vLLM & Ray 分布式推理模型部署
通过 vllm 和 ray 结合,使用 4 台 A10 显卡 部署 qwen2.5 14b 全参数推理模型。实现分布式推理模型部署的方法。解决单机单卡显存不够,模型推理效率低等问题。
一、 背景
近年来,大型语言模型(LLMs)发展迅猛,深刻影响各行业。然而,庞大的模型规模带来了推理挑战,如高计算成本和延迟。为解决这些问题,vLLM 创新性地提出 PagedAttention 机制,显著提升推理效率。同时,Ray 作为高性能分布式计算框架,能够轻松实现推理任务的横向扩展。
本篇博客将探讨如何结合 vLLM 和 Ray 构建高性能、可扩展的分布式 LLM 推理模型部署方案。我们将深入讲解环境搭建、模型加载、推理服务构建和性能优化等关键技术。旨在帮助读者掌握利用 vLLM 和 Ray 部署 LLM 推理模型的实践方法,为 LLM 的广泛应用提供技术支撑。
二、 介绍 vLLM 和 Ray 框架
2.1 vLLM:高效LLM推理引擎
vLLM是由加州大学伯克利分校团队开发的高吞吐量LLM推理框架,其核心创新在于PagedAttention内存管理机制。该技术解决了传统LLM部署中的关键瓶颈——显存碎片化和利用率不足的问题。
技术亮点:
-
内存优化:采用操作系统级别的分页思想,实现KV Cache的灵活分配与共享
-
连续批处理(Continuous Batching):动态合并不同长度的请求,显著提升GPU利用率
-
高性能解码:支持多种解码策略(并行/波束搜索等),吞吐量比HuggingFace Transformers提升最高24倍
-
生态兼容:支持HuggingFace模型权重,与OpenAI API协议兼容
典型应用场景:实时聊天系统、批量文本生成、API服务后端等需要高并发推理的场景。
2.2 Ray:分布式计算框架
Ray是UC Berkeley RISELab开发的分布式执行框架,其核心设计目标是让Python应用能轻松实现分布式扩展。在LLM时代,Ray凭借其独特的架构优势成为分布式推理的首选平台:
核心特性:
-
弹性任务调度:全局统一的任务调度器,支持毫秒级任务启停
-
无状态Actor模型:简化分布式编程范式,支持动态扩缩容
-
共享内存:通过Plasma对象存储实现零拷贝数据共享
-
异构资源管理:可同时管理GPU/CPU等异构计算资源
