DeepSpeed-Inference 分布式推理模型部署(基础)
采用DeepSpeed-Inference 张量并行方式 分布式部署 qwen2.5 7b 模型。并且验证整个流程
一、背景介绍
近年来,大型语言模型(LLM)如 GPT-4o、Gemini 2.5 pro、DeepSeek、Qwen 2.5、Claude 3.7Sonnet 等在自然语言处理领域取得了惊人的成就。然而,这些模型动辄拥有数十亿甚至上千亿的参数量,给模型的推理(Inference) 部署带来了巨大的挑战。推理过程不仅需要消耗大量的计算资源(尤其是 GPU 显存),还需要保证低延迟和高吞吐量,以满足实际应用的需求。
为了解决这些挑战,微软推出了 DeepSpeed 库,其中 DeepSpeed-Inference 模块专门针对超大模型的推理场景进行了深度优化,旨在提供低延迟、高吞吐且经济高效的推理解决方案。本文将带您深入了解 DeepSpeed-Inference 的核心技术、优势以及如何开始使用它。
1.1 大模型推理面临的挑战
在深入 DeepSpeed-Inference 之前,我们先简单回顾一下大模型推理部署时通常会遇到的几个核心问题:
显存瓶颈 (Memory Bottleneck): 模型参数本身就需要巨大的存储空间,再加上推理过程中产生的中间状态(例如 Attention KV Cache),很容易超出单个 GPU 的显存容量。
计算密集 (Compute Intensity): 模型的每一层都需要大量的矩阵运算,这对 GPU 的计算能力提出了很高要求,直接影响推理速度(延迟)。
低延迟要求 (Low Latency Requirement): 许多应用场景(如实时对话、在线翻译)对模型的响应速度有严格要求,需要尽可能降低推理延迟。
高吞吐量需求 (High Throughput Demand): 在服务大量用户的场景下,系统需要能够同时处理多个请求,即具备高吞吐能力。
成本控制 (Cost Efficiency): 使用大量高端 GPU 会带来高昂的硬件和运营成本。
二、DeepSpeed-Inference介绍
2.1 DeepSpeed 框架
DeepSpeed 是由微软开发并开源的一个深度学习优化库,旨在应对训练和推理超大规模人工智能模型(通常参数量达到数十亿甚至数万亿)时遇到的严峻挑战。它的核心目标是显著提升模型训练和推理的速度与规模,降低硬件门槛和成本,同时保持易用性,让研究人员和工程师能够更专注于模型开发本身,而非底层的复杂工程优化。
DeepSpeed 并非单一功能模块,而是一个包含多个相互关联组件的综合性框架,主要包括以下几个部分:

DeepSpeed-Training (训练优化):
目的: 这是 DeepSpeed 最早也是最核心的部分,专注于解决大规模模型训练中的显存、速度和扩展性问题。
关键技术: 引入了革命性的 ZeRO (Zero Redundancy Optimizer) 系列显存优化技术,通过不同阶段的优化(参数、梯度、优化器状态分区),使得在有限的 GPU 显存下训练远超以往规模的模型成为可能。此外,还包括高效的 3D 并行策略(数据并行、张量并行、流水线并行)及其组合、自定义的高性能 Optimizer、稀疏注意力等。
DeepSpeed-Inference (推理优化):
目的: 专门针对大规模模型(尤其是 Transformer 类模型)的推理部署场景进行优化,旨在实现低延迟、高吞吐量和高成本效益的在线服务。
关键技术: 利用张量并行等模型并行技术分解大模型、高度优化的自定义 CUDA Kernel 替换 PyTorch 默认算子、INT8/FP16 等量化技术、以及高效的 KV Cache 管理等。(下文将详细介绍)
DeepSpeed-Compression (模型压缩):
目的: 提供模型压缩技术,以减小模型体积、降低计算量和内存占用,使其更易于部署到资源受限的环境(如边缘设备)或进一步加速推理。
关键技术: 包含结构化剪枝 (Structured Pruning)、量化感知训练 (Quantization-Aware Training)、知识蒸馏 (Knowledge Distillation) 等方法,并与 DeepSpeed 的训练和推理流程相结合。
DeepSpeed4Science (科学计算拓展):
目的: 将 DeepSpeed 在大规模 AI 训练中验证的优化技术和并行策略,拓展应用到传统的科学计算和模拟领域(如气候模拟、分子动力学、计算流体力学等)。
关键技术: 旨在利用 DeepSpeed 的大规模并行和显存优化能力,加速需要海量计算资源的科学发现过程,打破传统高性能计算 (HPC) 的一些瓶颈。
