基于YOLOv8的人体检测、行人识别项目|完整源码数据集+PyQt5界面+完整训练流程+开箱即用!
在智能安防、智慧城市、公共安全等场景中,人体检测与行人识别是实现高级视觉感知的基础任务。相比传统图像处理方法,YOLO系列算法凭借其“一次前向传递即完成检测”的端到端优势,在速度和精度之间取得了良好平衡。随着YOLOv8的发布,其在轻量化结构、Anchor-Free设计、解耦头结构方面均做出了重大更新,进一步提升了在人群密集、遮挡复杂等现实场景下的检测性能。
基于YOLOv8的人体检测、行人识别项目|完整源码数据集+PyQt5界面+完整训练流程+开箱即用!
源码包含:完整YOLOv8训练代码+数据集(带标注)+权重文件+直接可允许检测的yolo检测程序+直接部署教程/训练教程
源码在文末哔哩哔哩视频简介处获取。
基本功能演示
人体检测、行人识别项目-基于YOLOv8:完整源码+PyQt5界面+完整训练,源码数据集一步到位!【技术开箱】
项目摘要
本项目集成了 YOLOv8人体检测与行人识别模型 与 PyQt5图形界面工具,构建了一个多平台、支持多输入的目标识别系统。系统具备以下特点:
- 采用最新Ultralytics YOLOv8架构,具备更强的检测精度和推理速度;
