Python数据分析-中风数据集预测分析
中风数据集预测分析
一、研究背景和应用
中风是一种严重的神经系统疾病,具有高发病率、高死亡率和高致残率的特点。全球范围内,中风是导致死亡和残疾的主要原因之一。随着人口老龄化的加剧,中风的发病率也在逐年上升,给社会和家庭带来了沉重的负担。目前,中风的诊断主要依赖于临床症状、影像学检查和实验室检查等方法。然而,这些方法存在一定的局限性,如诊断准确率不高、检测时间长等。因此,寻找一种快速、准确的中风诊断方法具有重要的临床意义。
研究意义:
- 提高中风的诊断准确率:通过对中风数据集的分析,可以挖掘出与中风相关的潜在特征和模式,从而提高中风的诊断准确率。
- 缩短中风的诊断时间:利用数据分析技术,可以快速处理和分析大量的中风数据,从而缩短中风的诊断时间,为患者提供及时的治疗。
- 为中风的治疗提供依据:通过对中风数据集的分析,可以了解中风的发病机制和危险因素,为中风的治疗提供依据。
- 降低中风的发病率和死亡率:通过对中风数据集的分析,可以发现中风的早期预警信号,从而采取相应的预防措施,降低中风的发病率和死亡率。
- 促进医疗信息化的发展:中风数据集的分析需要借助于先进的信息技术和数据分析工具,这将促进医疗信息化的发展,提高医疗服务的质量和效率。
二、实证分析
首先导入数据分析所用到的包:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['KaiTi'] #中文
plt.rcParams['axes.unicode_minus'] = False #负号
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier读取数据查看情况
data=pd.read_csv('stroke_data.csv')
data.head(10)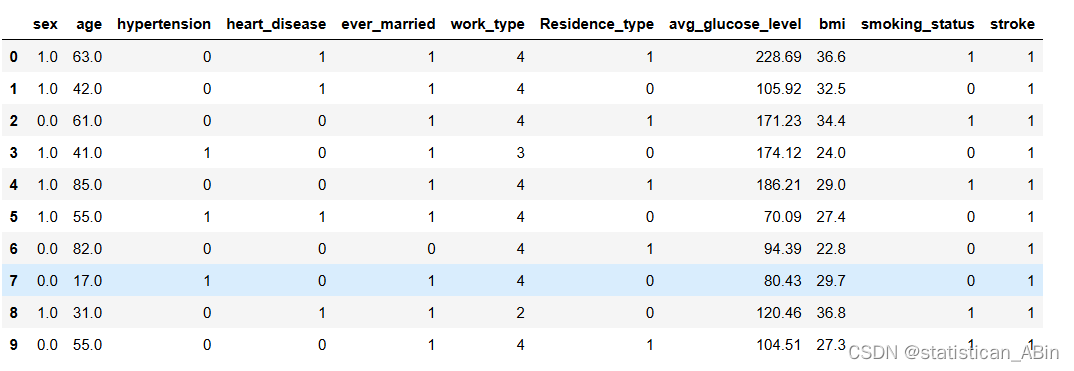
变量名称 中文含义 变量类别
sex 性别 分类型变量
age 年龄 数值型变量
hypertension 是否有高血压 分类型变量
heart_disease 是否有心脏病 分类型变量
ever_married 是否结过婚 分类型变量
