【TrOCR】在自己数据集上训练TrOCR
TrOCR是一种端到端的文本识别方法,它结合了预训练的图像Transformer和文本Transformer模型,利用Transformer架构同时进行图像理解和字块级别的文本生成。TrOCR: 基于预训练模型的Transformer光学字符识别李明浩,吕腾超,崔磊,卢一娟,迪内·弗洛伦西奥,张查,李周军,魏富如,AAAI 2023。TrOCR模型也以Huggingface格式提供。文档][模型模

论文地址: TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models
Huggingface:[ 文档][ 模型]
一、数据集预处理
数据集格式转换与划分:
两个变量记录输入的数据集图片和标签txt文件地址。
标签文件内容格式为:
crop_img/388_crop_2.jpg 通道
crop_img/388_crop_3.jpg 未意
crop_img/389_crop_0.jpg 1-E
crop_img/389_crop_1.jpg 7150
crop_img/391_crop_0.jpg 8400
划分数据集并且保存为一下格式其中用变量记录保存的位置。
data_dir/
├── train/
│ ├── images/
│ └── labels.json
└── val/
├── images/
└── labels.json
由于划分数据集要用到sklearn库的train_test_split,需要安装一下。
pip install scikit-learn
数据集格式转换与划分的脚本,可将原始图像和标签文件转换为训练所需的目录结构,并自动划分训练集和验证集。format_split.py
import os
import json
import shutil
from sklearn.model_selection import train_test_split
# -------------------------- 配置参数(请根据实际情况修改) --------------------------
# 原始数据路径
ORIGINAL_IMG_DIR = r"C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\oringal_dateset\crop_img"
ORIGINAL_LABEL_PATH = r"C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\oringal_dateset\rec_gt2.txt"
# 输出数据路径(最终会生成 train/val 目录)
OUTPUT_DATA_DIR = r"C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\formatted_dataset"
# 划分比例(验证集占比)
VAL_RATIO = 0.2 # 20% 数据作为验证集
# ----------------------------------------------------------------------------------
def main():
# 1. 读取原始标签文件
print("开始读取标签文件...")
image_label_pairs = []
with open(ORIGINAL_LABEL_PATH, "r", encoding="utf-8") as f:
for line in f.readlines():
line = line.strip()
if not line:
continue
# 分割图像路径和标签(按制表符分割)
img_path, label = line.split("\t")
# 提取图像文件名(如 "388_crop_2.jpg")
img_filename = os.path.basename(img_path)
# 检查图像文件是否存在
full_img_path = os.path.join(ORIGINAL_IMG_DIR, img_filename)
if not os.path.exists(full_img_path):
print(f"警告:图像文件不存在 - {full_img_path},已跳过")
continue
image_label_pairs.append({
"file_name": img_filename, # 图像文件名
"text": label # 对应标签
})
if not image_label_pairs:
print("错误:未找到有效图像-标签对,请检查输入路径")
return
print(f"成功读取 {len(image_label_pairs)} 个有效图像-标签对")
# 2. 划分训练集和验证集
print(f"划分训练集({1-VAL_RATIO:.0%})和验证集({VAL_RATIO:.0%})...")
train_pairs, val_pairs = train_test_split(
image_label_pairs,
test_size=VAL_RATIO,
random_state=42 # 固定随机种子,确保划分结果可复现
)
print(f"训练集:{len(train_pairs)} 个样本,验证集:{len(val_pairs)} 个样本")
# 3. 创建输出目录结构
print("创建输出目录结构...")
# 训练集路径
train_img_dir = os.path.join(OUTPUT_DATA_DIR, "train", "images")
train_label_path = os.path.join(OUTPUT_DATA_DIR, "train", "labels.json")
# 验证集路径
val_img_dir = os.path.join(OUTPUT_DATA_DIR, "val", "images")
val_label_path = os.path.join(OUTPUT_DATA_DIR, "val", "labels.json")
# 创建目录(递归创建,已存在则忽略)
os.makedirs(train_img_dir, exist_ok=True)
os.makedirs(val_img_dir, exist_ok=True)
# 4. 复制图像文件并保存标签JSON
# 处理训练集
print("复制训练集图像并保存标签...")
for pair in train_pairs:
src_img = os.path.join(ORIGINAL_IMG_DIR, pair["file_name"])
dst_img = os.path.join(train_img_dir, pair["file_name"])
shutil.copy2(src_img, dst_img) # 保留文件元数据
# 保存训练集标签JSON
with open(train_label_path, "w", encoding="utf-8") as f:
json.dump(train_pairs, f, ensure_ascii=False, indent=2)
# 处理验证集
print("复制验证集图像并保存标签...")
for pair in val_pairs:
src_img = os.path.join(ORIGINAL_IMG_DIR, pair["file_name"])
dst_img = os.path.join(val_img_dir, pair["file_name"])
shutil.copy2(src_img, dst_img)
# 保存验证集标签JSON
with open(val_label_path, "w", encoding="utf-8") as f:
json.dump(val_pairs, f, ensure_ascii=False, indent=2)
print(f"数据集转换完成!输出路径:{OUTPUT_DATA_DIR}")
print(f"训练集图像:{train_img_dir}")
print(f"训练集标签:{train_label_path}")
print(f"验证集图像:{val_img_dir}")
print(f"验证集标签:{val_label_path}")
if __name__ == "__main__":
main()
示例输出:
开始读取标签文件...
成功读取 6586 个有效图像-标签对
划分训练集(80%)和验证集(20%)...
训练集:5268 个样本,验证集:1318 个样本
创建输出目录结构...
复制训练集图像并保存标签...
复制验证集图像并保存标签...
数据集转换完成!输出路径:C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\formatted_dataset
训练集图像:C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\formatted_dataset\train\images
训练集标签:C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\formatted_dataset\train\labels.json
验证集图像:C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\formatted_dataset\val\images
验证集标签:C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\formatted_dataset\val\labels.json
(base) root@5de27e9cb8c1:/mnt/Virgil/TrOCR/ChineseDataset# python formet_split.py
开始读取标签文件...
成功读取 90000 个有效图像-标签对
划分训练集(80%)和验证集(20%)...
训练集:72000 个样本,验证集:18000 个样本
创建输出目录结构...
复制训练集图像并保存标签...
复制验证集图像并保存标签...