- 利用行人检测数据集(如CrowdHuman、Caltech Pedestrian等)进行微调,提高对遮挡、拥挤场景下的识别性能;
- 图形界面由PyQt5开发,操作简洁,便于非程序员使用;
- 模型训练与部署一体化,提供详细的训练流程说明,开箱即用;
- 全平台兼容(Windows/Linux),可扩展性强,可用于安防监控、人数统计、异常行为识别等多个场景。
项目源码、训练数据与部署文档统一打包,详见哔哩哔哩站内演示视频下方简介处。
文章目录
前言
在智能安防、智慧城市、公共安全等场景中,人体检测与行人识别是实现高级视觉感知的基础任务。相比传统图像处理方法,YOLO系列算法凭借其“一次前向传递即完成检测”的端到端优势,在速度和精度之间取得了良好平衡。
随着YOLOv8的发布,其在轻量化结构、Anchor-Free设计、解耦头结构方面均做出了重大更新,进一步提升了在人群密集、遮挡复杂等现实场景下的检测性能。
为此,我们构建了本项目,旨在:
- 降低人体检测的开发门槛;
- 提供一套完整的人体识别系统方案;
- 支持从训练到部署的闭环流程,助力用户快速落地实际应用。
无论你是AI初学者,还是打算将YOLO用于实际商业项目的开发者,这套系统都能为你提供一个可靠、高效、易用的技术框架。
一、软件核心功能介绍及效果演示
- ✅ 支持图片、视频、摄像头、文件夹多种检测输入方式