work_type 工作类型 分类型变量
Residence_type 居住地类型 分类型变量
avg_glucose_level 平均血糖水平 数值型变量
bmi 体质指数 数值型变量
smoking_status 吸烟状态 分类型变量
stroke 是否中风 分类型变量
查看数据类型以及其他情况
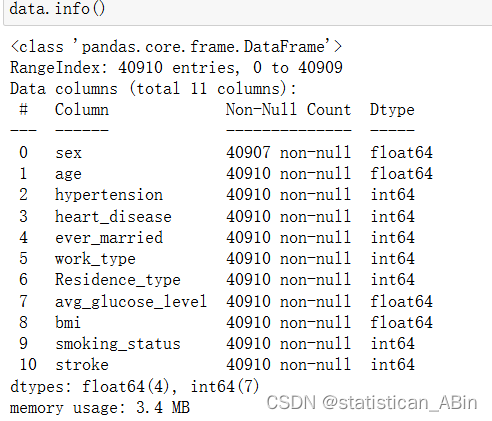
“gender”列中有 3 行缺少一个值 - 由于计数可以忽略不计,我将任意将它们设置为女性,即 0。
看一下重复值 发现没有
import missingno as msno
msno.matrix(data) 
描述性分析看看
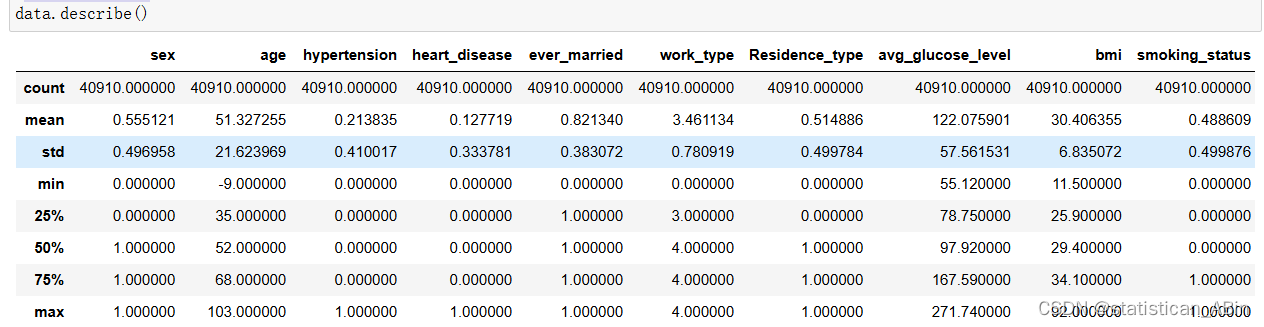 接下来可以使用pandas的groupby函数对数据框进行分组
接下来可以使用pandas的groupby函数对数据框进行分组
按性别和吸烟状态分组,计算中风发生率 显示每个性别和吸烟状态组合的中风发生率
grouped.pivot(index='sex', columns='smoking_status', values='stroke').plot(kind='bar', stacked=True)
plt.title('Stroke Rate by Gender and Smoking Status')
plt.xlabel('Gender')
plt.ylabel('Stroke Rate')
plt.show()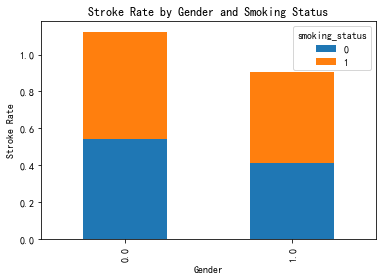
为了更好地分析数据,我决定将编码转换为实际值。
data_vis.sex[data_vis['sex'] == 0] = 'Female'
data_vis.sex[data_vis['sex'] == 1] = 'Male'
data_vis.hypertension[data_vis['hypertension'] == 0] = 'Not had hypertension'
data_vis.hypertension[data_vis['hypertension'] == 1] = 'Had hypertension'
