魔乐社区开发者实践系列(三):行业模型微调实践
本文以法律行业为背景,教你利用Mind应用使能套件微调训练行业模型
目前业界的模型微调实践主要集中在特定任务,行业模型的开发实践较少,一方面由于领域知识复杂、高质量数据稀缺、模型性能难以评估导致开发技术要求高、流程复杂,另一方面行业模型开发完成通常会直接应用该领域,导致开发细节较少公开。
本文以法律行业为背景,介绍利用应用使能套件开发行业模型微调训练的端到端流程,开发的模型在LawBench法律评测数据集上获得了16.57分的提升,能在法律领域具备更高专业性,帮助用户解决法律相关专业问题。
实践任务介绍
本实践以魔乐社区的law_mini_data法律数据集+Qwen2.5-7B-Instruct模型为例,介绍了数据集构建、二次预训练、微调以及模型评估的全流程,帮助开发者更好地理解端到端行业模型的微调开发流程,同时开发者也可以基于本案例自己手动复现全流程。本教程将包括如下内容:
1. 法律领域任务介绍,包括任务说明、指标和数据样例
2. 资源依赖和评估结果,包括机器资源、训练数据集、基座模型、训练套件、评估套件和评估结果等
3. 实验流程,包含开发环境配置、训练、评估等
本实践使用OpenCompass和LawBench评测集来评测模型在法律领域的能力。OpenCompass是一个开源的大模型评测平台,支持多种数据集和模型的评估,已支持昇腾NPU,同时支持LawBench评测。LawBench是一个针对中国法律体系设计的深度学习基准评测平台,旨在全面评估大型语言模型(LLMs)的法律知识、理解和应用能力。该平台精心设计了20个任务,覆盖了从简单的法律知识记忆到复杂的法律知识理解和应用,全方位评估模型的表现,具体的法律任务和指标参考,LawBench数据集-任务列表:https://github.com/open-compass/LawBench/blob/main/README.md
评测数据可参考LawBench/data,每个任务对应一个json文件,数据格式如下(以1-1法条背诵任务为例):
评测数据:https://github.com/open-compass/LawBench/tree/main/data
{"instruction": "回答以下问题,只需直接给出法条内容:下面是一个例子:\n民法商法公司法第六十条的内容是什么?\n答案:一人有限责任公司章程由股东制定。\n请你回答:","question": "民法商法农民专业合作社法第十四条的内容是什么?","answer": "答案:设立农民专业合作社,应当召开由全体设立人参加的设立大会。设立时自愿成为该社成员的人为设立人。,设立大会行使下列职权:,(一)通过本社章程,章程应当由全体设立人一致通过;,(二)选举产生理事长、理事、执行监事或者监事会成员;,(三)审议其他重大事项。"}
资源依赖和评估结果
PART 01
机器资源
本实践所需的机器资源为单台昇腾Atlas 900 A2 POD单机八卡
PART 02
训练数据集
本实践采用的数据集为魔乐社区的law_mini_data数据集,该数据集根据lawbench数据集来源进行构造,并剔除了用于评测的数据。数据共包含预训练与微调两部分,其中:
pretrain文件夹存放的law_mini_pretrain_data.json数据集用于领域预训练。
finetune文件夹存放的law_mini_finetune_data.json数据集和general_field_mini_finetune_data.json数据集分别用于法律领域微调和通用领域微调。
用户可在此处下载该数据集,本实践以数据集保存至/home/law/law_mini_data路径为例。
数据集下载地址:https://modelers.cn/datasets/AI-Research/law_mini_data
1. 数据示例与构建方式
(1)预训练数据
数据示例如下:

数据构建方式:
通过LawRefBook,JEC-QA,DISC-Law-SFT(判决预测,司法摘要,法律考试,法律问答)源数据构建,总数据量大约在170k左右。
(2)法律微调数据
数据示例如下:

数据构建方式:
针对LawBench每个任务的数据来源构建对应的微调数据集。例如,给定数据集D有10000条数据,假设任务A选取数据集D其中500条进行评估,则微调数据集A'从剩下的9500条中随机抽取一定的样本,仿照任务A的形式构建微调数据。采样方式为:随机抽取2000条数据,不足2000条数据则使用全量数据,共构建32774条领域微调数据。
(3)通用任务微调数据
数据示例如下:

数据构建方式:
取自BAAI/Infinity-Instruct数据集,由智源研究院发布,包括Infinity-Instruct-7M基础指令数据集和Infinity-Instruct-Gen对话指令数据集,中英文微调数据各选取32774条。
微调数据中,中文:英文:领域 = 1:1 :1。
PART 03
基座模型
