【SAM2代码解析】数据集处理2
这里的逻辑是,我们使用segment_load方法得到的mask是true.false填充的,此时直接计算sum,若和>0,则说明存在obj。使用segment_loader的load方法,得到对象mask字典,字典的key是调色盘掩码png图像中,不同对象自身对应的像素值,字典的value是将不同对象分离后得到的单对象mask掩码,掩码的值是True和False。随机采样对象ID:从可见对象ID
数据集处理中的segmentor和vos_raw_dataset见上一篇【SAM2代码解析】数据集处理1
数据集处理2
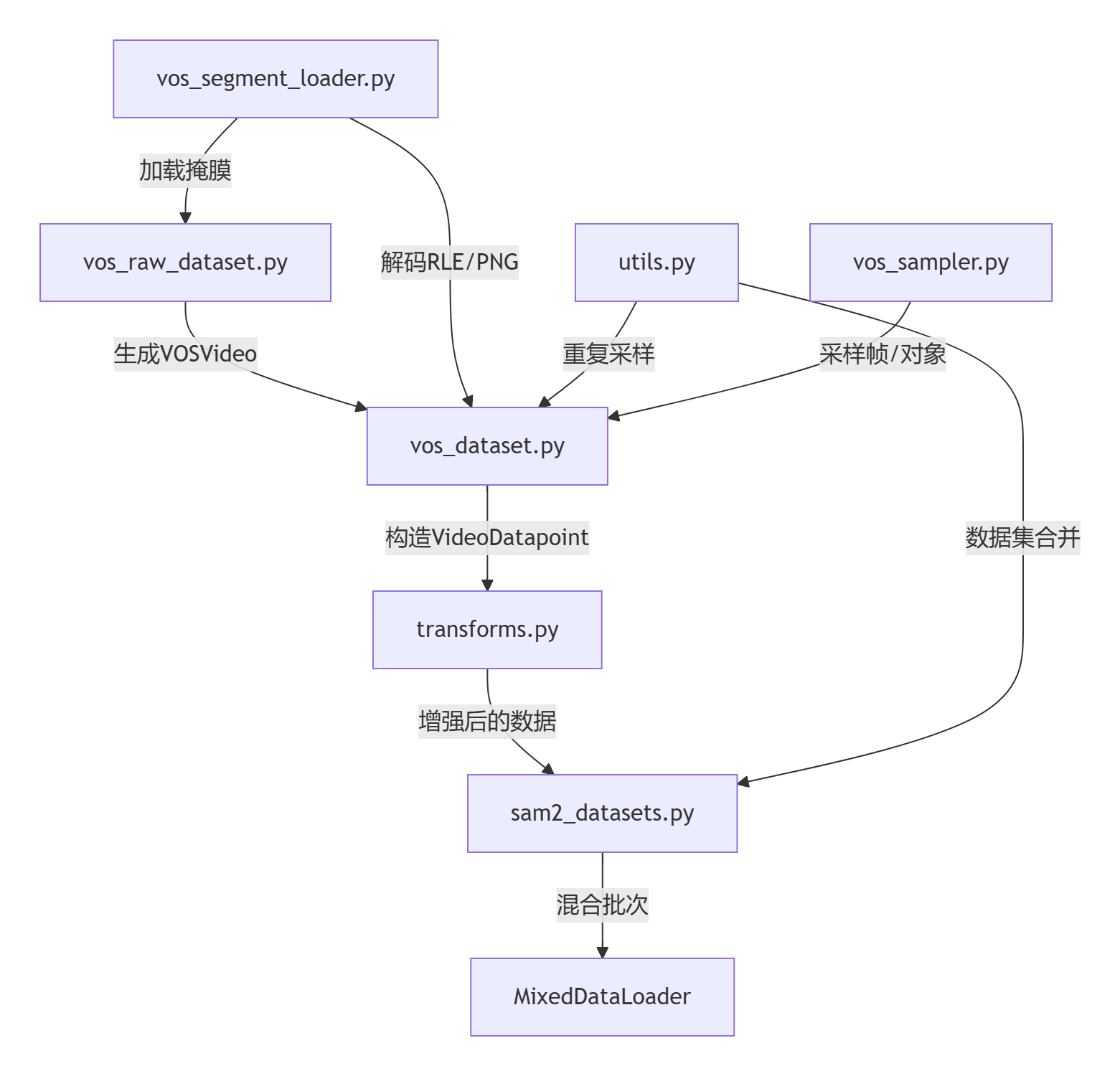
3. vos_sampler.py
3.1 基础模块类
1)SampledFramesAndObjects数据类
定义了视频帧数索引和对象id索引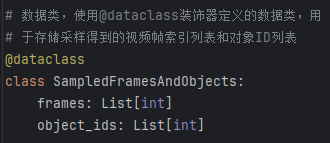
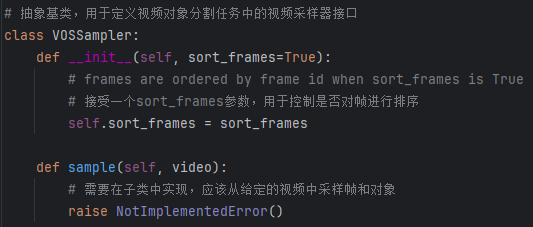
2)VOSSampler 抽象基类
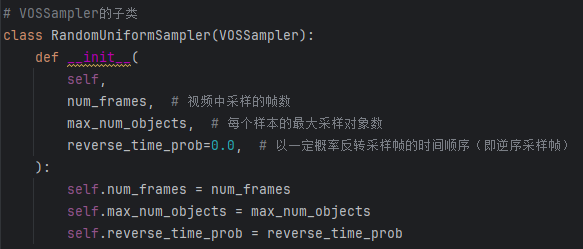
3.2 子类RandomUniformSampler
用于在视频对象分割任务中随机均匀地采样帧和对象
- 初始化构造
- sample方法
-
输入参数:video–包含帧信息的VOSVideo对象,segment_loader–用于加载视频帧掩码的加载器
-
检查帧数量:确保视频帧数量足够采样num_frames帧,如果不够则抛出异常

-
随机选择起始帧进行采样:随机选择一个起始帧索引start,确保从该索引开始的连续num_frames帧都在视频范围内
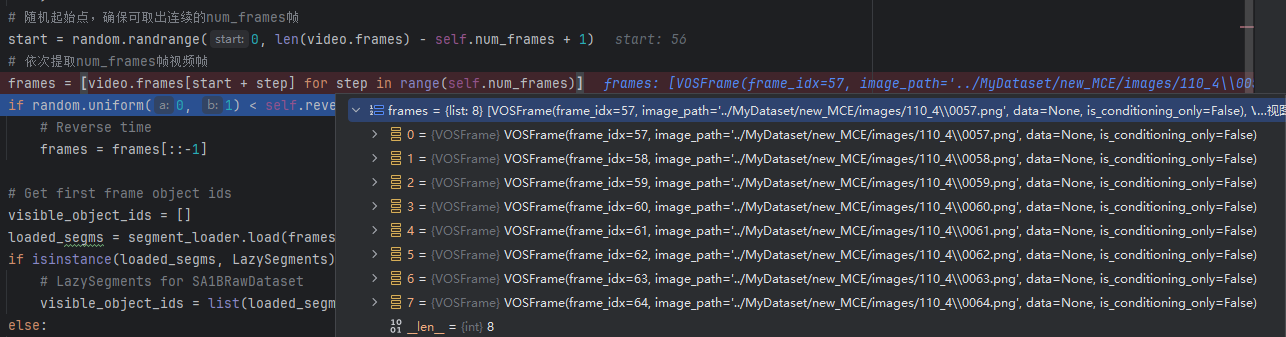
-
可选的反转帧顺序:以概率反转采样帧的顺序
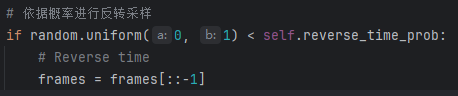
-
加载第一帧的对象掩码,并检查掩码中是否包含被检测对象

使用segment_loader的load方法,得到对象mask字典,字典的key是调色盘掩码png图像中,不同对象自身对应的像素值,字典的value是将不同对象分离后得到的单对象mask掩码,掩码的值是True和False。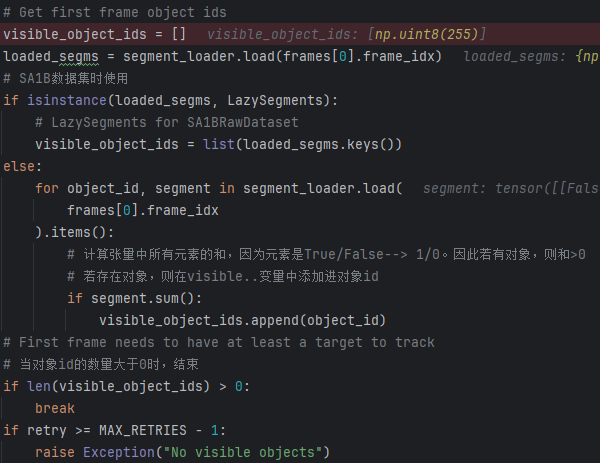
这里的逻辑是,我们使用segment_load方法得到的mask是true.false填充的,此时直接计算sum,若和>0,则说明存在obj。将mask对应的key添加进变量visible中,若visible中的长度>0,则说明是有效采样,退出循环。 -
