RF-DETR训练自建数据集代码及训练过程Debug
本文主要记录了使用rf-detr这一新型目标检测模型架构进行训练自己搭建的数据集的过程,并给出了相应的实现代码以及训练过程中可能遇到的报错情况和解决方法,此外还给出了将YOLO数据集转换为COCO数据集格式的代码,以及给出了rf-detr的预训练模型的下载地址。
RF-DETR训练自建数据集代码及训练过程Debug
一、RF-DETR简介
RF-DETR是由Roboflow研究和推出的基于Transformer的实时目标检测模型架构,是目前在RF100-VL数据集上的SOTA模型,也是第一个在COCO数据集上超过了mAP@0.50:0.95=60的实时模型,官网地址为:https://github.com/roboflow/rf-detr。
rf-detr按照参数量划分共有三种模型,分别为base模型、base-2模型和large模型,base模型的参数量约为29M,large模型的参数量约为128M。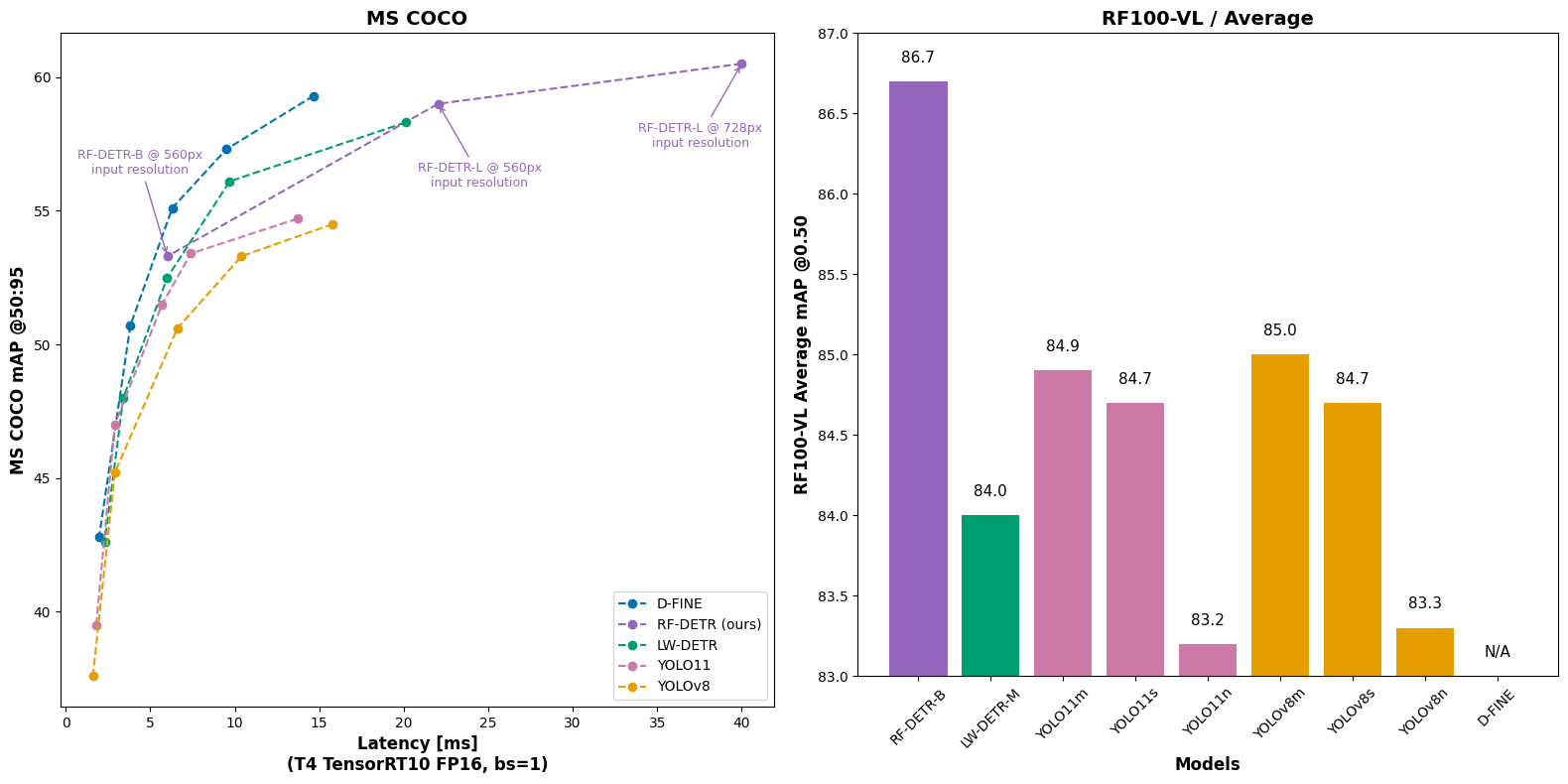
二、与YOLOv11、v12性能参数对比
rf-detr-base模型的性能如下图:
YOLOv11模型在COCO数据集上的性能及参数如下图:
YOLOv12模型在COCO数据集上的性能及参数如下图:
如表中所示,在COCO数据集上,rf-detr的base模型性能为mAP53.3,接近于YOLOv11的large模型的mAP53.4,略低于YOLOv12的large模型的mAP53.8,参数量略高于YOLOv11和v12的large模型。
三、训练自定义数据集
3.1训练环境配置
训练环境要求python版本≥3.9,pytorch版本为2.0及以上,此外官网未提及对操作系统的要求,本文的实际训练环境是在ubuntu系统上进行配置。
训练前只需安装rf-detr包,命令如下:
pip install rfdetr
3.2数据集格式要求
数据集格式要求为COCO数据集格式,要求格式如下图:
数据集分为train、valid和test文件夹,各个文件夹下存放图片文件和一个json标签文件。如果本地数据集格式为YOLO格式,那么可参照下面代码进行转换:
def convert_yolo2coco():
txt_path='dataset/valid.txt'
with open(txt_path, 'r') as f:
filepathList = f.readlines()
categories = [
{"id": 0, "name": "person", "supercategory": "none"},
{"id": 1, "name": "car", "supercategory": "none"},
{"id": 2, "name": "dog", "supercategory": "none"},
]
# 构建 COCO 格式字典
coco_format = {
"info": {"description": "YOLO to COCO Converted Dataset"},
"licenses": [],
"images": [],
"annotations": [],
"categories": categories
}
annotation_id = 0
image_id = 0
folderpath=txt_path.replace('.txt', '')
output_json=folderpath+'/_annotations.coco.json'
if not os.path.exists(folderpath):
os.mkdir(folderpath)
for filepath in tqdm(filepathList):
imgname = filepath.split('/')[-1].replace('\n', '')
shutil.copy(filepath.replace('\n', ''), folderpath+'/'+imgname)
coco_format["images"].append({
"id": image_id,
"width": 640,
"height": 640,
"file_name": imgname