Instruct模型相比base模型能够更好地理解和执行复杂的自然语言指令。本实践为了开发出更优秀的行业模型,采用的基座模型为Qwen2.5-7B-Instruct,用户可在魔乐社区下载该模型权重文件,本实践以模型保存到/home/law/Qwen2.5-7B-Instruct路径为例。
模型权重下载地址:https://modelers.cn/models/AI-Research/Qwen2.5-7B-Instruct
PART 04
训练套件
本实践以应用使能套件作为预训练与微调套件,该套件基于Transformers框架和常用的开源技术栈,更好的支持HF格式模型,可以提供简化的训练流程,无需配置复杂的并行化策略,适合快速开发中小型模型的训练和部署,具有良好的易用性,包含了常用的模型预训练、微调、模型合并、推理等功能。
套件开源仓地址:https://gitee.com/ascend/openmind
PART 05
评估套件
本实践采用的评估套件为OpenCompass,OpenCompass是由上海人工智能实验室研发的大模型评测一站式平台,提供公平、公开、可复现的大模型评测方案,支持70+数据集和20+Huggingface及API模型。当前,OpenCompass已经原生支持昇腾NPU,通过简单的配置,即可在昇腾NPU上使用OpenCompass评测大模型的能力。
OpenCompass网址:https://github.com/open-compass/opencompass/tree/main
PART 06
评估结果
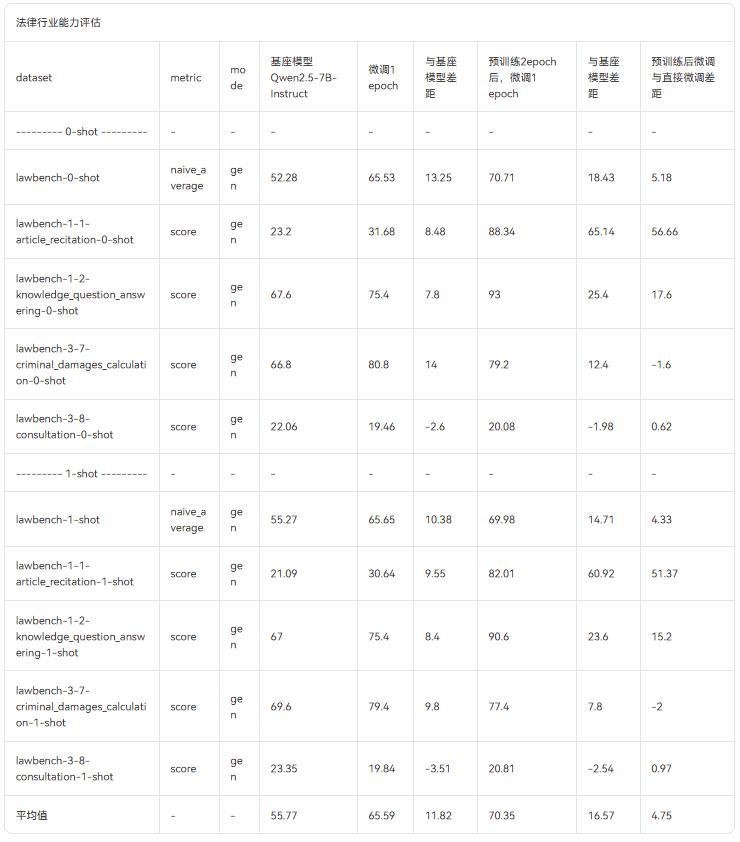
部分评估结果见下表所示,详细评估结果见魔乐社区数据集介绍,表中红色表示相较于基准模型,分数劣化,绿色表示相较于基准模型,分数提升。
数据集地址:
https://modelers.cn/datasets/AI-Research/law_mini_data
1. 法律行业能力评估结果
2. 通用领域评估结果

我们发现在法律行业方面,直接进行SFT微调,与进行二次预训练后,再进行SFT微调,均能够获得较高的行业能力提升,相比较而言,进行二次预训练后的SFT微调,能够获得更好的性能提升。
而对于通用能力方面,在进行了行业模型的SFT微调后,并没有对通用能力造成显著影响。在120个评估任务中,直接进行SFT微调的模型,评估平均分数增加了0.24,二次预训练后微调的模型,评估平均分数也只下降了1.67。
而对于行业能力评估,直接进行SFT微调能够获得11.82的平均分提升,二次预训练后微调,更是获得了16.57的平均分提升。
实验流程
本实践涉及的实验包含两部分:训练与评估。
训练包括:先做二次预训练,再做行业+通用领域的SFT微调。
评估包括:LawBench法律领域的大语言模型综合评估;通用领域评估
PART 01
开发环境配置
关键版本依赖
|
软件 |
版本 |
|
Python |
3.10 |
|
PyTorch |
2.1.0 |
|
Transformers |
4.47.1 |
|
CANN |
8.1.RC1 |
|
应用使能套件 |
1.1.0 |
1. CANN环境参考官方指导
CANN环境准备:
https://www.hiascend.com/document/detail/zh/canncommercial/81RC1/softwareinst/instg/instg_0000.html?Mode=PmIns&InstallType=local&OS=Ubuntu&Software=cannToolKit
2. 应用使能套件源码安装
该步骤会自动安装torch和torch_npu
git clone -b 1.1.0 https://gitee.com/ascend/openmind.gitcd openmindpip install .[pt]
3. OpenCompass安装与环境配置
git clone https://github.com/open-compass/opencompass.gitcd opencompasspip install -e .
OpenCompass安装完成后,还需要下载通用领域评估集、LawBench评估集和安装Humaneval及其相关依赖。我们在OpenCompass文件夹执行:
(1)准备通用领域评估集
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zipunzip OpenCompassData-core-20240207.zip
(2)准备LawBench评估集
git clone https://github.com/open-compass/LawBench.gitmkdir ./data/lawbenchcp -r ./LawBench/data/zero_shot ./data/lawbenchcp -r ./LawBench/data/one_shot ./data/lawbenchmkdir ./data/lawbench/eval_assetscp -r ./LawBench/evaluation/utils/data/* ./data/lawbench/eval_assets