随机采样对象ID:从可见对象ID列表中随机采样max_num_objects个对象ID,如果可见对象ID少于最大值,则全部采样
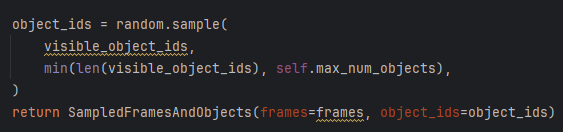
-
返回成基础数据类型
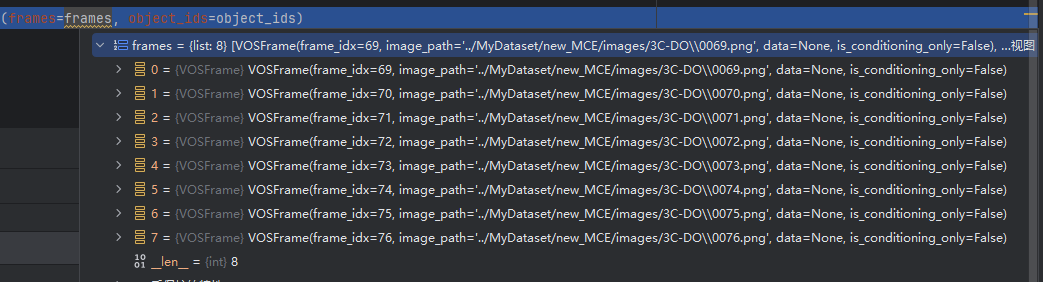
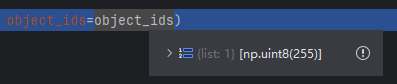
-
3.3 子类EvalSampler
# VOSSampler的子类
class EvalSampler(VOSSampler):
"""
VOS Sampler for evaluation: sampling all the frames and all the objects in a video
"""
def __init__(
self,
):
super().__init__()
def sample(self, video, segment_loader, epoch=None):
"""
Sampling all the frames and all the objects
"""
if self.sort_frames:
# ordered by frame id,按帧号排序
frames = sorted(video.frames, key=lambda x: x.frame_idx)
else:
# use the original order
frames = video.frames
# 加载首帧的所有对象ID
object_ids = segment_loader.load(frames[0].frame_idx).keys()
if len(object_ids) == 0:
raise Exception("First frame of the video has no objects")
# 返回所有帧和对象ID
return SampledFramesAndObjects(frames=frames, object_ids=object_ids)
4. vos_dataset.py
1)VOSDataset方法
- 初始化
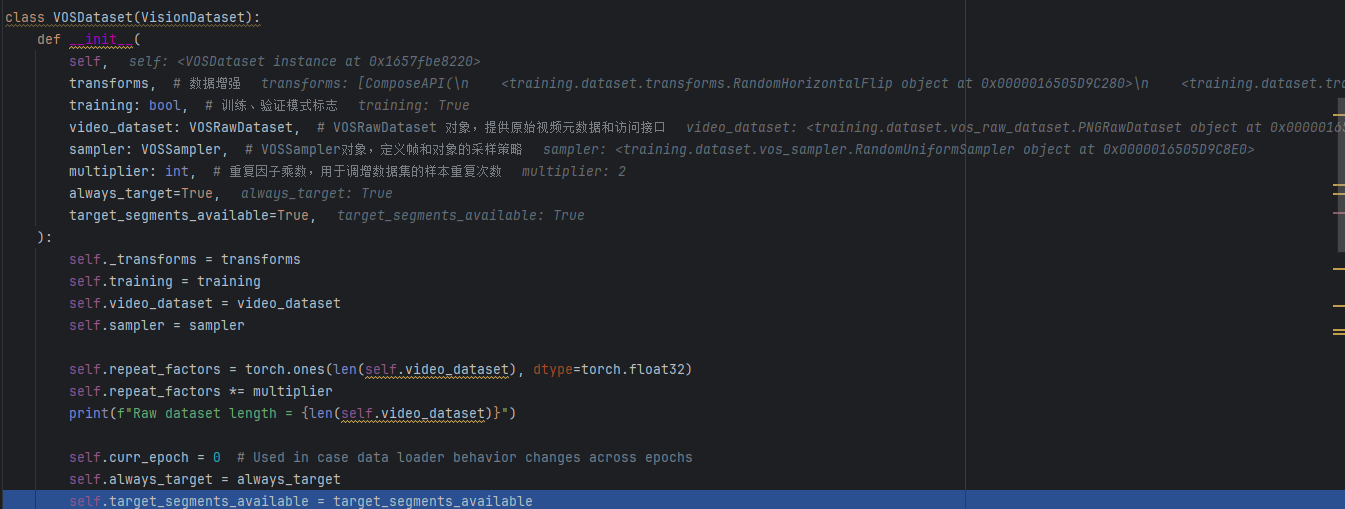
- __get_datapoint
- 调用sampler.sample从视频中采样帧和对象
具体见前面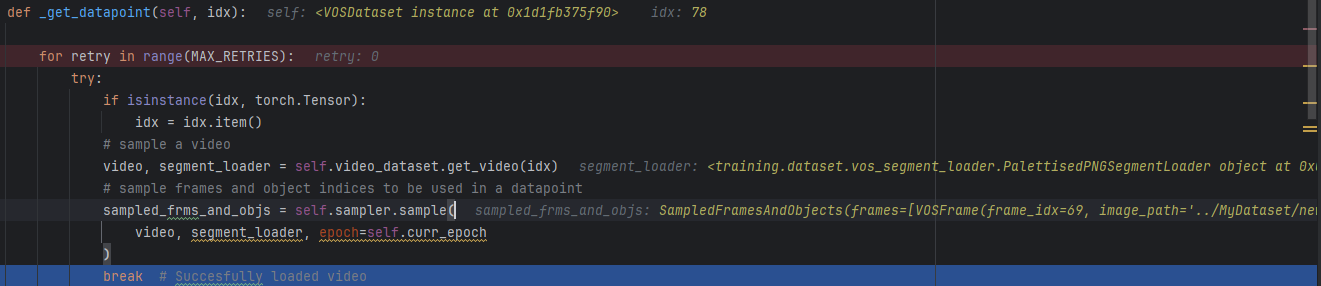
- 调用construct方法构建数据集
- 调用transform方法增强数据集
- 调用sampler.sample从视频中采样帧和对象
datapoint = self.construct(video, sampled_frms_and_objs, segment_loader)