数据集转换完成!输出路径:/mnt/Virgil/TrOCR/ChineseDataset/9w_train
训练集图像:/mnt/Virgil/TrOCR/ChineseDataset/9w_train/train/images
训练集标签:/mnt/Virgil/TrOCR/ChineseDataset/9w_train/train/labels.json
验证集图像:/mnt/Virgil/TrOCR/ChineseDataset/9w_train/val/images
验证集标签:/mnt/Virgil/TrOCR/ChineseDataset/9w_train/val/labels.json
数据增强
二、TrOCR推理
TrOCR预训练权重下载
huggingface上预训练权重trocr-base-printed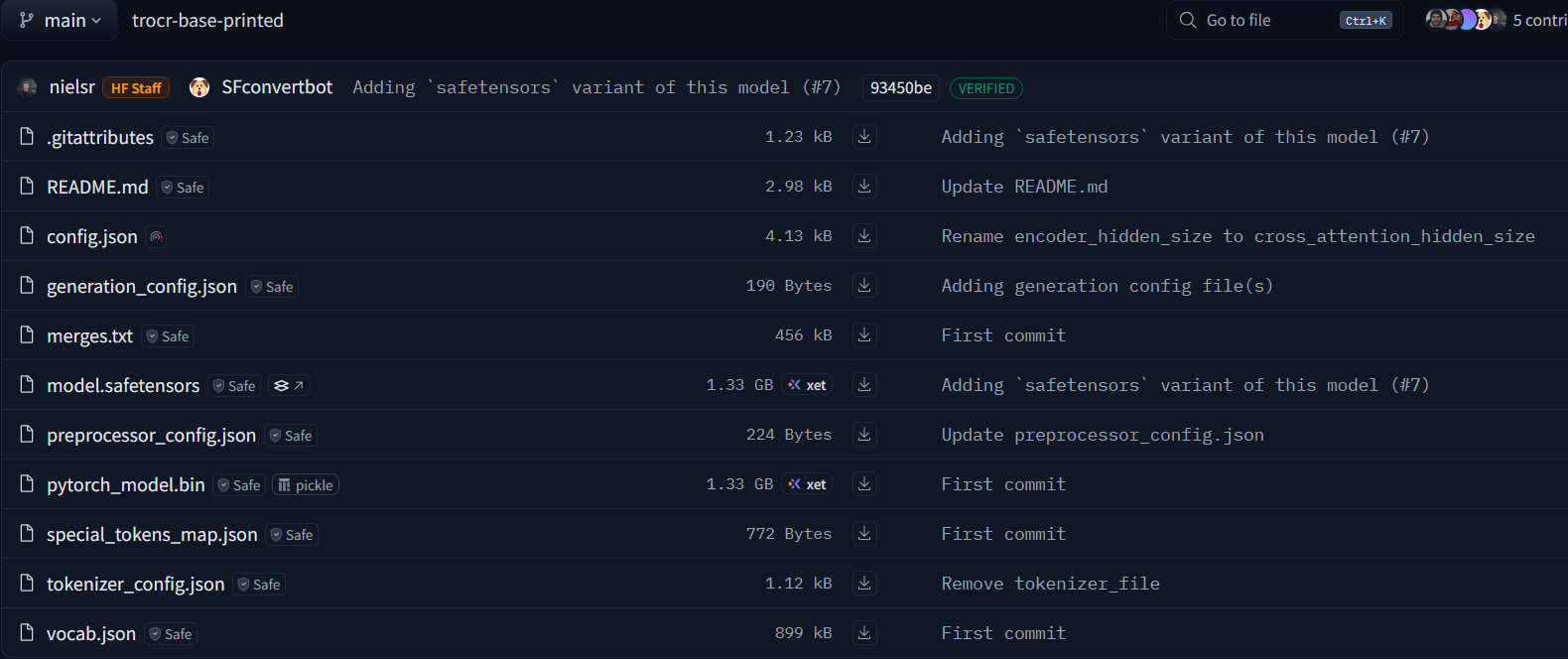

以下是 trocr-base-printed 目录中各文件的意义:
config.json:存储模型的配置信息,包括模型架构(如编码器和解码器层数、隐藏层维度等)、超参数(如激活函数类型等)。这些信息用于在创建模型实例时正确初始化模型结构。generation_config.json:与模型生成相关的配置文件,例如设置生成文本时的参数,如最大生成长度、束搜索(beam search)的参数(如束宽num_beams)、是否使用早停(early_stopping)等,用于控制模型生成文本的过程。gitattributes:用于定义 Git 仓库中文件的属性,例如可以指定某些文件的合并策略、是否进行文本换行符转换等,主要是在版本控制管理方面起作用。merges.txt:在基于字节对编码(Byte - Pair Encoding, BPE)的分词器中,该文件记录了合并操作的规则。BPE 是一种将频繁出现的子词单元合并成新的词单元的算法,merges.txt记录了这些合并的顺序和规则,用于构建分词器的词汇表。model.safetensors:存储模型的权重参数。safetensors是一种更安全、更轻量级的张量存储格式,相比传统的 PyTorch 模型权重存储方式,它在加载和保存时更高效,且能更好地防止恶意代码注入。preprocessor_config.json:保存预处理器(如 TrOCR 中用于处理图像和文本的组件)的配置信息,定义了如何对输入的图像和文本进行预处理,包括图像的归一化参数、文本分词器的相关配置等。README.md:通常是模型的说明文档,介绍模型的基本信息(如模型架构、用途)、训练数据、如何使用该预训练模型(包括示例代码)、模型性能指标等内容,是了解和使用模型的重要参考文档。special_tokens_map.json:记录特殊标记(如起始标记<s>、填充标记<pad>、结束标记</s>等)与它们在词汇表中对应索引的映射关系。这些特殊标记在模型处理文本输入和输出时起到重要作用,如标识句子开头、填充长度等。tokenizer_config.json:分词器的配置文件,定义了分词器的行为,如使用的分词算法、词汇表大小、是否使用一些特定的分词规则(如是否进行字节对编码等),是分词器正确工作的配置依据。vocab.json:存储分词器的词汇表,即所有词单元及其对应的索引。模型在处理文本时,会根据这个词汇表将文本转换为对应的数字索引序列,是文本向量化的重要依据。
对于单图TrOCR推理代码
修改image_path变量路径
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
from PIL import Image
# 加载处理器和模型
processor = TrOCRProcessor.from_pretrained("../trocr-base-printed")
model = VisionEncoderDecoderModel.from_pretrained("../trocr-base-printed")
# image_path = "img_test.png"
image_path = r"C:\Users\Virgil\Desktop\TrOCR\trocr\code_1\img_test.png"
try:
# 打开本地图片
image = Image.open(image_path).convert("RGB")
# 预处理图像
pixel_values = processor(images=image, return_tensors="pt").pixel_values
# 生成文本
generated_ids = model.generate(pixel_values)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
# 输出识别结果
print("识别结果:", generated_text)
except FileNotFoundError:
print(f"未找到图片文件: {image_path}")
except Image.UnidentifiedImageError as e:
print(f"无法识别图像: {e}")
except Exception as e:
print(f"发生其他错误: {e}")
对这个图片进行推理
识别结果: ACKNOWLEDGHENTS
并且输出相关信息:
Config of the encoder: <class 'transformers.models.vit.modeling_vit.ViTModel'> is overwritten by shared encoder config: ViTConfig {
"attention_probs_dropout_prob": 0.0,
"encoder_stride": 16,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_size": 768,
"image_size": 384,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"model_type": "vit",
"num_attention_heads": 12,
"num_channels": 3,
"num_hidden_layers": 12,
"patch_size": 16,
"qkv_bias": false,
"transformers_version": "4.48.0"
}
Config of the decoder: <class 'transformers.models.trocr.modeling_trocr.TrOCRForCausalLM'> is overwritten by shared decoder config: TrOCRConfig {
"activation_dropout": 0.0,
"activation_function": "gelu",
"add_cross_attention": true,
"attention_dropout": 0.0,
"bos_token_id": 0,
"classifier_dropout": 0.0,
"cross_attention_hidden_size": 768,
"d_model": 1024,
"decoder_attention_heads": 16,
"decoder_ffn_dim": 4096,
"decoder_layerdrop": 0.0,
"decoder_layers": 12,
"decoder_start_token_id": 2,
"dropout": 0.1,
"eos_token_id": 2,
"init_std": 0.02,
"is_decoder": true,
"layernorm_embedding": true,
"max_position_embeddings": 512,
"model_type": "trocr",
"pad_token_id": 1,
这段输出信息主要包含了模型配置的覆盖情况以及模型权重初始化的相关提示
- 编码器配置覆盖信息
Config of the encoder: <class 'transformers.models.vit.modeling_vit.ViTModel'> is overwritten by shared encoder config: ViTConfig { "attention_probs_dropout_prob": 0.0, "encoder_stride": 16, "hidden_act": "gelu", "hidden_dropout_prob": 0.0, "hidden_size": 768, "image_size": 384, "initializer_range": 0.02, "intermediate_size": 3072, "layer_norm_eps": 1e-12, "model_type": "vit", "num_attention_heads": 12, "num_channels": 3, "num_hidden_layers": 12, "patch_size": 16, "qkv_bias": false, "transformers_version": "4.48.0" }
- 含义:这里表明编码器原本的配置(
transformers.models.vit.modeling_vit.ViTModel)被一个共享的编码器配置(ViTConfig)覆盖了。覆盖后的编码器配置包含了一系列超参数,例如:attention_probs_dropout_prob:注意力概率的丢弃率,这里设置为 0.0,表示不进行丢弃。hidden_size:隐藏层的维度大小,为 768。num_hidden_layers:隐藏层的数量,为 12。
- 解码器配置覆盖信息
Config of the decoder: <class 'transformers.models.trocr.modeling_trocr.TrOCRForCausalLM'> is overwritten by shared decoder config: TrOCRConfig { "activation_dropout": 0.0, "activation_function": "gelu", "add_cross_attention": true, "attention_dropout": 0.0, "bos_token_id": 0, "classifier_dropout": 0.0, "cross_attention_hidden_size": 768, "d_model": 1024, "decoder_attention_heads": 16, "decoder_ffn_dim": 4096, "decoder_layerdrop": 0.0, "decoder_layers": 12, "decoder_start_token_id": 2, "dropout": 0.1, "eos_token_id": 2, "init_std": 0.02, "is_decoder": true, "layernorm_embedding": true, "max_position_embeddings": 512, "model_type": "trocr", "pad_token_id": 1, "scale_embedding": false, "transformers_version": "4.48.0", "use_cache": false, "use_learned_position_embeddings": true, "vocab_size": 50265 }
- 含义:解码器原本的配置(
transformers.models.trocr.modeling_trocr.TrOCRForCausalLM)被一个共享的解码器配置(TrOCRConfig)覆盖。覆盖后的解码器配置也包含了多个超参数,比如:d_model:模型的维度大小,为 1024。decoder_attention_heads:解码器的注意力头数量,为 16。vocab_size:词汇表的大小,为 50265。
模型权重初始化提示
Some weights of VisionEncoderDecoderModel were not initialized from the model checkpoint at ../trocr-base-printed and are newly initialized: ['encoder.pooler.dense.bias', 'encoder.pooler.dense.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
- 含义:在从