data_vis.heart_disease[data_vis['heart_disease'] == 0] = 'Not had heart disease'
data_vis.heart_disease[data_vis['heart_disease'] == 1] = 'Had heart disease'接下来对特征进行可视化
feature_cols = [x for x in data_vis.columns if x not in 'stroke']
plt.figure(figsize=(25,35))
# loop for subplots
for i in range(len(feature_cols)):
plt.subplot(8,5,i+1)
plt.title(feature_cols[i])
plt.xticks(rotation=90)
plt.hist(data_vis[feature_cols[i]],color = "deepskyblue")
plt.tight_layout()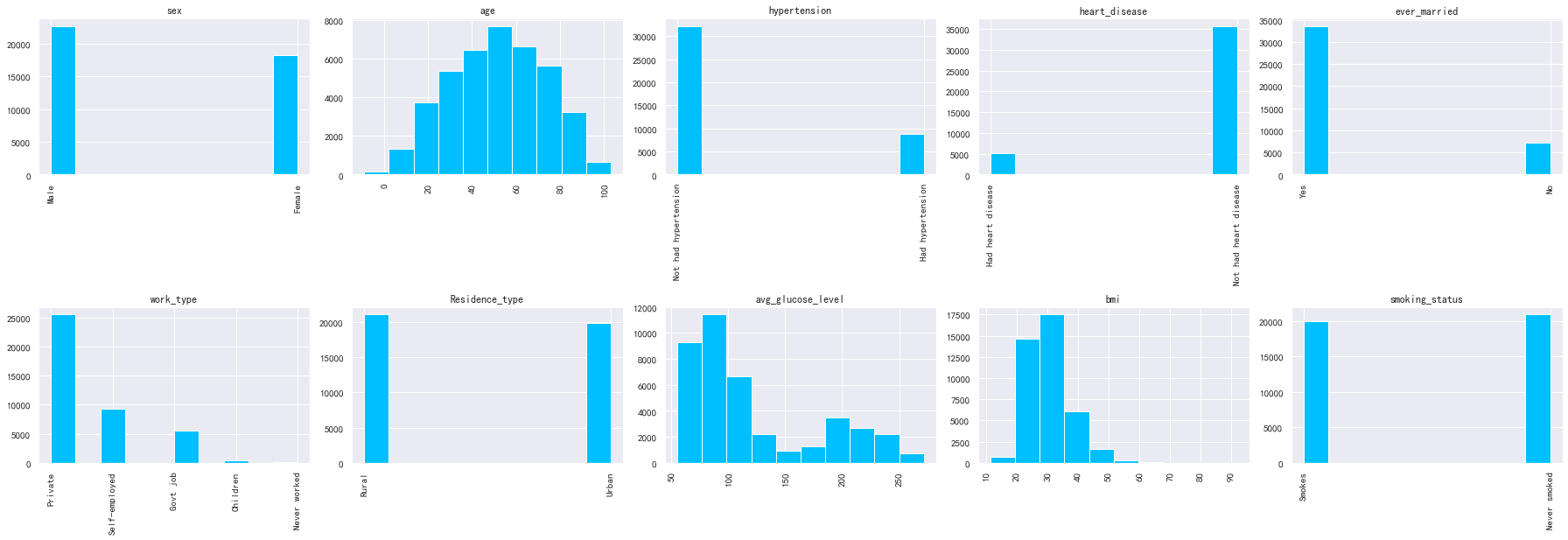
因为按理来说不能有负年龄,故我们不要
data = data.drop(data[data.age < 0].index)
data_vis = data_vis.drop(data_vis[data_vis.age < 0].index)
len(data. index)看一下目标特征的可视化
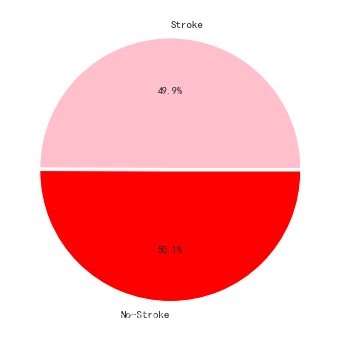
发现还是比较平均的
随后查看每个特征之间的相关性
data.drop('stroke', axis=1).corrwith(data.stroke).plot(kind='bar', grid=True, figsize=(10, 6), title="Correlation with Stroke",color="green"); 
我们发现特征“bmi”,“Residence_type”,“work_type”与Storke的相关性最小。所有其他特征都与中风有显著的相关性。
随后看两个特征之间的相关性