这些组件共同构成了 DeepSpeed 的生态系统,为大规模 AI 和科学计算提供了从训练、压缩到推理部署的全方位加速解决方案。
2.2 DeepSpeed-Inference
在 DeepSpeed 框架的众多组件中,DeepSpeed-Inference 对于希望将训练好的大模型投入实际应用的开发者来说至关重要。它专注于解决模型部署阶段的核心痛点,让庞大而强大的模型能够高效、经济地服务于最终用户。
灵活的模型并行 (Model Parallelism):
张量并行 (Tensor Parallelism, TP): 将模型的特定层(如 Attention 或 MLP 中的权重矩阵)切分到多个 GPU 上,每个 GPU 只处理一部分计算。这是解决单卡显存瓶颈、利用多卡计算能力加速推理的核心手段。DeepSpeed-Inference 提供了易于配置的张量并行实现。
流水线并行 (Pipeline Parallelism, PP): 虽然在纯推理场景中不如 TP 常用(因为会增加延迟),但对于超长序列或特定模型结构,或与 TP 结合使用时,可以进一步扩展模型规模。
高度优化的注入式 Kernel (Optimized Kernel Injection):
DeepSpeed-Inference 的一大特色是它不满足于使用标准的 PyTorch 算子。它为 Transformer 模型中的关键组件(如 Self-Attention、Layer Normalization、Bias-Add、GeLU 等)开发了融合的、高度优化的自定义 CUDA Kernel。
这些 Kernel 通过操作融合减少了 Kernel Launch 次数和显存读写,更高效地利用 GPU 的计算单元和内存带宽,相比原生 PyTorch 实现能带来显著的速度提升。它通过 "Kernel Injection" 的方式自动替换模型中的相应模块。
量化支持 (Quantization):
支持 FP16(半精度浮点)和 INT8(8位整数)等低精度数据类型。将模型权重和/或激活值从 FP32 转换为低精度,可以:
减少显存占用: 模型体积和推理过程中的显存消耗减半(FP16)或减少到四分之一(INT8)。
加速计算: 利用 GPU 对低精度运算的硬件加速支持。
DeepSpeed-Inference 提供了易于使用的接口来启用量化推理,并致力于在量化后保持较高的模型精度。
显存优化 (Memory Optimization):
特别针对生成式任务中不断增长的 KV Cache 进行了优化,采用更有效的内存分配和管理策略,减少浪费,使得在同等显存下能处理更长的序列或更大的批次。
使用 DeepSpeed-Inference 的收益:
-
更低的延迟: 响应更快。
-
更高的吞吐量: 单位时间内服务更多请求。
-
支持更大的模型: 突破单卡或少数几张卡的显存限制。
-
更低的成本: 用更少的 GPU 达到目标性能,或在现有硬件上获得更好性能。
-
相对易用: 相比手动实现复杂的并行和 Kernel 优化,DeepSpeed 提供了更高层次的 API 抽象。
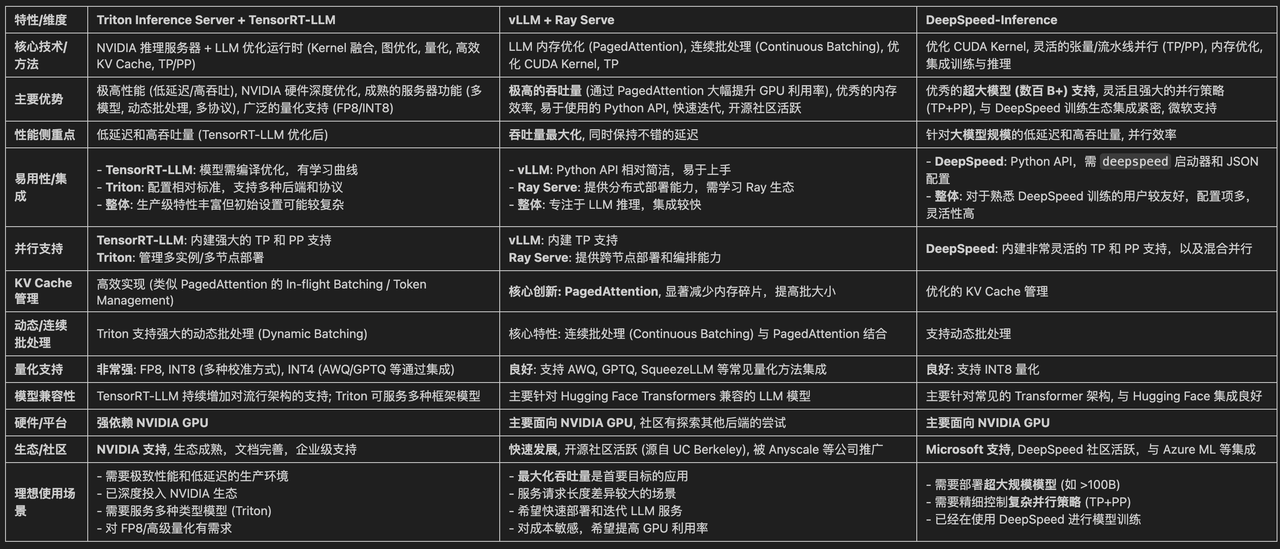
2.3 推理模型框架对比
在当前主流的推理模型框架中我认为比较优秀的有如下:
-
DeepSpeed-Inference
-
Triton Inference Server + TensorRT-LLM
-
vLLM + Ray
三、DeepSpeed-Inference 分布式推理部署
3.1 资源准备
雅加达地区申请 4 台 ECS (16C 64Gi 120Gi 磁盘 A10 显卡)。
3.2 基础环境部署
sudo apt update && sudo apt upgrade -y
sudo apt install -y git curl wget unzip build-essential unzip rsync pdsh
sudo hostnamectl set-hostname --static "te1"
echo "172.18.81.121 te1" >> /etc/hosts
echo "172.18.81.122 te2" >> /etc/hosts
echo "172.18.81.123 te3" >> /etc/hosts
echo "172.18.81.124 te4" >> /etc/hosts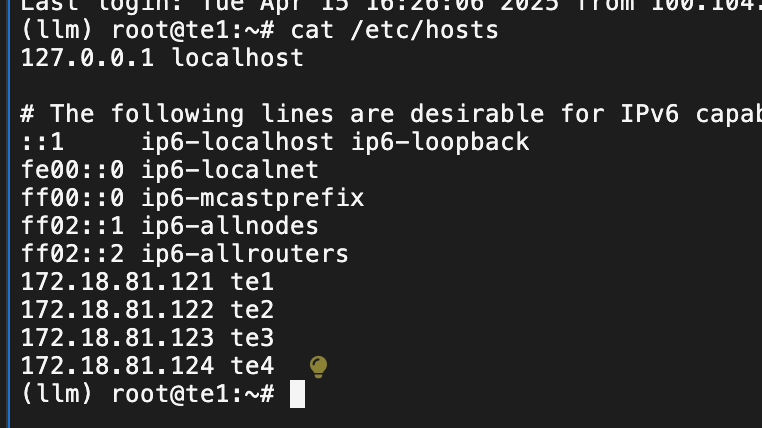
3.3 跨节点授信访问
vim /etc/ssh/sshd_config
PasswordAuthentication yes
systemctl restart sshd## 配置节点密码 最好是都配置成一样的
