ComfyUI进阶:SVD模型文生视频与图生视频全流程指南
SVD模型在ComfyUI中的应用标志着AI创作从静态向动态的跨越。文生视频适合从零开始的创意生成,图生视频则擅长让现有图像焕发动态生机。作为进阶用户,建议先掌握基础参数组合,再尝试结合ControlNet等工具实现精准控制。随着模型迭代,视频生成的质量和可控性将持续提升,提前布局的创作者将在内容生产领域获得显著优势。
随着AI生成技术的发展,视频创作正成为继图像生成后的新风口。Stable Video Diffusion(SVD)作为 Stability AI 推出的视频生成模型,在ComfyUI中能实现高质量的文生视频与图生视频创作。本文将从应用场景到具体工作流,带进阶用户掌握SVD的核心用法。
一、工作流生成视频的应用与未来趋势
SVD模型通过扩散过程生成连续帧视频,其工作流在以下场景已展现强大潜力:
| 应用场景 | 典型案例 | 技术优势 |
|---|---|---|
| 创意原型 | 广告分镜、动画草稿 | 快速将文字描述转化为动态视觉 |
| 内容创作 | 短视频片段、社交媒体素材 | 降低视频制作门槛,无需专业设备 |
| 教育演示 | 科学原理动画、流程演示 | 直观呈现抽象概念 |
| 游戏开发 | 角色动作预览、场景动画 | 辅助游戏原型设计 |
未来趋势:
- 分辨率提升:当前SVD主流输出为576×1024,未来将支持4K级视频生成
- 时长扩展:从目前的4-14秒向分钟级视频演进
- 交互增强:结合ControlNet实现动作精准控制
- 多模态融合:支持文本、图像、音频协同生成视频
对于进阶用户,提前掌握SVD工作流将在AI视频创作领域占据先机。
二、SVD模型下载与放置位置
(一)模型下载渠道