(3)安装Humaneval及其相关依赖
git clone https://github.com/open-compass/human-eval.gitpip install -e human-eval
(4)pip安装如下依赖包
pip install rouge_chinese==1.0.3 cn2an==0.5.22 ltp==4.2.13 python-Levenshtein==0.21.1 pypinyin==0.49.0 tqdm==4.64.1 timeout_decorator==0.5.0PART 02
训练
经过实验尝试,我们发现只进行SFT微调在个别行业任务的提升效果一般,所以改进了方法,先进行二次预训练再进行SFT微调,通过二次预训练来丰富7B模型的语言能力,进而再通过微调来提升模型性能。
1. 二次预训练
(1)在应用使能套件源码目录下新建qwen2.5-pretrain.yaml文件,内容如下:
# model_name_or_path请传入本地模型路径model_name_or_path: /home/law/Qwen2.5-7B-Instruct# methodstage: ptdo_train: truefinetuning_type: fulltemplate: qwen# deepspeed配置路径,应用使能套件代码仓下已有deepspeed: examples/deepspeed/ds_z3_config.jsontrust_remote_code: True# dataset请传入law_mini_pretrain_data.json本地路径dataset: /home/law/law_mini_data/pretrain/law_mini_pretrain_data.jsoncutoff_len: 4096max_length: 4096# outputlogging_steps: 1overwrite_output_dir: trueoutput_dir: saves/Qwen2.5-7B-Instruct-pretrain-epoch1# trainper_device_train_batch_size: 2gradient_accumulation_steps: 1learning_rate: 1.0e-5lr_scheduler_type: cosinewarmup_ratio: 0.1bf16: truenum_train_epochs: 2seed: 1234save_strategy: "epoch"
训练参数说明可以参考,应用使能套件训练参数,其中:
model_name_or_path:待微调的模型路径,例如:/home/law/Qwen2.5-7B-Instruct
stage:训练阶段,预训练设置为pt
dataset:数据集路径,例如:/home/law/law_mini_data/pretrain/law_mini_pretrain_data.json
output_dir:模型保存权重路径,例如:saves/Qwen2.5-7B-Instruct-pretrain-epoch1
(2) 完成上述配置后,在应用使能套件的源码目录下通过如下命令即可启动二次预训练:
openmind-cli train qwen2.5-pretrain.yaml2.行业+通用域SFT微调
(1)在准备好的law_mini_data数据集文件夹下,新建dataset_info.json文件,并填入如下内容:
"law_mini_finetune_data": {"file_name": "law_mini_finetune_data.json","local_path": "/home/law/law_mini_data/finetune","columns": {"prompt": "instruction","query": "question","response": "answer","system": "system","tools": "tools","history": "history"}},"general_field_mini_finetune_data": {"local_path": "/home/law/law_mini_data/finetune","file_name": "general_field_mini_finetune_data.json","formatting": "sharegpt","columns": {"messages": "conversations","system": "system","tools": "tools"}}}
其中local_path传入本地数据集路径,例如:/home/law/law_mini_data/finetune。
(2)在应用使能套件的源码目录下新建openmind-cli train qwen2.5-pretrain+sft.yaml文件,文件内容如下:
