CVPR2025 | 上海科技大学提出MITracker:多视图目标跟踪新框架+23万帧数据集,目标跟踪抗遮挡能力飙升!
经ViT处理后,通过特定计算得到聚焦于目标对象的特征,再利用基于CenterNet架构的边界框头输出跟踪结果,并将特征映射到2D特征图,为后续多视图集成做准备。和其他多视图数据集相比,它提供了更丰富的对象类别(27类,远超其他数据集的1 - 8类)和更多的视频(260 个),且采用实用的3 - 4视图相机设置,是唯一结合多视图跟踪、丰富对象类别、缺失标签注释和校准信息的数据集。跟踪的时候呢,当目标

标题:“MITracker: Multi-View Integration for Visual Object Tracking”
论文地址:[2502.20111] MITracker: Multi-View Integration for Visual Object Tracking
数据集和代码地址:MII Lab
导读:论文旨在解决传统单视图跟踪中的遮挡和目标丢失等问题,提出了MVTrack 数据集和MITracker方法,有效提升了多视图目标跟踪性能。
研究动机
-单视图跟踪的局限性:尽管单视图跟踪借助暹罗网络和变压器取得进展,但在处理遮挡、外观变化和目标丢失等问题时仍存在不足。单视图信息的固有局限性限制了跟踪性能的提升,如 RTracker 虽尝试解决目标丢失问题,但因复杂设计和对特定类别的依赖而受限。
-多视图跟踪的挑战:多相机系统为解决单视图跟踪问题提供了思路,但多视图目标跟踪(MVOT)发展面临难题。现有多视图数据集大多局限于特定对象类别,不适用于通用对象跟踪;当前 MVOT 方法主要针对特定类别对象,且因缺乏综合多视图数据,在训练时依赖单视图数据集,限制了模型对不同视角复杂空间关系和外观变化的理解。
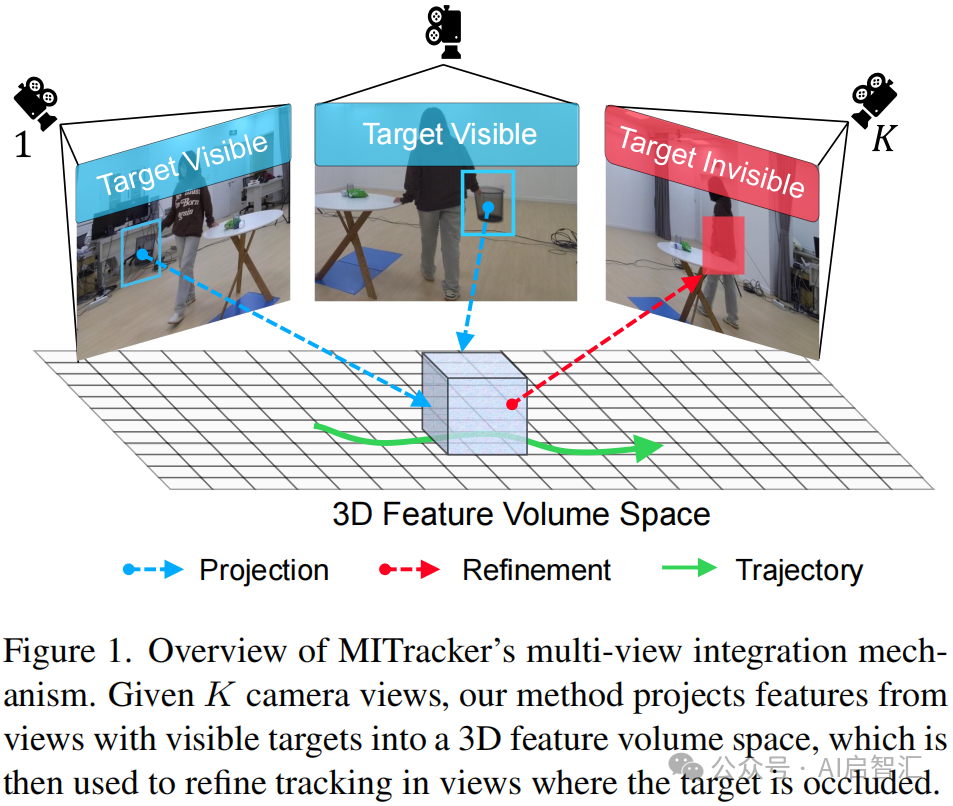
图1是MITracker多视图集成机制的概述。在多摄像头系统中,假设有K个摄像头视图。当目标在某些视图中可见时,MITracker会将这些视图中的特征投影到一个3D特征体空间中。这个3D特征体空间整合了来自不同可见视图的信息,包含了目标在不同角度下的特征。
跟踪的时候呢,当目标在部分视图中被遮挡,系统会利用构建好的3D特征体空间中的信息,对被遮挡视图中的目标跟踪进行优化和修正。从而实现更稳定、可靠的多视图目标跟踪。
