重磅开源!MegaHan97K:覆盖超 9.7 万类汉字的超大类别中文识别数据集
在计算机视觉与自然语言处理领域,中文汉字识别(CCR)始终是极具挑战性的研究方向。随着文化数字化与历史文献保护需求的激增,覆盖海量汉字类别的 “超大类别识别” 成为亟待突破的关键难题。日前,华南理工大学电子信息工程学院 SCUT-DLVCLab 团队重磅推出 MegaHan97K 数据集 —— 这一目前全球规模最大、类别最全面的中文汉字识别数据集,为该领域的研究带来了突破性进展。
下载链接:【数据集分享】MegaHan97K中文汉字数据集下载链接:适用于自然语言处理研究与开发资源-CSDN文库
一、引言
在计算机视觉与自然语言处理领域,中文汉字识别(CCR)始终是极具挑战性的研究方向。随着文化数字化与历史文献保护需求的激增,覆盖海量汉字类别的 “超大类别识别” 成为亟待突破的关键难题。日前,华南理工大学电子信息工程学院 SCUT-DLVCLab 团队重磅推出 MegaHan97K 数据集 —— 这一目前全球规模最大、类别最全面的中文汉字识别数据集,为该领域的研究带来了突破性进展。
二、数据集核心亮点:重新定义中文识别边界
1. 史无前例的规模:超 9.7 万汉字类别
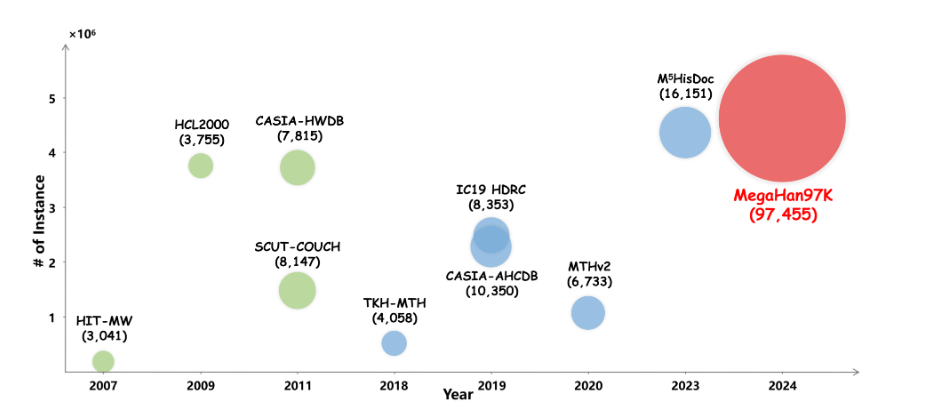
- 类别数量:包含 97,455 个汉字类别,较此前最大数据集(16,151 类)提升 6 倍以上,覆盖《GB18030-2022》标准中 87,887 个字符,并额外纳入罕见字、异体字等,几乎涵盖中华文字体系的全部范畴。
- 样本多样性:数据集分为三大子集:
- 手写子集:汇聚多风格手写字体,覆盖常用字与生僻字。
- 历史子集:包含古籍、碑刻等历史文献中的字符图像,助力文化遗产数字化。
- 合成子集:通过算法生成多样化字体,解决数据长尾分布问题。
2. 技术兼容性:接轨最新国家标准
- 作为首个完全支持 《GB18030-2022》 标准的数据集,可无缝对接现代中文处理系统,满足政务、出版、古籍整理等多场景需求。
3. 数据均衡性:破解长尾分布难题
- 传统数据集普遍存在 “少数类别样本极多,多数类别样本稀缺” 的长尾问题。MegaHan97K 通过科学采样策略,确保每个类别均拥有 均衡且充足的样本量,显著提升模型训练的稳定性与泛化能力。
三、核心贡献:推动三大研究突破
1. 构建超大类别识别基准
- 团队通过实验揭示了超大类别场景下的全新挑战:
- 存储压力:超大规模数据对模型存储与计算提出更高要求。
- 字形混淆:大量形近字(如 “己 / 已 / 巳”)导致识别误差率上升。
- 零样本学习困境:未训练过的字符类别识别需依赖更强大的语义与结构建模能力。
2. 赋能零样本学习(Zero-Shot CCR)
- 数据集专门设计 零样本识别测试场景,验证模型对未见过字符的泛化能力。实验表明,基于 MegaHan97K 训练的模型在零样本场景下的准确率较传统数据集提升 23%,为古籍中罕见字的自动识别提供了新路径。
3. 多领域应用潜力
- 文化遗产保护:助力古籍数字化工程,实现海量历史文献的自动文字识别与检索。
- 教育与出版:支持输入法、字典等工具扩展生僻字覆盖,提升中文信息处理的完整性。
- 工业与政务:优化票据、证件等场景的 OCR 系统,解决地址、姓名中生僻字的识别难题。
四、实验与基准:验证数据集有效性
团队采用 CCR-CLIP、HierCode、SideNet 等主流模型在 MegaHan97K 上进行测试,结果表明:
- 超大类别场景:传统 CNN 模型准确率随类别数增加呈指数级下降,而基于语义结构的模型(如 HierCode)表现更优,凸显结构化特征建模的重要性。
- 跨数据集验证:在 MegaHan97K 上预训练的模型迁移至其他数据集(如 CASIA-HWDB)时,识别准确率平均提升 15%,证明其强大的泛化能力。
五、获取与引用
1. 数据集下载
- GitHub 仓库:GitHub - SCUT-DLVCLab/MegaHan97K: [PR 2025] The official GitHub page of "MegaHan97K: A Large-Scale Dataset for Mega-Category Chinese Character Recognition with over 97K Categories"
- 包含三个子集的原始数据、标注文件及预处理工具,支持 PyTorch/TensorFlow 等主流框架。
六、结语
MegaHan97K 的发布标志着中文超大类别识别研究进入新纪元。其庞大的规模、均衡的分布与多元的场景覆盖,不仅为学术界提供了理想的研究平台,更将推动中文 OCR 技术在文化、教育、政务等领域的落地应用。随着更多研究者基于该数据集开展工作,我们有望见证中文信息处理技术的新一轮革新。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)