AISHELL-5 全球首套智能驾舱中文语音交互数据集开源
AISHELL-5作为首个开源的真实车载多通道中文语音识别数据集,填补了智能驾舱语音交互研究领域的数据空白。该数据集包含893.7小时真实车内录音(含706小时对话和187小时噪声),采集自165名说话人在60多个车载场景下的多方位麦克风信号。由希尔贝壳联合理想汽车等机构发布的该项研究入选INTERSPEECH2025会议,配套开源基线系统展示了主流ASR模型在复杂驾舱环境中的性能挑战。数据集下载
随着汽车成为人们日常生活中不可或缺的一部分,而驾驶舱中传统的触摸交互方式容易分散驾驶员的注意力,存在安全风险,因此,车内基于语音的交互方式得到重视。与通常家庭或会议场景中的语音识别系统不同,驾驶场景中的系统面临更加独特的挑战,缺乏大规模的公共真实车内数据一直是该领域发展的主要障碍。AISHELL-5是首个开源的真实车载多通道、多说话人中文自动语音识别(ASR)高质量数据集。AISHELL-5的开源加速了智能驾舱内语音交互的相关技术研究,并且希尔贝壳联合西工大音频语音与语言处理研究组(ASLP@NPU)、理想汽车发布的AISHELL-5论文成功入选INTERSPEECH2025国际会议,以下是AISHELL-5数据集的相关介绍。

数据地址:https://www.aishelltech.com/AISHELL_5


数据说明