研究贡献
-构建MVTrack数据集:包含 234K 帧,由3 - 4个校准相机拍摄,对27个对象类别进行精确标注,涵盖9种具有挑战性的跟踪属性,提供训练集和评估集,为训练通用MVOT方法和评估相关方法提供了全面基准。
-提出MITracker方法:构建BEV引导的3D特征体增强空间理解,并利用空间增强注意力机制从特定视图的目标丢失中稳健恢复,可从任意视角跟踪任意长度视频帧中的对象。
方法
-特定视图特征提取:使用Vision Transformer(ViT)作为骨干网络,将视频流从特定视点处理,基于参考帧提取搜索帧中目标感知特征。输入包含搜索帧、参考帧及两个时间令牌,以确保帧间时间连续性。经ViT处理后,通过特定计算得到聚焦于目标对象的特征,再利用基于CenterNet架构的边界框头输出跟踪结果,并将特征映射到2D特征图,为后续多视图集成做准备。
-多视图集成:将K个视点的2D特征图投影到3D特征空间并聚合。通过相机参数建立坐标映射关系,使用双线性采样填充3D特征体,再沿Z轴聚合特征,利用分类头生成BEV分数图,为多视图信息融合提供监督约束。引入空间增强注意力机制,将聚合后的3D特征嵌入3D感知令牌,与各视点未细化特征连接,经变压器块和注意力机制处理,由边界框头输出细化跟踪结果,纠正潜在错误。
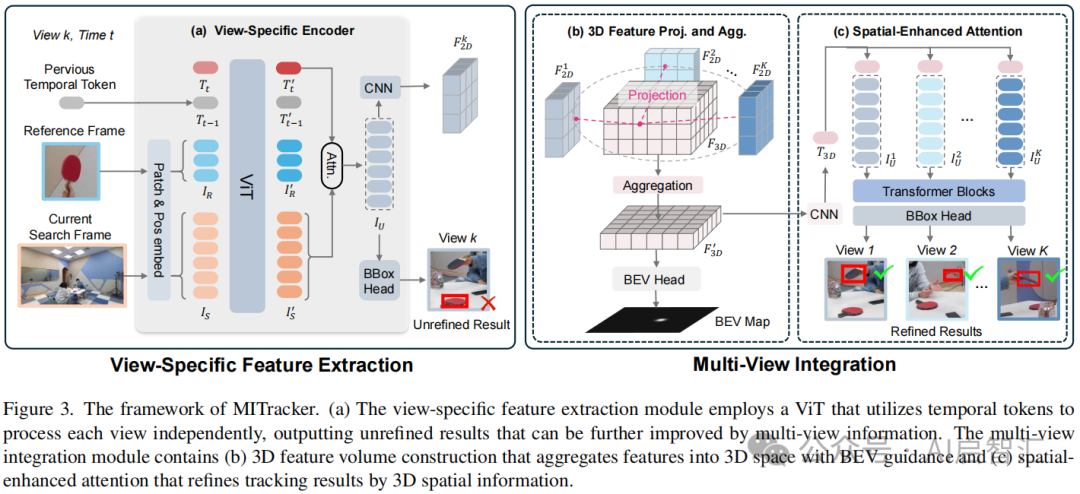
图3展示了MITracker的框架结构,其由特定视图特征提取模块和多视图集成模块组成,二者协同工作实现多视图目标跟踪。
特定视图特征提取模块:该模块ViT网络独立处理每个视图。为了保持时间连续性,它利用了时间令牌(temporal tokens)。在处理视频流时,从特定视点获取当前搜索帧和指示目标对象的参考帧,将其分割成非重叠的补丁(patches)并嵌入为令牌序列,同时加入可学习的时间令牌Tt和携带前一帧时间信息的Tt - 1。经过ViT处理后,通过计算注意力权重得到聚焦于目标对象的特征IU,再由基于CenterNet架构的边界框头输出初步的单视图跟踪结果。不过,这个结果是未经过多视图信息优化的,后续会由多视图集成模块进一步改进。
3D特征体构建:属于多视图集成模块的一部分。为了有效融合多个视图的信息,该模块将从K个视点得到的2D特征图
![]()
