【AI大模型部署】Qwen3 性价比新王 Qwen3-30B-A3B 本地私有化部署,可灵活切换思考模式
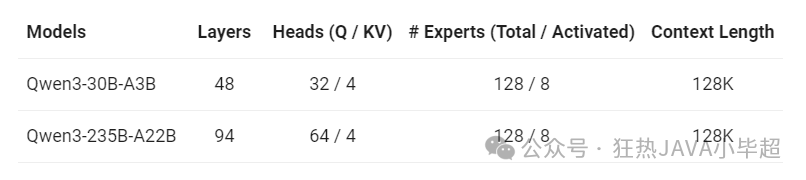
Qwen3 是 Qwen 系列大型语言模型的最新成员。该系列共包含8款模型,2款参数30B、235B的混合专家模型和6款参数0.6B、1.7B、4B、8B、14B、32B的稠密模型,每款模型均获得同尺寸开源模型的最佳性能。
一、Qwen3
Qwen3 是 Qwen 系列大型语言模型的最新成员。该系列共包含8款模型,2款参数30B、235B的混合专家模型和6款参数0.6B、1.7B、4B、8B、14B、32B的稠密模型,每款模型均获得同尺寸开源模型的最佳性能。

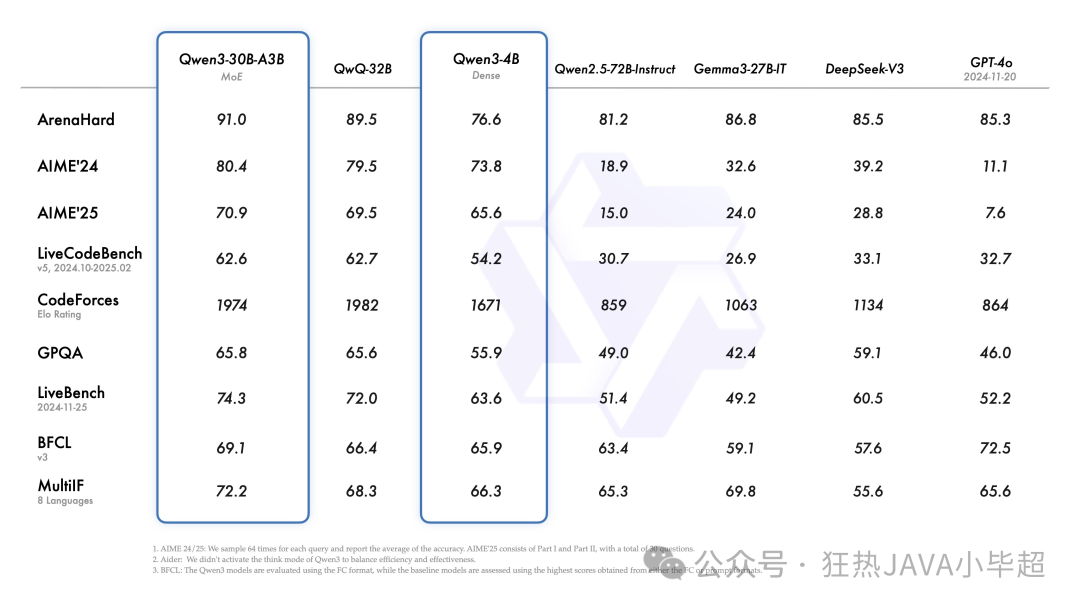
其中旗舰模型 Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,与 DeepSeek-R1、OpenAI-o1、OpenAI-o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。

小型的 MoE 模型 Qwen3-30B-A3B 的激活参数数量是 QwQ-32B 的 10%,表现也更胜一筹,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
Qwen3 模型其中比较有特色的亮点,支持两种思考模式,并且可以灵活切换:
- • 思考模式:在这种模式下,模型会逐步推理,经过深思熟虑后给出最终答案。这种方法非常适合需要深入思考的复杂问题。
- • 非思考模式:在此模式中,模型提供快速、近乎即时的响应,适用于那些对速度要求高于深度的简单问题。
模式的切换无需更换模型,可直接通过 enable_thinking 参数控制,例如:
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking.
