TeleAI发布TeleChat2.5及T1正式版,双双开源上线魔乐社区!
中国电信开源TeleChat系列大模型,包含35B/115B两种尺寸的复杂推理模型T1和通用问答模型2.5版本。该系列基于昇思MindSpore+vLLM打造,在理科、编程等任务上表现突出。开发者可通过魔乐社区下载模型(需67GB空间),支持Atlas800服务器部署,提供服务化和离线两种推理方式。评测显示模型在数理逻辑、指令遵循等方面有显著提升,现开源四个模型版本供开发者体验。
5月12日,中国电信开源TeleChat系列四个模型,涵盖复杂推理和通用问答的多个尺寸模型,包括TeleChat-T1-35B、TeleChat-T1-115B、TeleChat2.5-35B和TeleChat2.5-115B,实测模型性能均有显著的性能效果。TeleChat系列模型基于昇思MindSpore+vLLM打造,现已上线魔乐社区,欢迎广大开发者下载体验!
开源链接:
https://modelers.cn/models/MindSpore-Lab/T1-35B
https://modelers.cn/models/MindSpore-Lab/T1-115B
https://modelers.cn/models/MindSpore-Lab/TeleChat2.5-35B
https://modelers.cn/models/MindSpore-Lab/TeleChat2.5-115B
01 模型介绍
1 TeleChat T1模型
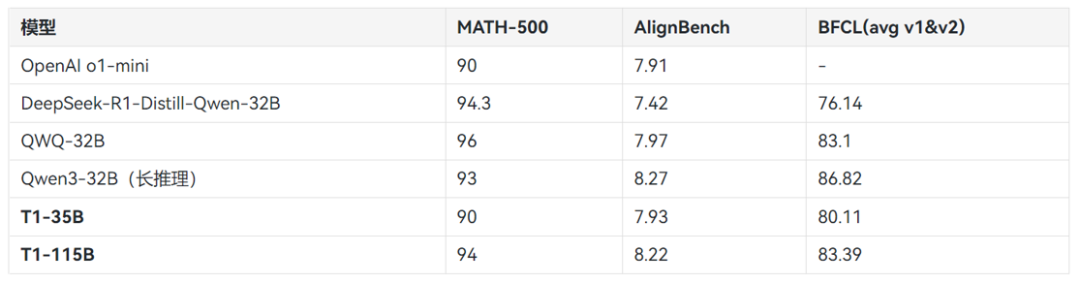
T1 模型是 TeleChat 系列专注于复杂推理的模型,由中国电信人工智能研究院研发训练。该系列模型借助先进的思维推理和批判纠错能力,在下游复杂任务中有很好的表现。本次中国电信开源了 T1-35B 和 T1-115B 两款不同尺寸的模型,与同尺寸模型相比都具有较好的效果表现。
训练策略
采用课程学习贯穿全流程的后训练方案,循序渐进提升模型效果。
-
微调阶段:将多任务数据集进行难度划分(根据模型推理正误比率判断),首先使用中低难度冷启动微调,然后使用RFT方式筛选中高难度数据进行持续微调进行效果提升;
-
强化学习阶段:首先对数理逻辑、代码能力进行提升,采用难度渐进式课程学习方案进行能力强化;然后,基于指令遵循、安全、幻觉、Function Call等10多种混合通用任务进行持续强化,全面提升模型效果。
效果评测
2 TeleChat2.5模型
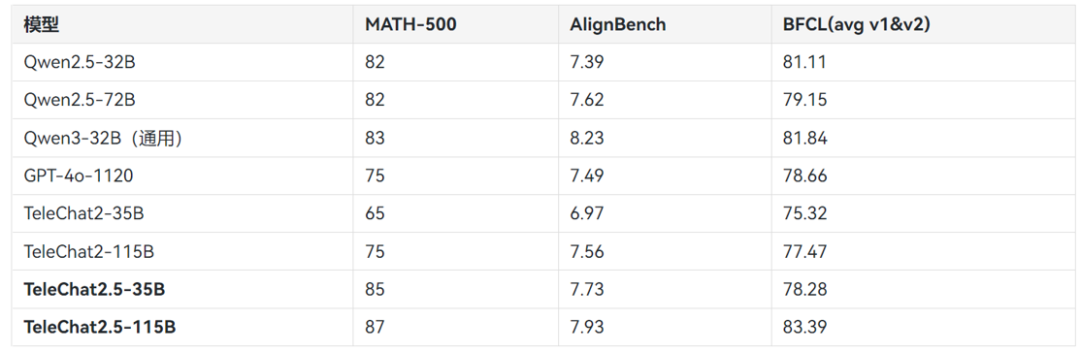
TeleChat2.5 是 TeleChat 系列新版通用问答模型,由中国电信人工智能研究院(TeleAI)研发训练,包括了 TeleChat2.5-35B 与 TeleChat2.5-115B。TeleChat2.5 基于最新强化的 TeleBase2.5 系列模型进行训练,在理科、通用问答、Function Call等任务上有显著的效果提升。TeleChat2.5 的微调方法延续了 TeleChat2 系列,具体请参考 TeleChat2(https://github.com/Tele-AI/TeleChat2)。
训练策略
数据
-
为了提高模型训练数据的数量和质量,TeleChat2.5 在训练过程中采用了大量理科学科和编程领域的合成数据。在合成过程中,为了减少错误信息的引入,主要以基于知识点或知识片段的教育类知识合成为主。
基础模型训练
-
TeleChat2.5 采用了多阶段课程学习策略,在训练过程中逐步提升理科和编程类高密度知识数据的比例。每个训练阶段都使用比前一阶段质量更高、难度更大的数据,以实现持续的模型优化。
-
在最终训练阶段,为了平衡模型在各个维度的能力表现,选取了不同训练阶段效果较优的多个模型,并基于各模型的综合表现进行参数加权融合,其中权重分配与模型性能呈正相关。
后训练阶段
TeleChat2.5采用分阶段优化的模型训练策略:
-