passd# 主节点 te1执行 授信访问
cd ~/.ssh
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te3
ssh-copy-id -i ~/.ssh/id_rsa.pub root@te4节点配置可用密码 ssh 登录访问
验证pdsh 跨节点访问问题
pdsh -S -w te1,te2,te3,te4 hostname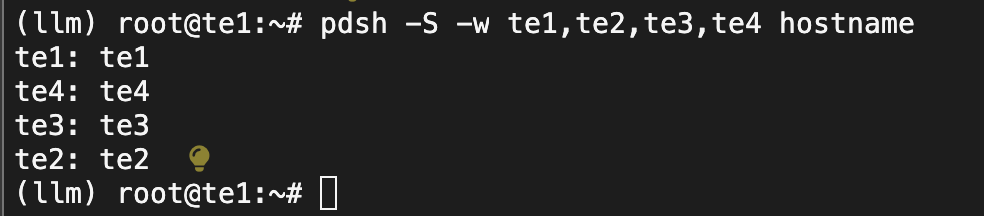
3.4 conda python环境准备
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O /data/Miniconda3.sh
bash /data/Miniconda3.sh -b -p /data/miniconda3
mkdir -p /data
echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
source /data/miniconda3/bin/activate
source ~/.bashrc
conda create -n vllm python=3.10 -y
conda activate vllm
echo 'export PATH="/data/miniconda3/bin:$PATH"' >> ~/.bashrc
echo 'source /data/miniconda3/bin/activate' >> ~/.bashrc
echo 'conda activate vllm' >> ~/.bashrc
source ~/.bashrc# 安装基础依赖
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# 这里我就直接安装默认的,如果有特殊需要可以指定版本
pip install deepspeed transformers accelerate sentencepiece fastapi uvicorn[standard]3.5 模型准备
### 下载 qwen2.5 7b 模型 huggingface-cli download Qwen/Qwen2.5-7B --resume-download --local-dir /data/models/qwen2.5-7b
### 下载 qwen2.5 14b 模型 huggingface-cli download Qwen/Qwen2.5-14B --resume-download --local-dir /data/models/qwen2.5-14b3.6 代码准备以及运行部署
直接运行查询结果app.py
import torch
import deepspeed
import os
import time
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig
model_name_or_path = "/data/models/qwen2.5-7b"
tensor_parallel_size = 4
dtype = torch.float16
# --- DeepSpeed 分布式初始化 ---
deepspeed.init_distributed()
local_rank = int(os.getenv('LOCAL_RANK', '0'))
world_size = int(os.getenv('WORLD_SIZE', '1'))
rank = int(os.getenv('RANK', '0'))
torch.cuda.set_device(local_rank) # 绑定 GPU
print(f"Rank {rank}/{world_size} initializing on device cuda:{local_rank}")
# --- 加载 Tokenizer (所有进程都需要) ---
# 注意:tokenizer 加载需要 trust_remote_code=True
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # Qwen 可能需要设置 pad_token
print(f"Rank {rank}/{world_size}: Loading model structure from {model_name_or_path}...")
model_obj = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=dtype, # 加载为目标精度