)
对于 vLLM 框架,可通过 --reasoning-parser 和 --enable-reasoning 控制思考模式:
vllm serve Qwen/Qwen3-30B-A3B \
--enable-reasoning \
--reasoning-parser deepseek_r1
Qwen3 还提供了软切换机制,允许用户在 enable_thinking=True 时动态控制模型的行为。只需在提示或系统消息中添加 /think 和 /no_think 来逐轮切换模型的思考模式。在多轮对话中,模型会遵循最近的指令。
更多亮点介绍可参考官方 Github:
https://github.com/QwenLM/Qwen3
Qwen3-30B-A3B ModelScope 地址:
https://modelscope.cn/models/Qwen/Qwen3-30B-A3B
Qwen3-30B-A3B huggleface 地址:
https://huggingface.co/Qwen/Qwen3-30B-A3B
本次本地部署 Qwen3-30B-A3B 推理优化框架采用 vLLM ,使用 Open-WebUI 交互测试,依赖的版本如下:
torch==2.5.1+cu118
modelscope==1.23.1
transformers==4.49.0
vllm==0.7.2
二、vLLM 部署 Qwen3-30B-A3B
首先使用 modelscope 下载 QWQ-32B 模型到本地:
modelscope download --model="Qwen/Qwen3-30B-A3B" --local_dir Qwen3-30B-A3B

使用 vLLM 读取模型启动API服务。
export CUDA_VISIBLE_DEVICES=0,1
vllm serve "Qwen3-30B-A3B" \
--host 0.0.0.0 \
--port 8060 \
--dtype bfloat16 \
