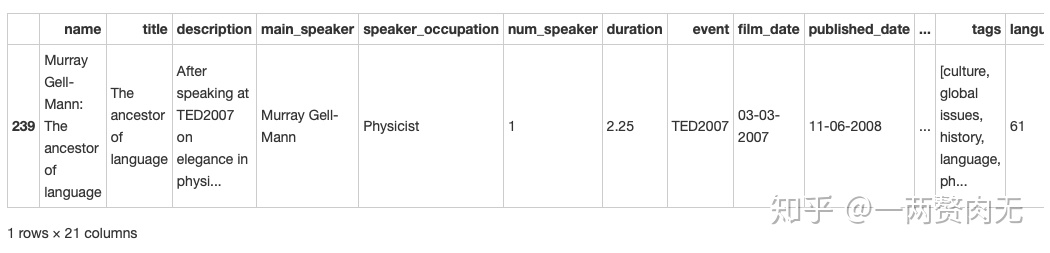
最短的演讲是在TED2007上,由Murray Gell-Mann带来的The ancestor of language.
# 最长的演讲
print(ted[ted['duration'] == max(ted['duration'])]["url"])640 https://www.ted.com/talks/douglas_adams_parrot...
Name: url, dtype: object
最长的演讲并不是TED自己的演讲,而是University of California的活动,在2001年由Douglas Adams带来的Parrots, the universe and everything.
接下来看一下演讲的时长和浏览量是否相关。为了确保我们的研究只有TED相关的活动,我们把演讲时长限制在了25分钟以内。
# 演讲长度和浏览量的相关关系
sns.jointplot(x = 'duration', y='views', data = ted[ted['duration'] < 25])
plt.xlabel('Duration')
plt.ylabel('Views')
plt.show()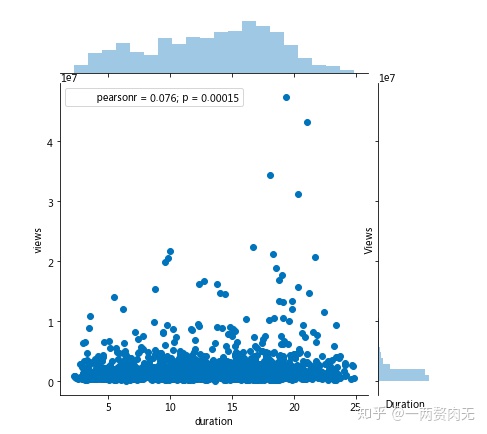
pearson相关系数为0.076,演讲时长和浏览量没有相关关系。看来一个演讲是否受欢迎,还是要看其内容,而非长度。
TED演讲的词汇量分析
接下来,我们引入数据集中的第二个数据transcripts.csv,看一下具体的演讲文本中的词汇量。
trans = pd.read_csv('../input/tedtalk/transcripts.csv')
trans.head()
在上一个数据集中,我们有2550条演讲视频信息,但在本数据集中,只有2467个演讲文本,说明有83个演讲的文本信息缺失,但不影响对文本的分析。
我们通过相同的url将transcripts中的文本信息提取并融合到ted_main中,继续分析。
#将演讲的文本信息与其他主要信息合并在一个dataframe中
df = pd.merge(left = ted,right = trans, how = 'left', left_on = 'url', right_on = 'url')
df.head(2)
#处理na值
df['transcript'] = df['transcript'].fillna('')
# 计算词汇量
df['wc'] = df['transcript'].apply(lambda x: len(x.split()))
# 词汇量分析
df['wc'].describe()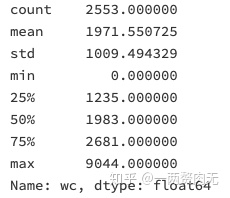
ax = sns.distplot(df['wc'])
ax.set_xlabel('词汇量(Word Count)')
plt.show()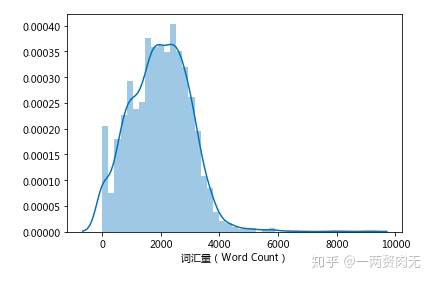
平均每个演讲含有1972个单词,最长的演讲含有9044个单词。标准差很大,有1009个单词。
# 每分钟词汇量 word per minute
df['wpm'] = df['wc']/df['duration']
#每分钟词汇量分析
df['wpm'].describe()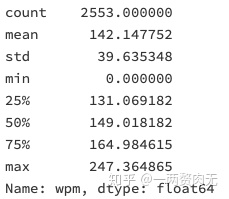
演讲者的平均速度是每分钟142个单词,最快的演讲者每分钟说247个单词,而正常的英语语速度在125-150个单词/每分钟。我们看看是哪个演讲者语速这么快?