SVD包含基础模型和升级模型,推荐下载以下版本:
| 模型名称 | 特点 | 下载地址 |
|---|---|---|
| stabilityai/stable-video-diffusion-img2vid(基础版) | 生成14帧,速度快 | Hugging Face |
| stabilityai/stable-video-diffusion-img2vid-xt(增强版) | 生成25帧,细节更丰富 | Hugging Face |
| stabilityai/stable-video-diffusion-img2vid-xt-1-1 | xt最新版 | 同上 |
提示:国内用户可通过hf-mirror等镜像站加速下载,需注册账号并同意模型使用协议。
(二)文件放置规范
下载后需按以下结构放置,确保ComfyUI能正确识别:
ComfyUI/
├─ models/
│ └─ stable_video_diffusion/ # 手动创建该文件夹
│ ├─ svd.safetensors # 基础模型文件
│ ├─ svd_xt.safetensors # XT增强模型文件
│ └─ svd_xt_1_1.safetensors # XT最新版
注意:模型文件较大(基础版约2.8GB,XT版约5.2GB),需预留足够存储空间,且确保文件完整未损坏。
三、文生视频工作流创建
文生视频(Text-to-Video)通过文字描述直接生成动态视频,核心是将文本信息转化为时间序列的视觉内容。
(一)核心节点组成
基于效率节点的精简工作流:
关键节点解析:
-
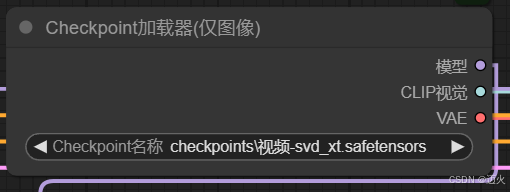
Checkpoint加载器(仅图像):
- 作用:加载SVD模型
- 节点介绍:仅图像检查点加载器
