大模型推理:大模型推理部署框架汇总
大模型推理引擎综述文章重点信息总结
一、信息来源
本文章是对韩国科学技术研究院于2025年5月8号发布的大模型推理服务框架综述文章《ASurvey on Inference Engines for Large Language Models:Perspectives on Optimization and Efficiency》做一个记录,方便后续查阅。
论文Github: https://github.com/sihyeong/Awesome-LLM-Inference-Engine
二、LLM推理流程
- 大模型结构和主流的Attention机制:当前大模型的架构基本是Decoder架构,也基本采用MQA(可通过config.json文件的num_key_value_heads查看分组信息,比如值为2,则是2个Query共享一对Key/Value值)。
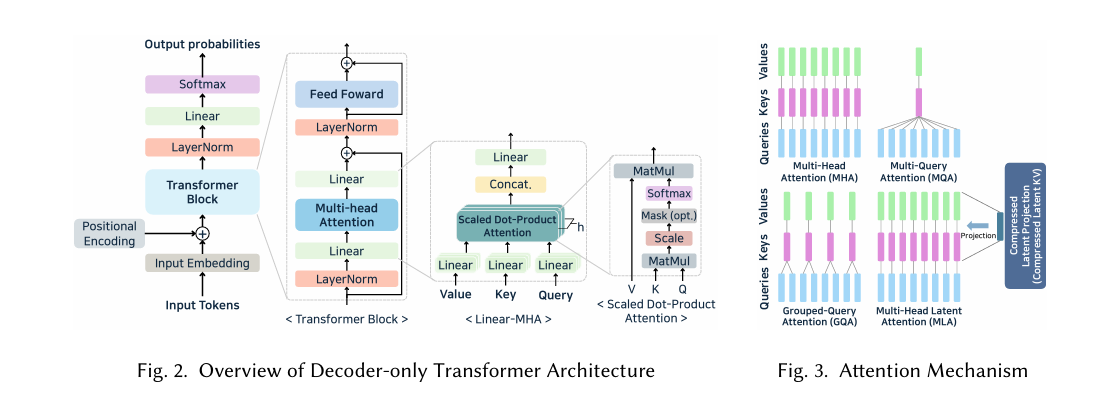
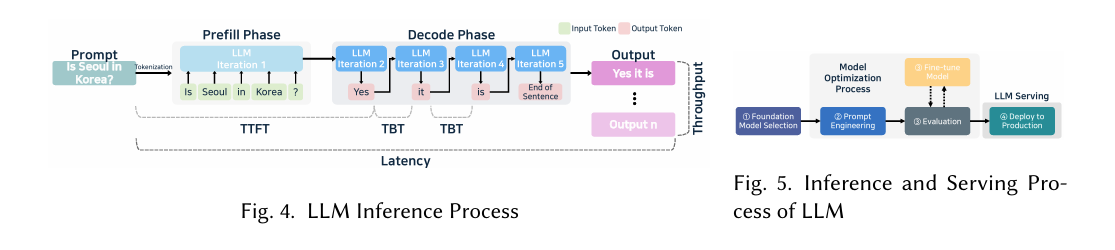
- 大模型推理流程:自回归解码(TTFT-首Token到达时间,TBT-Token与Token生成之间的时间间隔,Latency-输入至输出所耗费的时间)
三、论文重点关注点
大模型推理引擎选型时,根据以下四个方向,结合自己的使用场景,基本上都能够选定合适的推理引擎,根据个人经验,vLLM、Sglang适合大多数场景,但拥有一定的上手门槛,个人本地尝鲜Ollama足够了。补充个信息,Mac M芯片上部署大模型推荐使用LM Studio结合MLX推理引擎,当前能够获得M芯片上的最大推理性能。
-
大模推理引擎工程化和优化涉及到的知识分类
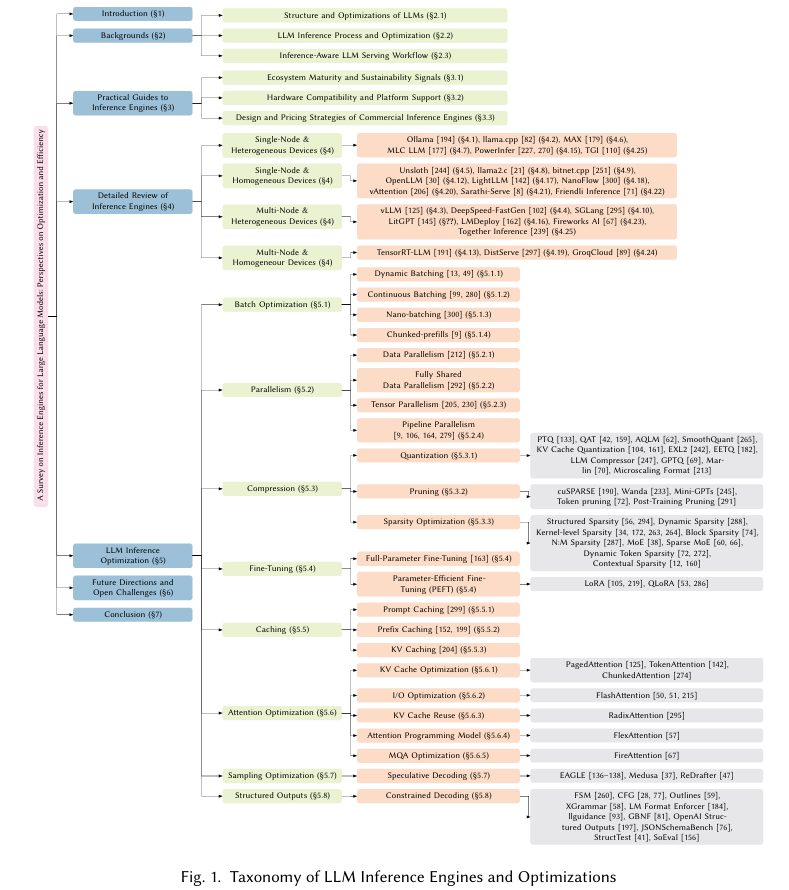
-
大模型推理引擎对比六大维度:模型通用性、易于部署和使用、端到端延迟、吞吐率优化以及可扩展性
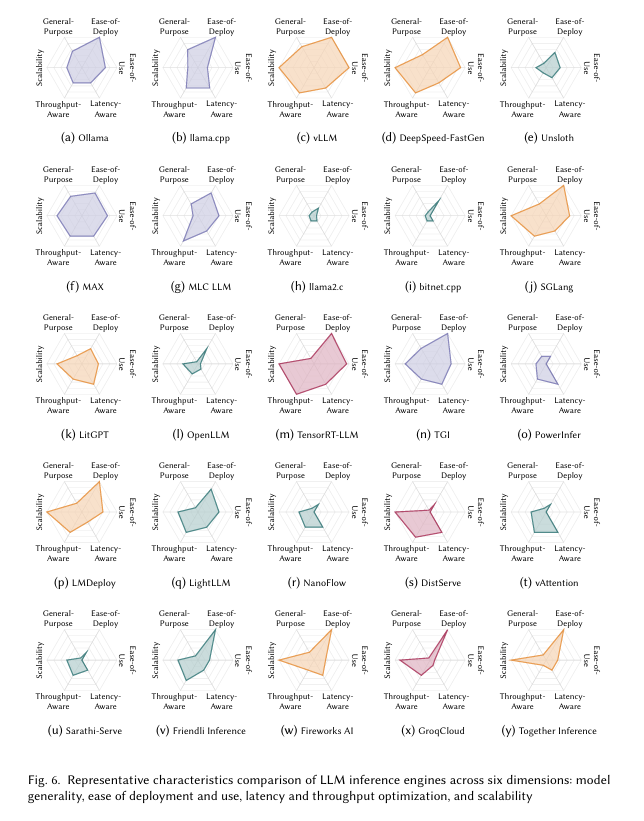
-
大模型推理引擎的开源信息,包括Github信息、推出日期、开源支持、支持模型的程度、是否有文档、交流渠道等