for transform in self._transforms:
datapoint = transform(datapoint, epoch=self.curr_epoch)
return datapoint
- construct 数据集构建----构建一个videodatapoint 样例去进行transforms
- 输入参数:

- 加载图像,通过load_images 高效读取RGB图像----调用load_images方法
- 构建VideoDatapoint数据
- 遍历采样的样本 sampled_frames
- 处理图像数据,实例化Frame数据类型,并添加进 images列表中
- 调用segment_loader的load方法,得到单个obj的mask张量

- 检查得到的segments,确保segments中每一个张量都不为空,即都有掩膜
- 检查segments是否包含全部obj,若不是则表明并不是全程都可监控到对象,若一开始的config设置里,设置的是一直都有检测对象,则创建一个虚假的全0掩码,若没有设置,则不做任何操作。
- 将segments和先前得到的读取图像等放入Frame数据类型中,并构建成一个采样images列表
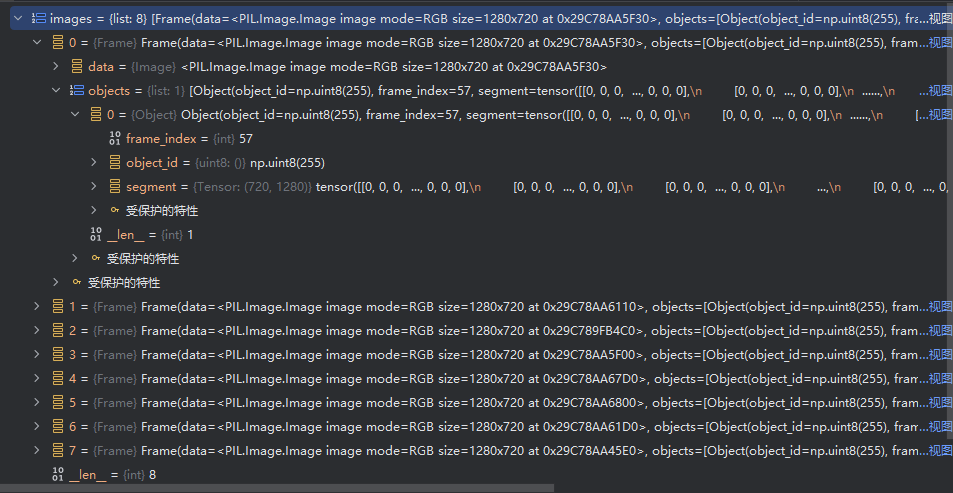
- 将上面得到的images组装成videopoint类型
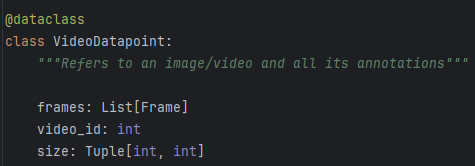
- 输入参数:
- load_images,高效加载图像,避免重复读取相同路径
- 可能存在的重复读取场景:多次采样同一视频的不同片段;数据增强时需要多次访问同一原始图像
- 1、首先创建两个参数all_images 存储最终加载的PIL图像,cache记录已加载的文件路径和索引,避免重复id
- 2、遍历所有帧,若存在已有张量数据,则直接将该张量数据转换成pil数据
- 3、若不存在已有张量,则查看cache中是否有记录,若有则直接从all_images中复制
- 4、若cache中没有记录,则读取文件并在cache中更新缓存的图像信息
# 高效加载图像,利用缓存避免重复读取相同路径
def load_images(frames):
all_images = []
cache = {}
for frame in frames:
if frame.data is None:
# Load the frame rgb data from file
path = frame.image_path
if path in cache:
all_images.append(deepcopy(all_images[cache[path]]))
continue
with g_pathmgr.open(path, "rb") as fopen:
