人脸检测数据集_人脸数据集:LaPa
Landmark guided face Parsing Dataset (LaPa)是京东人工智能发布的数据集,可用于人脸关键点检测(106个点)和人脸解析(11个类别,包含了背景类)。数据集地址:JDAI-CV/lapa-dataset论文地址:https://aaai.org/ojs/index.php/AAAI/article/view/6832简介:数据集一共有22176张彩色图像,以及

Landmark guided face Parsing Dataset (LaPa)是京东人工智能发布的数据集,可用于人脸关键点检测(106个点)和人脸解析(11个类别,包含了背景类)。
数据集地址:JDAI-CV/lapa-dataset
论文地址:https://aaai.org/ojs/index.php/AAAI/article/view/6832
简介:数据集一共有22176张彩色图像,以及对应的标签图像和关键点信息文件,其中训练集有18176张图像,占比82%;验证集有2000张图像,占比9%;测试集有2000张图像,占比9%。可视化结果,如题图所示。
对应论文提出了一种人脸解析方法,在网络结构和损失函数两个方面,充分利用边界信息(boundary information)。语义分割近一两年发展缓慢,其中有很多工作基于边界信息提升分割,比如SegFix。这篇论文的方法Boundary-attention semantic segmentation(BASS)属于这个角度,其流程如图1所示,看样子跟英伟达的一篇文章相像呢。
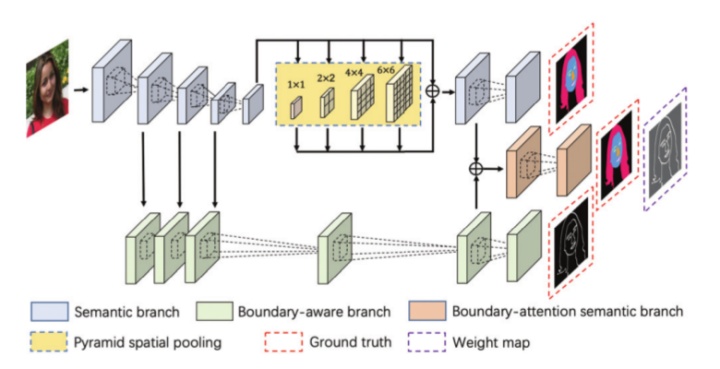
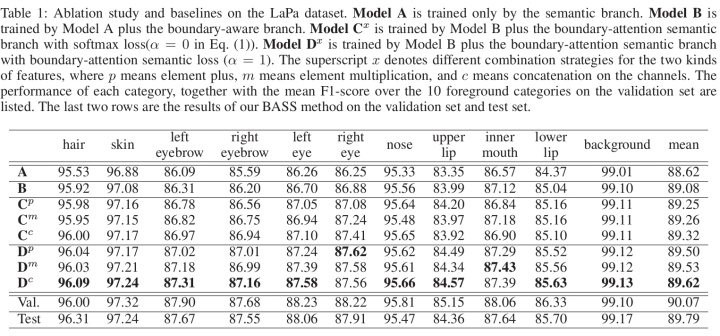
BASS包含3个分支,1) 语义分支semantic branch完成多类别分割,论文使用了ResNet-101,在第5个残差模块后面使用膨胀卷积dilation convolution以减少分辨率信息丢失,还使用了金字塔空间池化pyramid spatial pooling以捕获全局纹理信息;2) 边界感知分支boundary-aware branch完成边界检测;3) 边界注意力语义分支boundary-attention semantic branch融合上述两个网络的特征,融合方法具体就是相加plus(p),相乘multiplication(m)和级联concatenation(c)(the best way),如图2所示。好奇图2为什么还有Val.这一行性能。
损失函数就是3个分支的加权和了。在第3个分支中,损失函数多乘了个加权系数
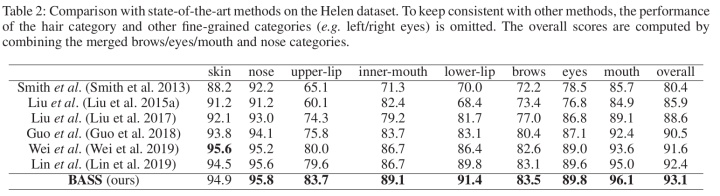
在Helen数据集上,与其他方法进行对比,取得了很高的F1-score,如图3所示。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)