融合优化阶段:整合复杂推理与通用问答能力,针对语言理解、数理逻辑等薄弱任务进行解构重组。通过重构任务框架并融合多维度解题思路,生成优化后的通用答案集。此阶段答案长度会适度增加,并基于优化数据实施微调训练。
-
能力强化阶段:针对数理逻辑与编程类任务,通过注入结构化解题思路,结合基于规则的强化学习奖励机制,显著提升模型对复杂任务的理解与处理能力。
-
泛化提升阶段:面向安全合规、指令响应、函数调用、数学推理、代码生成等十余种任务类型进行系统性强化学习增强,全面提升模型的通用任务处理能力。
效果评测
以下为手把手教程:(以T1-35B模型为例)
02 快速开始
T1-35B 推理至少需要1台(2卡)Atlas 800T A2(64G显存规格)服务器。昇思MindSpore提供了T1-35B 推理可用的Docker容器镜像,供开发者快速体验。
1 模型下载
|
社区 |
下载地址 |
|
魔乐社区 |
https://modelers.cn/models/MindSpore-Lab/T1-35B |
执行以下命令为自定义下载路径/home/teleAI/T1-35B添加白名单:
export HUB_WHITE_LIST_PATHS=/home/teleAI/T1-35B执行以下 Python 脚本从魔乐社区下载昇思 MindSpore 版本的 T1-35B 文件至指定路径 /home/teleAI/T1-35B (需提前pip安装openmind_hub库,相关参考文档可参考:openMind Hub Client使用教程(https://modelers.cn/docs/zh/openmind-hub-client/0.9/overview.html))。下载的文件包含模型代码、权重、分词模型和示例代码,占用约 67GB 的磁盘空间:
from openmind_hub import snapshot_downloadsnapshot_download(repo_id="MindSpore-Lab/T1-35B",local_dir="/home/teleAI/T1-35B",local_dir_use_symlinks=False,)
下载完成的模型文件夹目录结构如下:
T1-35B/├── config.json # 模型json配置文件├── configuration_telechat2.py├── generation_config.json├── generation_utils.py├── modeling_telechat2.py├── special_tokens_map.json├── tokenization_telechat2.py├── tokenizer.model # 词表model文件├── tokenizer_config.json # 词表配置文件├── model-000xx-of-000xx.safetensors # 模型权重文件└── model.safetensors.index.json # 模型权重映射文件
注意事项:
-
/home/teleAI/T1-35B 可修改为容器可访问的自定义路径,确保该路径有足够的磁盘空间(约 67GB)。
-
下载时间可能因网络环境而异,建议在稳定的网络环境下操作。
2 下载昇思 MindSpore 推理容器镜像
执行以下 Shell 命令,拉取昇思 MindSpore T1-35B 推理容器镜像:
docker pull swr.cn-central-221.ovaijisuan.com/mindformers/mindspore_telechat_t1:202504303 启动容器
执行以下命令创建并启动容器:
docker run -it -u 0 --ipc=host --network host \
--name vllm_telechat_t1 \
--privileged \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /var/log/npu/:/usr/slog \
-v /home/:/home \