../trocr-base-printed这个模型检查点加载VisionEncoderDecoderModel的权重时,有部分权重(encoder.pooler.dense.bias和encoder.pooler.dense.weight)没有从检查点中初始化,而是被重新初始化了。这意味着这些权重是随机初始化的,没有使用预训练的值。因此,建议你在下游任务上对这个模型进行训练,这样模型才能用于预测和推理。因为随机初始化的权重可能无法很好地完成具体的任务,需要通过训练来调整这些权重以适应特定的任务。
自己数据集上用模型推理
测试预训练模型。
遍历图片文件夹image_folder,用预训练预训练权重model_path推理,并保存输出结果到output_file
import os
from PIL import Image
from tqdm import tqdm
import torch
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
# 配置路径
image_folder = "C:/Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\crop_img" # 图片文件夹路径
output_file = "test_dataset.txt" # 输出结果文件路径
model_path = "../trocr-base-printed" # 模型路径
# 设置设备(优先使用GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 加载处理器和模型到指定设备
processor = TrOCRProcessor.from_pretrained(model_path)
model = VisionEncoderDecoderModel.from_pretrained(model_path).to(device)
def predict_image(image_path):
"""预测单张图片的文字内容"""
try:
# 打开图片并转换为RGB格式
image = Image.open(image_path).convert("RGB")
# 预处理图像并移至设备
pixel_values = processor(images=image, return_tensors="pt").pixel_values.to(device)
# 生成文本
with torch.no_grad():
generated_ids = model.generate(pixel_values)
# 解码文本
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
return generated_text
except FileNotFoundError:
print(f"未找到图片文件: {image_path}")
return None
except Image.UnidentifiedImageError as e:
print(f"无法识别图像: {image_path}, 错误: {e}")
return None
except Exception as e:
print(f"处理图片 {image_path} 时发生其他错误: {e}")
return None
def main():
# 获取所有图片文件
image_files = [f for f in os.listdir(image_folder)
if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
total_images = len(image_files)
print(f"找到 {total_images} 张图片")
# 创建输出文件
with open(output_file, 'w', encoding='utf-8') as f:
# 使用tqdm显示进度条
for filename in tqdm(image_files, desc="处理进度", unit="张"):
# 构建完整路径
image_path = os.path.join(image_folder, filename)
relative_path = os.path.join("crop_img", filename)
# 预测文字
predicted_text = predict_image(image_path)
# 如果预测成功,写入结果并打印
if predicted_text is not None:
result_line = f"{relative_path}\t{predicted_text}"
f.write(f"{result_line}\n")
print(result_line)
print(f"\n所有图片处理完成!结果已保存到 {output_file}")
if __name__ == "__main__":
main()
合并到csv文件方便对比分析
gt_dir为ground truth标签txt文件
run_dir为推理得到的结果txt文件
import csv
import os
# 文件路径(使用原始字符串或双反斜杠处理路径中的反斜杠)
gt_dir = r"C:/Users/Virgil/Desktop/TrOCR/TrOCR_Dataset/rec_gt.txt"
run_dir = r"C:/Users/Virgil/Desktop/TrOCR/trocr/code_1/test_dataset.txt"
def main():
# 读取 ground truth 文件
gt_dict = {}
with open(gt_dir, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line:
continue
parts = line.split('\t')
if len(parts) >= 2:
img_name = parts[0]
gt_text = parts[1]
gt_dict[img_name] = gt_text
# 读取模型推理结果文件
pred_dict = {}
with open(run_dir, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if not line:
continue
parts = line.split('\t')
if len(parts) >= 2:
img_name = parts[0]
pred_text = parts[1]
pred_dict[img_name] = pred_text
# 优化文件名匹配(处理反斜杠和大小写)
results = []
for gt_img_name, gt_text in gt_dict.items():
# 转换为统一格式(反斜杠转斜杠,小写处理)
normalized_gt = gt_img_name.replace('\\', '/').lower()
matched = False
for pred_img_name, pred_text in pred_dict.items():
normalized_pred = pred_img_name.replace('\\', '/').lower()
if normalized_gt == normalized_pred:
results.append([gt_img_name, gt_text, pred_text])
matched = True
break
if not matched:
results.append([gt_img_name, gt_text, ""]) # 未匹配到预测结果
# 写入 CSV 文件
with open("ocr_comparison.csv", 'w', encoding='utf-8', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["文件名", "Ground Truth", "模型预测"]) # 表头
writer.writerows(results)
print(f"合并完成!结果已保存到 ocr_comparison.csv")
print(f"总样本数: {len(results)}")
print(f"匹配成功的样本数: {sum(1 for r in results if r[2])}")
print(f"未找到预测结果的样本数: {sum(1 for r in results if not r[2])}")
if __name__ == "__main__":
main()
结果分析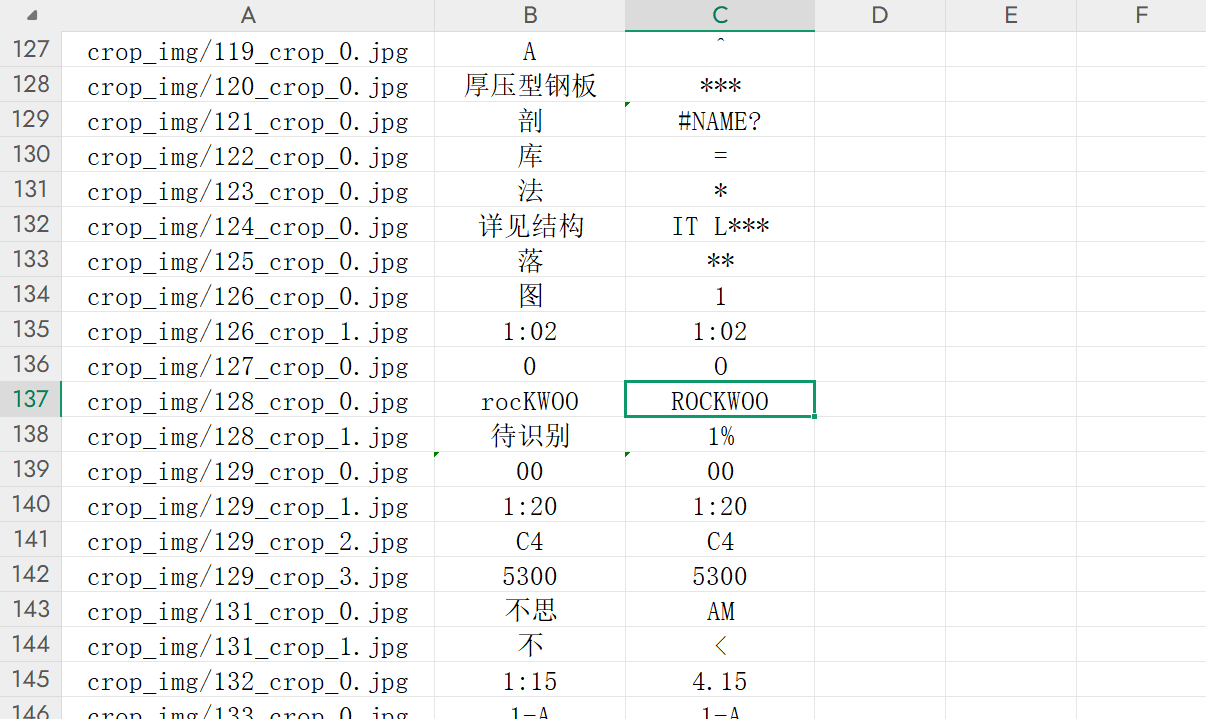
对于英文和数字表现还可以,但中文不是无法识别***,就是识别为英文或符号。
极少数的汉字,如月和日识别出来了。
中英分词器下载与测试
在TrOCR模型中,分词器(Tokenizer)是训练过程的关键组成部分,直接影响模型对文本的理解和生成效果。以下是详细解释和解决方案:
一、分词器在TrOCR中的作用
-
训练阶段:
- 分词器将标注文本(如“贷款给那些贫困的学生”)转换为模型可处理的token ID序列。
- 若分词器对中文支持不佳(如按英文字符切分),会导致token序列过长或语义碎片化,严重影响训练效果。
-
推理阶段:
- 模型生成的token ID需通过分词器解码回文本。若分词器不支持中文,可能生成乱码或无意义字符。
二、中英混合分词器下载与检验
1. BERT中文分词器
from transformers import TrOCRProcessor, BertTokenizer
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-printed")
processor.tokenizer = BertTokenizer.from_pretrained("bert-base-chinese") # 替换为中文分词器
- 优势:
- 预训练时已学习中文语境(如字、词的语义关联)。
- 支持中英混合文本(如“Hello世界”会正确切分为
["Hello", "世", "界"])。
- 注意:
- 需确保模型的词表大小与分词器一致(通常TrOCR的词表兼容BERT)。
- 若使用自定义词表,需重新训练分词器。
将分词器下载到本地指定路径,提前执行以下代码。如果报错HTTP之类的,开个梯子。
from transformers import BertTokenizer
# 下载并保存到本地目录
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
tokenizer.save_pretrained("./bert-base-chinese") # 替换为你的本地路径
验证分词器是否适配中文和英文
from transformers import TrOCRProcessor, BertTokenizer
# 初始化TrOCR处理器(包含图像处理器和原始分词器)
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-printed")
# 替换为本地的中文分词器(假设已下载到./bert-base-chinese目录)
processor.tokenizer = BertTokenizer.from_pretrained("./bert-base-chinese")
# 验证分词效果(中英混合文本)
test_text = "中文测试111 abandon Hello 123"
tokens = processor.tokenizer.tokenize(test_text)
# 输出分词结果
print(f"原始文本: {test_text}")
print(f"分词结果: {tokens}")
结果来看,不适用于中英混合的
原始文本: 中文测试111 abandon Hello 123
分词结果: ['中', '文', '测', '试', '111', 'ab', '##and', '##on', '[UNK]', '123']
2. 多语言分词器bert-base-multilingual-cased
from transformers import TrOCRProcessor, BertTokenizer
# 配置路径和参数
local_tokenizer_dir = "./bert-multilingual-cased" # 本地保存分词器的目录
test_text = "中文测试111 abandon Hello 123 混合文本test" # 待测试的中英混合文本
# 1. 下载多语言分词器到本地(仅首次运行时下载,后续直接加载)
print("正在下载多语言分词器到本地...")
tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
tokenizer.save_pretrained(local_tokenizer_dir)
print(f"分词器已保存到:{local_tokenizer_dir}\n")
# 2. 加载TrOCR处理器和本地多语言分词器
print("加载处理器和分词器...")
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-printed")
processor.tokenizer = BertTokenizer.from_pretrained(local_tokenizer_dir) # 替换为本地分词器
# 3. 验证中英混合分词效果
print("验证中英混合分词效果:")
tokens = processor.tokenizer.tokenize(test_text)
# 输出结果
print(f"原始文本:{test_text}")
print(f"分词结果:{tokens}")
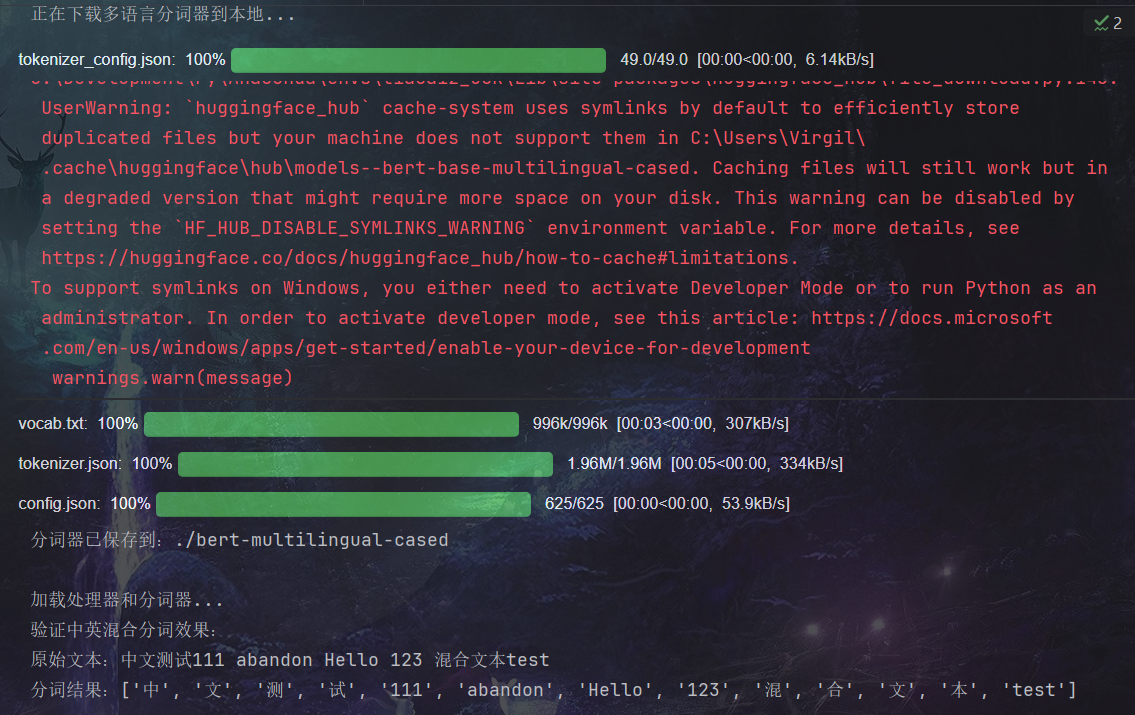
原始文本:中文测试111 abandon Hello 123 混合文本test
分词结果:['中', '文', '测', '试', '111', 'abandon', 'Hello', '123', '混', '合', '文', '本', 'test']
这个支持
四、分词器与模型训练的具体关联
-
词表大小一致性:
- 若更换分词器,需确保模型的
vocab_size与分词器的词表大小一致:model.config.vocab_size = processor.tokenizer.vocab_size # 自动同步词表大小
- 若更换分词器,需确保模型的
-
特殊token处理:
- TrOCR依赖特定的开始/结束token(如
<s>、</s>),需确保分词器支持:model.config.decoder_start_token_id = processor.tokenizer.cls_token_id model.config.eos_token_id = processor.tokenizer.sep_token_id
- TrOCR依赖特定的开始/结束token(如
五、其他注意事项
-
数据预处理: 若数据中包含大量特殊符号(如数学公式、表情),需自定义分词器或扩展现有词表。
-
训练效率: 中文分词可能产生更多token(如一个汉字对应一个token),需适当调整
max_target_length避免内存溢出。
三、微调训练
环境配置
以下是成功运行 TrOCR 训练代码所需的核心环境依赖(按安装优先级排序):
-
基础框架与模型库
pip install torch torchvision # PyTorch基础(需匹配CUDA版本,CPU版可省略) pip install "transformers[torch]==4.36.2" pip install "transformers[torch]" # 自动安装匹配版本的 accelerate 和 PyTorch 相关依赖 -
加速与分布式训练工具
pip install accelerate>=0.26.0 # 支持混合精度训练和设备管理 -
数据处理与评估工具
pip install datasets # 加载数据集(2.0+版本需配合evaluate库) pip install jiwer -
Hugging Face Hub 交互工具
pip install huggingface-hub>=0.30.0 # 用于加载预训练模型和缓存管理 -
辅助依赖
pip install pandas pillow # 处理图像和标签数据(PIL用于图像加载) pip install scikit-learn # 用于数据集划分(train_test_split)
可用以下代码检验环境版本
import transformers, accelerate, evaluate, huggingface_hub
print(f"transformers: {transformers.__version__}") # 需4.36.2左右
print(f"accelerate: {accelerate.__version__}") # 需≥0.26.0
print(f"evaluate: {evaluate.__version__}") # 需≥0.4.0
print(f"huggingface-hub: {huggingface_hub.__version__}") # 需≥0.30.0
评估函数
用from evaluate import load时。本以为跑通了,但训练了一轮后,报错了。
100%|█████████▉| 2249/2250 [2:34:24<00:04, 4.13s/it][A
100%|██████████| 2250/2250 [2:34:28<00:00, 4.10s/it][ATraceback (most recent call last):
File "/mnt/Virgil/TrOCR/没改分词器跑通的代码/train_OCR.py", line 210, in <module>
main()
File "/mnt/Virgil/TrOCR/没改分词器跑通的代码/train_OCR.py", line 200, in main
trainer.train()
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 2245, in train
return inner_training_loop(
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 2647, in _inner_training_loop
self._maybe_log_save_evaluate(tr_loss, grad_norm, model, trial, epoch, ignore_keys_for_eval, start_time)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 3093, in _maybe_log_save_evaluate
metrics = self._evaluate(trial, ignore_keys_for_eval)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 3047, in _evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer_seq2seq.py", line 197, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 4136, in evaluate
output = eval_loop(
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 4425, in evaluation_loop
metrics = self.compute_metrics(
File "/mnt/Virgil/TrOCR/没改分词器跑通的代码/train_OCR.py", line 191, in <lambda>
compute_metrics=lambda x: compute_metrics(x, processor),
File "/mnt/Virgil/TrOCR/没改分词器跑通的代码/train_OCR.py", line 116, in compute_metrics
cer_metric = load("cer")
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/evaluate/loading.py", line 748, in load
evaluation_module = evaluation_module_factory(
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/evaluate/loading.py", line 681, in evaluation_module_factory
raise FileNotFoundError(
FileNotFoundError: Couldn't find a module script at /mnt/Virgil/TrOCR/没改分词器跑通的代码/cer/cer.py. Module 'cer' doesn't exist on the Hugging Face Hub either.
