【SAM2代码解析】数据集处理1
原始视频/标注…↓…[vos_segment_loader.py] → 加载掩膜…↓…[vos_raw_dataset.py] → 生成VOSVideo(元数据+帧列表)…↓…[vos_dataset.py] → 调用VOSSampler选择帧/对象 → 构造VideoDatapoint…↓…[transforms.py] → 应用翻转/缩放/马赛克等增强 → 标准化Tensor…↓…
数据集处理
以下是SAM2数据加载流程的模块关联与数据流解析,包含7个核心文件的作用及交互关系: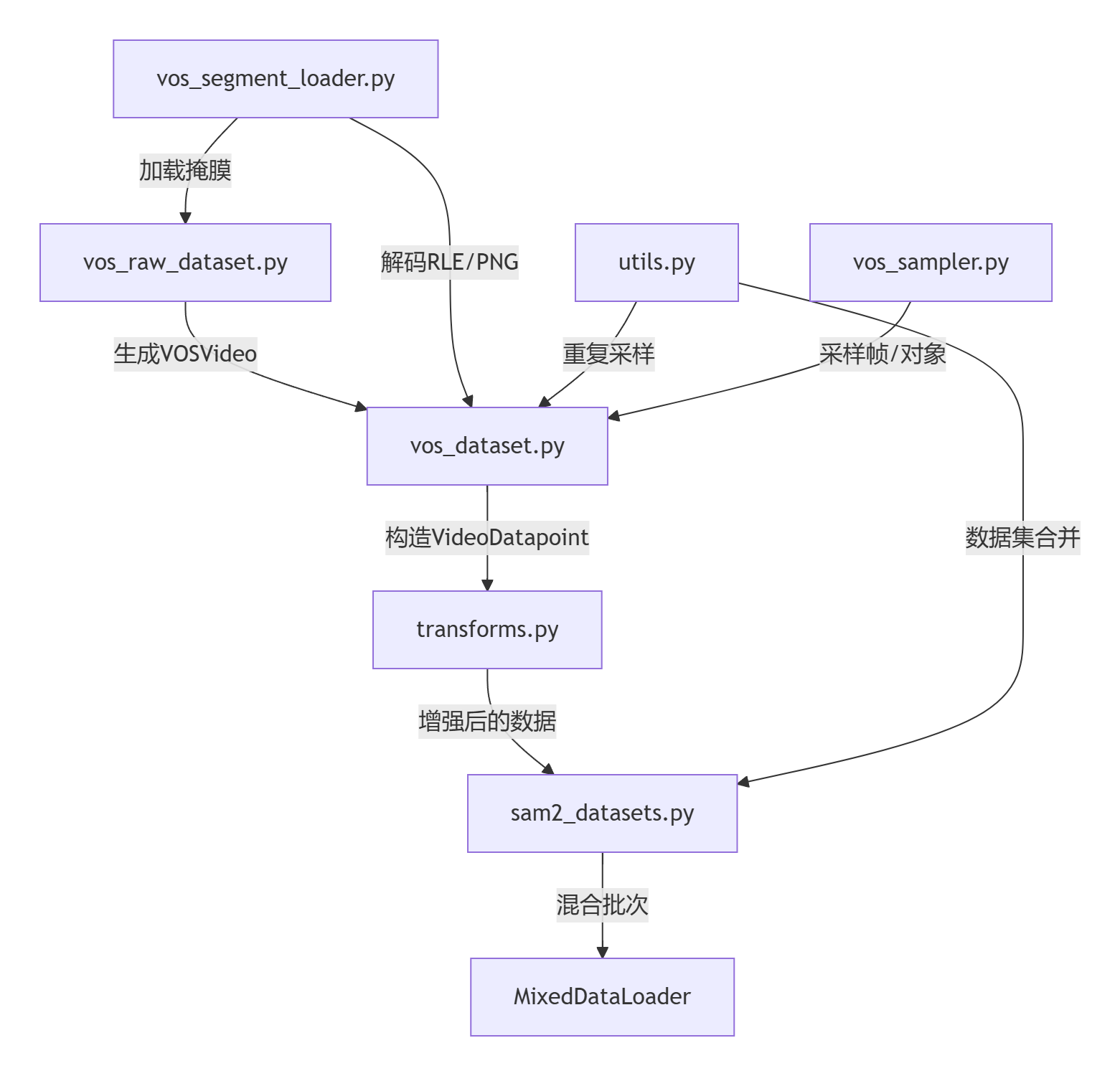
原始视频/标注
…↓…
[vos_segment_loader.py] → 加载掩膜
…↓…
[vos_raw_dataset.py] → 生成VOSVideo(元数据+帧列表)
…↓…
[vos_dataset.py] → 调用VOSSampler选择帧/对象 → 构造VideoDatapoint
…↓…
[transforms.py] → 应用翻转/缩放/马赛克等增强 → 标准化Tensor
…↓…
[utils.py] → ConcatDataset合并数据集 → RepeatFactorWrapper调整频率
…↓…
[sam2_datasets.py] → TorchTrainMixedDataset管理混合 → MixedDataLoader生成批次
…↓…
模型训练
1. vos_segment_loader.py
加载分割掩膜数据,将不同格式的标注转换为统一的二进制掩膜张量,供模型训练或推理使用。
程序中一共有四个方法来处理四种不同格式的掩膜:
1、处理JSON格式的RLE掩膜标注(JSONSegmentLoader)
2、处理调色板PNG格式掩膜标注(PalettisedPNGSegmentLoader)