-
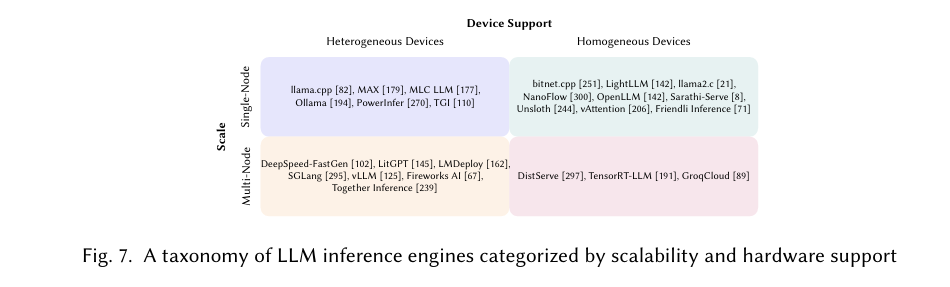
大模型推理引擎支持的硬件情况

四、模型推理引擎维度评估指标解释:
🧑💻 易用性:
评估文档质量与社区活跃度。评分越高代表开发者体验越友好,社区支持越完善。
⚙️ 部署便捷性:
衡量通过pip/APT/Homebrew/Conda/Docker/源码编译/预构建二进制等工具的安装简易度与速度。
🌐 通用性支持:
反映支持的LLM模型范围与硬件平台广度。数值越高表明对多样化模型家族和运行环境的兼容性越强。
🏗 扩展能力:
评估引擎在边缘设备、服务器及多节点集群上的运行效能。高分代表具备应对大规模分布式工作负载的能力。
📈 吞吐量优化:
检测是否集成持续批处理、并行计算、缓存复用等提升吞吐量的关键技术。
⚡ 低延迟优化:
评估是否支持无阻塞调度、分块预填充、优先级执行等降低延迟的专项技术。
五、扩展知识
- vLLM production-stack: Github、Usage Document、vLLM Blog Introduction
- LLM推理引擎综述:优化与效率的多维探索

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)