投影到3D特征空间。利用相机的内参矩阵CK、旋转矩阵C_R和平移向量Ct,将 2D 特征图中的坐标投影到3D特征体的坐标,通过双线性采样填充3D特征体,并计算各视图映射值的平均值以确保一致性,得到F3D。之后,沿着3D特征体的Z轴应用1D卷积层聚合特征,得到F'3D,并利用分类头(BEV 头)生成BEV分数图,以此在水平面上确定目标位置,为多视图信息融合提供监督约束。
空间增强注意力:同样是多视图集成模块的重要部分。BEV引导对聚合的3D特征F'3D仅隐式约束了原始单视图输出,不足以解决潜在的目标丢失问题。为此,引入空间增强注意力机制。先通过卷积层将F'3D嵌入为3D感知令牌T3D,它继承了多视图空间信息。然后将T3D与各视点特定编码器生成的未细化特征
![]()
分别连接,通过一系列变压器块和注意力机制,利用融合的 3D空间信息对这些特征进行细化,最后由边界框头输出经过优化的跟踪结果。
-数据集:旨在填补多视图目标跟踪(MVOT)领域的空白,为相关研究提供全面的基准。它在数据的多样性、标注的精确性以及场景和属性的丰富性等方面具备优势,为训练和评估MVOT模型提供了基础。下面是数据集的一些特点:
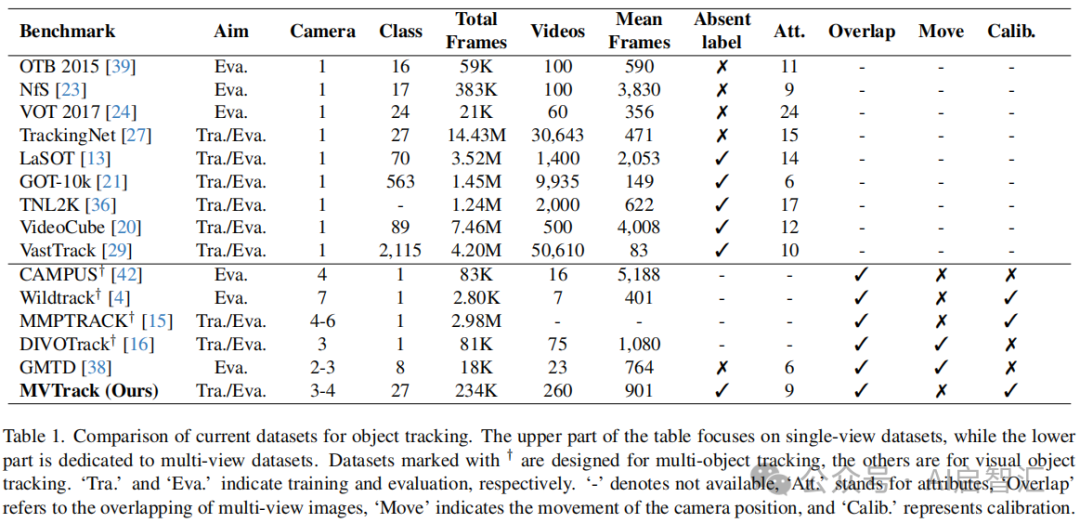
多视图与丰富类别融合:与单视图数据集相比,数据集在保持类别多样性的同时增加了多视图能力。和其他多视图数据集相比,它提供了更丰富的对象类别(27类,远超其他数据集的1 - 8类)和更多的视频(260 个),且采用实用的3 - 4视图相机设置,是唯一结合多视图跟踪、丰富对象类别、缺失标签注释和校准信息的数据集。

数据采集与校准规范:采用由3或4个时间同步的Azure Kinect 相机组成的多相机系统进行数据采集,分辨率为1920×1080,帧率30FPS。相机位置确保有多个重叠视图。
精确的数据标注:提供帧级注释,包括2D对象边界框(BBox)和统一坐标系下的地面坐标注释(BEV注释)。BBox注释采用类似LaSOT的半自动标注策略,为模型训练和评估提供精确标注数据。
涵盖多种挑战属性:重点关注9种常见的跟踪挑战属性,如背景杂波、运动模糊、部分遮挡、完全遮挡、视野外、变形、低分辨率、宽高比变化和尺度变化。
合理的数据集划分:训练集包含196 个视频和180K帧,验证集有30个视频和28K帧,测试集有34个视频和26K帧。验证集和测试集包含训练集未出现的场景,测试集还涵盖训练集出现和未出现的对象类别。
