大模型推理:Qwen3 32B vLLM Docker本地部署
使用Docker和vllm在本地部署Qwen3系列模型,同时给出其他模型部署框架参考,比如MindIE、Sglang等
·
Qwen3基础知识
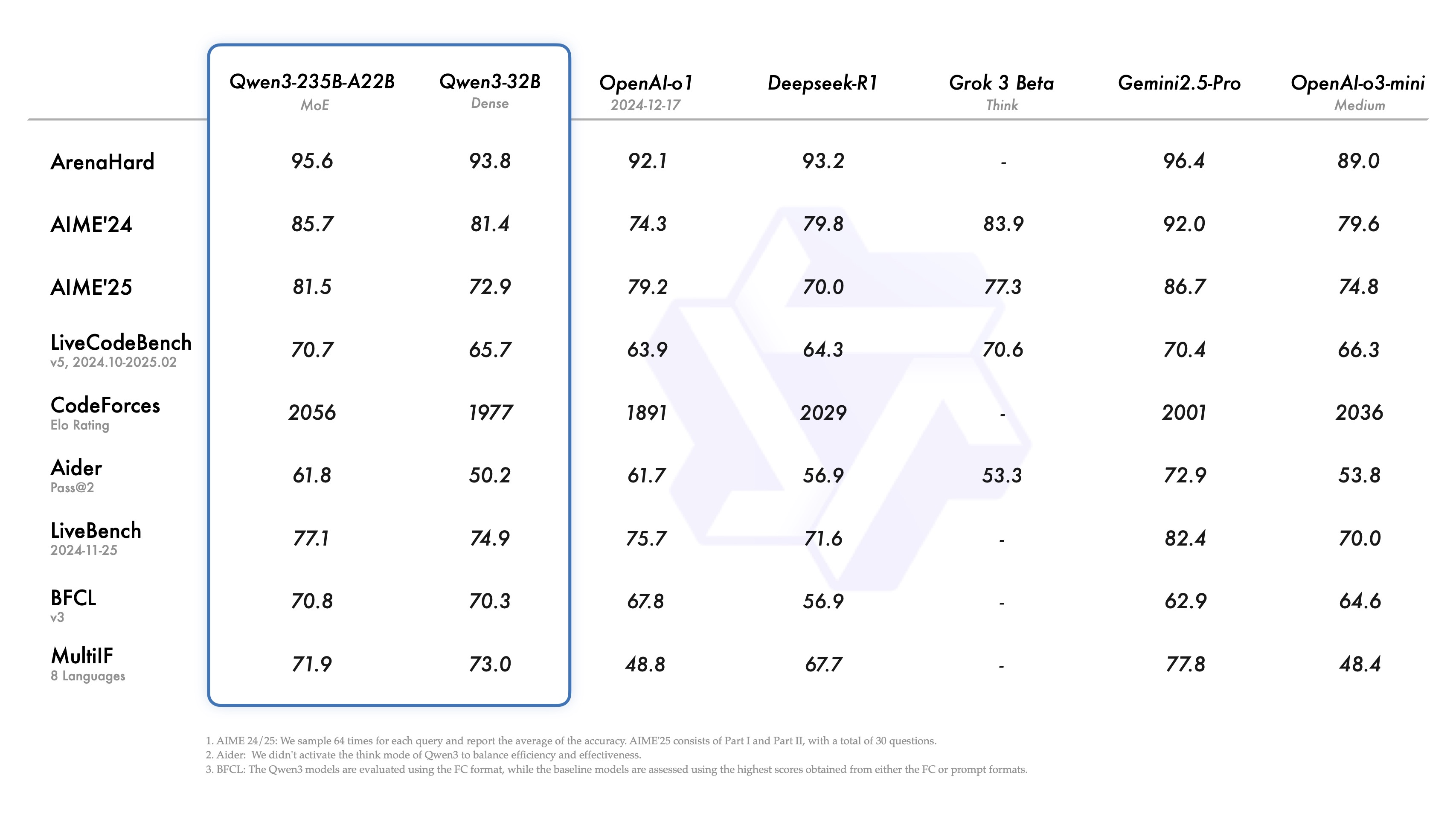
此次Qwen3开源8个模型(MOE架构:Qwen3-235B-A22B、Qwen3-30B-A3B,Dense架构:Qwen3 0.6B/1.7B/4B/8B/14B/32B),新版本的Qwen3特性包括:
- 支持混合思维模式,即推理/非推理一体模型:
- 多语言支持:支持119种语言和方言
- Agent能力提升:加强了编码和Agent表现,并加强了MCP的支持
- 快速体验方式:千问web chat官网
其中,除Qwen3-235B-A22B和Qwen3-32B之外,另外6个模型是蒸馏模型。
各模型版本的参数: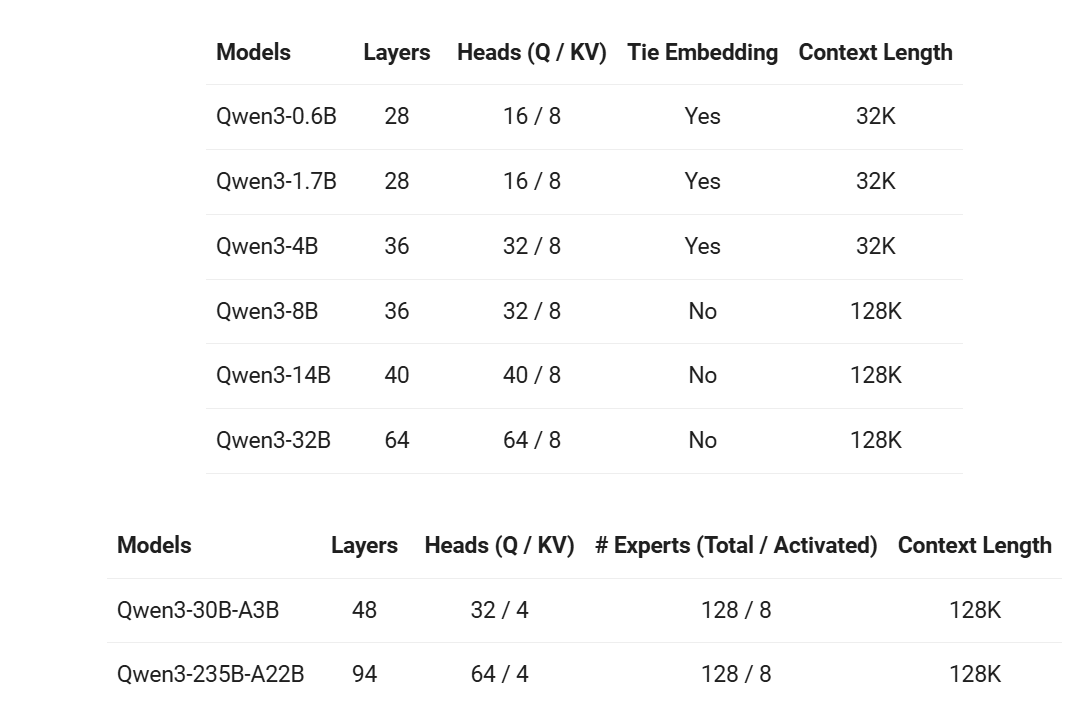
部署环境
- 单机4090 x 4部署BF16格式的Qwen3-32B模型
- 10并发下,最长上下文可支持96k(128k显存不够,就只测96k)
- vLLM docker版本:vllm/vllm-openai:v0.8.5(>=0.8.5)
- 需安装好Docker和Nvidia container toolkit,可参考Ubuntu Nvidia Docker单机多卡环境配置
Docker部署
模型下载:
