[深度学习]-利用pytorch训练好的VGG16网络实现自定义数据集上的图像分类(含代码及详细注释)
VGG16分类因资源有限只能调用训练好的模型进行图像预测相关代码# 1.读取图片plt.show()plt.show()# 根据输出结果预测标签的后处理类的编写。
前言
本文主要分为两部分:
第一部分大致的介绍了VGG原理
第二部分详细的介绍了如何用pytorch实现VGG模型训练自己的数据集实现图像分类
只想看代码部分的同学,可以直接看第二部分
内容一:VGG原理简介
1.VGG主要工作
2014年的论文,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG主要有两种结构,VGG16和VGG19,两者没有本质上的区别,只是网络深度不一样。
论文地址:VGG论文
2.VGG的主要改进
1)提升卷积网络的深度
2)多个小卷积核代替单个大卷积核
3)多尺度输入
3.多个小卷积核如何替代单个大卷积核
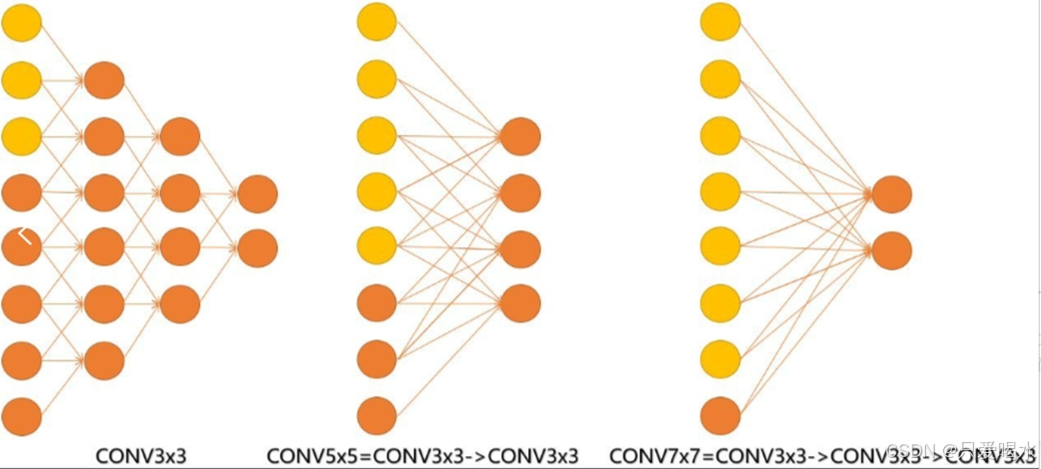
如上图所示,对于最中间的特征图(5*5)来说:
- 一个 5 × 5卷积核卷积后,得到四个特征点
- 使用两个3 × 3卷积核卷积分后,同样得到了四个特征点。
可以看到的是,感受野相同都是5 * 5,但是两个3 * 3卷积核 参数量更少,且小卷积核卷积整合了多个非线性激活层,代替单一非线性激活层,增加了判别能力。
同理使用,3个3x3卷积核来代替7x7卷积核。
4.VGG网络结构
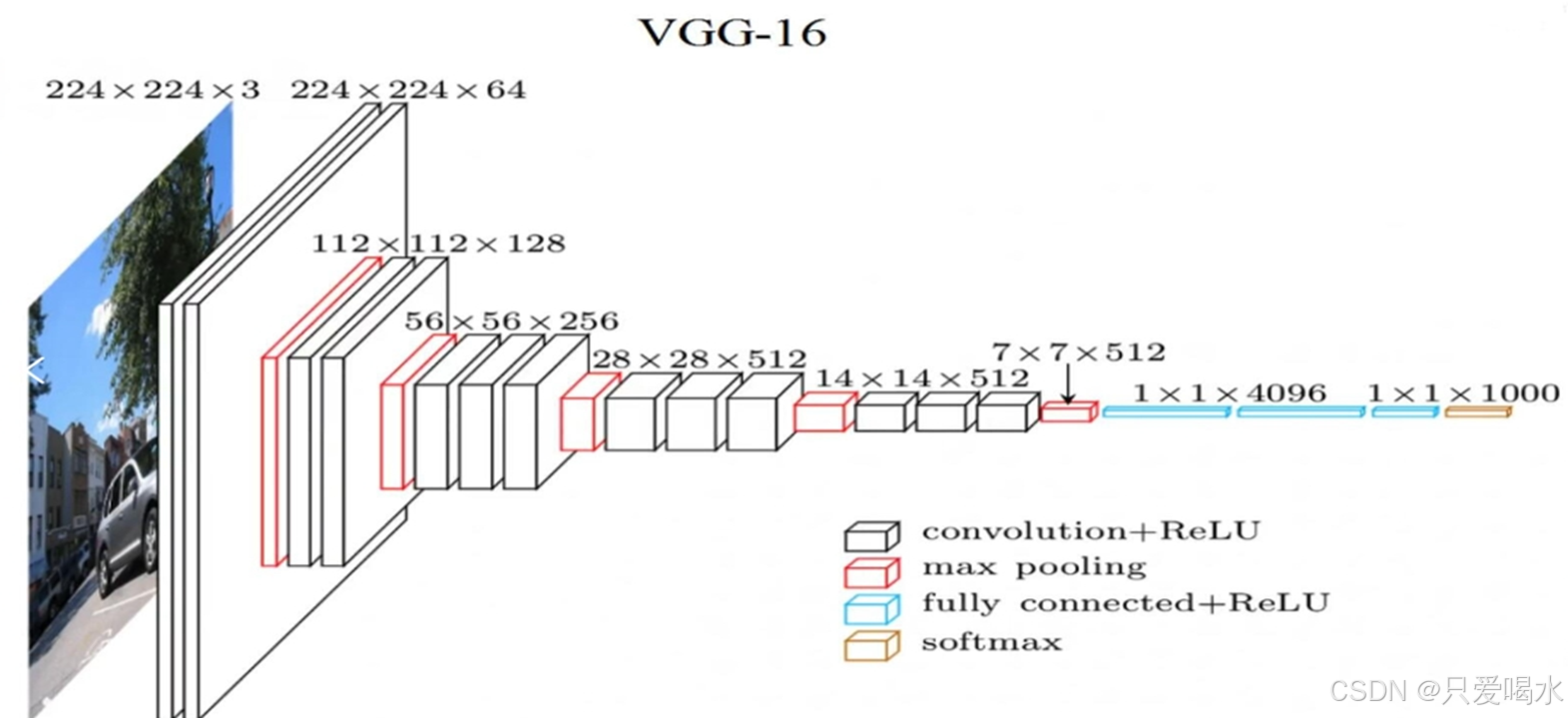
VGG16包含16层,VGG19包含19层。一系列的VGG在最后三层的全连接层上完全一样,整体结构上都包含5组卷积层,卷积层之后跟一个MaxPool。所不同的是5组卷积层中包含的级联的卷积层越来越多。
内容二:pytorch调用已训练好的模型进行自定义图像预测
完整下载github地址:VGG16分类
因资源有限只能调用训练好的模型进行图像预测
1.相关文件下载
官网下载ImageNet数据集编号对应的类别内容文件(1000个类别名称和编号)