3、处理多对象分文件存储的PNG掩膜标注(MultiplePNGSegmentLoader)
4、处理SA-1B数据集大规模掩膜标注(LazySegments)
4.1 SA-1B数据集大规模掩膜处理(LazySegments),延迟掩膜处理,以减少内存这里只解析调色板PNG格式掩膜标注
调色板PNG格式掩膜处理(PalettisedPNGSegmentLoader)
处理每个PNG文件包含多个对象掩膜的数据(如DAVIS数据集),通过调色板索引区分不同对象。
1)初始化构造
- 1、传入掩膜文件根目录
- 2、使用os.listdir方法获取所有PNG文件名
- 3、构建帧ID到文件名的帧映射(兼容不同数字长度的文件名)
- 这里的做法是将001.png的后缀名和图像名分开
- 再使用int(图像名)的方式,得到实际整数,将它和原来的图像名相对应。
下图是debug时的记录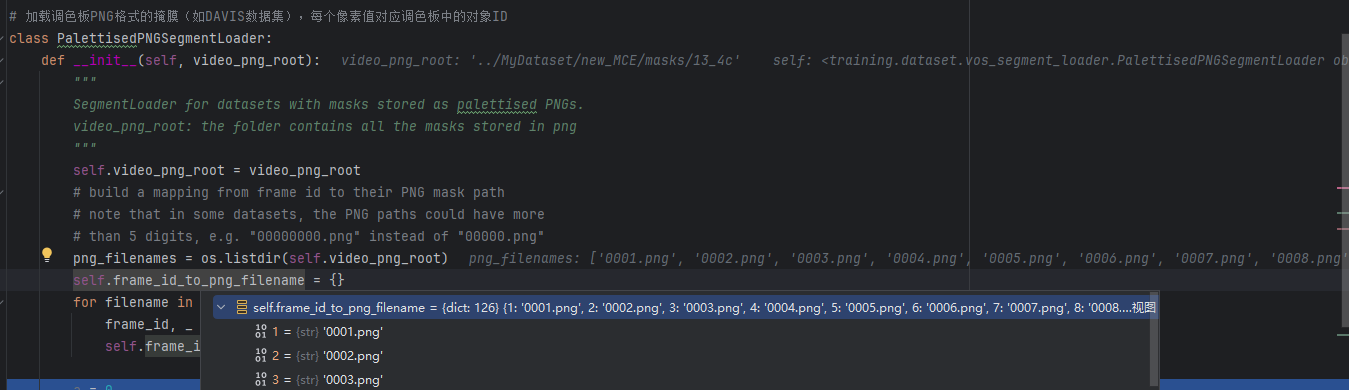
2)掩膜加载方法load
以下是源码+debug的中间变量记录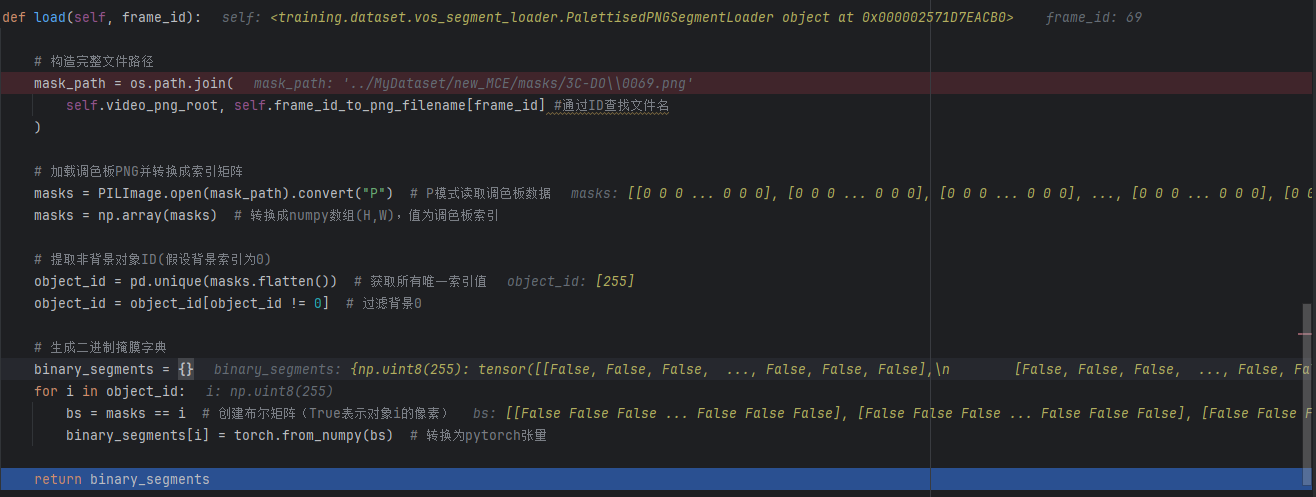
- 1、构造完整文件路径,eg:“…/MyDataset/new_MCE/masks/3C/0069.png”
- 这里通过frame_id查找文件名
- 2、加载调色板PNG并转换为索引矩阵,下图是索引矩阵的可视化:
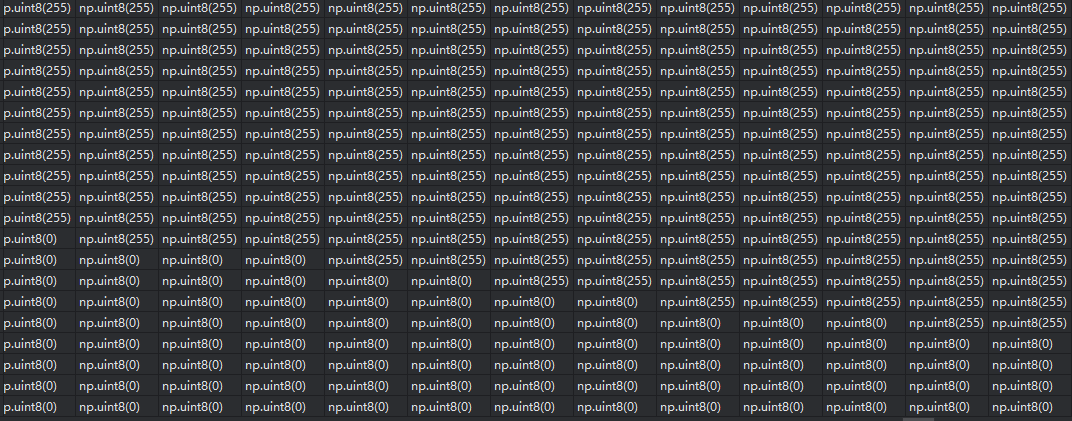
- 3、提取非背景对象ID,得到唯一索引值,同时过滤背景0
- 以上图为例,最开始会得到[255, 0]两个索引值(只有一个对象)
- 然后过滤背景0后,得到索引值 255
- 4、生成二进制掩膜字典
- 遍历第三步得到的索引值
- 在遍历的过程中,将每个对象的mask分开,同时转换成True/False值的张量
- 将分开得到的mask存储在字典binary_segments中,这里key为索引值,value是上一步得到的mask张量,如下图所示:

