tensorflow SSD训练自己的数据集
本篇文章是我在自己学习的过程中写的,当作一个笔记,写的比较详细在github上下载SSD的tensorflow版本:https://github.com/balancap/SSD-Tensorflow下载后先解压缩checkpoint:unzip ssd_300_vgg.ckpt.zip用jupyter-notebook 跑一下训练好的模型:jupyter notebook note...
本篇文章是我在自己学习的过程中写的,当作一个笔记,写的比较详细
在github上下载SSD的tensorflow版本:
https://github.com/balancap/SSD-Tensorflow
下载后先解压缩checkpoint:
unzip ssd_300_vgg.ckpt.zip
用jupyter-notebook 跑一下训练好的模型:
jupyter notebook notebooks/ssd_notebook.ipynb
作者在README中已经写了训练的方法,但是为英文,也不是那么详细,本篇针对我训练过程中遇到的一些问题进行处理
一,coco数据集格式转Voc
这里我的数据集是coco格式的,但是训练的是voc格式,需要转化为voc格式,如果本身是voc格式的数据集,可以跳过这一步。
转换方法参考我另一篇博客:
coco数据集和voc数据集的相互转换
二,voc数据集转换为标准的TF_records
1,制作voc标准数据集
转换是根据标准voc数据集进行转换的,所以需改为标准数据集:
建立如下文件夹结构:
将xml文件放到Annotations文件夹下 图片文件放到 JPEGImages文件夹下
voc2020
├── Annotations
│ ├── img_0000004.xml
│ ├── img_0000012.xml
│ ├── img_0000014.xml
└── JPEGImages
├── img_0000004.jpg
├── img_0000012.jpg
├── img_0000014.jpg
├── img_0000034.jpg
├── img_0000043.jpg
2,使用tf_convert_data.py进行转换
打开终端运行python脚本 --dataset_name=pascalvoc这个不变 --dataset_dir=填写Annotations和JPEGImages所在目录 --output_name=随意起 output_dir=输出路径
python3 tf_convert_data.py --dataset_name=pascalvoc --dataset_dir=/root/workspace/dataset/voc2020/ --output_name=bottle_cap --output_dir=/root/workspace/dataset/boottle_tf_records_train/
但是执行后遇到错误:
labels.append(int(VOC_LABELS[label][0]))
KeyError: '标贴歪斜

网上查找解决方案:
打开datasets文件夹下的pascalvoc_to_tfrecords.py文件,修改它的第103行
注释掉原来的, 括号内改为1,即可
#labels.append(int(VOC_LABELS[label][0]))
labels.append(1)#int(VOC_LABELS[label][0])label对应的类别编号,此处直接使用1.没什么特殊意义
继续执行,报错:
labels_text.append(label.encode('ascii'))
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-3: ordinal not in range(128)
这是由于我的标签为中文,需要把pascalvoc_to_tfrecords.py105行改为utf-8:
执行程序: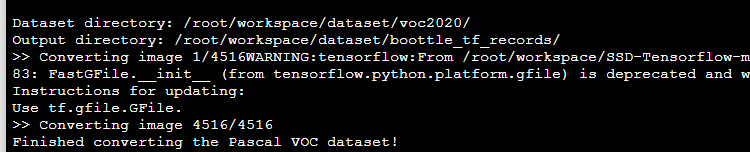
成功!