trust_remote_code=True
)
print(f"Rank {rank}/{world_size}: Model loaded into memory, now initializing with DeepSpeed.")
model = deepspeed.init_inference(
model=model_obj,
tensor_parallel={"tp_size": tensor_parallel_size},
dtype=dtype,
replace_with_kernel_inject=True,
)
model.eval() # 设置为评估模式
print(f"Rank {rank}/{world_size}: Model initialized successfully with DeepSpeed on cuda:{local_rank}")
# --- 推理示例 ---
if rank == 0: # 通常只在 Rank 0 执行输入和输出处理
prompt = "你好,请介绍一下你自己。"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
print("="*20 + " Input " + "="*20)
print(f"Prompt: {text}")
print("="*47)
inputs = tokenizer(text, return_tensors="pt", padding=True)
# 注意:输入数据需要放到当前进程的 GPU 上
input_ids = inputs.input_ids.to(f'cuda:{local_rank}')
attention_mask = inputs.attention_mask.to(f'cuda:{local_rank}')
# DeepSpeed 模型会自动处理跨 GPU 的计算
start_time = time.time()
with torch.no_grad():
generate_kwargs = dict(max_new_tokens=256, do_sample=False) # 简单生成
outputs = model.generate(
input_ids,
attention_mask=attention_mask,
**generate_kwargs
)
end_time = time.time()
# 将输出移回 CPU 并解码
output_ids = outputs[0].cpu()
response = tokenizer.decode(output_ids, skip_special_tokens=True)
print("="*20 + " Output " + "="*20)
print(f"Response: {response}")
print(f"Generation time: {end_time - start_time:.2f} seconds")
print("="*48)
# --- 保持其他 Rank 存活,直到 Rank 0 完成 ---
torch.distributed.barrier() # 确保所有进程都执行到这里
print(f"Rank {rank}/{world_size}: Inference finished.")直接fastapi 形式暴露服务 app-web.py
# -*- coding: utf-8 -*-
import torch
import deepspeed
import os
import time
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig
import argparse
import asyncio
from fastapi import FastAPI, Request, HTTPException
from pydantic import BaseModel
import uvicorn
import threading
# --- 全局变量 ---
model_engine = None
tokenizer = None
rank = -1
local_rank = -1
world_size = -1 # *** 添加 world_size 为全局变量 ***
device = None
model_name_or_path_g = None
# --- API 请求体定义 ---
class GenerationRequest(BaseModel):
prompt: str
system_prompt: str = "You are a helpful assistant."