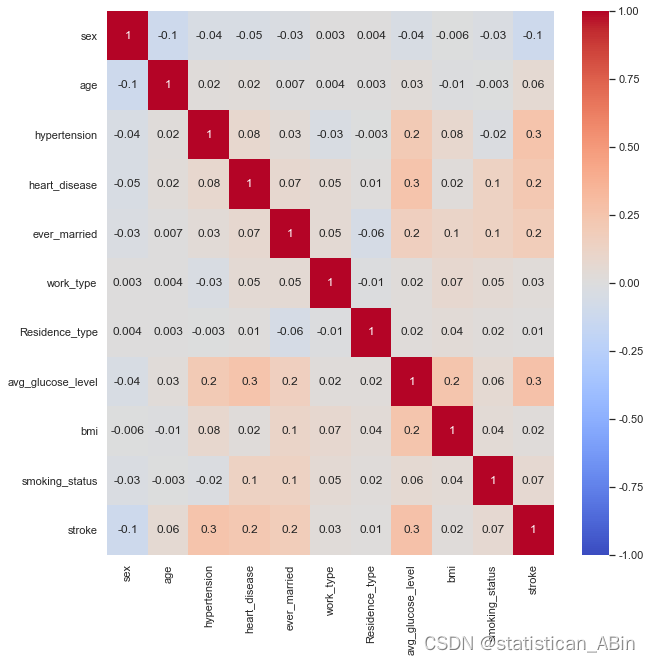
接下来看一下按分类划分的频率可视化图 查看各个特征与响应变量之间的关系
plt.figure(figsize = (30,23))
plt.suptitle('Stroke by categorical features')
#subplots
for i in enumerate(features):
plt.subplot(2,4, i[0]+1)
x = sns.countplot(i[1] ,hue='stroke', data=data_vis, palette = ['yellow','pink'])
for z in x.patches:
x.annotate('{:.1f}'.format((z.get_height()/data_vis.shape[0])*100)+'%',(z.get_x()+0.25, z.get_height()+0.01))
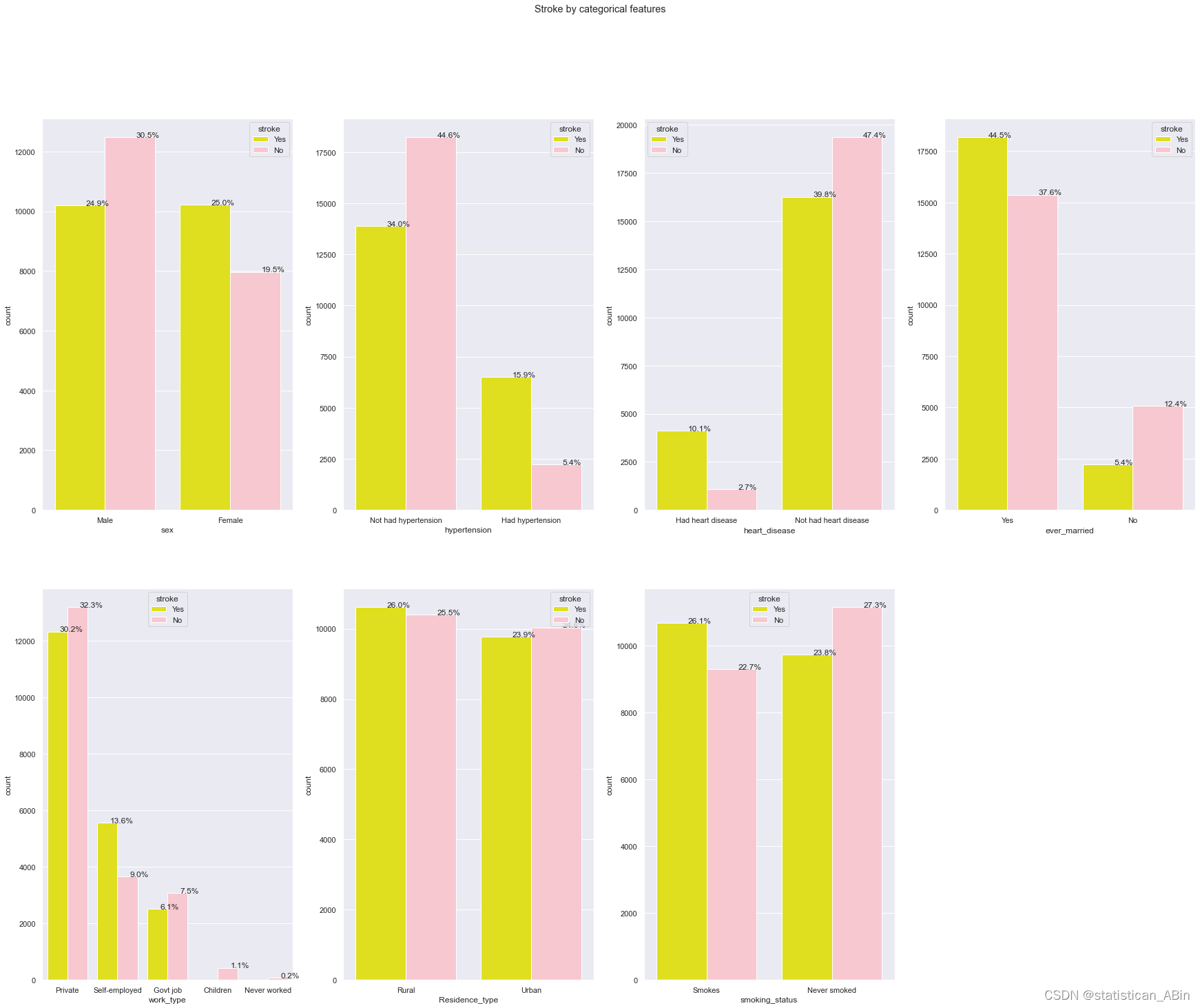
我们从上面的图可以看出
居住类型与中风之间没有明确的联系,但在农村住宅类型中存在轻微的中风倾向。
吸烟、高血压和心脏病会增加中风的风险。
工作类型为“自雇”的人比其他类型的工作具有更高的中风风险。
性别对中风没有影响。
接下来结合分类特征对中风的影响 以小提琴图的格式展示
for i in range (len(features)):
for x in range (len(features)-i-1):
sns.catplot(data=data, x=features[i], y=features[i+x+1], hue="stroke", kind="violin",palette = ['blue','black']).set(title="The effect of "+features[i] + " and "+features[i+x+1]+" on stroke")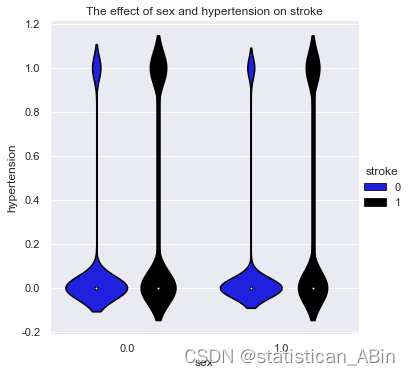
接下来看一下中风响应变量的分布情况
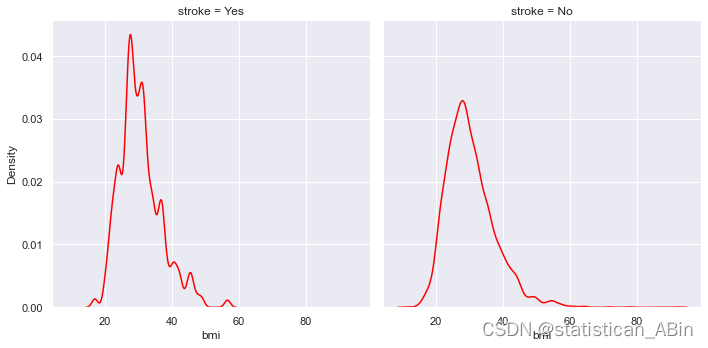
plt.figure(figsize=(10,6))