- ✅ 支持YOLOv8n、YOLOv8s等多个模型权重一键切换
- ✅ 支持自定义模型训练、导出和加载
- ✅ 集成PyQt5图形界面:拖拽式操作,零门槛使用
- ✅ 可视化检测结果:标注人体位置、识别行人目标
- ✅ 实现检测速度快、精度高、轻量部署
二、软件效果演示
为了直观展示本系统基于 YOLOv8 模型的检测能力,我们设计了多种操作场景,涵盖静态图片、批量图片、视频以及实时摄像头流的检测演示。
(1)单图片检测演示
用户点击“选择图片”,即可加载本地图像并执行检测:
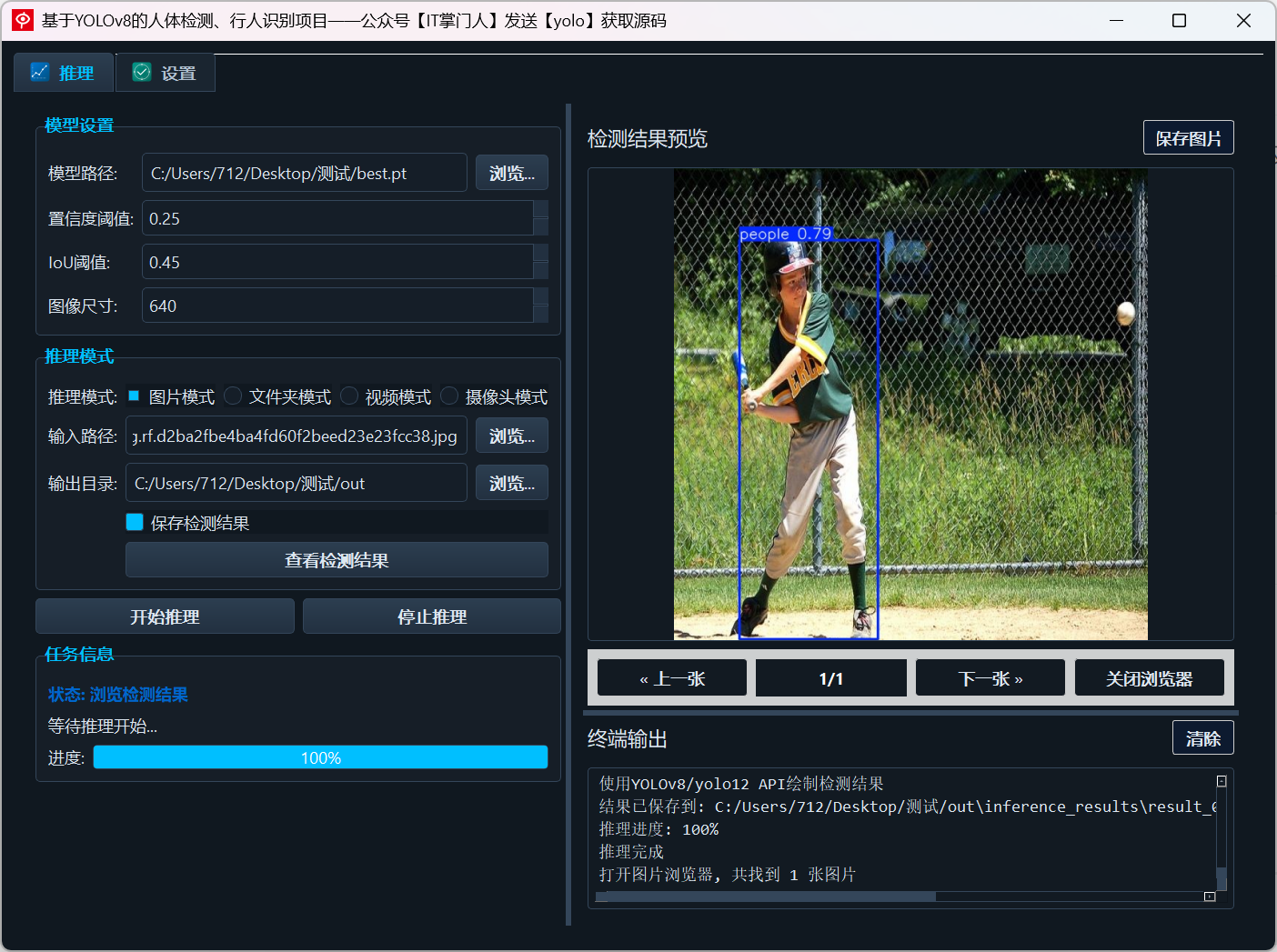
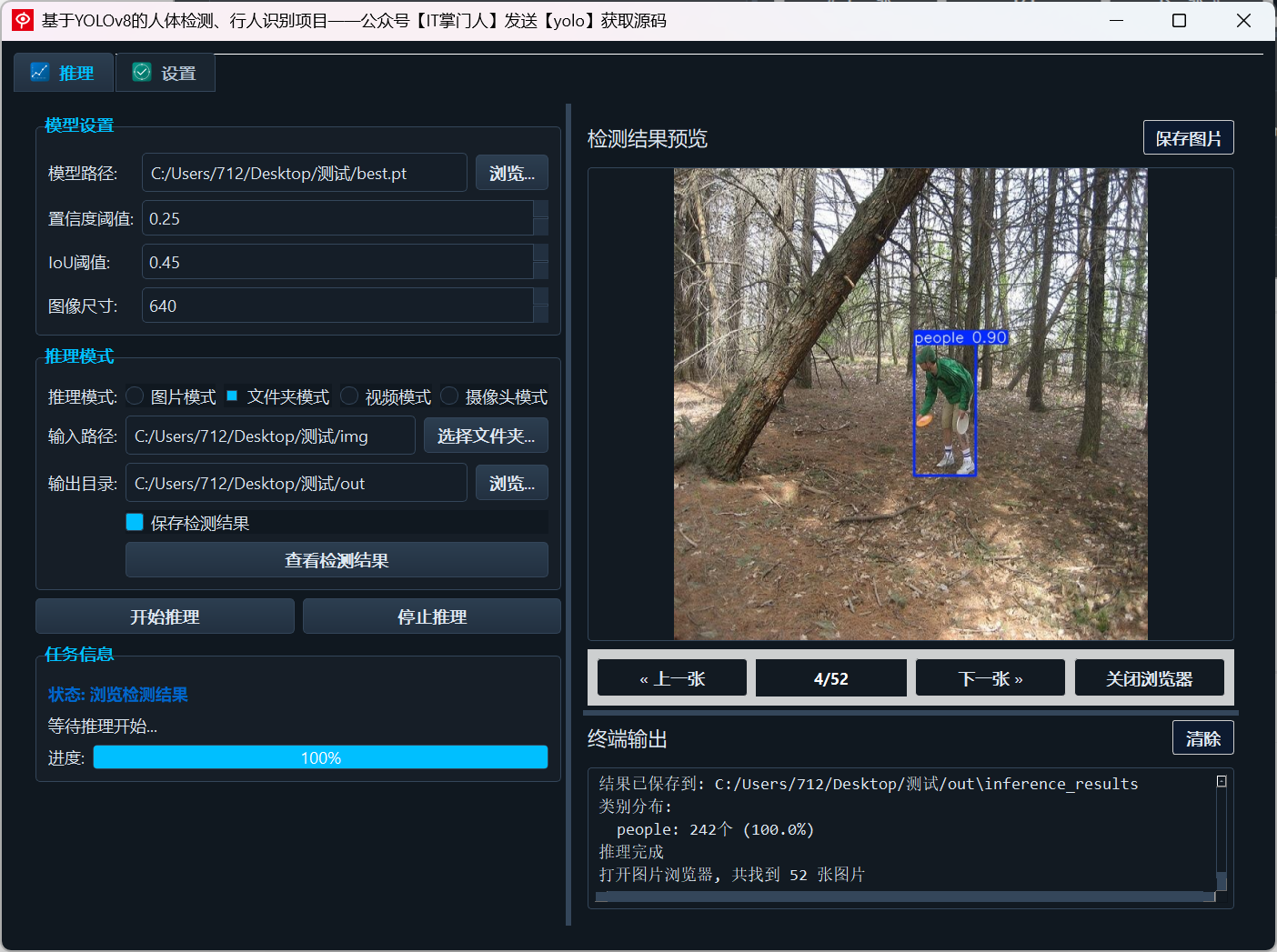
(2)多文件夹图片检测演示
用户可选择包含多张图像的文件夹,系统会批量检测并生成结果图。
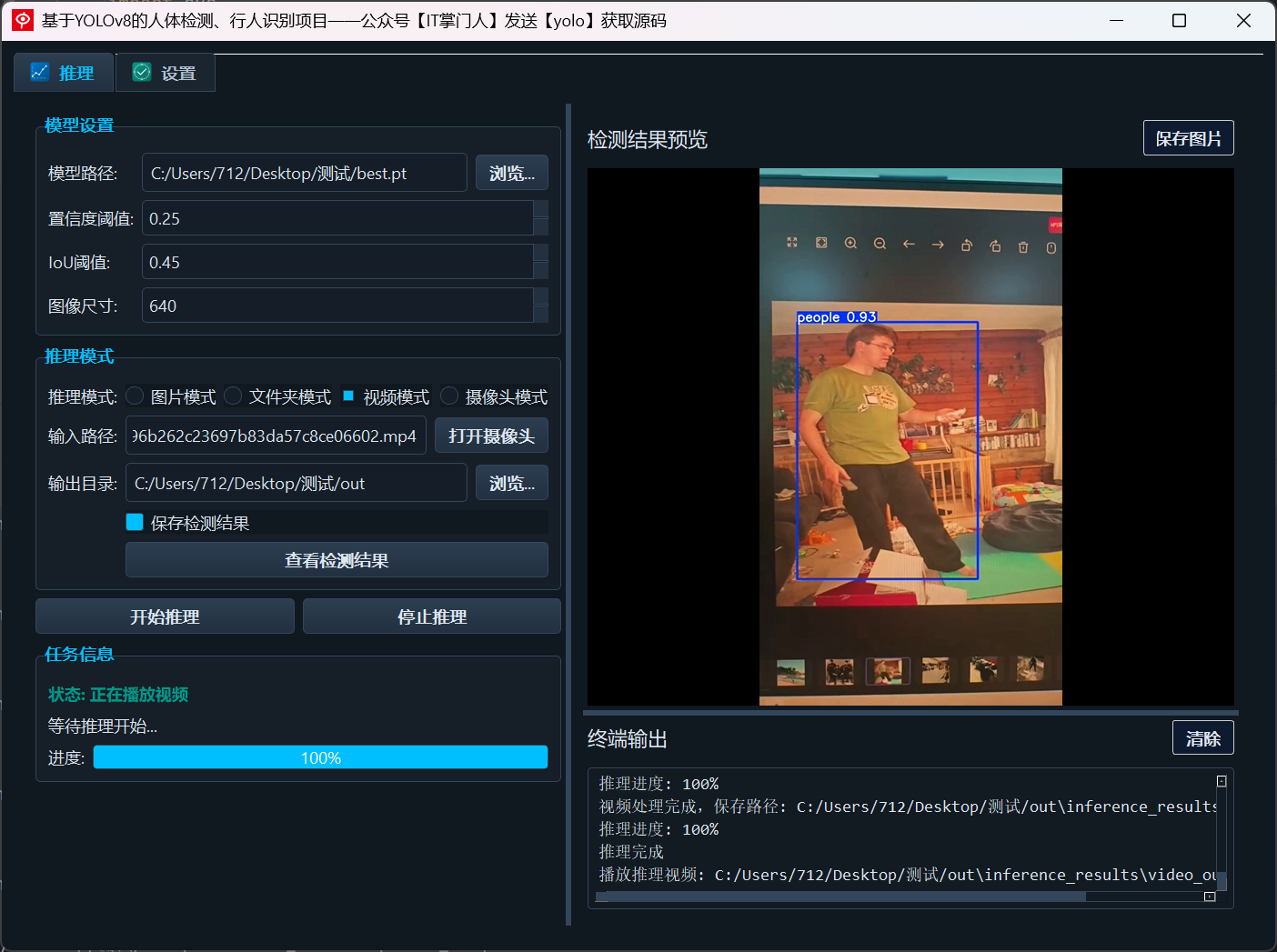
(3)视频检测演示
支持上传视频文件,系统会逐帧处理并生成目标检测结果,可选保存输出视频:
(4)摄像头检测演示
实时检测是系统中的核心应用之一,系统可直接调用摄像头进行检测。由于原理和视频检测相同,就不重复演示了。
(5)保存图片与视频检测结果
用户可通过按钮勾选是否保存检测结果,所有检测图像自动加框标注并保存至指定文件夹,支持后续数据分析与复审。
