MMRotate使用记录(MMDetection类似):数据集的创建、加载及测试
MMRotate、MMDetection学习
train_pipeline
数据集的config配置文件如下
train_pipeline = [
dict(type='mmdet.LoadImageFromFile', backend_args=backend_args),
dict(type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
dict(type='ConvertBoxType', box_type_mapping=dict(gt_bboxes='rbox')),
dict(type='mmdet.Resize', scale=(1024, 1024), keep_ratio=True),
dict(
type='mmdet.RandomFlip',
prob=0.75,
direction=['horizontal', 'vertical', 'diagonal']),
dict(
type='RandomRotate',
prob=0.5,
angle_range=180,
rect_obj_labels=[9, 11]),
dict(
type='mmdet.Pad', size=(1024, 1024),
pad_val=dict(img=(114, 114, 114))),
dict(type='mmdet.PackDetInputs')]
train_pipeline列表类型的数据,列表中每一个元素都是对数据的一个处理方法,根据列表名字中的pipeline可以看出该列表是对输入的训练数据按照流水线顺序处理。
train_pipeline中每个元素为字典类型的数据,其中关键词type对应的value为处理方法的名称,比如type='RandomRotate’表示对数据采用随机旋转的处理方法。
dict(
type='RandomRotate',
prob=0.5,
angle_range=180,
rect_obj_labels=[9, 11]),
后面的keys如“prob”,"angle_angle"和“rect_obj_labels”为RandomRotate类中的其他参数名称,参考下列关于RandomRotate类的定义。
@TRANSFORMS.register_module()
class RandomRotate(BaseTransform):
def __init__(self,
prob: float = 0.5,
angle_range: int = 180,
rect_obj_labels: Optional[List[int]] = None,
rotate_type: str = 'Rotate',
**rotate_kwargs) -> None:
assert 0 < angle_range <= 180
self.prob = prob
self.angle_range = angle_range
self.rect_obj_labels = rect_obj_labels
self.rotate_cfg = dict(type=rotate_type, **rotate_kwargs)
self.rotate = TRANSFORMS.build({'rotate_angle': 0, **self.rotate_cfg})
self.horizontal_angles = [90, 180, -90, -180]
train_dataloader
数据集的加载在配置文件中的代码如下,train_dataloader是字典类型的数据,key为参数名称,对应的value是参数的设置,这里常用的设置为batch_size,num_workers,sampler以及dataset,其中batch_size,num_workers的含义通过名字就可以看出。
dataset_type = 'DOTADataset'
data_root = r'D:\Trial\MMRotate\mmrotate-1.x\mmrotate-1.x\DOTA\train'
backend_args = None
train_dataloader = dict(
batch_size=8,
num_workers=8,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
batch_sampler=None,
pin_memory=False,
dataset=dict(
type=dataset_type,
data_root=data_root,
ann_file='labelTxt/',