2.导入相关模块代码
import numpy as np
import json #解析json文件
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision
from torchvision import models, transforms3.导入已训练好的模型并输出模型
# VGG-16已完成训练模型的载入
use_pretrained = True
net = models.vgg16(pretrained=use_pretrained)
# net = models.resnet50(pretrained=use_pretrained)
net.eval()
# 输出模型的网络结构
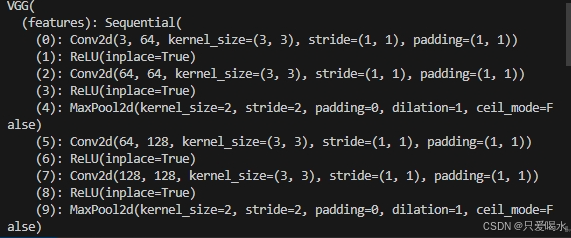
print(net)下图是VGG模型部分层的输出
3.定义一个类对输入图片进行处理(使用的是一张兔子的图像)

相关代码
# 1.读取图片
image_file_path = '/home/dell/CV408/hb/11.jpg'
img = Image.open(image_file_path)
plt.imshow(img)
plt.show()
resize = 224
mean = (0.485, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
transform = BaseTransform(resize, mean, std)
img_transformed = transform(img)
img_transformed2 = img_transformed.numpy().transpose((1, 2, 0))
img_transformed2 = np.clip(img_transformed2, 0, 1)
plt.imshow(img_transformed2)
plt.show()
# 根据输出结果预测标签的后处理类的编写
ILSVRC_class_index = json.load(open('/home/dell/CV408/hb/imagenet_class_index.json', 'r'))
# print(ILSVRC_class_index)4.调用模型进行图像预测
#定义一个类便于函数调用
class ILSVRCPredictor():
def __init__(self, class_index):
self.class_index = class_index
def predict_max(self, out):
maxid = np.argmax(out.detach().numpy())
predicted_label_name = self.class_index[str(maxid)][1]
return predicted_label_name
predictor = ILSVRCPredictor(ILSVRC_class_index) #进行图像预测
inputs = img_transformed.unsqueeze_(0)#0表示在张量最外层加一个中括号变成第一维
out = net(inputs)
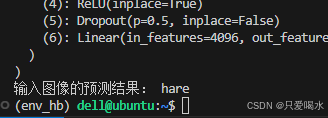
result = predictor.predict_max(out) #根据类别文件输出对应图像的类别名称
print('输入图像的预测结果:', result)预测结果为:hare(野兔)
5.注意事项:
1)如果是在cpu上运行,则运行速度较慢;如果是在GPU上运行速度会快上很多。
2)在运行过程中最好将相关文件打包放入自己在conda上创建的虚拟环境里面,方便后续自己的环境配置
3)对于图像处理模块是相对重要的,对于不同尺寸的图像必须统一成224*224的输入

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)