--tensor-parallel-size 2 \
--cpu-offload-gb 0 \
--gpu-memory-utilization 0.8 \
--max-model-len 8126 \
--api-key token-abc123 \
--enable-prefix-caching \
--enable-reasoning \
--reasoning-parser deepseek_r1\
--trust-remote-code
关键参数说明:
- •
export CUDA_VISIBLE_DEVICES=0,1:指定所使用的GPU。 - •
dtype: 数据类型,其中bfloat16,16位浮点数,适合NVIDIA A100等设备。 - •
tensor-parallel-size:Tensor并行的数量,当多GPU分布式推理时使用,建议和GPU的数量一致。 - •
cpu-offload-gb:允许将部分模型权重或中间结果卸载到CPU的内存中,单位为GB。,模拟GPU内存扩展,如果部署的模型大于了显存大小可以设置该参数,但是推理速度会大大下降。 - •
gpu-memory-utilization:设置GPU内存利用率的上限。 - •
max-model-len:允许模型最大处理的Token数,该参数越大占用显存越大。 - •
enable-prefix-caching:启用前缀缓存减少重复计算。
显存占用情况:
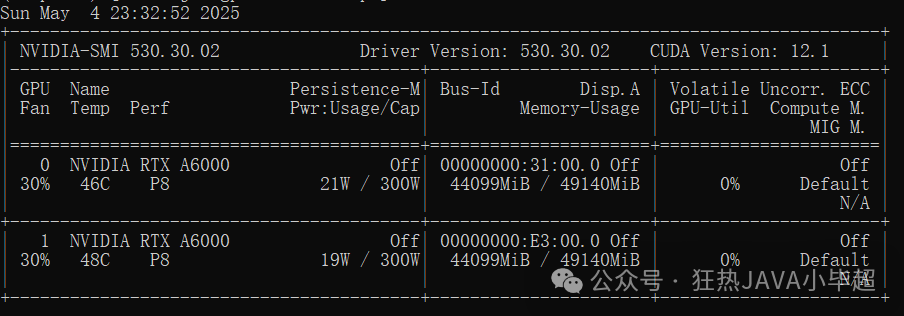
如果启动显存不足,可适当调整 gpu-memory-utilization 和 max-model-len 参数,或通过 cpu-offload-gb 将部分模型权重卸载到内存中。
启动成功后,可通过 /v1/models 接口可查看模型列表:
curl http://127.0.0.1:8060/v1/models -H "Authorization: Bearer token-abc123"