evaluate 库无法找到 cer 指标。
所以metrics,evaluate,load_metric这三个库都不行。
用pip install jiwer,测试 jiwer 是否正常工作:
from jiwer import cer, wer
# 测试用例
reference = ["中文测试123", "我爱自然语言处理"]
prediction = ["中文测试123", "我喜爱语言处理"]
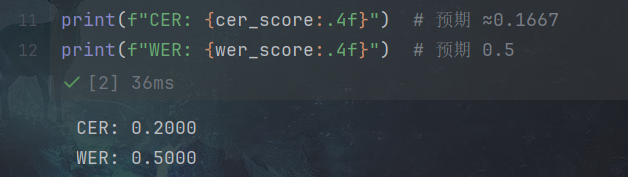
# 计算指标
cer_score = cer(reference, prediction)
wer_score = wer(reference, prediction)
print(f"CER: {cer_score:.4f}") # 预期 ≈0.1667
print(f"WER: {wer_score:.4f}") # 预期 0.5
评估函数:
from jiwer import cer, wer
# 评估函数(改用 jiwer 库)
def compute_metrics(eval_pred, processor):
# 使用 jiwer 的 cer 和 wer 函数
labels_ids = eval_pred.label_ids
pred_ids = eval_pred.predictions
# 替换-100为pad_token_id,确保解码正确
pred_ids[pred_ids == -100] = processor.tokenizer.pad_token_id
labels_ids[labels_ids == -100] = processor.tokenizer.pad_token_id
# 解码为文本
pred_str = processor.tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
labels_str = processor.tokenizer.batch_decode(labels_ids, skip_special_tokens=True)
# 计算指标(jiwer的参数顺序:参考文本在前,预测文本在后)
return {
"cer": cer(labels_str, pred_str),
"wer": wer(labels_str, pred_str)
}
早停机制
加了patience参数但报错
Traceback (most recent call last):
File "/mnt/Virgil/TrOCR/train_OCR.py", line 208, in <module>
main()
File "/mnt/Virgil/TrOCR/train_OCR.py", line 164, in main
training_args = Seq2SeqTrainingArguments(
TypeError: Seq2SeqTrainingArguments.__init__() got an unexpected keyword argument 'patience'
transformers 库的 Seq2SeqTrainingArguments 没有 patience 参数。早停机制需通过 EarlyStoppingCallback 实现。
通过 EarlyStoppingCallback(early_stopping_patience=10) 实现早停(连续 10 轮验证指标无提升则停止),需从 transformers 导入该回调
# 新增导入早停回调
from transformers import EarlyStoppingCallback
# ... 其他代码不变(数据集类、评估函数等) ...
def main():
# ... 加载处理器、模型等代码不变 ...
# 训练参数:移除patience,添加早停回调
training_args = Seq2SeqTrainingArguments(
predict_with_generate=True,
eval_strategy="epoch",
save_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
fp16=True,
num_train_epochs=150,
learning_rate=5e-5,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
save_total_limit=3,
load_best_model_at_end=True,
metric_for_best_model="cer",
greater_is_better=False,
output_dir="./trocr-finetuned-multilingual",
warmup_steps=1000,
lr_scheduler_type="cosine"
# 移除patience参数
)
# 初始化训练器:添加EarlyStoppingCallback实现早停
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda x: compute_metrics(x, processor),
data_collator=default_data_collator,
callbacks=[
CSVLogger(log_file="training_metrics.csv"), # 之前的CSV日志回调
EarlyStoppingCallback(early_stopping_patience=10) # 官方早停回调,patience=10
]
)
# ... 训练代码不变 ...
日志输出与保存
日志默认仅打印到控制台,若需将训练指标(如损失、CER、WER)保存到 CSV,通过 Trainer 的回调函数 TrainingCallback 实时将指标写入 CSV实现。
import csv
from datetime import datetime
from transformers import (
TrOCRProcessor,
BertTokenizer,
VisionEncoderDecoderModel,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
default_data_collator,
TrainerCallback
)
# 自定义回调:将指标写入CSV
class CSVLogger(TrainerCallback):
def __init__(self, log_file="training_logs.csv"):
self.log_file = log_file
# 初始化CSV文件并写入表头
with open(self.log_file, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
"timestamp", "epoch", "step",
"train_loss", "eval_cer", "eval_wer"
])
def on_log(self, args, state, control, logs=None, **kwargs):
# 记录训练日志(每步损失)
if "loss" in logs and "eval" not in logs:
with open(self.log_file, "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
state.epoch,
state.global_step,
logs.get("loss"),
None, None # eval指标为空
])
def on_evaluate(self, args, state, control, metrics=None,** kwargs):
# 记录验证日志(CER、WER)
if metrics:
with open(self.log_file, "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
state.epoch,
state.global_step,
None, # 训练损失为空
metrics.get("eval_cer"),
metrics.get("eval_wer")
])
# 主函数(添加CSV日志回调)
def main():
# 加载处理器、模型、配置模型(与之前一致)
# 加载数据
# 训练参数(不变)
# 初始化训练器,添加CSV日志回调
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda x: compute_metrics(x, processor),
data_collator=default_data_collator,
callbacks=[CSVLogger(log_file="training_metrics.csv")] # 添加自定义回调
)
# 训练和保存
自定义 CSVLogger 回调:
on_log:每logging_steps记录一次训练损失。on_evaluate:每轮结束记录验证集的 CER 和 WER。- 日志文件为
training_metrics.csv,包含时间戳、轮次、步数、损失、CER、WER 等信息。
保存模型
-
模型保存逻辑
代码中通过save_strategy="epoch"配置,模型会在 每轮(epoch)结束后保存,同时:save_total_limit=3:只保留最近3个模型 checkpoint,避免磁盘占用过大。load_best_model_at_end=True+metric_for_best_model="cer":训练结束后,自动加载验证集上 CER 最低(最佳)的模型。
-
官方是否区分 “best” 和 “latest”
latest模型:每轮结束保存的是当前轮次的模型(即 “latest”),文件名格式为checkpoint-{epoch数}。best模型:训练结束后,会将验证集表现最佳的模型复制到输出目录根目录(output_dir),替代最后一轮的模型,相当于 “best” 模型。
因此,官方通过上述参数间接实现了 “best” 和 “latest” 的区分,最终保留的是最佳模型。
MLflow
要将你的TrOCR训练代码与MLflow集成(并连接到你的MLflow服务器http://172.29.172.33:5000/),只需添加以下代码即可实现实验跟踪(记录参数、指标、模型等)。以下是具体修改步骤:
1. 导入MLflow并连接到你的服务器
在代码开头添加MLflow的导入和服务器配置:
import mlflow
from mlflow.tracking import MlflowClient
# 连接到你的MLflow服务器(关键步骤)
mlflow.set_tracking_uri("http://172.29.172.33:5000/")
# 创建实验(如果不存在会自动创建)
experiment_name = "TrOCR_Chinese_OCR" # 自定义实验名称
mlflow.set_experiment(experiment_name)
2. 在训练主函数中添加MLflow跟踪逻辑
在main()函数中,用mlflow.start_run()包裹训练过程,并记录关键信息:
def main():
# ...(原有代码:数据路径、模型加载等)
# 启动MLflow运行(跟踪单次实验)
with mlflow.start_run(run_name=f"trocr_run_{datetime.now().strftime('%Y%m%d_%H%M%S')}"):
# 记录超参数(根据你的训练参数添加)
mlflow.log_params({
"model_name": model_name,
"num_train_epochs": 10,
"learning_rate": 5e-5,
"batch_size": 8,
"weight_decay": 0.01,
"fp16": True,
"num_beams": 4,
"max_length": 128
})
# 加载处理器和模型(原有代码)
processor = TrOCRProcessor.from_pretrained(model_name)
model = VisionEncoderDecoderModel.from_pretrained(model_name)
# ...(原有代码:模型配置、数据加载等)
# 自定义回调:在评估时记录MLflow指标
class MLflowCallback(TrainerCallback):
def on_evaluate(self, args, state, control, metrics=None, **kwargs):
if metrics:
# 记录评估指标(CER和WER)
mlflow.log_metrics({
"eval_cer": metrics["eval_cer"],
"eval_wer": metrics["eval_wer"]
}, step=state.global_step)
def on_log(self, args, state, control, logs=None,** kwargs):
if "loss" in logs and "eval" not in logs:
# 记录训练损失
mlflow.log_metric("train_loss", logs["loss"], step=state.global_step)
# 初始化训练器(添加MLflow回调)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda x: compute_metrics(x, processor),
data_collator=default_data_collator,
callbacks=[
CSVLogger(log_file="training_metrics.csv"), # 保留原有CSV日志
EarlyStoppingCallback(early_stopping_patience=10),