all_images.append(PILImage.open(fopen).convert("RGB"))
cache[path] = len(all_images) - 1
else:
# The frame rgb data has already been loaded
# Convert it to a PILImage
all_images.append(tensor_2_PIL(frame.data))
return all_images
6. transforms.py
这里进行简单的讲解+伪代码叙述逻辑
- 水平翻转 hflip—对指定帧的图像和所有对象掩膜进行水平翻转
def hflip(datapoint, index):
# 翻转图像
datapoint.frames[index].data = F.hflip(datapoint.frames[index].data)
# 翻转每个对象的掩膜
for obj in datapoint.frames[index].objects:
if obj.segment is not None:
obj.segment = F.hflip(obj.segment)
return datapoint
- 尺寸计算 get_size_with_aspect_ratio — 根据目标尺寸和最大限制计算保持宽高比的图像尺寸
def get_size_with_aspect_ratio(image_size, size, max_size):
w, h = image_size
# 处理最大尺寸限制
if max_size and (max(w,h)/min(w,h)*size > max_size):
size = max_size * min(w,h)/max(w,h)
# 计算新尺寸
if w < h:
return (size, int(size * h/w))
else:
return (int(size * w/h), size)
- 调整大小 resize — 调整图像和掩膜尺寸
def resize(datapoint, index, size, max_size, square, v2):
# 计算目标尺寸
if square:
size = (size, size)
else:
size = get_size_with_aspect_ratio(cur_size, size, max_size)
# 调整图像
if v2:
datapoint.frames[index].data = Fv2.resize(data, size, antialias=True)
else:
datapoint.frames[index].data = F.resize(data, size)