swr.cn-central-221.ovaijisuan.com/mindformers/mindspore_telechat_t1:20250430 \
/bin/bash注意:
-
若模型下载目录不在 /home/ 路径下,需要在 docker run 命令中映射相关的路径(修改-v /home/:/home \),使容器可以访问对应路径中的文件;
-
启动容器前,通过 npu-smi info 查看服务器状态,确保卡资源未被其他进程占用。
-
后续所有操作均在容器中进行。
本文提供两种推理使用方式:服务化部署及离线推理,用户可按需使用。
03 服务化部署
说明: 在服务化部署模式下,启动一次vLLM推理服务后,可重复多次发送推理请求。
1 配置环境变量:
export MINDFORMERS_MODEL_CONFIG=/usr/local/Python-3.11/lib/python3.11/site-packages/research/telechat2/predict_telechat_35b.yaml2 一键启动vLLM推理
在服务器上执行以下命令启动vLLM推理服务:
python3 -m vllm_mindspore.entrypoints vllm.entrypoints.openai.api_server --model "/home/teleAI/T1-35B" --port=8000 --trust_remote_code --tensor_parallel_size=2 --max-num-seqs=256 --max_model_len=8192 --max-num-batched-tokens=8192 --block-size=32 --gpu-memory-utilization=0.93注意: 其中/home/teleAI/T1-35B需要修改为实际的模型目录
看到以下日志打印,说明vLLM推理服务启动成功:
INFO: Started server process [xxxxx]INFO: Waiting for application startup.INFO: Application startup complete.
3 执行推理请求测试
执行以下命令发送推理请求进行测试:
curl http://localhost:8000/v1/completions
-H "Content-Type: application/json" -d '{
"model": "/home/teleAI/T1-35B",
"prompt": "<_system><_user>生抽与老抽的区别?<_bot><think>\n",
"max_tokens": 2048,
"temperature": 0.6,
"repetition_penalty":1.05,
"top_p":0.95
}'推理请求报文配置注意事项:
-
model: 需要配置为实际的网络权重路径。
-
prompt: 模板需保持固定,以确保推理时能够生成 reason 过程。可将其中文字部分修改为其他的推理请求问题。
-
max_tokens:字段为推理输出最大token长度,可按需修改。
-
temperature:建议保持0.6不变
-
top_p:建议保持0.95不变
-
repetition_penalty:在推理通用任务时,建议使用1.05,可以有效减少重复生成现象;在推理数学、代码任务时,建议使用1.0。
推理结果:
嗯,用户问生抽和老抽的区别。首先,我得回忆一下这两种酱油的基本信息。
生抽,我记得是用发酵后的酱油醅提取的,颜色比较浅,味道比较鲜。通常用来炒菜或者凉拌菜,增加鲜味。
老抽的话,应该是用生抽再加入焦糖色或其他色素制成的,颜色更深,呈棕褐色,味道相对较咸,鲜味不如生抽明显。老抽的主要用途是给食物上色,比如在红烧肉类、卤味或者调色时使用,让菜肴看起来更有食欲。
不过,可能有些细节需要确认。比如,老抽是否真的添加了焦糖色?不同品牌的做法是否一致?另外,生抽和老抽在酿造工艺上的具体区别是什么?是否都经过了发酵过程,只是提取的方式不同?