MLflowCallback() # 添加MLflow回调
]
)
# 训练(原有代码)
trainer.train()
trainer.save_model(output_dir)
processor.save_pretrained(output_dir)
# 记录最终模型到MLflow
mlflow.pytorch.log_model(
model=model,
artifact_path="trocr_model", # 模型在MLflow中的保存路径
registered_model_name="TrOCR_Chinese" # 可选:注册到模型仓库
)
# 记录处理器配置(可选,方便复现)
with open(os.path.join(output_dir, "processor_config.json"), "w") as f:
json.dump(processor.config.to_dict(), f)
mlflow.log_artifact(os.path.join(output_dir, "processor_config.json")) # 上传到MLflow
# 最终评估(原有代码)
metrics = trainer.evaluate()
print(f"最终验证结果: {metrics}")
# 记录最终指标
mlflow.log_metrics({
"final_eval_cer": metrics["eval_cer"],
"final_eval_wer": metrics["eval_wer"]
})
3. 关键修改说明
-
连接MLflow服务器:通过
mlflow.set_tracking_uri("http://172.29.172.33:5000/")指定你的服务器地址,所有实验数据会同步到该服务器。 -
记录超参数:用
mlflow.log_params()记录训练的关键参数(如学习率、批次大小等),方便后续对比不同实验。 -
跟踪指标:通过自定义
MLflowCallback,在训练过程中实时记录train_loss、eval_cer、eval_wer,并关联到训练步数(step),在MLflow UI中可查看指标变化曲线。 -
保存模型:用
mlflow.pytorch.log_model()将训练好的模型保存到MLflow,支持后续下载、部署或版本管理。 -
实验命名:通过
run_name为每次运行命名(如包含时间戳),方便在UI中区分不同实验。
4. 运行代码后查看结果
- 运行训练代码,MLflow会自动将数据同步到
http://172.29.172.33:5000/。 - 打开该地址,进入
TrOCR_Chinese_OCR实验,可查看:- 所有超参数的对比表格。
- 训练损失、CER、WER的实时曲线图。
- 保存的模型文件和配置。
总结
添加的代码主要实现了:
- 连接到你的MLflow服务器。
- 跟踪超参数、训练损失、评估指标(CER/WER)。
- 保存模型和配置文件到MLflow。
这些修改不会影响原有训练逻辑,却能让你在MLflow UI中直观地管理和对比实验,非常适合后续调优和模型版本控制。
训练结果

命名规则含义
- checkpoint:表示这是模型训练过程中的检查点文件,保存了模型在特定阶段的状态 。
- 数字(如18000、9000 ):一般代表训练步数(steps) ,即模型在经过这些数量的训练步骤后保存了当前状态。比如
checkpoint-18000意味着模型训练了18000步时保存的状态。
训练步数定义:
-
一步(step) 对应 一次参数更新,即模型在一个 批次(batch) 的数据上进行前向传播、计算损失、反向传播并更新参数的完整过程。
-
训练总步数 = (训练集样本数 / 批次大小) × 轮次数
检查点作用
- 恢复训练:如果训练过程因意外中断(如断电、程序崩溃等),可以从最近的检查点恢复训练,而不用从头开始。通过加载对应检查点的模型参数,继续后续训练。
- 评估模型:在不同训练步数的检查点保存模型,方便在训练过程中多次评估模型性能,对比不同阶段模型的表现,如对比
checkpoint-9000和checkpoint-18000对应的模型在验证集上的 CER、WER 指标,查看模型是否在持续优化。 - 模型选择:可以根据不同检查点模型在验证集或测试集上的性能表现,选择表现最佳的模型用于实际部署和应用 。
完整训练代码
在自己数据集上对预训练权重进行微调的训练代码。
import os
import json
import torch
import numpy as np
from PIL import Image
from datasets import Dataset
from transformers import (
TrOCRProcessor,
VisionEncoderDecoderModel,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
default_data_collator
)
from evaluate import load # 从evaluate库导入load函数
from torch.utils.data import Dataset
# 设置中文字体支持(确保matplotlib能正常显示中文)
# 注意:需要根据系统中实际的字体名称进行修改
# import matplotlib.pyplot as plt
# plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
# 定义数据集类
# 定义数据集类
class OCRDataset(Dataset):
def __init__(self, root_dir, df, processor, max_target_length=128):
self.root_dir = root_dir
self.processor = processor
self.max_target_length = max_target_length
self.image_files = [item["file_name"] for item in df] # 直接从列表元素中提取文件名
self.texts = [item["text"] for item in df] # 直接从列表元素中提取文本
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
# 获取图像
image_file = self.image_files[idx]
image_path = os.path.join(self.root_dir, image_file)
image = Image.open(image_path).convert("RGB")
# 获取文本
text = self.texts[idx]
# 处理图像
pixel_values = self.processor(image, return_tensors="pt").pixel_values
# 处理文本
labels = self.processor.tokenizer(
text,
padding="max_length",
max_length=self.max_target_length,
truncation=True
).input_ids
# 模型在训练时会忽略label中值为-100的token
labels = [label if label != self.processor.tokenizer.pad_token_id else -100 for label in labels]
encoding = {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)}
return encoding
# 数据加载函数
def load_and_preprocess_data(data_dir, processor):
# 加载训练数据
train_images_dir = os.path.join(data_dir, "train", "images")
train_labels_path = os.path.join(data_dir, "train", "labels.json")
with open(train_labels_path, "r") as f:
train_labels = json.load(f)
# 创建训练数据集
train_dataset = OCRDataset(
root_dir=train_images_dir,
df=train_labels,
processor=processor
)
# 加载验证数据
val_images_dir = os.path.join(data_dir, "val", "images")
val_labels_path = os.path.join(data_dir, "val", "labels.json")
with open(val_labels_path, "r") as f:
val_labels = json.load(f)
# 创建验证数据集
val_dataset = OCRDataset(
root_dir=val_images_dir,
df=val_labels,
processor=processor
)
return train_dataset, val_dataset
# 评估函数
def compute_metrics(eval_pred):
# 从evaluate库加载字符错误率(CER)和词错误率(WER)评估指标
cer_metric = load("cer")
wer_metric = load("wer")
labels_ids = eval_pred.label_ids
pred_ids = eval_pred.predictions
# 忽略-100的token
pred_ids[pred_ids == -100] = processor.tokenizer.pad_token_id
labels_ids[labels_ids == -100] = processor.tokenizer.pad_token_id
# 将预测和标签转换为文本
pred_str = processor.tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
labels_str = processor.tokenizer.batch_decode(labels_ids, skip_special_tokens=True)
# 计算评估指标
cer = cer_metric.compute(predictions=pred_str, references=labels_str)
wer = wer_metric.compute(predictions=pred_str, references=labels_str)
return {"cer": cer, "wer": wer}
# 主函数
def main():
# 设置参数
data_dir = r"C:\Users\Virgil\Desktop\TrOCR\TrOCR_Dataset\formatted_dataset" # 数据集路径
model_name = r"C:\Users\Virgil\Desktop\TrOCR\trocr\trocr-base-printed" # 预训练模型名称
output_dir = "./trocr-finetuned" # 微调后模型保存路径
max_target_length = 128 # 最大文本长度
batch_size = 8 # 批处理大小
num_train_epochs = 10 # 训练轮数
learning_rate = 5e-5 # 学习率
# 加载处理器和模型
processor = TrOCRProcessor.from_pretrained(model_name)
model = VisionEncoderDecoderModel.from_pretrained(model_name)
# 配置模型
# 设置词汇表大小
model.config.decoder.vocab_size = processor.tokenizer.vocab_size
# 设置生成参数
model.config.decoder_start_token_id = processor.tokenizer.cls_token_id
model.config.pad_token_id = processor.tokenizer.pad_token_id
model.config.vocab_size = processor.tokenizer.vocab_size
# 设置 beam search 参数
model.config.eos_token_id = processor.tokenizer.sep_token_id
model.config.max_length = max_target_length
model.config.early_stopping = True
model.config.no_repeat_ngram_size = 3
model.config.length_penalty = 2.0
model.config.num_beams = 4
# 加载数据
train_dataset, val_dataset = load_and_preprocess_data(data_dir, processor)
# 设置训练参数
training_args = Seq2SeqTrainingArguments(
predict_with_generate=True,
eval_strategy="epoch",
save_strategy="epoch",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
fp16=True, # 使用混合精度训练以加速
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
save_total_limit=3,