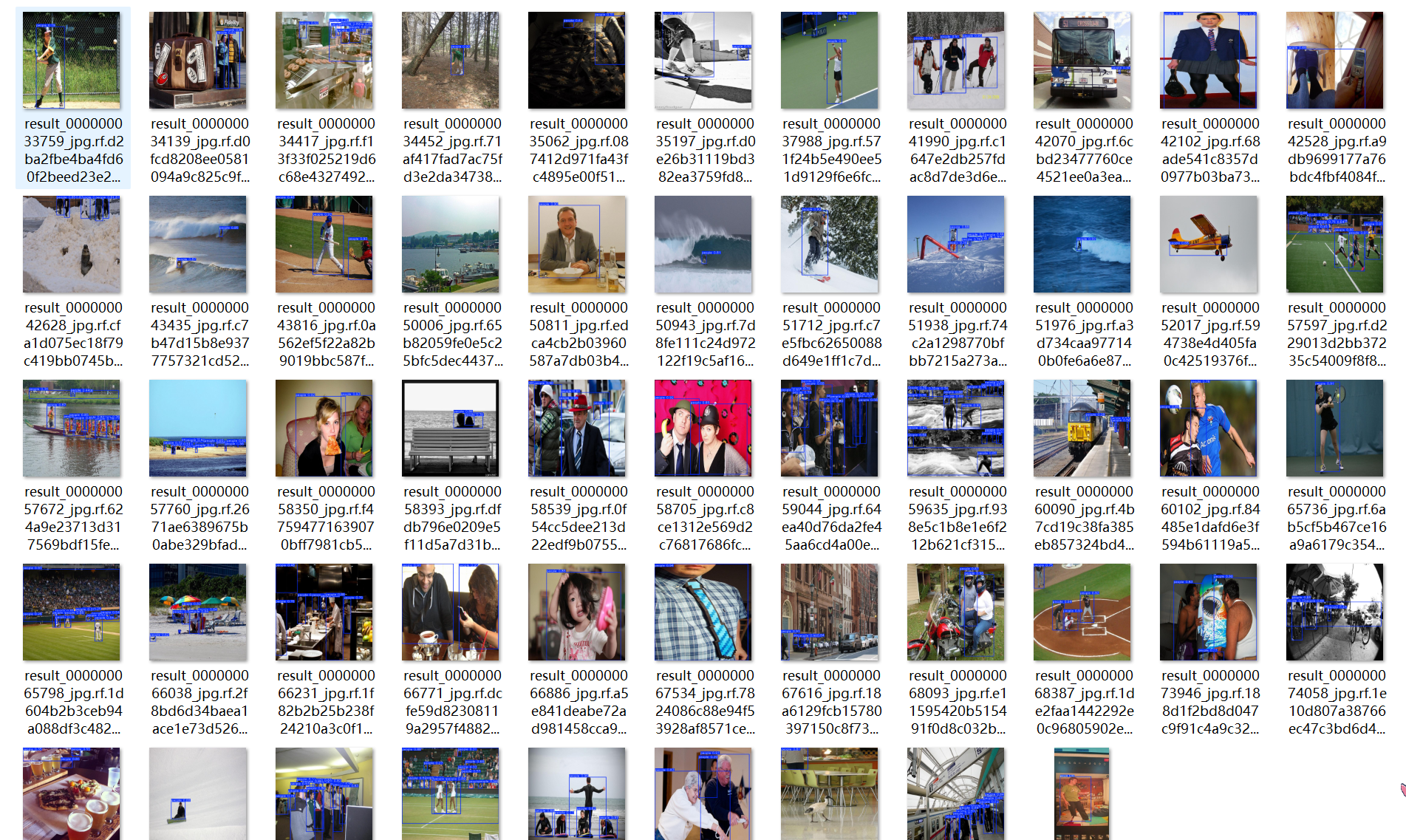
三、模型的训练、评估与推理
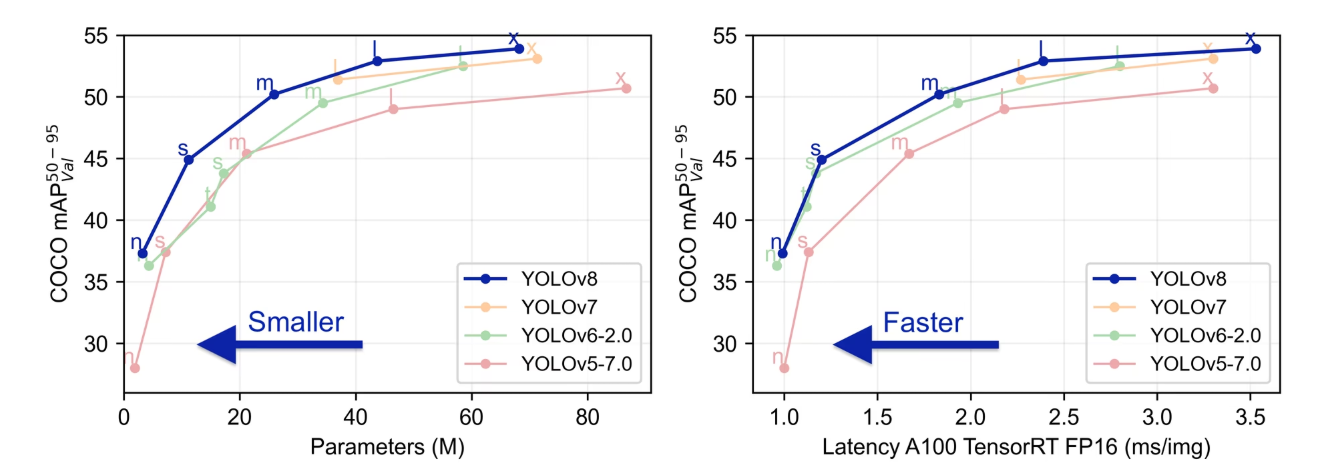
YOLOv8是Ultralytics公司发布的新一代目标检测模型,采用更轻量的架构、更先进的损失函数(如CIoU、TaskAlignedAssigner)与Anchor-Free策略,在COCO等数据集上表现优异。
其核心优势如下:
- 高速推理,适合实时检测任务
- 支持Anchor-Free检测
- 支持可扩展的Backbone和Neck结构
- 原生支持ONNX导出与部署
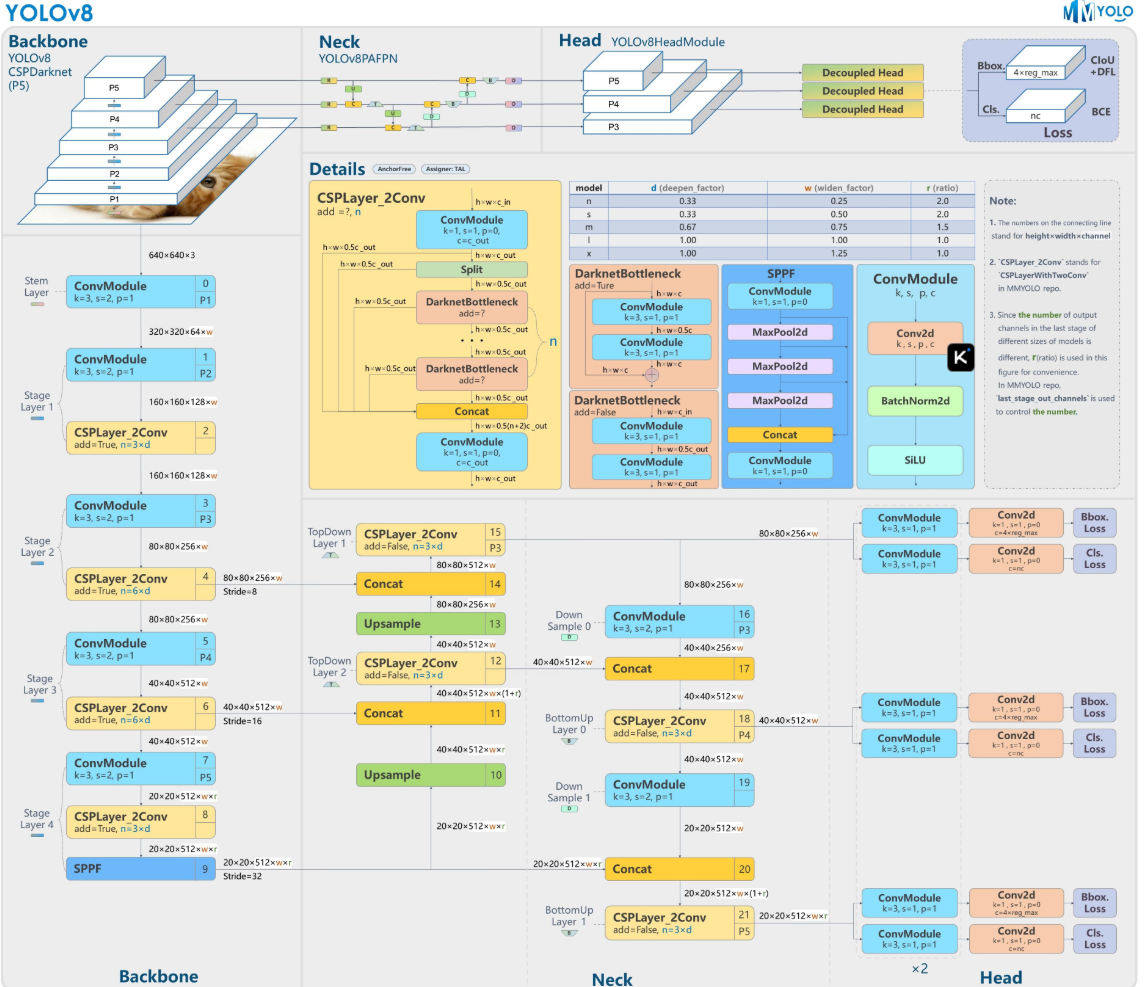
3.1 YOLOv8的基本原理
YOLOv8 是 Ultralytics 发布的新一代实时目标检测模型,具备如下优势:
- 速度快:推理速度提升明显;
- 准确率高:支持 Anchor-Free 架构;
- 支持分类/检测/分割/姿态多任务;
- 本项目使用 YOLOv8 的 Detection 分支,训练时每类表情均标注为独立目标。