关键技术组件:
-
Ray Core:基础分布式运行时
-
Ray Serve:可扩展模型服务库
-
Ray Data:分布式数据流水线
2.3 推理模型框架分析对比
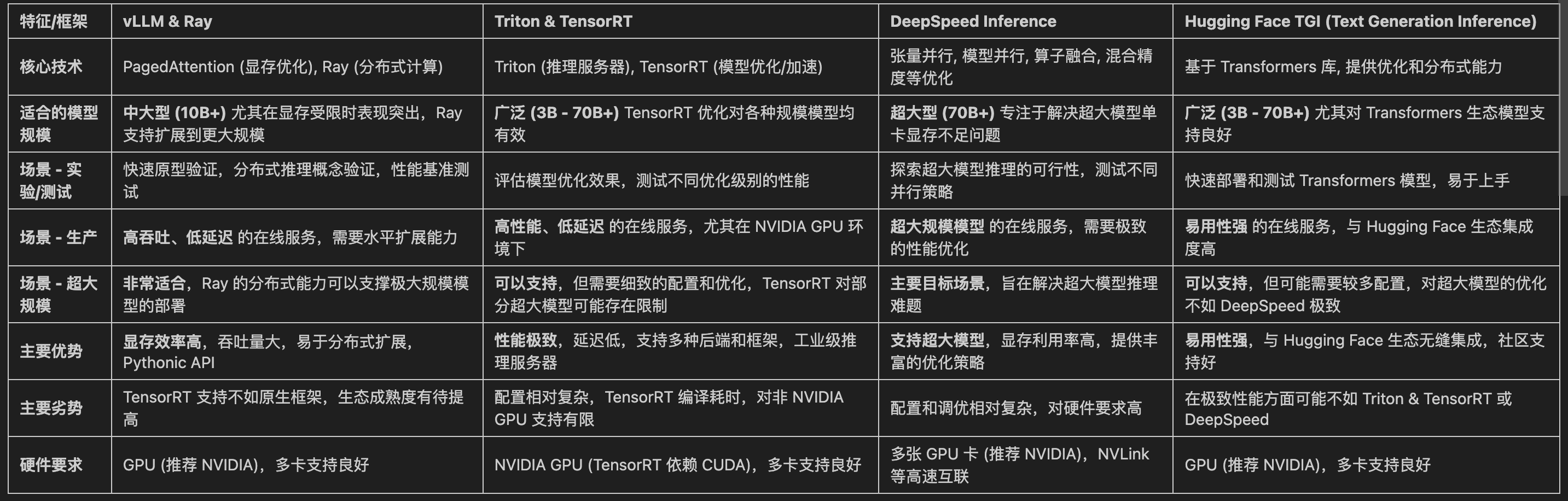

三、 vLLM & Ray (qwen2.5 14b全参数)
3.1 资源申请准备
雅加达地区 4台 ECS (16C 60Gi 内存 120Gi 磁盘 A10 显卡)
具体申请流程请参考:
3.2 基础环境部署
sudo apt update && sudo apt upgrade -y
sudo apt install -y git curl wget unzip build-essential unzip rsync pdsh
sudo hostnamectl set-hostname --static "te1"
echo "172.18.81.126 te1" >> /etc/hosts
echo "172.18.81.127 te2" >> /etc/hosts
echo "172.18.81.128 te3" >> /etc/hosts
echo "172.18.81.129 te4" >> /etc/hosts
3.3 跨节点授信访问
vim /etc/ssh/sshd_config
PasswordAuthentication yes
systemctl restart sshd## 配置节点密码 最好是都配置成一样的
passd# 主节点 te1执行 授信访问
cd ~/.ssh
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te3
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te42) 节点配置可用密码 ssh 登录访问
验证pdsh 跨节点访问问题
pdsh -S -w te1,te2,te3,te4 hostname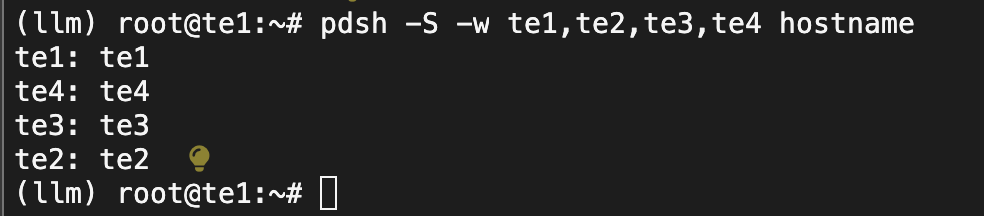
3.4 conda python环境准备
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /data/Miniconda3.sh