# 语速最快的TED演讲
df[df['wpm'] == max(df['wpm'])]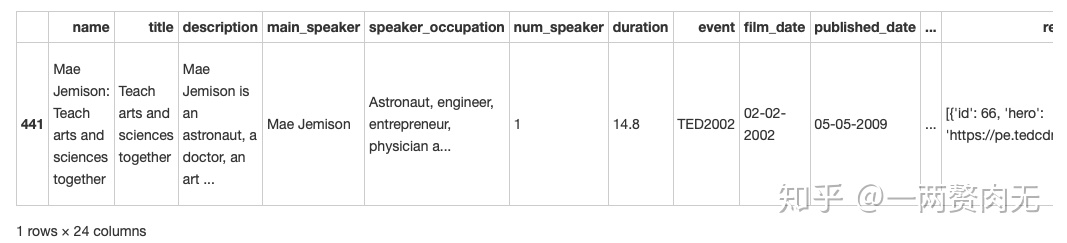
语速最快的TED演讲来自于TED2002,Mae Jemison的 Teach arts and sciences together.
这个结论是值得商榷的,因为如果你点击视频,可以发现该演讲者的语速并没有想象的快。
TED演讲的评价分析
TED允许用户在一系列维度上对演讲视频进行评价。ratings一列的数据是字符串化的列表,列表里包含多个字典,每个字典里面是对数据集的评价(如“有趣”、“励志”、“创新”)以及点赞人数,如下图所示:
# 将ratings栏由字符串转为词典
ted['ratings'] = ted['ratings'].apply(lambda x: ast.literal_eval(x))
#ratings举例
ted.iloc[0]['ratings']
# 评价词都有哪些
rating_words = []
for i in range(len(ted)):
l = ted.iloc[i]['ratings']
for d in l:
if d['name'] not in rating_words:
rating_words.append(d['name'])
rating_words
我们发现每个视频都有同样的14个评价词,用户可以通过点击选择适合的评价词。因此,一个视频越符合评价特征,其相应分数会越高。
最有趣的10个视频
ted[['title', 'main_speaker', 'views', 'published_date', 'funny']].sort_values('funny', ascending = False)[:10]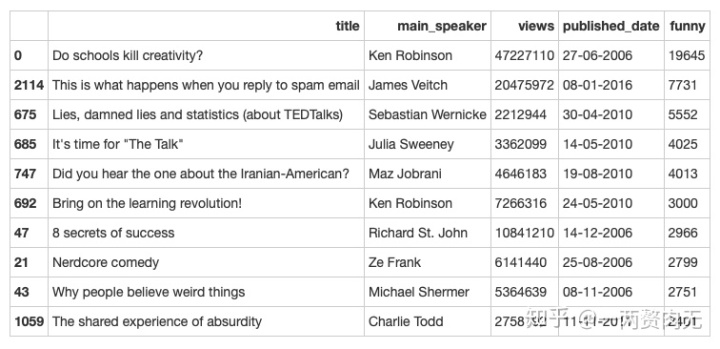
在最有趣的10个视频中,高居榜首的又是我们熟悉的Ken Robinson带来的 Do Schools Kill Creativity?。
所以,TED视频的浏览量和视频有趣程度是否相关呢?