- 国内推荐魔塔社区Modelscope、hf-mirror,以及魔乐社区modelers
Docker启动命令:
docker run -d --runtime nvidia --gpus 4 --ipc=host -p 8000:8000 -v /root/models:/root/models -e "PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128" --name=Qwen3-32b vllm/vllm-openai:v0.8.5 --model /root/models/Qwen3-32B --trust-remote-code --served-model-name Qwen3-32b --max_num_seqs 10 --tensor-parallel-size 4 --gpu_memory_utilization 0.98 --enforce-eager --disable-custom-all-reduce --enable-auto-tool-choice --tool-call-parser hermes --compilation-config 0 --enable-reasoning --reasoning-parser deepseek_r1 --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":40960}' --max-model-len 98304
参数解释:
- model : 映射到容器的本地模型所在的目录
- served-model-name:模型别名,API等调用时使用
- max_num_seqs:最大并发数
- gpu_memory_utilization:显存利用率
- enable-auto-tool-choice、tool-call-parser:启用tool calling,Qwen系列模型是hermes
- enable-reasoning、reasoning-parser:启用推理模式,并设置参考推理为deepseek_r1(截止当前均为deepseek_r1)
- rope-scaling:模型默认是40k,外推长度参数
- max-model-len:模型支持的上下文长度(Qwen32 B最大支持128k)
使用方式
-
启用推理模式(默认,也就是不指定/think):
官方推荐参数:Temperature=0.6,TopP=0.95,TopK=20,MinP=0, presence_penalty=0~2,不使用greedy decodeing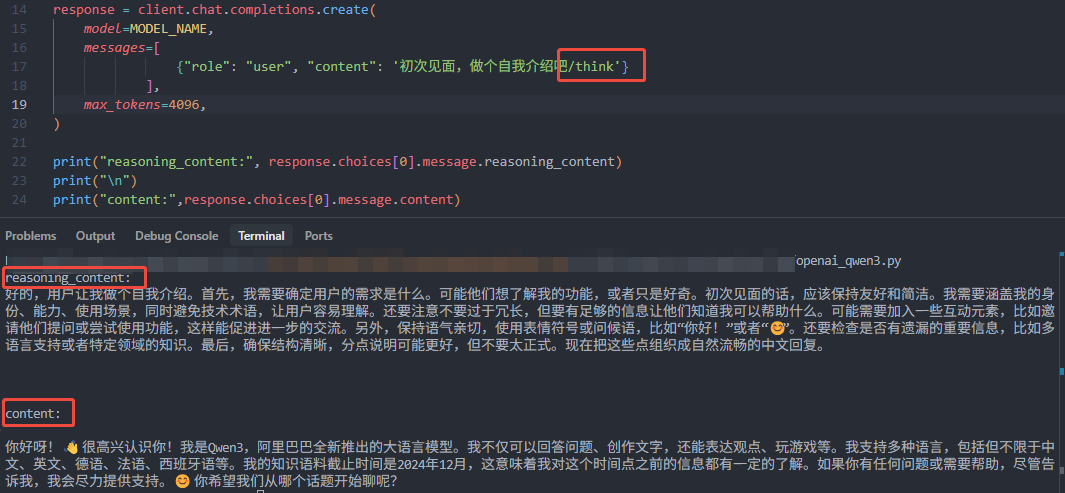
-
启用非推理模式
官方推荐参数:Temperature=0.7,TopP=0.8,TopK=20,MinP=0, presence_penalty=0~2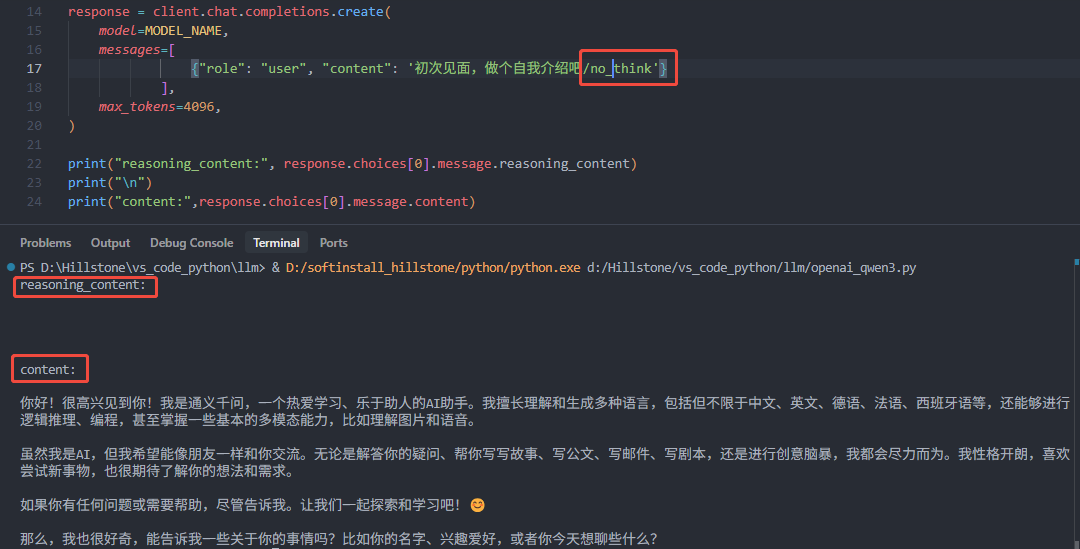
其它部署方式