3)长度方法 len
这里没有定义,后续根据自己的需要定义。
2、 vos_raw_dataset.py
2.1 基类模块
1)单帧数据容器VOSFrame
@dataclass
class VOSFrame: #单帧数据容器
# 帧在视频中的索引
frame_idx: int
# 图像文件的路径
image_path: str
# 用于缓存加载后的图像数据,避免重复读取
data: Optional[torch.Tensor] = None
# 标记该帧是否用于条件生成
is_conditioning_only: Optional[bool] = False
2)视频数据容器VOSVideo
@dataclass
class VOSVideo: #视频数据容器
# 视频名称
video_name: str
# 视频唯一ID
video_id: int
# 该视频所有帧的列表
frames: List[VOSFrame]
def __len__(self):
#返回视频总帧数
return len(self.frames)
3)统一数据集接口VOSRawDataset
# 原始数据集接口,定义视频数据集的统一接口,强制子类实现 get_video
class VOSRawDataset:
def __init__(self):
pass
def get_video(self, idx):
raise NotImplementedError() #子类必须实现此方法
2.2 处理图像和标注掩码 – PNGRawDataset(VOSRawDataset)
这里一共有三个不同的数据集处理方法,分别为:①处理PNG格式图像和掩码;②处理SA-1B大尺度掩膜数据;③处理JSON格式标注。这里只详解PNG格式的处理方法
1)初始化构造
- 参数初始化
- 读取视频子集