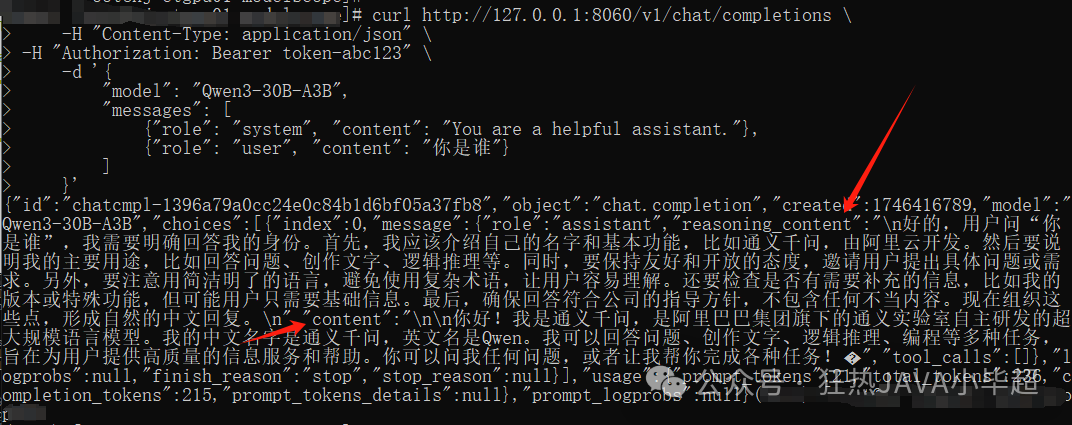
测试API方式交互,默认思考模式:
curl http://127.0.0.1:8060/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "Qwen3-30B-A3B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁"}
]
}'
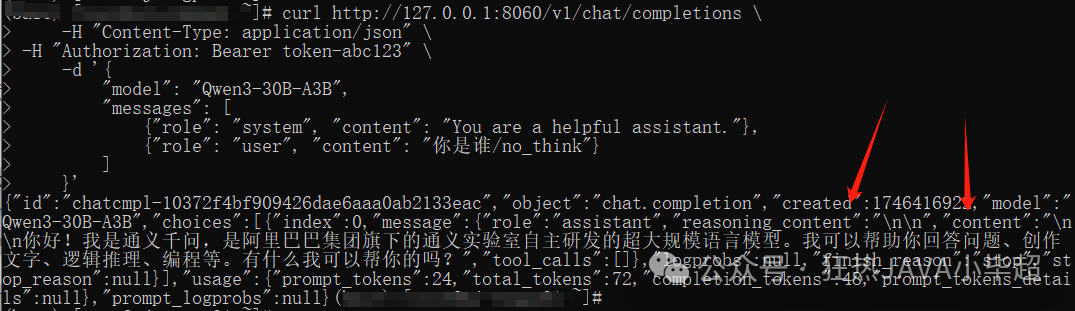
非思考模式测试:
curl http://127.0.0.1:8060/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer token-abc123" \
-d '{
"model": "Qwen3-30B-A3B",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁/no_think"}
]
}'
三、Open-WebUI 交互测试
连接 Qwen3-30B-A3B 模型。
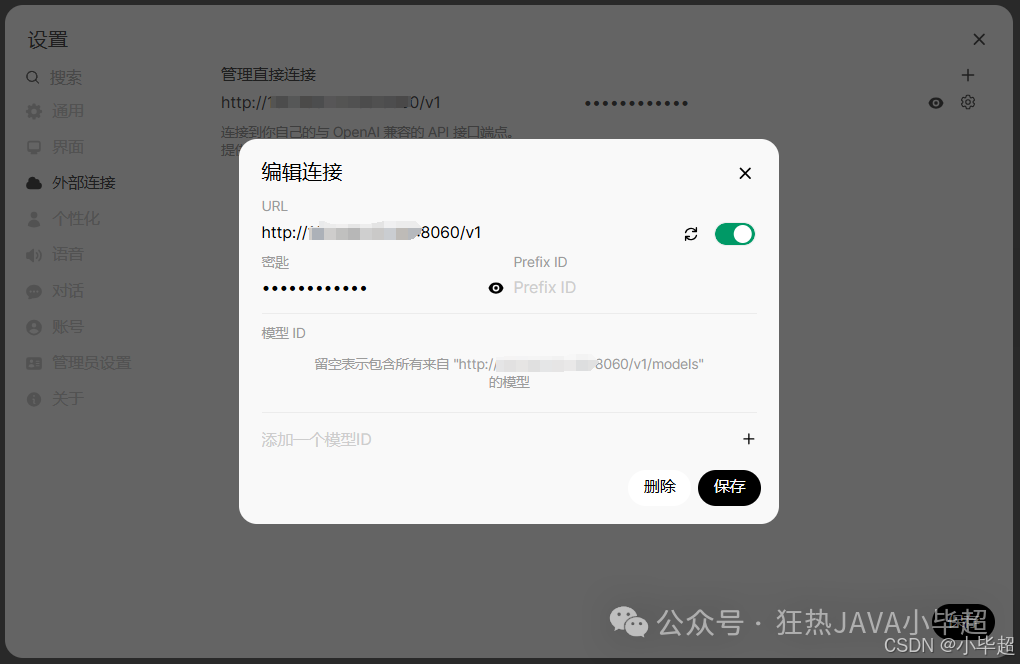
模型ID 可以留空,会自动从 /v1/models 接口中获取。
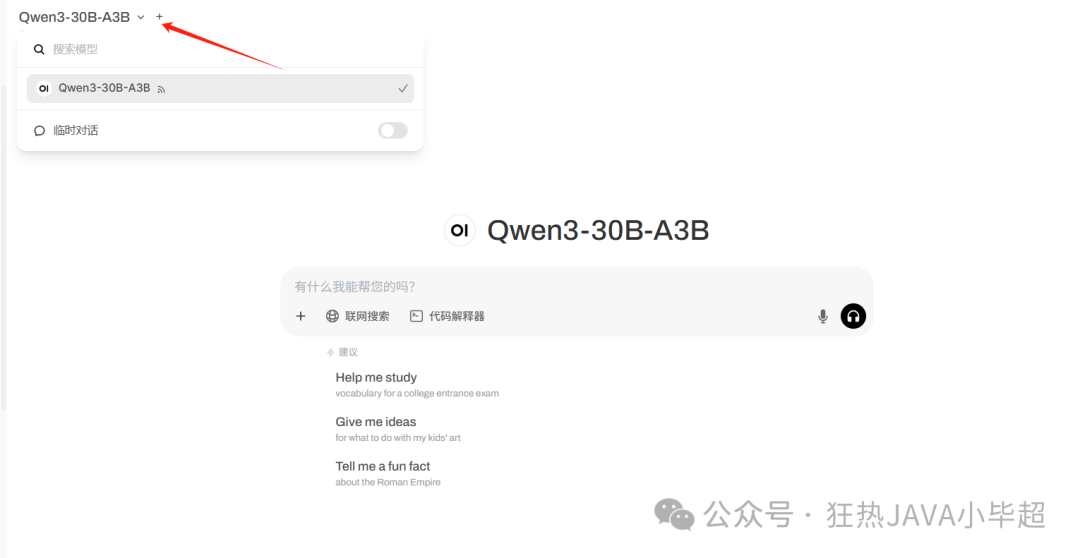
保存后,回到对话窗口, 可在左上角选择 Qwen3-30B-A3B 模型:
对话测试
问题:三人三台三桶水,九人九天几桶水

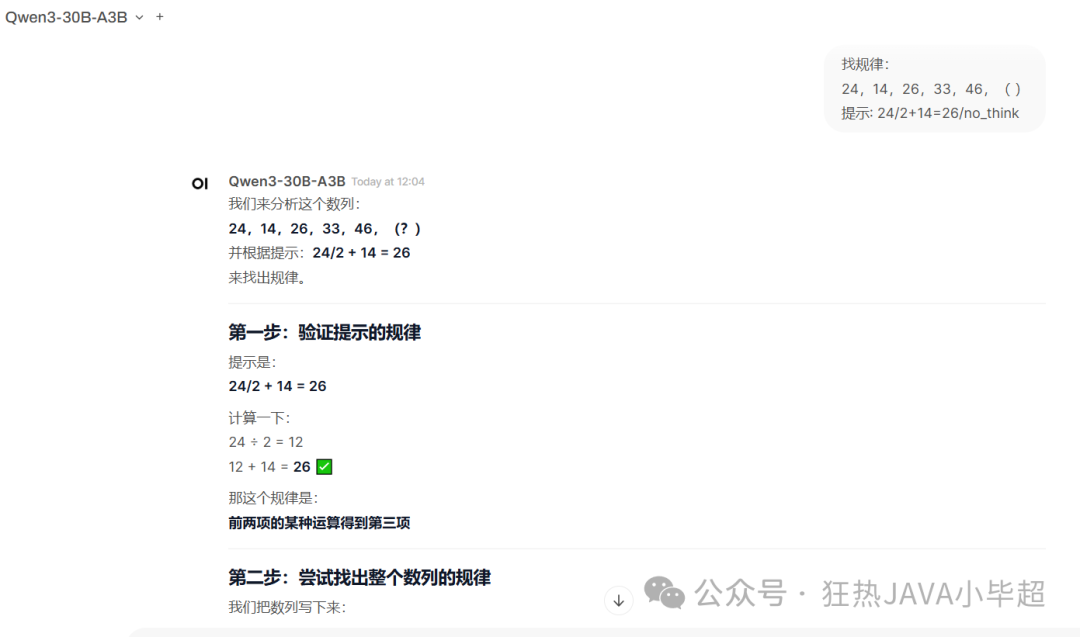
问题:找规律:
24,14,26,33,46,( )
提示: 24/2+14=26/no_think
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 7
7 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)