还有,用户可能想知道在实际烹饪中如何合理使用这两种酱油,以达到最佳的味道和颜色效果。例如,在炒青菜时,只需用少量生抽提鲜;而在做红烧肉时,则需要在翻炒肉块后加入老抽,使肉块均匀上色,之后再加入生抽和其他调料继续炖煮,这样既能保证肉质的鲜嫩,又能使菜肴的颜色看起来非常诱人。
总结一下,生抽和老抽的主要区别在于颜色、味道和使用场景。生抽颜色浅、味道鲜,主要用于提鲜和调色;老抽颜色深、味道咸,主要用于给食物上色,使菜肴看起来更加诱人。在实际烹饪中,合理搭配使用这两种酱油,可以显著提升菜肴的口感和视觉效果。
</think>
生抽与老抽是常见的酱油种类,它们在颜色、味道和使用场景上有显著区别:
### **1. 颜色差异**
- **生抽**:颜色较浅,呈红褐色或琥珀色。
- **老抽**:颜色更深,呈棕褐色或黑褐色,类似焦糖色。
### **2. 味道差异**
- **生抽**:味道偏鲜,含较多氨基酸,常用于提鲜。
- **老抽**:味道偏咸,鲜味较弱,主要作用是上色。
### **3. 使用场景差异**
- **生抽**:
- 炒菜、凉拌菜(如青菜、豆腐、凉拌鸡等)。
- 腌制食材(如腌黄瓜、泡菜等)。
- 蘸食(如白灼虾、蒸鱼等)。
- **老抽**:
- 上色(如红烧类、卤味类、酱烧类等)。
- 调色(如制作汤底、酱料,或需要深色的菜肴)。
- 少量提味(虽然主要作用是上色,但少量使用可以增加菜肴的层次感)。
### **4. 烹饪技巧**
- **生抽**:
- 避免过量使用,以免掩盖食材本身的鲜味。
- 在凉拌菜中,可先将生抽与香油、蒜末等混合,再淋在食材上,这样味道更均匀。
- **老抽**:
- 上色时,应早加入锅中,并翻炒均匀,使食材均匀上色。
- 避免在收汁阶段加入老抽,否则可能导致颜色过深,且不易均匀分布。
- 在制作红烧类菜肴时,可将老抽与生抽、糖、料酒等调味料提前调成汁,再倒入锅中与食材一同烧制,这样能更好地控制调味料的用量和火候,使菜肴的味道更加协调。
### **总结**
生抽与老抽的核心区别在于**颜色深浅**和**味道鲜咸**。生抽颜色浅、味道鲜,主要用于提鲜和轻上色;老抽颜色深、味道咸,主要用于重上色和轻微提味。在烹饪实践中,合理搭配使用这两种酱油,能够显著提升菜肴的口感层次和视觉吸引力。04 离线推理
说明:在离线推理模式下,无需事先启动推理服务,每次执行推理脚本均会单独执行推理过程输出结果。
1 配置环境变量:
export MINDFORMERS_MODEL_CONFIG=/usr/local/Python-3.11/lib/python3.11/site-packages/research/telechat2/predict_telechat_35b.yaml2 执行以下离线推理python脚本:
import vllm_mindspore
from vllm import LLM, SamplingParams
from mindformers import AutoTokenizer
if __name__ == "__main__":
model='/home/teleAI/T1-35B' # 指定模型路径
tokenizer = AutoTokenizer.from_pretrained(model, trust_remote_code=True)
sampling_params = SamplingParams(temperature=0.6, repetition_penalty=1.05, max_tokens=8192)
llm = LLM(model=model, trust_remote_code=True, tensor_parallel_size=4)
prompt = "生抽与老抽的区别?"