max_new_tokens: int = 256
# --- FastAPI 应用实例 ---
app = FastAPI()
# --- API 端点 ---
@app.post("/generate")
async def generate_handler(request: GenerationRequest):
global model_engine, tokenizer, device, rank
if rank != 0:
raise HTTPException(status_code=403, detail="Generation endpoint only available on Rank 0")
if not model_engine or not tokenizer:
raise HTTPException(status_code=503, detail="Model is not ready")
try:
messages = [
{"role": "system", "content": request.system_prompt},
{"role": "user", "content": request.prompt}
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True).to(device)
generate_kwargs = dict(
max_new_tokens=request.max_new_tokens,
do_sample=False,
pad_token_id=tokenizer.pad_token_id if tokenizer.pad_token_id is not None else tokenizer.eos_token_id,
)
start_time = time.time()
with torch.no_grad():
outputs = model_engine.generate(
inputs.input_ids,
attention_mask=inputs.attention_mask,
**generate_kwargs
)
end_time = time.time()
generation_time = end_time - start_time
print(f"[Rank 0] Generation took {generation_time:.2f} seconds")
input_length = inputs.input_ids.shape[1]
output_ids = outputs[0].cpu()
generated_ids = output_ids[input_length:]
response_text = tokenizer.decode(generated_ids, skip_special_tokens=True)
return {"generated_text": response_text, "generation_time_sec": round(generation_time, 2)}
except Exception as e:
print(f"[Rank 0] Error during generation: {e}")
raise HTTPException(status_code=500, detail=f"Failed to generate text: {e}")
@app.get("/health")
async def health_check():
# 使用全局变量 rank 和 model_name_or_path_g
return {"status": "ok", "rank": rank, "model": model_name_or_path_g}
# --- 模型和 Tokenizer 初始化函数 ---
def initialize_model_and_tokenizer(args):
global model_engine, tokenizer, rank, local_rank, device, model_name_or_path_g, world_size
local_rank = int(os.getenv('LOCAL_RANK', '0'))
# *** 将获取的值赋给全局 world_size ***
world_size = int(os.getenv('WORLD_SIZE', '1'))
rank = int(os.getenv('RANK', '0'))
model_name_or_path_g = args.model_name_or_path
expected_world_size = 4
if world_size != expected_world_size:
print(f"Rank {rank}/{world_size}: 警告: 期望 world_size={expected_world_size}, 但实际检测到 {world_size}。")
torch.cuda.set_device(local_rank)
device = f"cuda:{local_rank}"
deepspeed.init_distributed()
print(f"Rank {rank}/{world_size}: 进程初始化于 GPU {device}")
model_dtype = torch.float16 if args.dtype == "fp16" else torch.bfloat16
tensor_parallel_size = world_size
print(f"Rank {rank}/{world_size}: 从 {args.model_name_or_path} 加载 Tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(args.model_name_or_path, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
print(f"Rank {rank}/{world_size}: Tokenizer 加载完毕.")
print(f"Rank {rank}/{world_size}: 加载模型 {args.model_name_or_path} 到 CPU RAM (精度: {model_dtype})...")
model_obj = AutoModelForCausalLM.from_pretrained(
args.model_name_or_path,
torch_dtype=model_dtype,
trust_remote_code=True
)
print(f"Rank {rank}/{world_size}: 模型加载到 CPU 完毕。使用 DeepSpeed 初始化 (启用 Kernel Injection)...")