# “有趣”和浏览量的相关关系:
# 相关关系1
sns.jointplot(x = 'views', y='funny', data = ted)
# 相关关系2
sns.jointplot(x = 'views', y='funny', data = ted[ted['views'] < 0.4e7])
plt.show()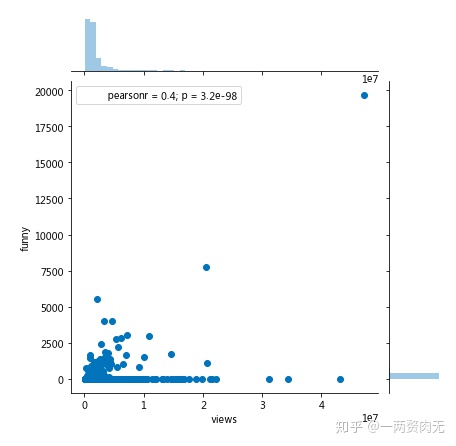
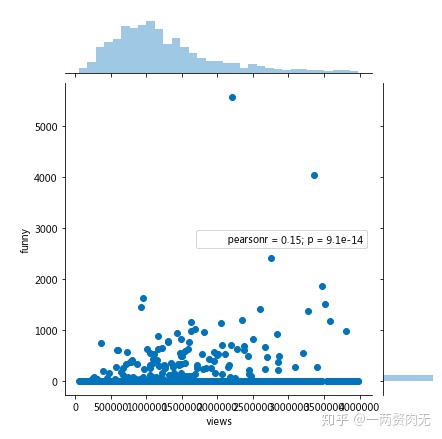
在使用全部数据时,pearson系数为0.4,中度相关;在使用浏览量小于4 million的数据时,pearson系数为0.15,弱相关。但无论如何,视频的有趣程度和播放量还是有一定相关性的。
网络分析:由相关推荐,看TED演讲之间的关联
每一个TED演讲视频,都有一些“其他相关视频推荐”。为了理清各个演讲之间的关系,我们选择网络分析。
构图时,每一个视频单独构成一个点,两个视频之间如果有推荐关系,则添加一条边。
在这里,我们使用networkx库实现画图功能。
# 将related_talks栏由字符串转为词典
ted['related_talks'] = ted['related_talks'].apply(lambda x: ast.literal_eval(x))#将推荐视频单个拆开
s = ted.apply(lambda x: pd.Series(x['related_talks']),axis=1).stack().reset_index(level=1, drop=True)
s.name = 'related'
s.head()
#将修改后的推荐视频列加上
related_df = ted.drop('related_talks', axis=1).join(s)
related_df['related'] = related_df['related'].apply(lambda x: x['title'])
related_df.head(2)
#建立字典,一个演讲对应一个序号
d = dict(related_df['title'].drop_duplicates())
d = {v: k for k, v in d.items()}#把所有的演讲标题转换为代号
related_df['title'] = related_df['title'].apply(lambda x: d[x])
related_df['related'] = related_df['related'].apply(lambda x: d[x])
#演讲标题和推荐标题(显示的应该是代号)
related_df = related_df[['title', 'related']]
related_df.head()

由于每个视频都有相应的推荐视频,这个网络非常的密集。这个图给了我们一个启示:无论演讲的主题多么的多样化,主题之间总会有一些联系。不存在“遗世而独立”的思想,各种科学研究和各行各业之间,都存在着千丝万缕的联系。
TED演讲词汇云图
TED演讲者最常用的词汇有哪些?我们可以创造一个云图来展示,在这里我们使用了WordCloud库。
#把所有演讲文本放在一起,形成语料库
corpus = ' '.join(trans['transcript'])
corpus = corpus.replace('.', '. ')
#建立云图
from wordcloud import WordCloud, STOPWORDS
tedwordcloud = WordCloud(stopwords=STOPWORDS, background_color='white', width=2400,height=2000).generate(corpus)#绘制云图
plt.figure(figsize = (10,10))
plt.imshow(tedwordcloud)
plt.axis('off')
plt.show()
最常见的词汇有one, now, people, know, think, see。看起来TED很强调对人和知识的观察、理解和思考。
参考链接
- TED官网
- TED Data Analysis - from kaggle
转载本文请联系和鲸社区取得授权。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)