AISHELL-5 共计893.7小时,单通道145.25小时。邀请165名录音人,在真实车内,涉及60+车载场景下录制。录音内容包含对话(706.59H)和噪声(187.11H)两类。拾音点位共计5个:近讲为头戴麦克风(采样率:16kHz,16bit,数据量:215.63H),远讲为驾舱内麦克风(采样率:16kHz,16bit,数据量:490.96H,拾音位:4个音位)。噪声采集由驾舱内麦克风(采样率:16kHz,16bit,数据量:187.11H,拾音位:4个音位)录制。
录制场景示意图:
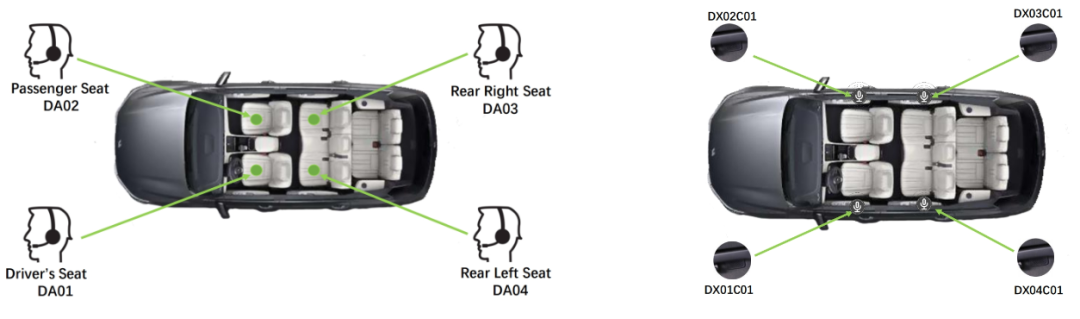
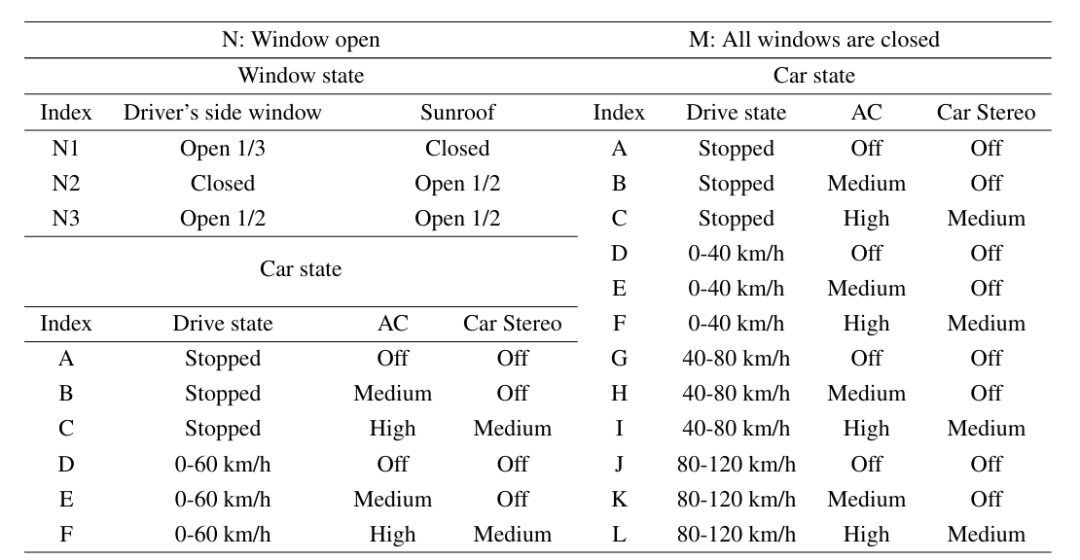
录制环境设计信息:
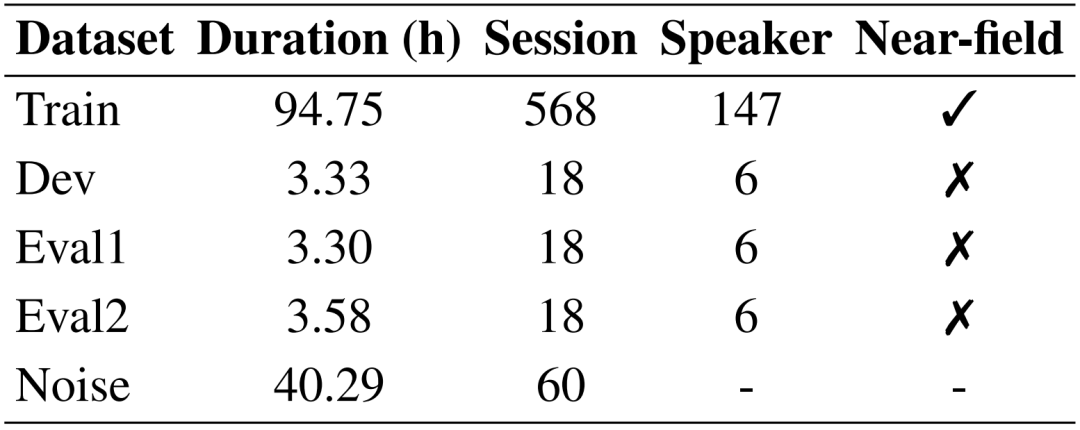
实验数据分配如下:
试验说明
我们提供了基于该数据集构建的一套开源基线系统。该系统包括一个语音前端模型,利用语音源分离技术从远场信号中提取出每位说话人的清晰语音,以及一个语音识别模块,用于准确转写每位说话人的语音内容。
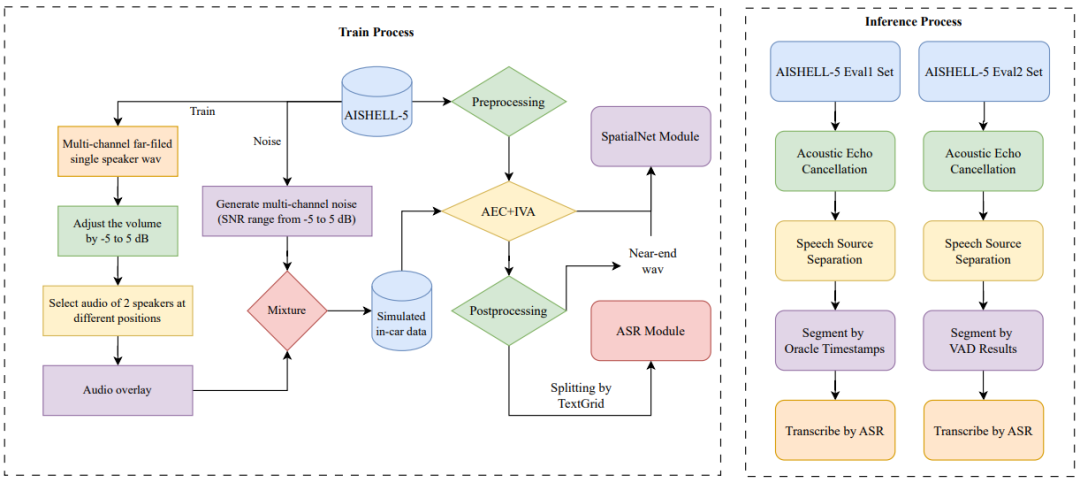
系统实验结果:
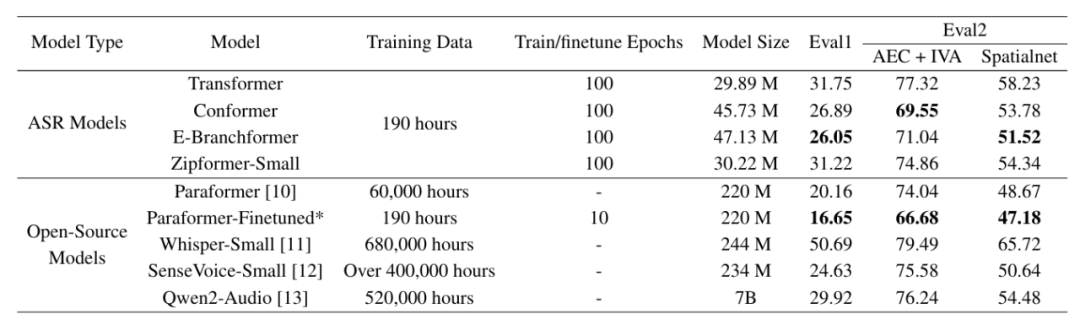
实验结果展示了多种主流ASR 模型在 AISHELL-5 数据集上面临的挑战。AISHELL-5 数据的开源能够推动智驾领域复杂驾舱场景下的语音技术研究。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)