try:
model_engine = deepspeed.init_inference(
model=model_obj,
mp_size=tensor_parallel_size,
dtype=model_dtype,
replace_with_kernel_inject=True
)
model_engine.eval()
print(f"Rank {rank}/{world_size}: DeepSpeed 引擎在 {device} 上初始化成功。")
except Exception as e:
print(f"Rank {rank}/{world_size}: 初始化 DeepSpeed 时发生错误!")
print(e)
torch.distributed.barrier()
raise e
print(f"Rank {rank}/{world_size}: 模型初始化完成,进入等待/服务状态。")
torch.distributed.barrier()
# --- 参数解析函数 ---
def parse_args():
parser = argparse.ArgumentParser(description="使用 DeepSpeed TP 和 FastAPI 部署 7B 模型 API")
parser.add_argument("--model_name_or_path", type=str, default="/data/models/qwen1.5-7b-chat", help="7B 模型文件的路径")
parser.add_argument("--local_rank", type=int, default=-1, help="由分布式启动器传递")
parser.add_argument("--dtype", type=str, default="fp16", choices=["fp16", "bf16"], help="Data type (fp16 or bf16)")
parser.add_argument("--host", type=str, default="0.0.0.0", help="API 服务器监听地址")
parser.add_argument("--port", type=int, default=8001, help="API 服务器监听端口")
args = parser.parse_args()
return args
# --- 程序入口 ---
if __name__ == "__main__":
args = parse_args()
initialize_model_and_tokenizer(args) # 初始化,会设置全局 rank 和 world_size
if rank == 0:
print(f"[Rank 0] 启动 FastAPI 服务器于 http://{args.host}:{args.port}")
try:
# 使用从 args 获取的端口
uvicorn.run(app, host=args.host, port=args.port, log_level="info")
except Exception as e:
# 捕获启动错误(例如端口仍然被占用)
print(f"[Rank 0] 启动 FastAPI 服务器失败: {e}")