-
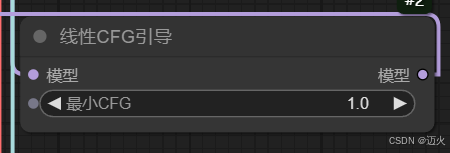
线性CFG引导:
- 作用:跨帧缩放CFG进行视频采样
- 参数:min_cfg-中文意思为最小无分类器指导,默认值为1。SVD在绘制视频第一帧内容时运用最小CFG,之后逐渐增大,到最后一帧内容时变为K采样器里面的最终CFG。
-
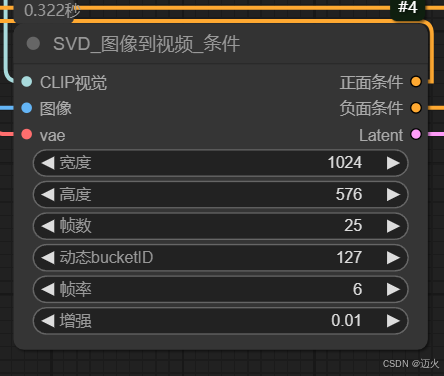
SVD_图像到视频_条件:
- 作用:核心节点,用于将图片转换为视频。
- 参数1:width:生成视频的宽度。
- 参数2:heigth:生成视频的高度。
- video_frames:生成的运动总帧数,使用原版模型,建议最大设置为14;使用XT版本模型,建议最大设置为25。
- motion_bucket_id:控制生成视频的运动幅度,数值越大运动幅度越大,默认值为127。
- fps:帧率,代表视频每秒播放的帧数,默认值为6,一般设置为6或8。
- augmentation_level:控制添加到图像的噪声量,数值越大视频与初始帧的差异就越大,一般设置不超过1。
(二)工作流展示
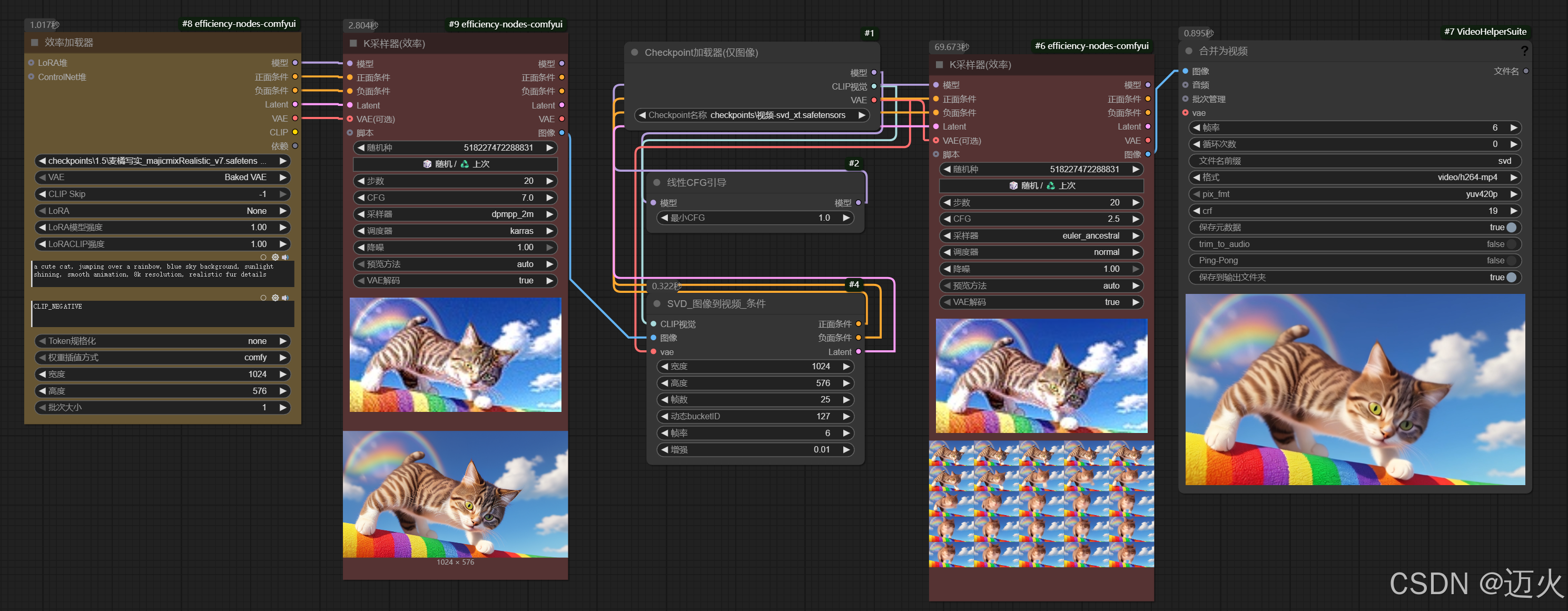
(三)提示词撰写技巧
文生视频提示词需包含时空信息,结构公式:
[主体],[动作描述],[环境],[时间变化],[风格]
示例:
a cute cat, jumping over a rainbow, blue sky background, sunlight shining, smooth animation, 8k resolution, realistic fur details
提示:避免过于复杂的动作描述(如"同时跑跳+转头"),当前模型对复合动作支持有限。