load_best_model_at_end=True,
metric_for_best_model="cer",
greater_is_better=False,
output_dir=output_dir,
)
# 初始化训练器
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics,
data_collator=default_data_collator,
)
# 训练模型
trainer.train()
# 保存微调后的模型
trainer.save_model(output_dir)
processor.save_pretrained(output_dir)
# 在验证集上评估最终模型
metrics = trainer.evaluate()
print(f"最终验证结果: {metrics}")
if __name__ == "__main__":
main()
import os
import json
import torch
import csv
from datetime import datetime
from PIL import Image
from transformers import (
TrOCRProcessor,
VisionEncoderDecoderModel,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
default_data_collator,
EarlyStoppingCallback,
TrainerCallback
)
from evaluate import load
from torch.utils.data import Dataset
# 自定义回调:将指标写入CSV
class CSVLogger(TrainerCallback):
def __init__(self, log_file="training_metrics.csv"):
self.log_file = log_file
# 初始化CSV文件并写入表头
with open(self.log_file, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
"timestamp", "epoch", "step",
"train_loss", "eval_cer", "eval_wer"
])
def on_log(self, args, state, control, logs=None, **kwargs):
# 记录训练日志(每步损失)
if "loss" in logs and "eval" not in logs:
with open(self.log_file, "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
state.epoch,
state.global_step,
logs.get("loss"),
None, None # eval指标为空
])
def on_evaluate(self, args, state, control, metrics=None, **kwargs):
# 记录验证日志(CER、WER)
if metrics:
with open(self.log_file, "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
state.epoch,
state.global_step,
None, # 训练损失为空
metrics.get("eval_cer"),
metrics.get("eval_wer")
])
# 定义数据集类
class OCRDataset(Dataset):
def __init__(self, root_dir, df, processor, max_target_length=128):
self.root_dir = root_dir
self.processor = processor
self.max_target_length = max_target_length
self.image_files = [item["file_name"] for item in df]
self.texts = [item["text"] for item in df]
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
# 加载图像
image_path = os.path.join(self.root_dir, self.image_files[idx])
image = Image.open(image_path).convert("RGB")
# 加载文本
text = self.texts[idx]
# 处理图像
pixel_values = self.processor(image, return_tensors="pt").pixel_values
# 处理文本
labels = self.processor.tokenizer(
text,
padding="max_length",
max_length=self.max_target_length,
truncation=True
).input_ids
# 替换pad_token为-100(模型训练时忽略)
labels = [label if label != self.processor.tokenizer.pad_token_id else -100 for label in labels]
return {"pixel_values": pixel_values.squeeze(), "labels": torch.tensor(labels)}
# 数据加载函数
def load_and_preprocess_data(data_dir, processor):
# 加载训练集
train_images_dir = os.path.join(data_dir, "train", "images")
with open(os.path.join(data_dir, "train", "labels.json"), "r") as f:
train_labels = json.load(f)
train_dataset = OCRDataset(train_images_dir, train_labels, processor)
# 加载验证集
val_images_dir = os.path.join(data_dir, "val", "images")
with open(os.path.join(data_dir, "val", "labels.json"), "r") as f:
val_labels = json.load(f)
val_dataset = OCRDataset(val_images_dir, val_labels, processor)
return train_dataset, val_dataset
# 评估函数
def compute_metrics(eval_pred, processor):
cer_metric = load("cer")
wer_metric = load("wer")
labels_ids = eval_pred.label_ids
pred_ids = eval_pred.predictions
# 替换-100为pad_token_id,确保解码正确
pred_ids[pred_ids == -100] = processor.tokenizer.pad_token_id
labels_ids[labels_ids == -100] = processor.tokenizer.pad_token_id
# 解码为文本
pred_str = processor.tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
labels_str = processor.tokenizer.batch_decode(labels_ids, skip_special_tokens=True)
return {
"cer": cer_metric.compute(predictions=pred_str, references=labels_str),
"wer": wer_metric.compute(predictions=pred_str, references=labels_str)
}
# 主函数
def main():
data_dir = r"/mnt/Virgil/TrOCR/ChineseDataset/9w_train" # 数据集路径
model_name = r"/mnt/Virgil/TrOCR/trocr-base-printed" # 预训练模型名称
output_dir = "./trocr-finetuned" # 微调后模型保存路径
# 加载处理器和模型
processor = TrOCRProcessor.from_pretrained(model_name)
model = VisionEncoderDecoderModel.from_pretrained(model_name)
# 模型配置(直接传值)
model.config.decoder.vocab_size = processor.tokenizer.vocab_size
model.config.decoder_start_token_id = processor.tokenizer.cls_token_id
model.config.pad_token_id = processor.tokenizer.pad_token_id
model.config.vocab_size = processor.tokenizer.vocab_size
model.config.eos_token_id = processor.tokenizer.sep_token_id
model.config.max_length = 128
model.config.early_stopping = True
model.config.no_repeat_ngram_size = 3
model.config.length_penalty = 2.0
model.config.num_beams = 4
# 加载数据
train_dataset, val_dataset = load_and_preprocess_data(
data_dir=data_dir,
processor=processor
)
# 训练参数(直接传值,移除变量)
training_args = Seq2SeqTrainingArguments(
predict_with_generate=True,
eval_strategy="epoch",
save_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
fp16=True,
num_train_epochs=10,
learning_rate=5e-5,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
save_total_limit=3,
load_best_model_at_end=True,
metric_for_best_model="cer",
greater_is_better=False,
output_dir=output_dir,
)
# 初始化训练器,添加CSV日志和早停回调
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=lambda x: compute_metrics(x, processor),
data_collator=default_data_collator,
callbacks=[
CSVLogger(log_file="training_metrics.csv"), # 保存训练指标到CSV
EarlyStoppingCallback(early_stopping_patience=10) # 早停机制:10轮无改善则停止
]
)
# 训练和保存
trainer.train()
trainer.save_model(output_dir)
processor.save_pretrained(output_dir)
# 最终评估
metrics = trainer.evaluate()
print(f"最终验证结果: {metrics}")
if __name__ == "__main__":
main()
训练开始,
日志输出是 transformers 库的官方默认行为。Seq2SeqTrainer 会根据 TrainingArguments 中的配置输出训练进度,包括:
- 每轮(epoch)的训练损失(train_loss)
- 验证集的评估指标(如 CER、WER,由 compute_metrics 定义)
- 模型保存信息、学习率等
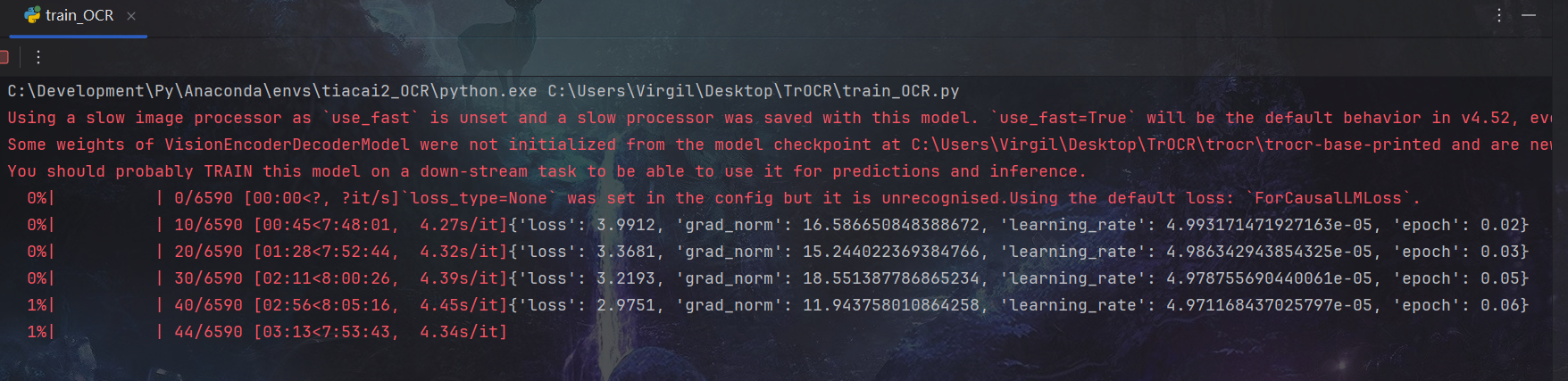
输出一些警告:
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Some weights of VisionEncoderDecoderModel were not initialized from the model checkpoint at C:\Users\Virgil\Desktop\TrOCR\trocr\trocr-base-printed and are newly initialized: ['encoder.pooler.dense.bias', 'encoder.pooler.dense.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
`loss_type=None` was set in the config but it is unrecognised.Using the default loss: `ForCausalLMLoss`.