# 调整掩膜
for obj in datapoint.frames[index].objects:
obj.segment = F.resize(obj.segment[None,None], size).squeeze()
- 填充 pad --对图像和掩膜进行填充
def pad(datapoint, index, padding, v2):
# 图像填充
if len(padding) == 2:
datapoint.frames[index].data = F.pad(data, (0,0,padding[0],padding[1]))
else:
datapoint.frames[index].data = F.pad(data, padding)
# 掩膜填充
for obj in datapoint.frames[index].objects:
if v2:
obj.segment = Fv2.pad(obj.segment, padding)
else:
obj.segment = F.pad(obj.segment, padding)
- RandomHorizontalFlip – 随机水平翻转,支持帧间一致性
class RandomHorizontalFlip:
def __call__(self, datapoint):
if self.consistent_transform:
if random.random() < self.p:
for i in range(len(datapoint.frames)):
datapoint = hflip(datapoint, i)
else:
for i in range(len(datapoint.frames)):
if random.random() < self.p:
datapoint = hflip(datapoint, i)
return datapoint
- RandomResizeAPI—随机调整尺寸
class RandomResizeAPI:
def __call__(self, datapoint):
size = random.choice(self.sizes)
for i in range(len(datapoint.frames)):
datapoint = resize(datapoint, i, size)
return datapoint
- ColorJitter — 随机调整颜色
- RandomAffine — 随机仿射变换(旋转、平移、缩放、剪切)
- RandomMosaicVideoAPI — 马赛克增强,将图像分割为网格并随机排列。
- …

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)