0day同步!昇思MindSpore框架成功适配面壁MiniCPM4.0模型并上线魔乐社区
6 月 6 号,面壁智能正式发布并开源了端侧「小钢炮」系列最新力作——MiniCPM 4.0 模型,实现了最快震撼的 220 倍极限加速!昇思MindSpore框架对齐主流生态接口,不断提升HuggingFace Transformers类模型接入vllm-mindspore框架效率,同时基于vLLM推理框架与MindSpore One套件,0day支持MiniCPM4.0双尺寸模型快速适配。欢迎
6 月 6 号,面壁智能正式发布并开源了端侧「小钢炮」系列最新力作——MiniCPM 4.0 模型,实现了最快震撼的 220 倍极限加速!昇思MindSpore框架对齐主流生态接口,不断提升HuggingFace Transformers类模型接入vllm-mindspore框架效率,同时基于vLLM推理框架与MindSpore One套件,0day支持MiniCPM4.0双尺寸模型快速适配。欢迎广大开发者下载体验!
MindSpore-vLLM代码仓:
https://gitee.com/mindspore/vllm-mindspore
🔗魔乐社区体验指导链接:
https://modelers.cn/models/MindSpore-Lab/MiniCPM4-8B
https://modelers.cn/models/MindSpore-Lab/MiniCPM4-0.5B
# 01 模型介绍
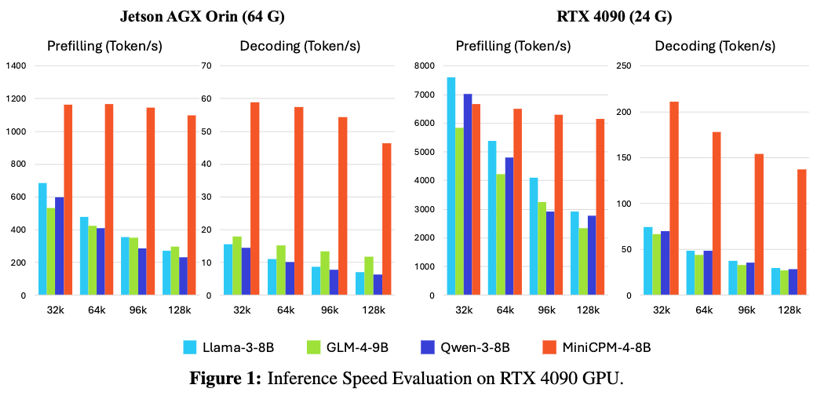
MiniCPM 4-8B 「闪电版」,为新一代稀疏高效架构模型,通过架构层、算法层、系统层、数据层等多维度的技术创新,MiniCPM 4.0 相较于 Qwen-3-8B、Llama-3-8B、GLM-4-9B等同等参数规模端侧模型,实现了长文本推理速度 5 倍稳定加速以及最高 70 倍加速,并实现了同级最佳的模型性能,持续卫冕全球最强端侧模型。继 Deepseek 之后,成为大模型领域又一次「标杆式创新」典范。
![]()
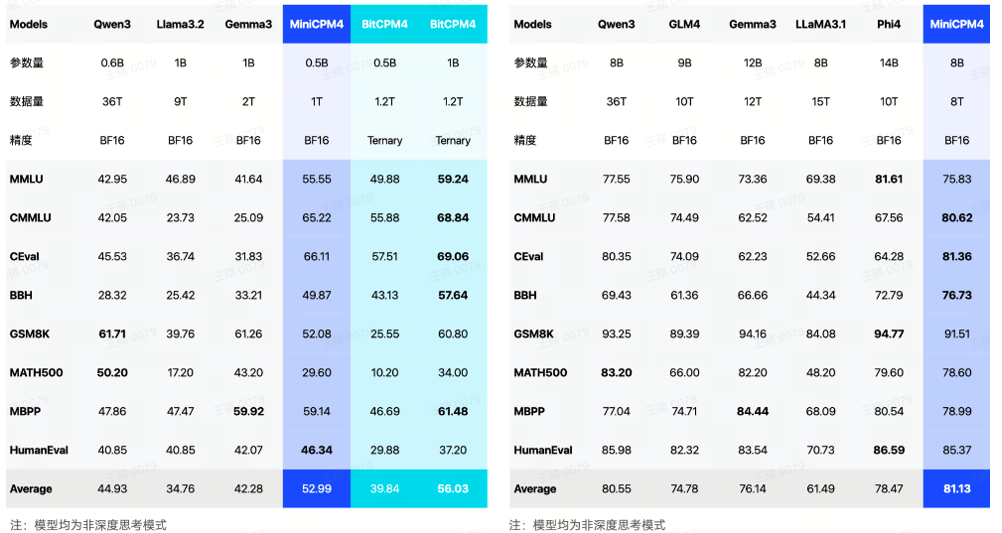
MiniCPM 4.0 推出端侧性能“大小王”组合,拥有 8B 、0.5B 两种参数规模,均实现了同级最佳的模型性能。其中,MiniCPM 4.0-8B 模型为稀疏注意力模型,在MMLU、CEval、MATH500、HumanEval等基准测试中,MiniCPM 4.0-8B 性能超越 Qwen-3-8B、Gemma-3-12B。MiniCPM 4.0-0.5B 在性能上,也显著优于 Qwen-3-0.6B,并实现了最快 600 Token/s 的极速推理速度,成为速度最快的轻量级模型。
![]()
针对单一架构难以兼顾长、短文本不同场景的技术难题,MiniCPM 4.0-8B 采用「高效双频换挡」机制,能够根据任务特征自动切换注意力模式:在处理高难度的长文本、深度思考任务时,启用稀疏注意力以降低计算复杂度,在短文本场景下切换至稠密注意力以确保精度,实现了长、短文本切换的高效响应。

值得一提的是,MiniCPM 4.0 实现了长文本缓存的大幅锐减。在 128K 长文本场景下,MiniCPM 4.0-8B 相较于 Qwen3-8B 仅需 1/4 的缓存存储空间。
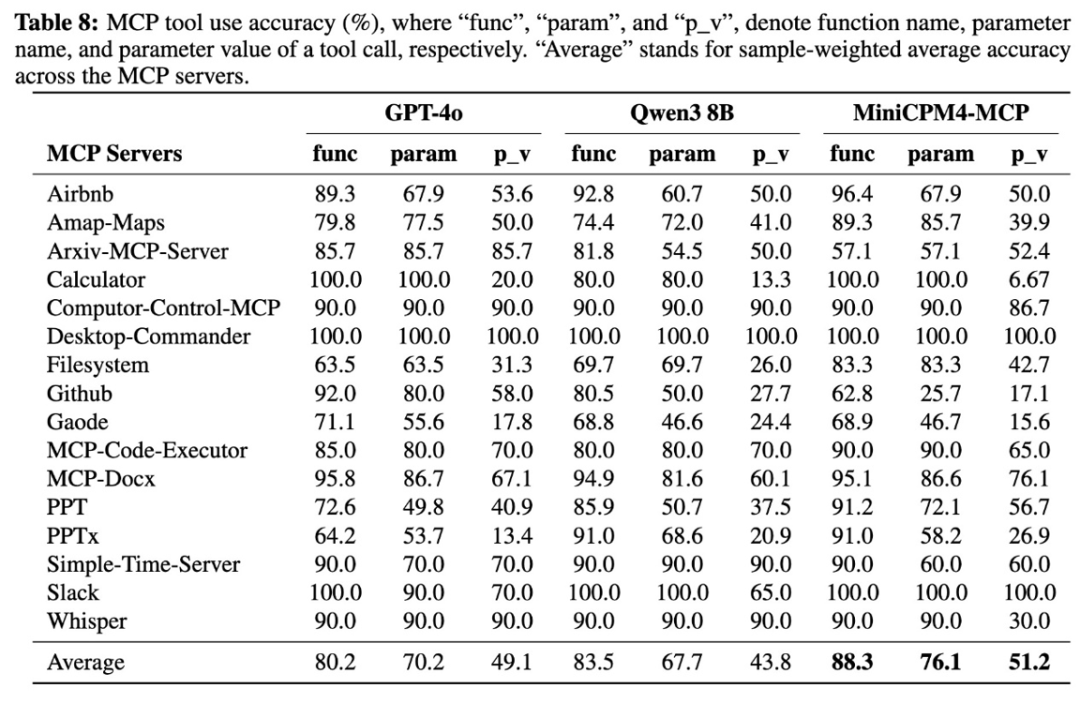
此外, MiniCPM 4.0可在 vLLm、SGLang、llama.cpp、LlamaFactory、XTuner等开源框架部署;同时加强了对 MCP的支持,且性能超过同尺寸开源模型( Qwen-3-8B),进一步拓展了模型开发、应用潜力。
# 02 快速开始
1 环境搭建