实验
-实验数据集
一个是作者构建的MVTrack 数据集,包含234K 帧,由3 - 4个校准相机拍摄,涵盖27个对象类别,9种跟踪属性,如遮挡、变形等。还有GOT10K数据集、GMTD数据集。
-实验设置
评估指标:采用单视图跟踪基准中的三个标准指标。AUC通过改变IoU阈值评估跟踪区域的面积误差;Precision衡量预测和真实BBox中心的距离,评估位置误差;Normalized Precision对BBox中心进行归一化,减少 BBox大小变化带来的偏差。
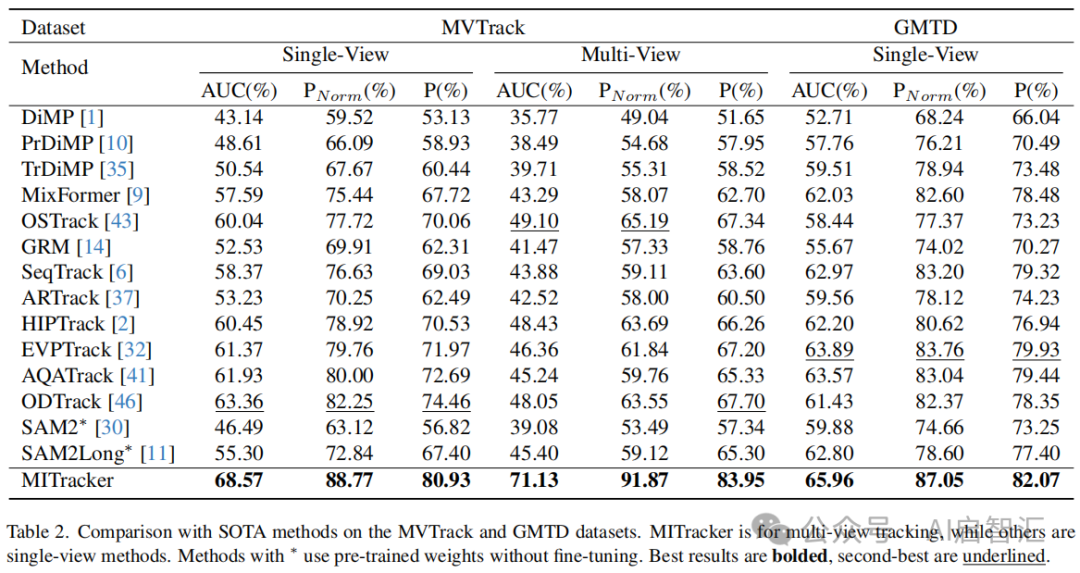
-对比实验:将 MITracker与单视图视觉对象跟踪方法对比,在GOT10K和 MVTrack数据集上训练模型,在MVTrack和GMTD数据集的单视图和多视图设置下测试。对于单视图方法,采用后融合策略获取多视图结果。结果表明,MITracker表现出色,在多视图场景下比第二好的方法OSTrack高出约26%;在单视图设置下,比ODTrack 高约5%。
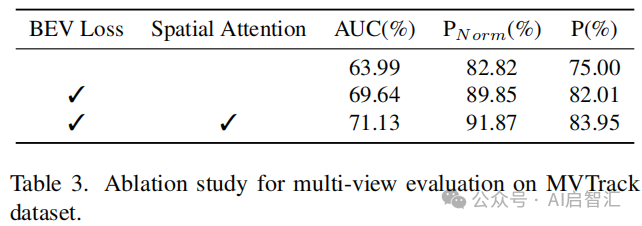
-消融实验:研究BEV Loss和空间注意力对模型性能的影响。BEV Loss提供的多视图信息反馈和空间注意力利用融合信息调整输出,均显著提升了性能。
-可视化对比:定性评估遮挡和快速运动对跟踪的影响,MITracker 在目标重新出现时重新跟踪的性能更优,且通过可视化 BEV 轨迹,提供准确的3D空间信息。

总结
论文旨在解决传统单视角目标跟踪中的遮挡和目标丢失问题。主要贡献有:
1、提出MVTrack数据集:包含23.4万帧高精度标注的多视角数据(3-4个同步摄像头),涵盖27类物体及9种复杂场景属性(如遮挡、变形),首次为类无关多视角跟踪提供了完整的训练与评估基准。
2、提出MITracker方法:将多视角2D特征投影为3D特征体积,并通过鸟瞰图(BEV)压缩实现跨视角信息融合。提出基于几何信息的空间增强注意力机制,动态优化各视角跟踪结果。
论文方法依赖摄像头标定,未来计划扩展至户外场景并降低标定依赖,推动多视角跟踪的实际应用。
以上仅供学习交流参考。
感谢阅读!可微信搜索公众号【AI启智汇】获取更多AI干货分享。


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)