YOLOv8 由Ultralytics 于 2023 年 1 月 10 日发布,在准确性和速度方面具有尖端性能。在以往YOLO 版本的基础上,YOLOv8 引入了新的功能和优化,使其成为广泛应用中各种物体检测任务的理想选择。
YOLOv8原理图如下:
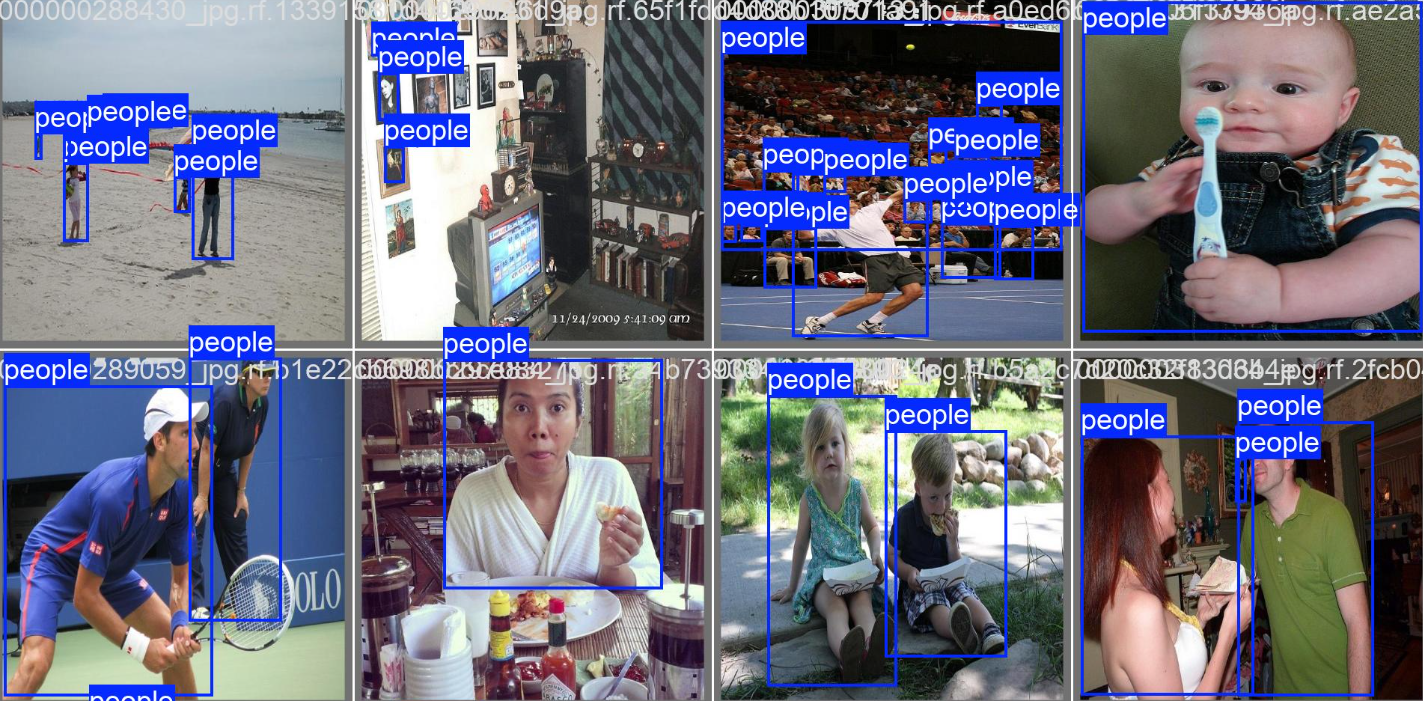
3.2 数据集准备与训练
采用 YOLO 格式的数据集结构如下:
dataset/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
每张图像有对应的 .txt 文件,内容格式为:
4 0.5096721233576642 0.352838390077821 0.3947600423357664 0.31825755058365757
分类包括(可自定义):
3.3. 训练结果评估
训练完成后,将在 runs/detect/train 目录生成结果文件,包括:
results.png:损失曲线和 mAP 曲线;weights/best.pt:最佳模型权重;confusion_matrix.png:混淆矩阵分析图。
若 mAP@0.5 达到 90% 以上,即可用于部署。
在深度学习领域,我们通常通过观察损失函数下降的曲线来评估模型的训练状态。YOLOv8训练过程中,主要包含三种损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss)。训练完成后,相关的训练记录和结果文件会保存在runs/目录下,具体内容如下:
3.4检测结果识别
使用 PyTorch 推理接口加载模型:
import cv2
from ultralytics import YOLO
import torch
from torch.serialization import safe_globals
from ultralytics.nn.tasks import DetectionModel
# 加入可信模型结构
safe_globals().add(DetectionModel)
# 加载模型并推理
model = YOLO('runs/detect/train/weights/best.pt')
results = model('test.jpg', save=True, conf=0.25)
# 获取保存后的图像路径
# 默认保存到 runs/detect/predict/ 目录
save_path = results[0].save_dir / results[0].path.name
# 使用 OpenCV 加载并显示图像
img = cv2.imread(str(save_path))
cv2.imshow('Detection Result', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
预测结果包含类别、置信度、边框坐标等信息。

四.YOLOV8+YOLOUI完整源码打包
本文涉及到的完整全部程序文件:包括python源码、数据集、训练代码、UI文件、测试图片视频等(见下图),获取方式见【4.2 完整源码下载】:
4.1 项目开箱即用
作者已将整个工程打包。包含已训练完成的权重,读者可不用自行训练直接运行检测。
运行项目只需输入下面命令。
python main.py
读者也可自行配置训练集,或使用打包好的数据集直接训练。
自行训练项目只需输入下面命令。
yolo detect train data=datasets/expression/loopy.yaml model=yolov8n.yaml pretrained=yolov8n.pt epochs=100 batch=16 lr0=0.001
4.2 完整源码下载
至项目实录视频下方获取:https://www.bilibili.com/video/BV1Uvg3zsEg7
包含:
📦完整项目源码
📦 预训练模型权重
🗂️ 数据集地址(含标注脚本)
总结
本项目基于 Ultralytics 发布的 YOLOv8 框架,结合 PyQt5 构建了一个操作简单、功能全面、可直接部署的人体检测与行人识别系统。项目不仅支持图片、视频、摄像头等多种输入方式,还实现了训练与推理的无缝衔接,极大地降低了AI模型在实际场景中应用的技术门槛。
通过对 YOLOv8 架构的深入理解与调优,项目在遮挡、拥挤等复杂环境下依然保持了较高的检测精度。同时,PyQt5 提供了直观可视化的界面,使非技术人员也能便捷使用本系统,真正实现“AI赋能下沉应用”。
不论你是AI开发者、科研工作者,还是初学者、企业工程师,这个项目都可以作为你部署行人检测/人数统计/安防监控系统的优秀起点。
📌 项目亮点总结:
- ✅ 支持多输入格式的检测操作;
- ✅ PyQt5图形界面即点即用;
- ✅ 完整训练 + 推理流程,一键运行;
- ✅ COCO格式兼容,支持自定义数据集;
- ✅ 支持二次开发与迁移学习。
未来可拓展方向包括:加入目标追踪(DeepSORT)、行人再识别(ReID)、异常行为识别等模块,构建更智能化的综合视频分析系统。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 22
22 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)