# model_name_or_path请传入本地模型路径model_name_or_path: saves/Qwen2.5-7B-Instruct-pretrain-epoch1/checkpoint-24380/# methodstage: sftdo_train: truefinetuning_type: fulltemplate: qwen# deepspeed配置路径,应用使能套件代码仓下已有deepspeed: examples/deepspeed/ds_z3_config.jsontrust_remote_code: True#custom_dataset_info请传入步骤(1)中的dataset_info.json的路径custom_dataset_info: /home/law/law_mini_data/dataset_info.json# dataset请传入步骤(1)文件中的数据集名称dataset: law_mini_finetune_data, general_field_mini_finetune_datacutoff_len: 4096max_length: 4096# outputlogging_steps: 1overwrite_output_dir: trueoutput_dir: saves/Qwen2.5-7B-Instruct-pretrain_sft# trainper_device_train_batch_size: 2gradient_accumulation_steps: 1learning_rate: 1.0e-6lr_scheduler_type: cosinewarmup_ratio: 0.1bf16: truenum_train_epochs: 1seed: 1234save_strategy: "epoch"
其中:
model_name_or_path:需改为二次预训练后保存的权重路径,例如:saves/Qwen2.5-7B-Instruct-pretrain-epoch1/checkpoint-24380/
stage:训练阶段,微调设置为sft
cunstom_dataset_info:步骤(1)中自定义数据集配置文件路径,例如:/home/law/law_mini_data/dataset_info.json
dataset:自定义数据集配置文件中数据集名称,例如:law_mini_finetune_data, general_field_mini_finetune_data
output_dir:模型保存权重路径,例如:saves/Qwen2.5-7B-Instruct-pretrain_sft
(3)在配置完环境和微调配置文件后,在应用使能套件的源码目录下通过如下命令启动微调训练:
openmind-cli train qwen2.5-pretrain+sft.yamlPART 03
评估
本次实践中,我们使用OpenCompass工具,对大模型的法律领域能力和通用领域能力进行评估。在用户完成4.1.3节中相关的环境配置后,需要通过如下步骤完成OpenCompass评估脚本配置(如下操作均在OpenCompass目录下进行):
1. 法律行业能力评估
(1)修改examples/eval_qwen_7b_chat_lawbench.py,内容如下:
from mmengine.config import read_basewith read_base():from opencompass.configs.datasets.lawbench.lawbench_one_shot_gen_002588 import \lawbench_datasets as lawbench_one_shot_datasetsfrom opencompass.configs.datasets.lawbench.lawbench_zero_shot_gen_002588 import \lawbench_datasets as lawbench_zero_shot_datasets#from opencompass.configs.models.qwen.hf_qwen_7b_chat import modelsfrom opencompass.configs.models.qwen.hf_qwen2_7b_instruct_law import modelsfrom opencompass.configs.summarizers.lawbench import summarizerdatasets = lawbench_zero_shot_datasets + lawbench_one_shot_datasetsfor d in datasets:d['infer_cfg']['inferencer']['save_every'] = 1
(2)新建opencompass/configs/models/qwen/hf_qwen2_7b_instruct_law.py,内容如下,其中:path字段需要修改为待评测的模型路径