})
labelpath = filepath.replace('images', 'labels').replace('.jpg', '.txt').replace('\n', '')
with open(labelpath, "r") as f:
for line in f.readlines():
parts = line.strip().split()
class_id = int(parts[0])
x_center, y_center, w, h = (float(parts[1]), float(parts[2]), float(parts[3]), float(parts[4]))
x = (x_center - w / 2) * 640
y = (y_center - h / 2) * 640
coco_format["annotations"].append({
"id": annotation_id,
"image_id": image_id,
"category_id": class_id,
"bbox": [x, y, w * 640, h * 640],
"area": w * 640* h * 640,
"iscrowd": 0,
"segmentation": [] # 只做目标检测,不需要分割
})
annotation_id += 1
image_id += 1
#break
# 保存为 COCO 格式 JSON 文件
with open(output_json, "w") as f:
json.dump(coco_format, f, indent=2)
print(f"转换完成,输出文件为: {output_json}")
3.3训练过程Debug
3.3.1训练代码
训练代码如下:
from rfdetr import RFDETRBase
model = RFDETRBase(pretrain_weights='rf-detr-base-coco.pth')
#model = RFDETRBase(pretrain_weights='rf-detr-base-2.pth')
#model = RFDETRLarge(pretrain_weights='rf-detr-large.pth')
model.train(dataset_dir='dataset', epochs=10, batch_size=12, grad_accum_steps=4, lr=1e-4, output_dir='model')
3.3.2预训练模型下载
官网给出的代码似乎只能在预训练模型上进行微调,因此需要通过pretrain_weights参数指定预训练模型,如果pretrain_weights参数为空,那么会自动下载预训练模型,这一过程很可能因网络问题无法下载成功,导致代码长时间无反应。
解决方法为,先将预训练模型下载到本地,三种模型官方下载地址如下:
https://storage.googleapis.com/rfdetr/rf-detr-base-coco.pth
https://storage.googleapis.com/rfdetr/rf-detr-base-2.pth
https://storage.googleapis.com/rfdetr/rf-detr-large.pth
CSDN免费下载地址:
https://download.csdn.net/download/weixin_46846685/90995591
https://download.csdn.net/download/weixin_46846685/90992340
3.3.3Transformer模型下载
预训练模型下载后,运行上面训练代码,可能还会报错:
OSError: We couldn’t connect to ‘https://huggingface.co’ to load this file, couldn’t find it in the cached files and it looks like facebook/dinov2-small is not the path to a directory containing a file named config.json.