sns.displot(data=data_vis,col='stroke',x=avg_glucose_level,color='red')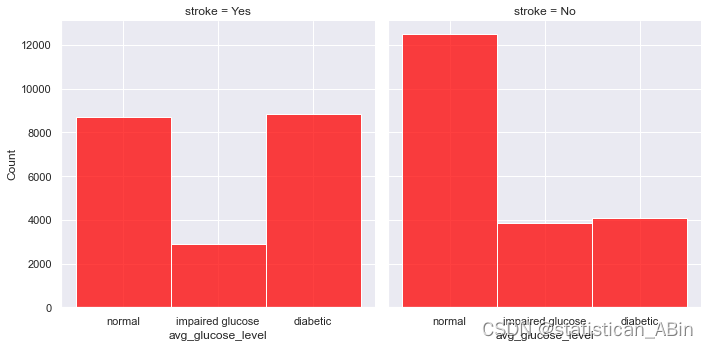
通过上面图形可以分析出目标列值的平均葡萄糖水平分布不同。此功能是解释性功能;高血糖的人比正常值的人更容易中风。
features = ['stroke','smoking_status','heart_disease','hypertension']
for i in enumerate(features):
box_cols = ['bmi', 'age', 'avg_glucose_level']
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(20,8))
fig.suptitle('Distribution of Continuous Features by '+i[1], y = 1.05);
for col, ax in zip(box_cols, axes.ravel()):
sns.boxplot(data=data_vis, x=i[1], y=col ,palette = ['green','yellow'], ax=ax)
plt.tight_layout() 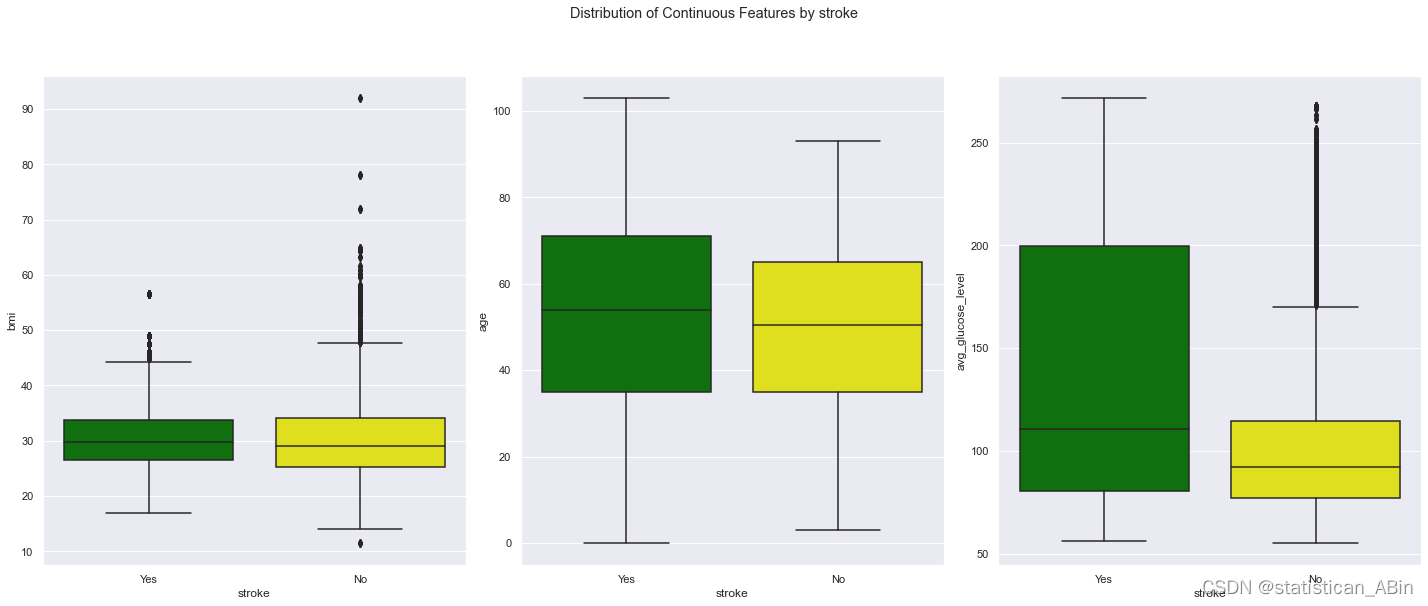 基于以上 我们又可以看出当中风/高血压/heart_disease时,“avg_glucose_level”特征中的中位数,范围和值更高。
基于以上 我们又可以看出当中风/高血压/heart_disease时,“avg_glucose_level”特征中的中位数,范围和值更高。
然后还需要查看响应变量y的分布
接下来进行机器学习
##KNN模型
#Knn
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=50)
model.fit(X_train,y_train )
model.score(X_test,y_test)
#随机森林 时间要久一点 但是精度高