这些警告主要是模型加载和配置过程中的提示信息,不影响程序运行,简单说明如下:
-
图像处理相关警告
提示当前使用的是“慢速图像处理器”,未来版本(v4.52)会默认使用“快速处理器”(use_fast=True),可能导致输出略有差异。若想继续用慢速处理器,可显式设置use_fast=False。 -
模型权重未初始化警告
加载的VisionEncoderDecoderModel中,encoder.pooler.dense.bias和encoder.pooler.dense.weight这两个权重未从预训练 checkpoint 中加载,而是新初始化的。建议在下游任务上训练模型后再用于推理,否则可能影响效果。 -
损失函数配置警告
模型配置中设置了loss_type=None,但该参数不被识别,因此默认使用ForCausalLMLoss作为损失函数。
补、改分词器报错记录
报错记录
(tiacai) root@5de27e9cb8c1:/mnt/Virgil/TrOCR# python train_OCR.py
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
Config of the encoder: <class 'transformers.models.vit.modeling_vit.ViTModel'> is overwritten by shared encoder config: ViTConfig {
"attention_probs_dropout_prob": 0.0,
"encoder_stride": 16,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"hidden_size": 768,
"image_size": 384,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"model_type": "vit",
"num_attention_heads": 12,
"num_channels": 3,
"num_hidden_layers": 12,
"patch_size": 16,
"pooler_act": "tanh",
"pooler_output_size": 768,
"qkv_bias": false,
"torch_dtype": "float32",
"transformers_version": "4.50.3"
}
Config of the decoder: <class 'transformers.models.trocr.modeling_trocr.TrOCRForCausalLM'> is overwritten by shared decoder config: TrOCRConfig {
"activation_dropout": 0.0,
"activation_function": "gelu",
"add_cross_attention": true,
"attention_dropout": 0.0,
"bos_token_id": 0,
"classifier_dropout": 0.0,
"cross_attention_hidden_size": 768,
"d_model": 1024,
"decoder_attention_heads": 16,
"decoder_ffn_dim": 4096,
"decoder_layerdrop": 0.0,
"decoder_layers": 12,
"decoder_start_token_id": 2,
"dropout": 0.1,
"eos_token_id": 2,
"init_std": 0.02,
"is_decoder": true,
"layernorm_embedding": true,
"max_position_embeddings": 512,
"model_type": "trocr",
"pad_token_id": 1,
"scale_embedding": false,
"torch_dtype": "float32",
"transformers_version": "4.50.3",
"use_cache": false,
"use_learned_position_embeddings": true,
"vocab_size": 50265
}
Some weights of VisionEncoderDecoderModel were not initialized from the model checkpoint at /mnt/Virgil/TrOCR/trocr-base-printed and are newly initialized: ['encoder.pooler.dense.bias', 'encoder.pooler.dense.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Detected kernel version 3.10.0, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
Detected kernel version 3.10.0, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
0%| | 0/1350000 [00:00<?, ?it/s]`loss_type=None` was set in the config but it is unrecognised.Using the default loss: `ForCausalLMLoss`.
Traceback (most recent call last):
File "/mnt/Virgil/TrOCR/train_OCR.py", line 230, in <module>
main()
File "/mnt/Virgil/TrOCR/train_OCR.py", line 221, in main
trainer.train()
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 2245, in train
return inner_training_loop(
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 2556, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs, num_items_in_batch)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 3718, in training_step
loss = self.compute_loss(model, inputs, num_items_in_batch=num_items_in_batch)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/trainer.py", line 3783, in compute_loss
outputs = model(**inputs)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1553, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1562, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/accelerate/utils/operations.py", line 814, in forward
return model_forward(*args, **kwargs)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/accelerate/utils/operations.py", line 802, in __call__
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/torch/amp/autocast_mode.py", line 43, in decorate_autocast
return func(*args, **kwargs)
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/models/vision_encoder_decoder/modeling_vision_encoder_decoder.py", line 644, in forward
loss = self.loss_function(
File "/opt/anaconda3/envs/tiacai/lib/python3.10/site-packages/transformers/loss/loss_utils.py", line 52, in ForCausalLMLoss
logits = logits.view(-1, vocab_size)
RuntimeError: shape '[-1, 119547]' is invalid for input of size 51471360
0%| | 0/1350000 [00:00<?, ?it/s]
(tiacai) root@5de27e9cb8c1:/mnt/Virgil/TrOCR#
模型日志显示解码器配置的 vocab_size=50265(TrOCR 默认词表),但词表大小是 119547,两者冲突导致维度计算失败。
从你的代码和报错来看,问题出在 只修改了 model.config.decoder.vocab_size,但未同步解码器实际输出层(lm_head)的维度,导致模型计算时维度不匹配。具体来说:
TrOCR的解码器(model.decoder)包含一个输出层(lm_head),其输出维度固定为预训练时的词表大小(50265),而你替换的多语言分词器词表大小不同(bert-base-multilingual-cased 是 105879),导致 logits 维度不匹配。
解决方案:必须同步解码器输出层维度
在你的代码基础上,添加 替换解码器输出层 的代码,确保其输出维度与分词器词表大小一致:
def main():
# 加载处理器和模型
processor = TrOCRProcessor.from_pretrained("/mnt/Virgil/TrOCR/trocr-base-printed")
processor.tokenizer = BertTokenizer.from_pretrained("/mnt/Virgil/TrOCR/bert-multilingual-cased")
model = VisionEncoderDecoderModel.from_pretrained("/mnt/Virgil/TrOCR/trocr-base-printed")
# 1. 获取分词器词表大小
vocab_size = processor.tokenizer.vocab_size
print(f"分词器词表大小:{vocab_size}") # 应输出 105879(bert-multilingual-cased的实际词表)
# 2. 同步解码器配置的词表大小
model.config.decoder.vocab_size = vocab_size
model.config.vocab_size = vocab_size # 同步主配置
# 3. 替换解码器输出层(关键!否则输出维度还是50265)
from torch import nn
model.decoder.lm_head = nn.Linear(
in_features=model.decoder.lm_head.in_features, # 保持输入维度不变(通常是1024)
out_features=vocab_size, # 输出维度改为分词器词表大小
bias=False # 与原层保持一致(无偏置)
)
# 4. 验证输出层维度
print(f"解码器输出层维度:{model.decoder.lm_head.out_features}") # 必须等于 vocab_size
# 其他配置不变
model.config.decoder_start_token_id = processor.tokenizer.cls_token_id
model.config.pad_token_id = processor.tokenizer.pad_token_id
model.config.eos_token_id = processor.tokenizer.sep_token_id
model.config.max_length = 128
model.config.early_stopping = True
model.config.no_repeat_ngram_size = 2
model.config.length_penalty = 1.5
model.config.num_beams = 4
# 后续加载数据、训练参数等代码不变...
关键说明
-
bert-base-multilingual-cased的实际词表大小是105879,而非之前假设的119547。你的代码中未显式打印该值,导致误以为词表大小匹配,实际存在差异。 -
必须替换
lm_head:
解码器的lm_head是最后一层线性层,负责将隐藏状态映射到词表维度。如果不替换,其输出维度永远是预训练时的50265,与新词表大小105879冲突,导致logits.view失败。 -
验证步骤:
运行代码后,确保分词器词表大小和解码器输出层维度均为105879,此时logits的总大小(51471360)应能被105879整除(或接近整除,允许微小误差)。
通过上述修改,强制解码器输出层维度与分词器词表大小匹配,即可解决维度不兼容的错误。
# 原来的
# model.config.decoder.vocab_size = processor.tokenizer.vocab_size
# 在模型配置部分,强制同步词表大小
# 获取分词器实际词表大小
tokenizer_vocab_size = processor.tokenizer.vocab_size
# 强制模型词表大小与分词器一致
model.config.vocab_size = tokenizer_vocab_size
model.config.decoder.vocab_size = tokenizer_vocab_size # 确保decoder词表同步
# 验证词表大小是否一致(可选,用于调试)
print(f"分词器词表大小:{processor.tokenizer.vocab_size}")
print(f"模型词表大小:{model.config.vocab_size}")
# 若不一致,会继续报错,需检查分词器是否正确加载

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)