若提供了file_list_txt文件路径,则从文件中读取视频名称列表。若没有提供,则直接从img_folder目录中列出所有文件作为视频名称列表。
- 读取并处理排除的视频文件
若提供了excluded_videos_list_txt文件路径,则从文件中读取要排除的视频名称列表
- 检查视频名称是否在排除列表中
现在有两个列表subset和excluded_files,分别包含视频子集名称和需要去除的视频子集名称。因此遍历excluded_files,若视频名不包含在excluded_files中,则将取出该视频名放入video_names:
- 单对象模式处理
这个是针对“处理多对象分文件夹存储的PNG掩膜”情况下的。 - 根据帧数量对视频名称进行重复
如果frames_sampling_mult 为真,则根据每个视频的帧数量对视频名称进行重复
我们在前面首先得到了视频名列表–self.video_names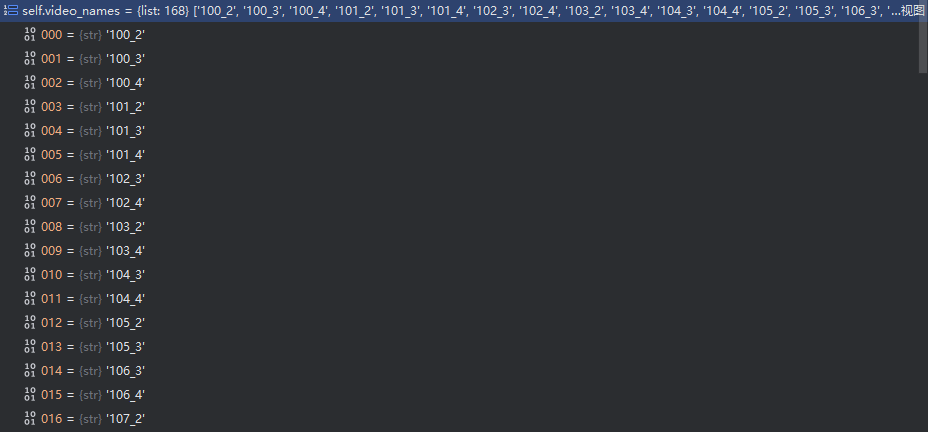
现在我们根据每个视频名里面有多少视频帧数,将视频名数量扩展成和视频帧数数量一致: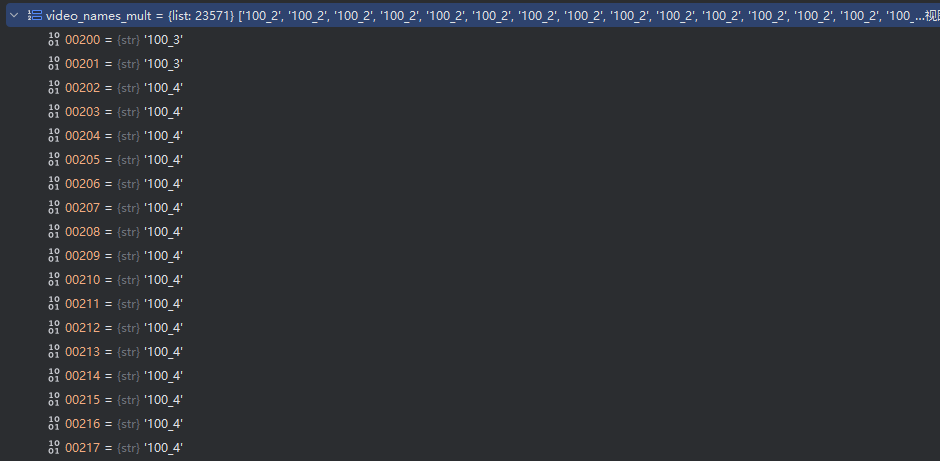
即假设原始的列表里有两个视频名:name1 和name2,每个视频文件夹内包含100个视频帧,则新设的列表名包含200个值(100个name1和100个name2)“根据帧数量对视频名称进行重复”是一种确保视频数据集中每个视频在采样过程中具有相同代表性的方法。这在处理帧数差异较大的视频数据集时特别有用,可以避免模型偏向于帧数较多的视频。
2)get_video方法
- 初始化获得目录
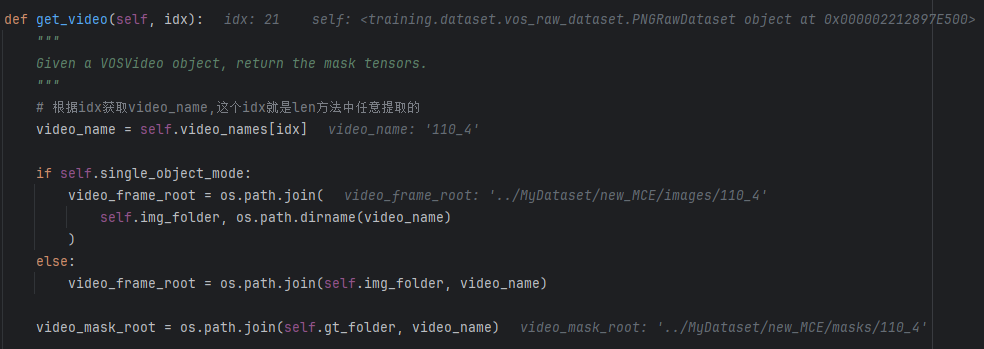
- 选择掩码加载器------看1、 vos_segment_loader.py