- Qwen3 Moe架构可选:vllm>=0.8.4,sglang >=0.4.6.post1,Ktransformers>=0.3、ollama >=0.6.6、llamacpp、lm studio(尤其适合Mac M芯片)等
- Qwen3 Dense架构:除上述Ktransformers外,其他均可。
- 国产NPU部署:华为自研的MindIE等
除了上述外,还有像lm deploy、xinference、fastchat等,陆陆续续都会支持。
扩展:Qwen3系列模型训练方式
- Pre-Training,共使用36T Tokens,是Qwen2.5的两倍:
- 阶段1:30T 4k上下文长度的tokens训练,让模型学习语言能力和通用知识
- 阶段2:额外5T tokens训练,包括数学、代码、推理、STEM等类型数据
- 长文本训练:32k上下文的高质量长文本数据训练,提高模型长文本场景能力
- Post-Training,针对Qwen3-235B-A22B和Qwen3-32B模型(其他模型是在base模型蒸馏得到):
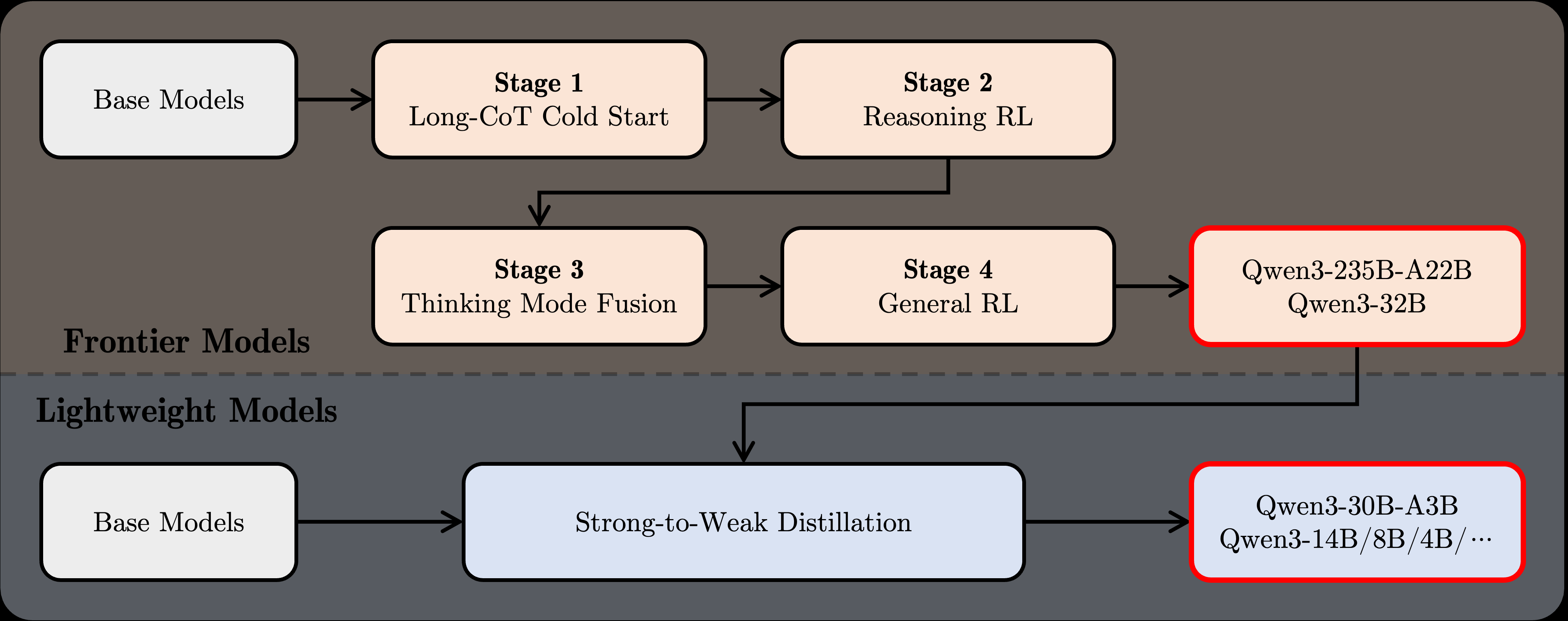
- 长思维链冷启动:使用数学、代码、推理、SEM等数据微调,模型可具有推理能力
- 长思维链强化学习:RL进一步提升模型的推理能力
- 思维模式混合:长推理数据与指令数据微调,模型可具有两种思维模式
- 通用强化学习:使用RL对模型的各项通用能力进行强化提升
扩展阅读
参考文献

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)