bash /data/Miniconda3.sh -b -p /data/miniconda3
mkdir -p /data
echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
source /data/miniconda3/bin/activate
source ~/.bashrc
conda create -n vllm python=3.10 -y
conda activate vllm
echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
echo 'source /data/miniconda3/bin/activate' >> ~/.bashrc
echo 'conda activate vllm' >> ~/.bashrc
source ~/.bashrc# 安装基础依赖
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 这里我就直接安装默认的,如果有特殊需要可以指定版本
# 比如pip install vllm==0.3.3 ray==2.10.0
pip install vllm ray torch transformers3.5 部署 Ray 集群
在不同的节点上执行
## te1主节点
export VLLM_HOST_IP=te1
ray start --head --node-ip-address=te1 --port=6379 \
--num-gpus=1 \
--resources='{"node:te1": 1}'##te2 节点
export VLLM_HOST_IP=te2
ray start --head --node-ip-address=te2 --port=6379 \
--num-gpus=1 \
--resources='{"node:te2": 1}'##te3 节点
export VLLM_HOST_IP=te3
ray start --head --node-ip-address=te3 --port=6379 \
--num-gpus=1 \
--resources='{"node:te3": 1}'##te4 节点
export VLLM_HOST_IP=te4
ray start --head --node-ip-address=te4 --port=6379 \
--num-gpus=1 \
--resources='{"node:te4": 1}'# 查看状态
ray status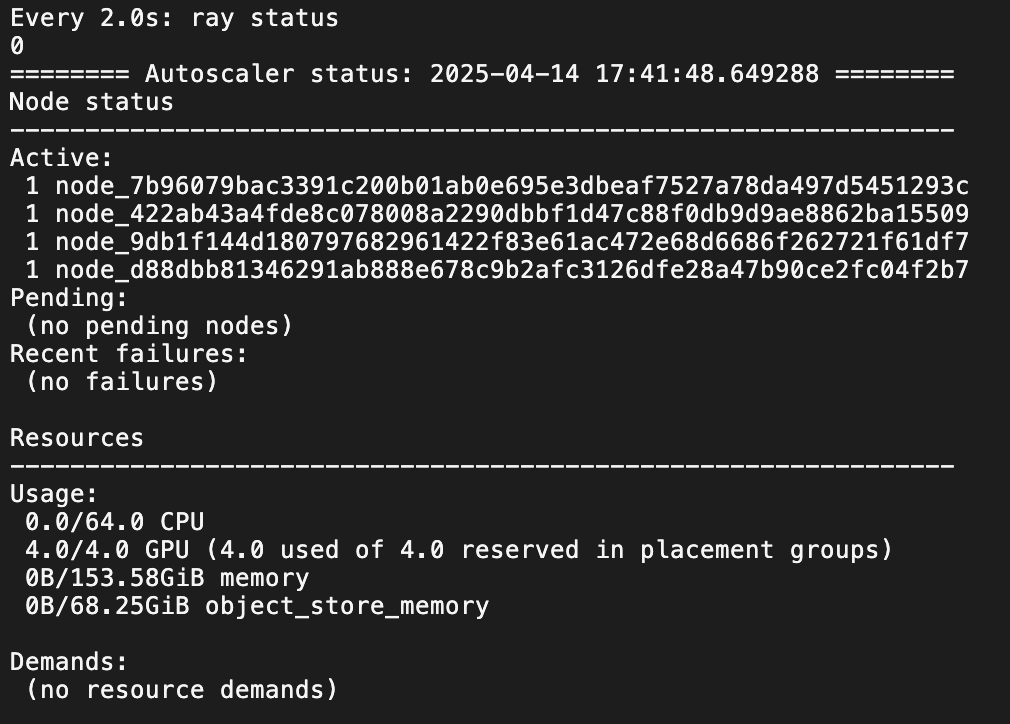
## 查看节点状态
ray list nodes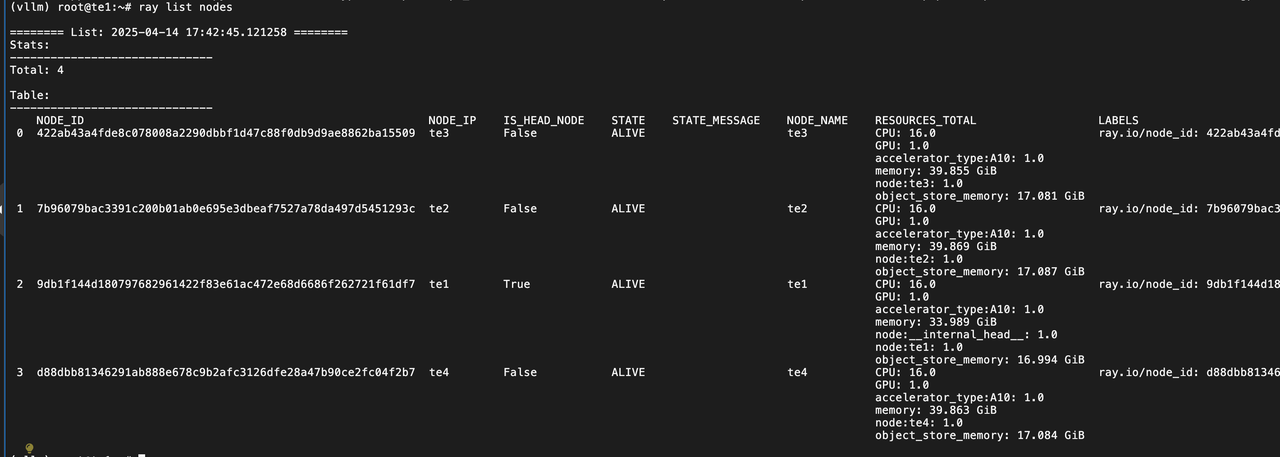
3.6 vllm 部署 qwen 2.5 14b 全参数模型
模型并行有两种方式Tensor Parallelism (TP,张量并行)和Pipeline Parallelism (PP,流水线并行)。我这里只采用了TP方式并禁用了流水线并行,张量并行 4。主要是为了测试简单直观。也可以采用 TP 和 PP 混合的方式部署,这个也是可以尝试的。

查看模型的参数:
huggingface-cli download Qwen/Qwen2.5-14B \
config.json \
--repo-type model \
--resume-download \
--local-dir qwen2.5-14b-config \
--local-dir-use-symlinks False{
"architectures": [
"Qwen2ForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151643,
"hidden_act": "silu",
"hidden_size": 5120,
"initializer_range": 0.02,
"intermediate_size": 13824,
"max_position_embeddings": 131072,
"max_window_layers": 48,
"model_type": "qwen2",
"num_attention_heads": 40,
"num_hidden_layers": 48,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-05,
"rope_theta": 1000000.0,