这里最终得到的是二进制掩膜字典,key是像素值,value是值为True/False的二维mask张量。key的像素值代表的是不同颜色mask勾勒的不同obj。详情见1
但是这里并没有调用load方法,仅仅是实例化对象,这里实例化后的segmentor包含如下图所示的两个初始化值
- 按照采样率采样,实例化帧对象和视频对象
# 先获取全部帧数
all_frames = sorted(glob.glob(os.path.join(video_frame_root, "*.png")))
if self.truncate_video > 0:
# 判断是否截断视频
all_frames = all_frames[: self.truncate_video]
frames = []
# 按帧率采样帧数
# all_frames[:: self.sample_rate] 是一种切片(slicing)语法,
# 用于从列表 all_frames 中按照指定的间隔(步长)获取元素
for _, fpath in enumerate(all_frames[:: self.sample_rate]):
#获取id
fid = int(os.path.basename(fpath).split(".")[0])
# 实例化帧对象
frames.append(VOSFrame(fid, image_path=fpath))
# 将实例化后的帧对象添加进视频对象中
video = VOSVideo(video_name, idx, frames)
帧对象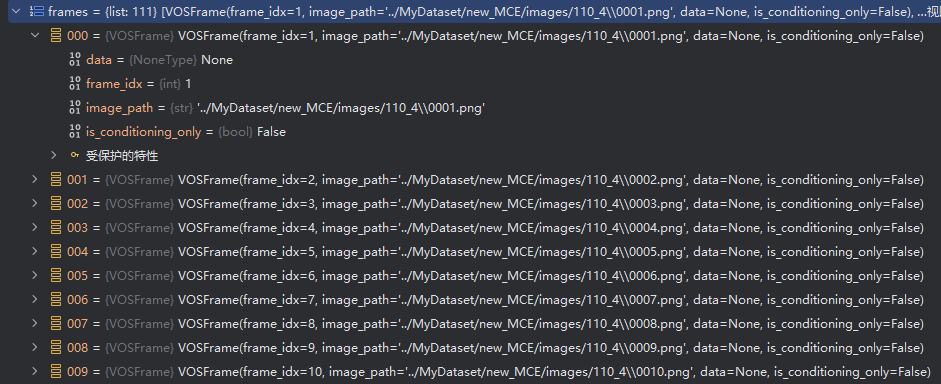
视频对象
3)len方法
根据self.video_names的数量设置长度

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 21
21 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)