三.更改相关标签数目为自己的数目
因为原本训练标签数为作者的,所以需要改为自己的标签数:
1.先改:SSD-Tensorflow-master—>datasets—>pascalvoc_common.py 更改类别数: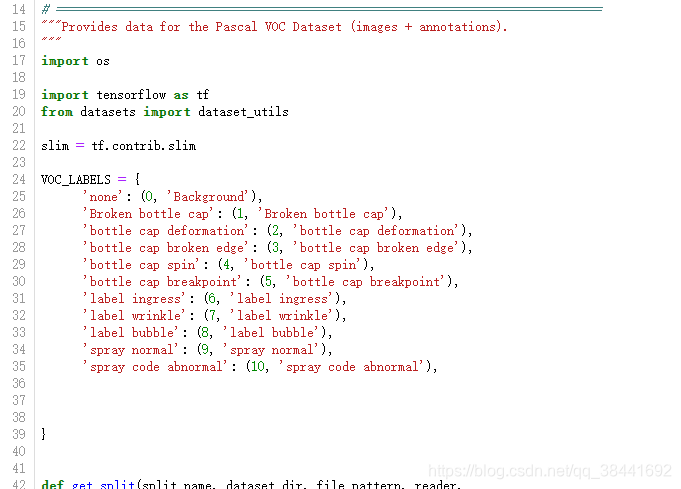
2.更改 train_ssd_network.py这里改为自己的类别数+1(背景也算类别数)
tf.app.flags.DEFINE_integer(
'num_classes', 10, 'Number of classes to use in the dataset.')
3.更改SSD-Tensorflow-master/net/ssd_v300.py
这里 num_classes,no_annotation_label改为类别数+1
default_params = SSDParams(
img_shape=(300, 300),
num_classes=10,
no_annotation_label=10,
4,datasets/pascalvoc_2007.py类别数更改
#这里写你想分割的训练集和测试集
SPLITS_TO_SIZES = {
'train': 5011,
'test': 4952,
}
SPLITS_TO_STATISTICS = {
'train': TRAIN_STATISTICS,
'test': TEST_STATISTICS,
}
5,SSD-Tensorflow-master—>datasets—>pascalvoc_to_tfrecords.py 然后更改文件的83行读取方式为’rb’)
这是由于一个小bug引起的,修改下就行了
四,训练
前面的准备工作已经做完了,可以运行train_ssd_network.py进行训练了
这里是根据vgg300的权重继续训练,写一个sh文件,传入参数运行:
python3 train_ssd_network.py \
--train_dir=/media/comway/data/dial_SSD/SSD-Tensorflow-master/train_log/ \ #训练生成模型的存放路径
--dataset_dir=/media/comway/data/dial_SSD/SSD-Tensorflow-master/dialvoc-train-tfrecords \ #数据存放路径
--dataset_name=pascalvoc_2007 \ #数据名的前缀,我觉得应该通过这个调用是2007还是2012
--dataset_split_name=train \ #是加载训练集还是测试集
--model_name=ssd_300_vgg \ #加载的模型的名字
--checkpoint_path=/media/comway/data/dial_SSD/SSD-Tensorflow-master/checkpoints/ssd_300_vgg.ckpt \ #所加载模型的路径
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--save_summaries_secs=60 \#每60s保存一下日志
--save_interval_secs=600 \ #每600s保存一下模型
--weight_decay=0.0005 \ #正则化的权值衰减的系数
--optimizer=adam \ #选取的最优化函数
--learning_rate=0.001 \ #学习率
--learning_rate_decay_factor=0.94 \ #学习率的衰减因子
--batch_size=16 \
--gpu_memory_fraction=0.9 #指定占用gpu内存的百
这里我是直接改的train_ssd_network.py代码文件进行训练: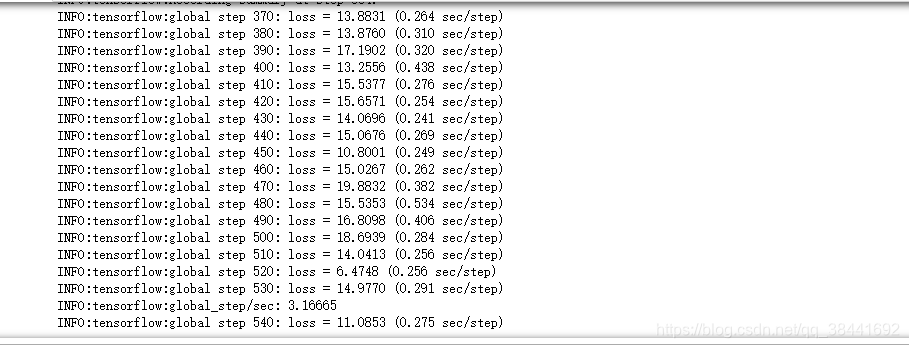

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)