"sliding_window": 131072,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.43.1",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 152064
}
注意力头的数量: "num_attention_heads": 40,
num_attention_heads必须是的tensor-parallel-size张量并行度的整数倍。
运行 vllm 部署命令:
python -m vllm.entrypoints.openai.api_server \
--model /data/models/qwen2.5-14b \
--tensor-parallel-size 4 \
--pipeline-parallel-size 1 \
--trust-remote-code \
--gpu-memory-utilization 0.75 \
--max-num-seqs 64 \
--max-model-len 4096 \
--host 0.0.0.0 \
--port 8000 \
--disable-log-requests
3.7 测试验证
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "/data/models/qwen2.5-14b","max_tokens":"256" ,"temperature": "0.7","prompt": "世界上最高的山峰是哪个?"}' | jq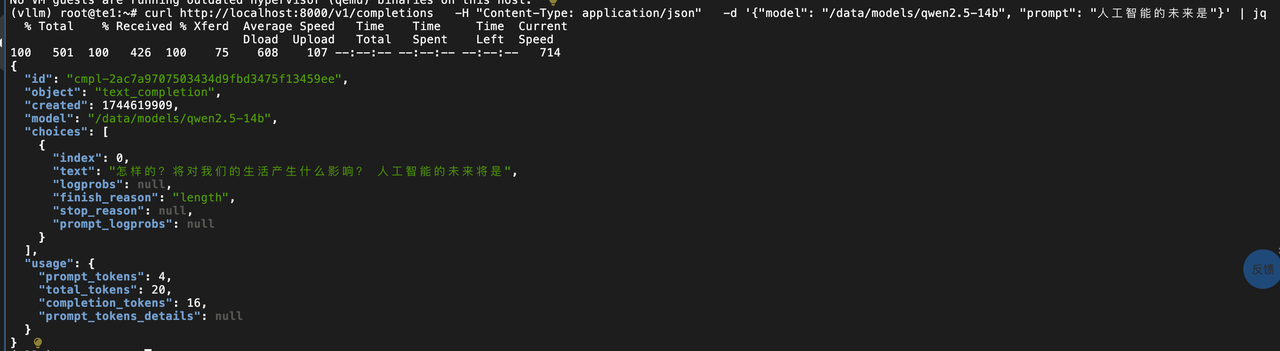
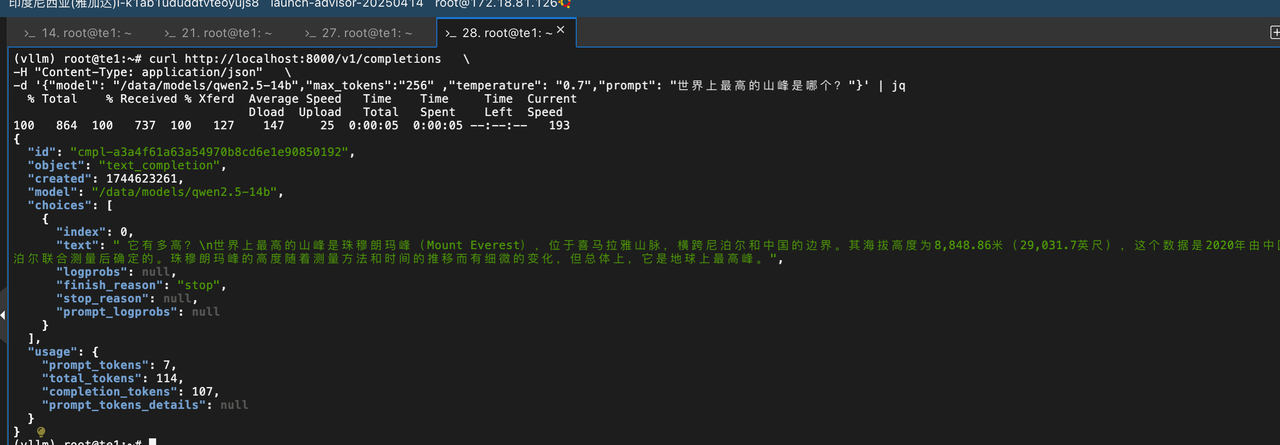
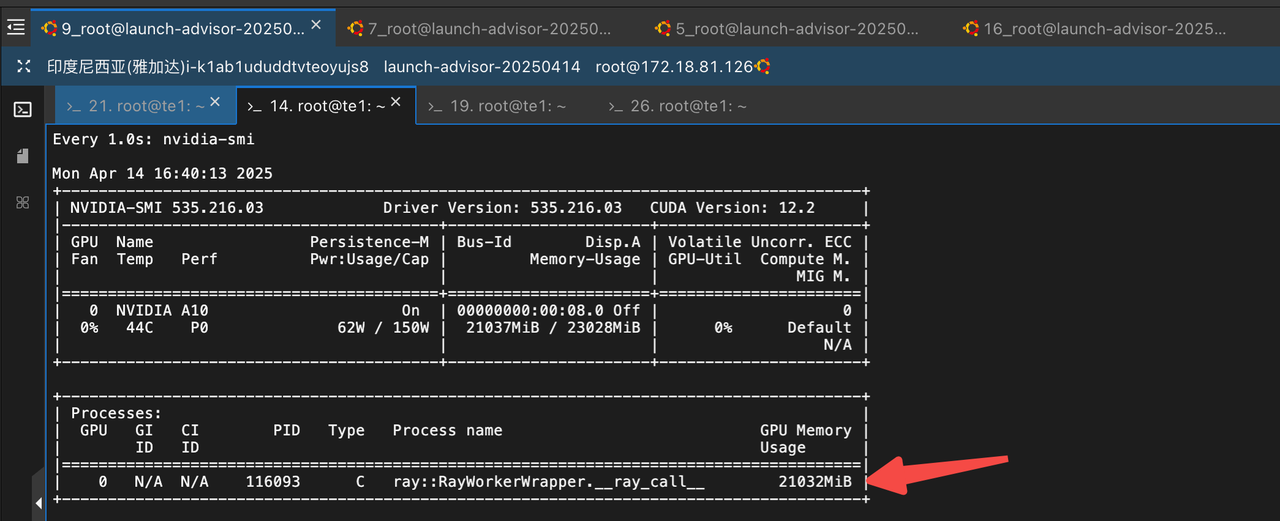
部分资源消耗情况 :
四、小结
Ray 和 vLLM 的使用还是比较简单的,遇到的问题比较少。应该来说解决了一些小坑然后就是很顺畅的实验完毕。完成 4 节点单机单卡 A10,全参数部署 Qwen2.5 14B的推理部署。后续希望都在 Kubernetes 容器上去做尝试。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)