LangChain 本地模型部署指南:Llama3 与 Open-WebUI 的可视化交互开发
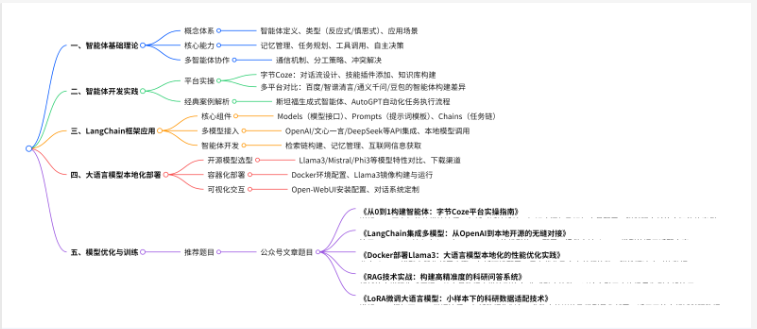
这篇文章系统介绍了智能体(Agent)和大语言模型(LLM)的开发与应用体系。内容包括:智能体的核心能力、构建方法及多智能体协作;基于Coze、LangChain等平台的开发实践;开源模型(Llama3、Mistral等)的本地化部署;从数据收集到模型训练、优化(RAG、LoRA微调、量化)的全流程技术;以及智能体在科研等场景的应用案例。课程采用"理论-实践-优化"的体系,帮助
技术点目录
——————————————————————————————————————————————————
前言综述
在人工智能技术迅猛发展的当下,大语言模型与智能体技术已成为推动科研创新与产业智能化转型的核心动力。从 GPT 系列模型的迭代到 Llama、DeepSeek 等开源模型的崛起,大语言模型不仅革新了自然语言处理领域,更通过智能体(Agent)技术实现了自动化任务执行、多模态交互等进阶应用。系统构建 “理论 - 实践 - 优化” 的知识体系,从智能体的记忆、规划、工具调用等核心能力解析入手,通过字节 Coze、LangChain 等框架实操,帮助学员掌握智能体开发全流程。课程重点涵盖开源大语言模型的本地化部署(如 Llama3、Mistral)、Docker 容器化技术及模型优化(RAG 检索增强、LoRA 微调、量化压缩),同时结合斯坦福小镇、AutoGPT 等经典案例,深入剖析智能体在科研数据处理、自动化实验设计等场景的应用逻辑。通过从数据集构建到模型推理的全链条实践,助力科研人员将 AI 技术深度融入科研工作流,提升创新效率与数据安全管理能力。
第一章、智能体(Agent)入门
1、智能体(Agent)概述(什么是智能体?智能体的类型和应用场景、典型的智能体应用,如:Google Data Science Agent等)
2、智能体(Agent)与大语言模型(LLM)的关系
3、智能体(Agent)的五种能力(记忆、规划、工具、自主决策、推理)
4、多智能体(Multi-Agent)协作
5、智能体(Agent)构建的基本步骤
第二章、基于字节Coze 构建智能体(Agent)
1、Coze平台概述
2、从0到1搭建第一个智能体(Agent)
3、智能体(Agent)基础设置(多Agent模式、对话流模式、LLM模型设置、提示词撰写等)
4、为智能体(Agent)添加技能(插件、工作流、触发器、卡片等)
5、为智能体(Agent)添加知识(知识库介绍、添加知识库、知识库检索与召回等)
6、为智能体(Agent)添加记忆(创建和使用变量、数据库、长期记忆的开启、修改和删除等)
7、提升智能体(Agent)的对话体验(设置开场白、快捷指令等)
8、智能体(Agent)的预览、调试与发布
第三章、基于其他平台构建智能体(Agent)
1、基于百度平台构建智能体
2、基于智谱清言平台构建智能体
3、基于通义千问平台构建智能体
4、基于豆包平台构建智能体
第四章、国内外智能体(Agent)经典案例详解
1、斯坦福小镇:生成式智能体(Generative Agents)
2、ByteDance Research推出的论文检索智能体
3、Google Data Science Agent
4、AutoGPT:通过自然语言的需求描述执行自动化任务
5、OpenAI推出的首个智能体(Agent):Operator
第五章、大语言模型应用开发框架LangChain入门
1、LangChain平台概述(LangChain框架的核心功能与特点)
2、LangChain安装与使用
3、LangChain的核心组件:Models(模型)、Prompts(提示词)、Indexes(索引)、Chains(链)、Agents(智能体)、Memory(记忆)
第六章、基于LangChain的大模型API接入
1、在LangChain 中使用OpenAI大语言模型
2、在LangChain 中使用文心一言大语言模型
3、在LangChain 中使用DeepSeek大语言模型
4、在LangChain 中使用智谱清言大语言模型
5、在LangChain 中使用本地开源大语言模型
第七章、基于LangChain的智能体(Agent)开发
1、使用LangChain构建Agent的使用流程
2、LangChain的配置与管理
3、LangChain提示词模板(PromptTemplate)的创建与调用
4、(实操演练)
利用LLMRequestsChain类实现从互联网获取信息(查询天气等)
5、LangChain链式请求的创建与调用
6、LangChain让AI记住你说过的话
第八章、开源大语言模型及本地部署
1、开源大语言模型简介(开源大语言模型的基本概念、开源大语言模型与闭源大语言模型的对比)
2、开源大语言模型(Llama3、Mistral、Phi3、Qwen2、DeepSeek等)下载与使用
3、使用Docker部署开源大语言模型(Docker的基本概念、Docker的核心组件与功能、Docker的安装与配置、在Docker中部署Llama3等开源大语言模型)
4、使用Open-WebUI构建Web可视化交互(类似ChatGPT)的开源大语言模型对话系统(Open-WebUI的基本概念与功能、Open-WebUI的下载与安装、配置一个用于对话系统的Open-WebUI)
第九章、从0到1搭建第一个大语言模型
1、数据集构建(数据集的收集与处理、从互联网上收集文本数据、数据清洗与标注、常用的数据集格式,如:CSV、JSON、TXT等)
2、大语言预训练模型的选择(预训练模型的优势、常见的预训练模型,如:GPT、BERT等、从Hugging Face等平台下载预训练模型)
3、大语言模型的训练(模型训练的基本步骤、训练过程中的监控与调试)
4、大语言模型的优化(常见训练参数,如:学习率、批次大小等、参数调整与优化技巧、优化训练参数以提高模型性能)
5、大语言模型的推理(模型推理与模型训练的区别、提高推理速度的技巧、从输入到输出的完整推理流程)
6、大语言模型的部署与应用(模型部署的基本流程、部署环境的配置与管理)
第十章、大语言模型优化
1、检索增强生成(RAG)技术详解(RAG的基本原理、RAG在大语言模型中的作用和优势、RAG的系统架构、RAG检索结果与生成结果相结合的方法、RAG知识库的构建方法)
2、向量数据库简介与向量检索技术详解(使用向量数据库进行快速检索)
3、文本嵌入(Text Embedding)技术概述(常用的文本嵌入模型、使用GPT API)
4、基于RAG的问答系统设计
5、微调(Fine-Tuning)技术详解(微调的基本原理、微调在大语言模型中的作用、准备一个用于微调的数据集、常见的微调方法,如PEFT、LoRA等、不同任务的微调策略、微调过程中的常见问题与解决方案)
6、微调一个预训练的GPT模型
7、量化技术详解(量化的基本概念、量化在模型优化中的重要性、量化的不同方法,如:静态量化、动态量化、混合量化等、量化处理的步骤)
了解更多
V头像

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)