环境准备:Atlas 800I/800T A2 (64G),单卡。
执行以下 Shell 命令,拉取MindSpore MiniCPM 推理容器镜像:
docker pull swr.cn-central-221.ovaijisuan.com/mindsporelab/minicpm:v42 通过魔乐社区下载权重
pip install openmind_hub
export HUB_WHITE_LIST_PATHS=/mnt/data/MiniCPM8B # 该路径存放权重
br
from openmind_hub import snapshot_download
snapshot_download(
repo_id="MindSpore-Lab/MiniCPM4-8B",
local_dir="/mnt/data/MiniCPM8B",
local_dir_use_symlinks=False
)3 创建并进入容器
执行以下命令创建容器,name设置为MiniCPM8B。
docker run -it --privileged --name=MiniCPM8B --net=host \
--shm-size 500g \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device /dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/firmware:/usr/local/Ascend/firmware \
-v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \
-v /usr/local/sbin:/usr/local/sbin \
-v /etc/hccn.conf:/etc/hccn.conf \
-v /mnt/data/MiniCPM8B/:/mnt/data/MiniCPM8B/ \
swr.cn-central-221.ovaijisuan.com/mindsporelab/minicpm:v4 \
bash4 通过vllm_mindspore拉起推理服务
python3 -m vllm_mindspore.entrypoints vllm.entrypoints.openai.api_server --model "/mnt/data/MiniCPM8B"
--trust_remote_code --tensor_parallel_size=1 --max-num-seqs=256 --block-size=32 --max_model_len=8192 --max-num-batched-tokens=81925 打开一个新的窗口,然后发起推理请求
curl http://localhost:8000/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "/mnt/data/MiniCPM8B",
"messages": [
{"role": "user", "content": "帮我介绍一下上海"}
],
"temperature": 0.0,
"top_p": 0.95,
"top_k": 20,
"min_p": 0,
"max_tokens": 4096
}'本文档提供的模型代码、权重文件和部署镜像,仅限于基于昇思MindSpore AI框架体验MiniCPM4.0的部署效果,如需生产使用,欢迎邮件联系我们。(contact@public.mindspore.cn)
昇思MindSpore AI框架将持续支持更多业界主流模型,欢迎大家试用并提供宝贵的反馈意见。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)