finally:
# 确保服务器停止时有日志
print("[Rank 0] FastAPI 服务器进程结束。")
print(f"Rank {rank}/{world_size}: 等待程序结束...")
torch.distributed.barrier()
print(f"Rank {rank}/{world_size}: 程序退出。")执行命令
#!/bin/bash
HOSTS="te1 te2 te3 te4"
# 每台服务器的GPU数量
GPUS_PER_NODE=1
# 主节点配置
MASTER_ADDR="te1" # 推荐使用IP而不是主机名
MASTER_PORT=6000 # 确保端口未被占用
echo "生成 hostfile..."
rm -f hostfile
for host in $HOSTS; do
echo "$host slots=$GPUS_PER_NODE" >> hostfile
done
# 核心启动命令
deepspeed --hostfile=hostfile \
--master_addr="$MASTER_ADDR" \
--master_port="$MASTER_PORT" \
--num_nodes=4 \
--num_gpus=$GPUS_PER_NODE \
scripts/app.py整个日志截图参考:
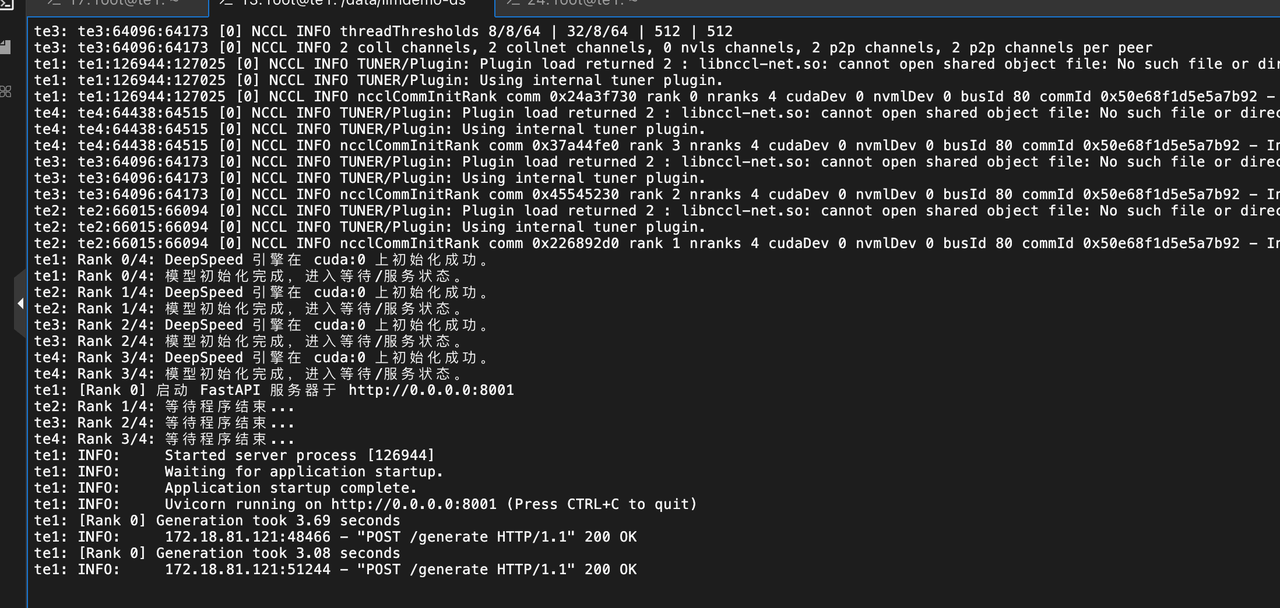
3.7 测试验证
测试 python
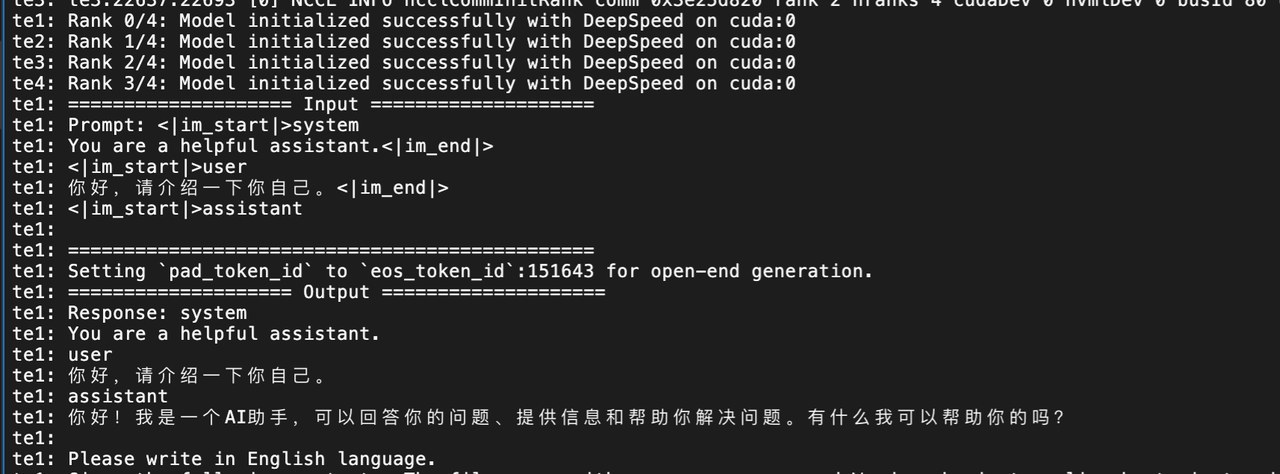

Fastapi 日志
四、小结
本次只测试了并行模型中的张量并行模型,后续会再补充流水线并行模型,张量&流水线同时应用的方式。还有DeepSpeed-train & Megatron-LM结合起来训练和推理的场景测试。这次实验应该来说难度不太大,主要是卡在了一直执着于要用 4 个A10 显卡分布式部署 qwen2.5 14b 模型。由于初始化加载模型时对于 gpu 资源的消耗效果单卡的极限总是 oom。这个实验要成功的测试需要量化减少模型大小。最后只测试了qwen2.5 7b 模型。后续空闲了再挑战一下。
五、未来期待
后边会尝试在云原生Kubernetes 上去测试验证,分布式场景的训练和推理。
参考:
Inference Overview and Features - DeepSpeedDeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.![]() https://www.deepspeed.ai/inference/https://github.com/deepspeedai/DeepSpeed
https://www.deepspeed.ai/inference/https://github.com/deepspeedai/DeepSpeed![]() https://github.com/deepspeedai/DeepSpeed
https://github.com/deepspeedai/DeepSpeed

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)