from opencompass.models import HuggingFaceCausalLM_meta_template = dict(round=[dict(role="SYSTEM",prompt="You are a helpful assistant.",begin="<|im_start|>system\n",end="<|im_end|>\n",),dict(role="HUMAN", begin="<|im_start|>user\n", end="<|im_end|>\n"),dict(role="BOT",begin="<|im_start|>assistant\n",end="<|im_end|>\n",generate=True,),],eos_token_id=151645)models = [dict(type=HuggingFaceCausalLM,abbr="qwen2_7b_instruct_law",path="/home/law/Qwen2.5-7B-Instruct", #填写待评测的本地权重路径tokenizer_kwargs=dict(padding_side="left",truncation_side="left",trust_remote_code=True,use_fast=False,),meta_template=_meta_template,max_seq_len=8192,max_out_len=1024,batch_size=1,batch_padding=True,run_cfg=dict(num_gpu=1),model_kwargs=dict(torch_dtype="torch.float",device_map="npu",),)]
(3) 配置完上述文件后,通过如下命令启动评估:
python run.py examples/eval_qwen_7b_chat_lawbench.py --debug2. 通用领域评估
(1)新建examples/eval_qwen2_7b_instruct_general_field.py,内容如下:
from mmengine.config import read_basewith read_base():from opencompass.configs.models.qwen.hf_qwen2_7b_instruct_general import modelsfrom opencompass.configs.datasets.ceval.ceval_gen import ceval_datasetsfrom opencompass.configs.datasets.mmlu.mmlu_gen_4d595a import mmlu_datasetsfrom opencompass.configs.datasets.gpqa.gpqa_openai_simple_evals_gen_5aeece import gpqa_datasetsfrom opencompass.configs.datasets.gsm8k.gsm8k_gen_1d7fe4 import gsm8k_datasetsfrom opencompass.configs.datasets.humaneval.humaneval_gen_8e312c import humaneval_datasetsfrom opencompass.configs.datasets.mbpp.sanitized_mbpp_mdblock_gen_a447ff import sanitized_mbpp_datasetsfrom opencompass.configs.datasets.math.math_0shot_gen_393424 import math_datasetsdatasets = ceval_datasets + mmlu_datasets + gpqa_datasets + \gsm8k_datasets + humaneval_datasets + sanitized_mbpp_datasets + math_datasets
(2)新建opencompass/configs/models/qwen/hf_qwen2_7b_instruct_general.py,内容同4.3.1节步骤(2),其中path字段需要修改为待评测的模型路径。
(3)配置完上述文件后,通过如下命令启动评估:
python run.py examples/eval_qwen2_7b_instruct_general_field.py --debug若遇到gpqa数据集自动下载失败问题,可通过手动下载该数据集并上传至data/gpqa路径解决。
gpqa数据集下载地址:http://opencompass.oss-cn-shanghai.aliyuncs.com/datasets/data/gpqa.zip

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 8
8 0
0- 0



 已为社区贡献70条内容
已为社区贡献70条内容

所有评论(0)