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = llm.generate([text], sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r},
Generated text: {generated_text!r}")脚本说明:
-
T1 系列模型在 chat template 中加入了<think>\n符号以确保推理时能够生成 reason 过程。推理脚本会自动在推理起始拼接<think>\n符号,此时输出结果会缺少开头的<think>\n符号。
-
model 需要配置为实际的模型路径。
-
sampling_params 推理参数配置:
1、在推理数学、代码任务时,建议使用repetition_penalty=1.0, temperature=0.6, top_p=0.95的推理设置。
2、在推理通用任务时,建议使用repetition_penalty=1.05, temperature=0.6, top_p=0.95的推理设置,可以有效减少重复生成现象。
-
prompt 可修改为其他推理问题。
3 推理结果
嗯,用户问生抽和老抽的区别。首先,我得确认自己对这两个调味品的了解是否正确。
生抽,我记得主要是用于炒菜和凉拌的。它的颜色较浅,呈红褐色,味道比较咸,但带有一定的鲜味,因为通常含有谷氨酸钠(味精)。
然后是老抽,主要用于给食物上色,比如红烧、卤味等。老抽的颜色更深,呈深红或黑红色。味道方面,老抽比生抽更咸,且鲜味相对较少,因为有些老抽可能不含味精,或者含量较低。
接下来,用户可能还关心的是,这两种酱油在烹饪时的具体应用,以及它们对菜肴风味和色泽的影响。此外,可能还需要提到一些关于酱油制作的传统工艺,比如发酵时间、原料配比等,这些都会影响生抽和老抽的最终风味和质地。
不过,在回答用户的问题时,需要保持回答的简洁性和针对性,避免过于冗长或偏离主题。因此,在总结生抽和老抽的区别时,应该重点突出它们在颜色、用途、风味等方面的不同,同时也可以简要提及它们在烹饪中的具体应用场景,以及它们对菜肴整体风味和视觉效果的影响。
最后,在确保回答准确无误的基础上,可以用一种较为亲切和自然的方式将这些信息呈现给用户,让用户能够轻松理解并记住生抽和老抽之间的主要区别。
</think>
生抽与老抽都是常见的酱油品种,但它们在颜色、用途、风味等方面有显著区别:
---
### **1. 颜色差异**
- **生抽**:颜色较浅,呈红褐色或琥珀色。
- **老抽**:颜色深,呈深红、黑红或接近黑色。
---
### **2. 用途差异**
- **生抽**:主要用于日常炒菜、凉拌、蘸食等,提鲜增香。
- **老抽**:主要用于给菜肴上色,例如红烧、卤味、酱烧等,使菜品色泽更诱人。
---
### **3. 风味差异**
- **生抽**:味道较咸,但带有明显的鲜味(因含谷氨酸钠,即味精)。适合直接用于调味。
- **老抽**:味道更咸,鲜味相对较弱(部分老抽可能不含味精)。由于主要用于上色,因此在调味时通常不会直接使用老抽,而是在出锅前少量淋入以增色。
---
### **4. 存储方式**
- 两种酱油均需存放在阴凉干燥处,避免高温和阳光直射,以免加速变质或损失风味。
---
### **总结对比表**
| 特性 | 生抽 | 老抽 |
|--------------|----------------------------|----------------------------|
| **颜色** | 浅红褐色 | 深红/黑红色 |
| **用途** | 炒菜、凉拌、蘸食 | 上色(红烧、卤味等) |
| **风味** | 咸鲜味,含味精 | 咸味为主,鲜味较弱 |
| **存储** | 阴凉干燥处 | 同上 |
通过以上对比,可以清晰地理解生抽与老抽在烹饪中的不同角色和用途。昇思MindSpore AI框架将持续支持相关主流模型演进,并根据情况向全体开发者提供镜像与支持。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 12
12 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)