四、图生视频工作流创建
图生视频(Image-to-Video)以静态图像为基础生成动态扩展,适合让插画、照片"动起来",是进阶用户创作的重点方向。
(一)核心节点组成
在文生视频基础上增加图像输入与处理节点:
(二)实战技巧
-
静态照片动起来:
- 输入:风景照
- 提示词:
gentle wind blowing leaves, clouds moving slowly, sunlight changing gradually - 参数:
Motion Bucket Id=127(轻微运动)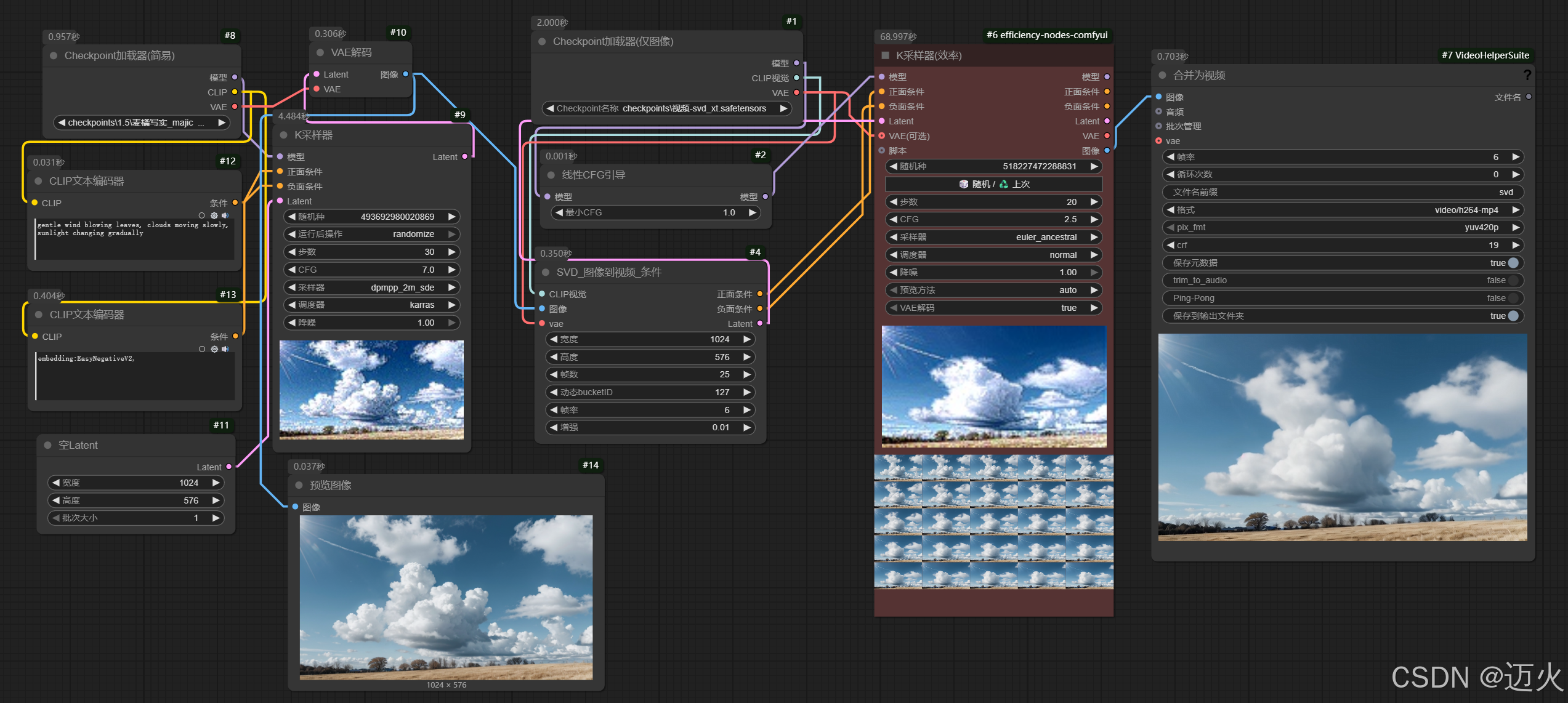
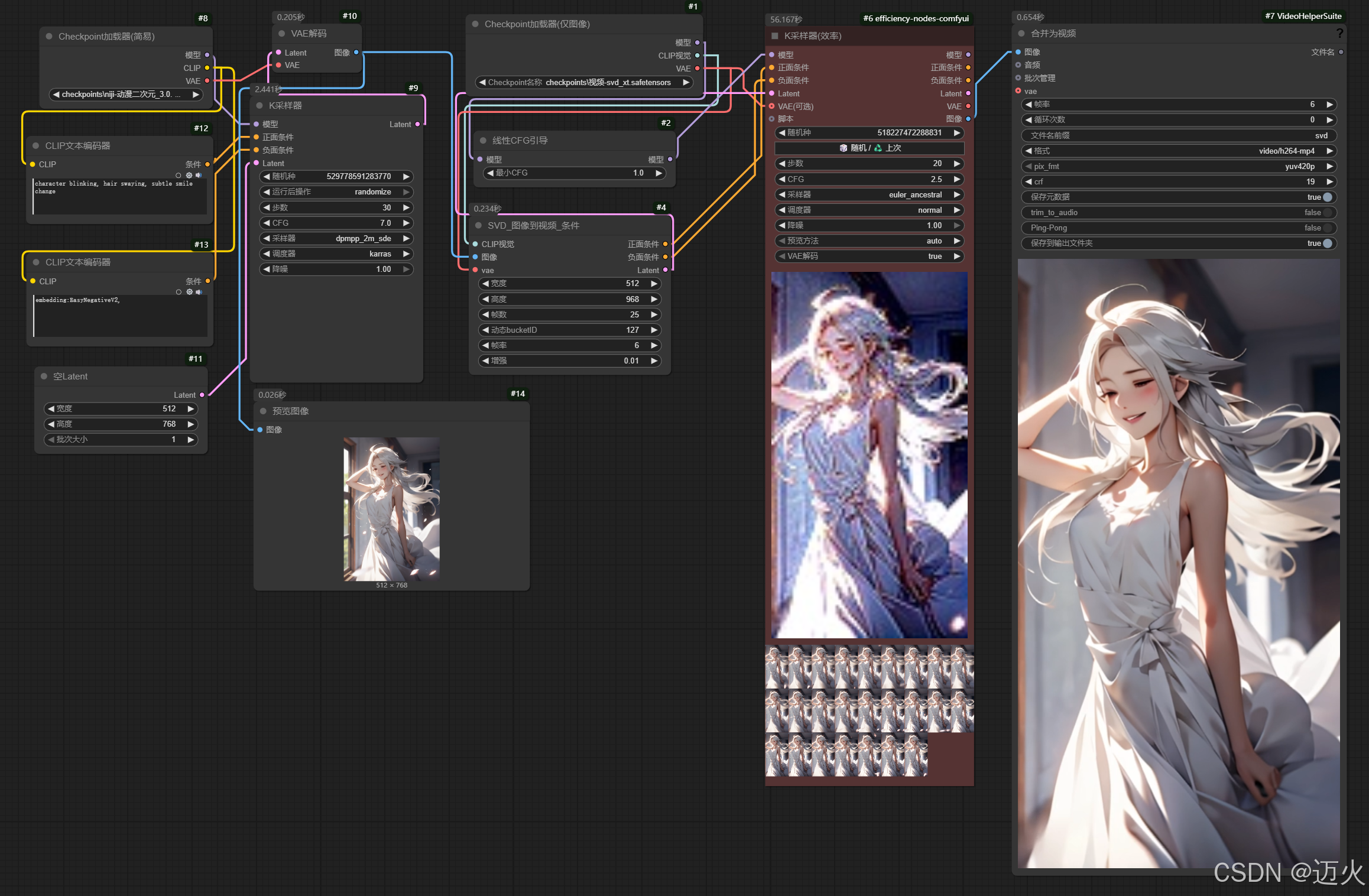
-
插画转动画:
- 输入:二次元角色插画
- 提示词:
character blinking, hair swaying, subtle smile change - 参数:
Init Strength=1(保留角色特征)
总结
SVD模型在ComfyUI中的应用标志着AI创作从静态向动态的跨越。文生视频适合从零开始的创意生成,图生视频则擅长让现有图像焕发动态生机。作为进阶用户,建议先掌握基础参数组合,再尝试结合ControlNet等工具实现精准控制。
随着模型迭代,视频生成的质量和可控性将持续提升,提前布局的创作者将在内容生产领域获得显著优势。如果本文对你有帮助,欢迎点赞收藏,评论区可分享你的SVD创作经验!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐

 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)