data_prefix=dict(img_path='images/'),
filter_cfg=dict(filter_empty_gt=True),
pipeline=train_pipeline))
另外需要注意dataset,dataset同样为字典类型的数据,其中常用的参数及对应的含义如下表
| 参数 | 含义 |
|---|---|
| type | 数据集类型,这里为DOTA数据集 |
| data_root | 存放数据的根目录,以DOTA数据集为例该目录下至少要有labelTxt和images两个文件夹,与后面的ann_file参数和data_prefix参数中的img_path对应 |
| ann_file | 存放标签相对路径名称,与data_root参数对应 |
| data_prefix | 字典类型,主要关注关键词img_path,该key对应的value为存放图片的相对路径名称 |
| pipeline | 字典类型的数据,对应train_pipeline,存放数据的加载以及数据增强的流水顺序处理方法 |
如何测试数据集的制作是否正确
这里举一个例子,假如我自己构建了一个新的数据集并且标签标注形式与DOTA完全一致,这里我就可以直接采用已有的DOTADataset构建数据集,此时可将train_dataloader中的pipeline置为空列表,data_root修改为自己数据集的根目录,然后导入DOTADataset类填写相关参数创建数据实例如下:
from mmrotate.datasets import DOTADataset
data_root = r'D:\Trial\MMRotate\mmrotate-1.x\mmrotate-1.x\DOTA\train'
data = DOTADataset(
data_root=data_root,
ann_file='labelTxt/',
data_prefix=dict(img_path='images/'),
filter_cfg=dict(filter_empty_gt=True),
pipeline=[])
创建data之后便可直接调用data[0]验证输出是否正常即可,如图所示: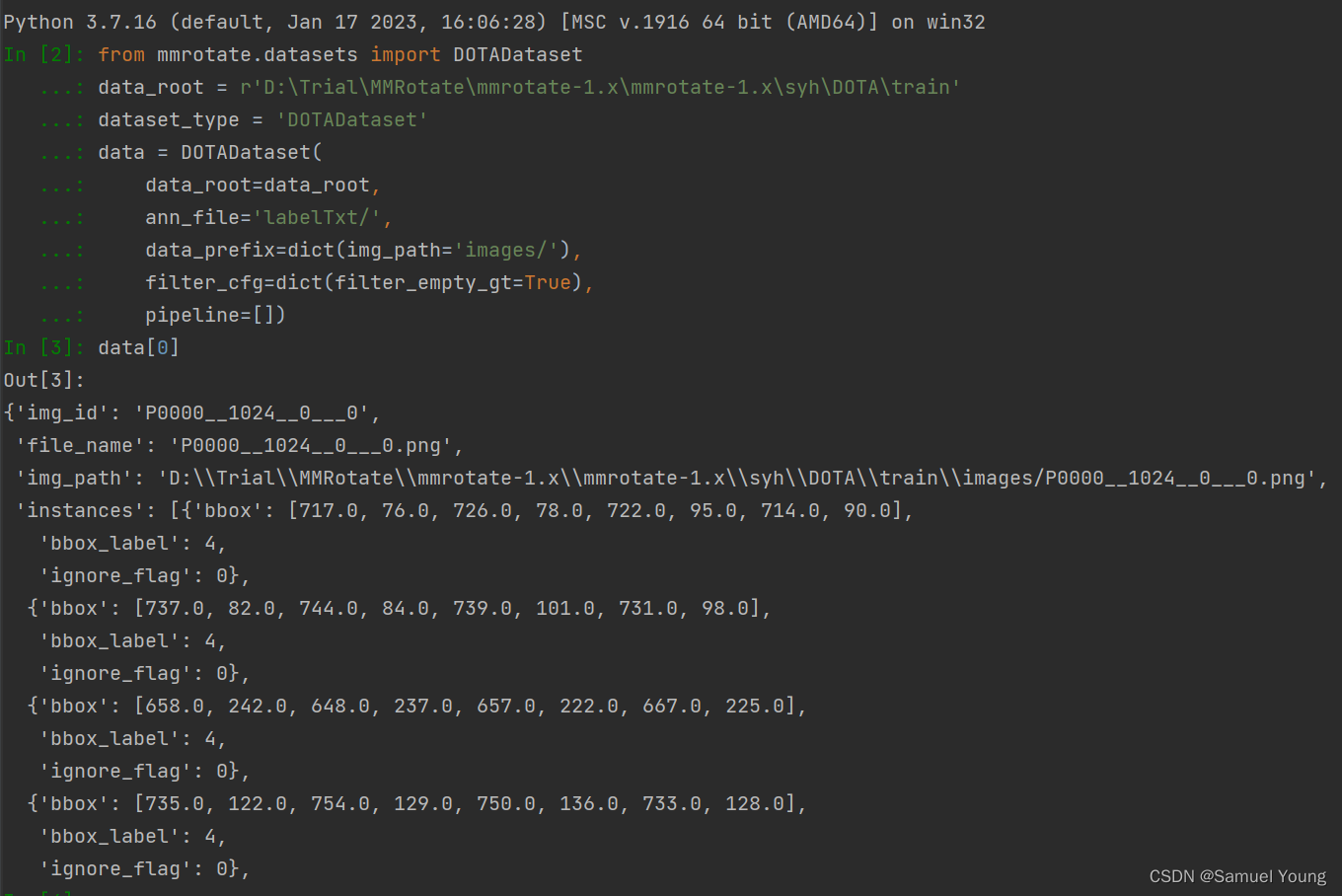
如何测试个人构造的数据增强方法是否正确
有时候官方提供的数据增强方法接口用在自己的数据集上可能存在问题或者个人提出了一些新的数据增强方法希望进行实现,此时就需要验证自己写的方法受否在按照自己的想法运行。
我们可将写出的新方法放入pipeline列表中再运行,观察代码是否报错,输出是否符合预期即可。
比如我创建了一个名为xxx的数据增强方法,希望将它放在随机旋转之后实现一定的功能,那么代码如下:
train_pipeline = [
dict(type='mmdet.LoadImageFromFile', backend_args=backend_args),
dict(type='mmdet.LoadAnnotations', with_bbox=True, box_type='qbox'),
dict(type='ConvertBoxType', box_type_mapping=dict(gt_bboxes='rbox')),
dict(type='mmdet.Resize', scale=(1024, 1024), keep_ratio=True),
dict(
type='mmdet.RandomFlip',
prob=0.75,
direction=['horizontal', 'vertical', 'diagonal']),
dict(
type='RandomRotate',
prob=0.5,
angle_range=180,
rect_obj_labels=[9, 11]),
dict(
type='xxx',
arg1 = ...,
arg2 = ...,
arg3 = ...)]
from mmrotate.datasets import DOTADataset
data_root = r'D:\Trial\MMRotate\mmrotate-1.x\mmrotate-1.x\DOTA\train'
data = DOTADataset(
data_root=data_root,
ann_file='labelTxt/',
data_prefix=dict(img_path='images/'),
filter_cfg=dict(filter_empty_gt=True),
pipeline=[])
然后调用data[0],观察是否报错,不报错的情况下输出是否与预期一致。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)