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=123)
model.fit(X_train,y_train )
model.score(X_test,y_test)
三、小结
中风是一种常见的危险疾病,及时的预测和分类对患者的生命和健康具有重要意义。在这个背景下,机器学习技术被广泛应用于中风预测分类问题中。本文采用了随机森林和KNN模型来对中风数据进行预测分类,并进行了总结如下:
# 随机森林模型是一种基于决策树的集成学习模型,具有高准确率和鲁棒性的优点。该模型可以通过多棵树的平均值来减少单棵树的方差,从而提高模型的泛化能力。在中风预测分类中,随机森林模型可以通过特征选择和交叉验证等技术来提高模型的准确性和稳定性。KNN模型是一种基于距离度量的分类算法,具有简单、易用和高效的特点。该模型可以通过计算待分类样本与已有样本之间的距离来确定其所属类别。在中风预测分类中,KNN模型可以通过选择合适的距离度量方法和K值来提高模型的准确性和泛化能力。在中风预测分类中,随机森林模型和KNN模型还可以结合使用来提高分类的准确性和稳定性。例如,可以通过使用随机森林模型进行特征选择和初步分类,再将分类结果输入到KNN模型中进行进一步分类和优化。在应用随机森林和KNN模型进行中风预测分类时,需要注意数据预处理、特征选择、模型参数的调整等方面的问题。同时,还需要对模型的评价指标进行选择和优化。具体而言从上面可以看出,特征选择降低了大多数算法的模型噪声。基于随机森林的算法产生了很不错的分类结果。相比于KNN,随机森林虽然计算时间较为长,但是分类的效果很好。KNN的计算结果很快,但是在分类效果来看一般,才达到了68.9%。但是在后期我们可以优化其模型,比如改变其参数,例如网格搜索或者其他优化算法来进行搜索参数,也是一个不错的选择。同时也可以更换其模型,可以利用深度学习的神经网络来进行预测和优化。
创作不易,希望大家多点赞关注评论!!!(类似代码或报告定制可以私信)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 33
33 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)