Checkout your internet connection or see how to run the library in offline mode at ‘https://huggingface.co/docs/transformers/installation#offline-mode’
这是由于网络问题无法下载相关的Transformer模型导致的报错,解决方法为手动下载模型,然后在本地创建文件夹:facebook/dinov2-small,将模型文件复制该目录下。
模型官方下载地址为:https://huggingface.co/facebook/dinov2-small/tree/main
CSDN免费下载地址:https://download.csdn.net/download/weixin_46846685/90977658
至此,应该可以正常训练。
3.3.4训练过程其他参数
训练的其他参数如下表所示:
| 项目 | Value |
|---|---|
| dataset_dir | Specifies the COCO-formatted dataset location with train, valid, and test folders, each containing _annotations.coco.json. Ensures the model can properly read and parse data. |
| output_dir | Directory where training artifacts (checkpoints, logs, etc.) are saved. Important for experiment tracking and resuming training. |
| epochs | Number of full passes over the dataset. Increasing this can improve performance but extends total training time. |
| batch_size | Number of samples processed per iteration. Higher values require more GPU memory but can speed up training. Must be balanced with grad_accum_steps to maintain the intended total batch size. |
| grad_accum_steps | Accumulates gradients over multiple mini-batches, effectively raising the total batch size without requiring as much memory at once. Helps train on smaller GPUs at the cost of slightly more time per update. |
| lr | Learning rate for most parts of the model. Influences how quickly or cautiously the model adjusts its parameters. |
| lr_encoder | Learning rate specifically for the encoder portion of the model. Useful for fine-tuning encoder layers at a different pace. |
| resolution | Sets the input image dimensions. Higher values can improve accuracy but require more memory and can slow training. Must be divisible by 56. |
| weight_decay | Coefficient for L2 regularization. Helps prevent overfitting by penalizing large weights, often improving generalization. |
| device | Specifies the hardware (e.g., cpu or cuda) to run training on. GPU significantly speeds up training. |
| use_ema | Enables Exponential Moving Average of weights, producing a smoothed checkpoint. Often improves final performance with slight overhead. |
| gradient_checkpointing | Re-computes parts of the forward pass during backpropagation to reduce memory usage. Lowers memory needs but increases training time. |
| checkpoint_interval | Frequency (in epochs) at which model checkpoints are saved. More frequent saves provide better coverage but consume more storage. |
| resume | Path to a saved checkpoint for continuing training. Restores both model weights and optimizer state. |
| tensorboard | Enables logging of training metrics to TensorBoard for monitoring progress and performance. |
| wandb | Activates logging to Weights & Biases, facilitating cloud-based experiment tracking and visualization. |
| project | Project name for Weights & Biases logging. Groups multiple runs under a single heading. |
| run | Run name for Weights & Biases logging, helping differentiate individual training sessions within a project. |
| early_stopping | Enables an early stopping callback that monitors mAP improvements to decide if training should be stopped. Helps avoid needless epochs when mAP plateaus. |
| early_stopping_patience | Number of consecutive epochs without mAP improvement before stopping. Prevents wasting resources on minimal gains. |
| early_stopping_min_delta | Minimum change in mAP to qualify as an improvement. Ensures that trivial gains don’t reset the early stopping counter. |
| early_stopping_use_ema | Whether to track improvements using the EMA version of the model. Uses EMA metrics if available, otherwise falls back to regular mAP. |

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)