昇腾底座+SGLang框架,成功实现Qwen3-Next Day0首发!
Qwen3-Next-80B-A3B-Thinking在复杂推理任务上表现卓越,不仅优于预训练成本更高的Qwen3-30B-A3B-Thinking-2507与Qwen3-32B-Thinking,更在多项基准测试中。基于Qwen3-Next-80B-A3B-Base模型, 千问团队同步开发并发布了Qwen3-Next-80B-A3B-Instruct与Qwen3-Next-80B-A3B-Thi
就在今天,千问团队发布了下一代基础模型架构Qwen3-Next,并开源了基于该架构的Qwen3-Next-80B-A3B系列模型。Qwen3-Next在模型架构上实现了重大突破,引入了注意力机制方面的多项创新,包括线性注意力和注意力门控机制,并在其MoE设计中进一步提升了稀疏性。Qwen3-Next-80B-A3B在“思考模式”和“非思考模式”下的性能均与规模更大的Qwen3-235B-A22B-2507相当,同时在推理速度上显著提升,尤其在长上下文场景中表现更为突出。
昇腾基于SGLang推理框架Day0支持Qwen3-Next,兼容当前SGLang框架内主流的分布式并行能力,Qwen3-Next系列模型一经发布即实现低代码无缝使能。相关模型和实践已上线魔乐社区,欢迎体验!
🔗模型链接:
https://modelers.cn/models/SGLangAscend/Qwen3-Next-80B-A3B-Instruct
01
模型介绍
Qwen3-Next结构相比Qwen3的MoE模型结构,进行了以下核心改进:混合注意力机制、高稀疏度MoE结构、一系列训练稳定友好的优化,以及提升推理效率的多token预测机制。
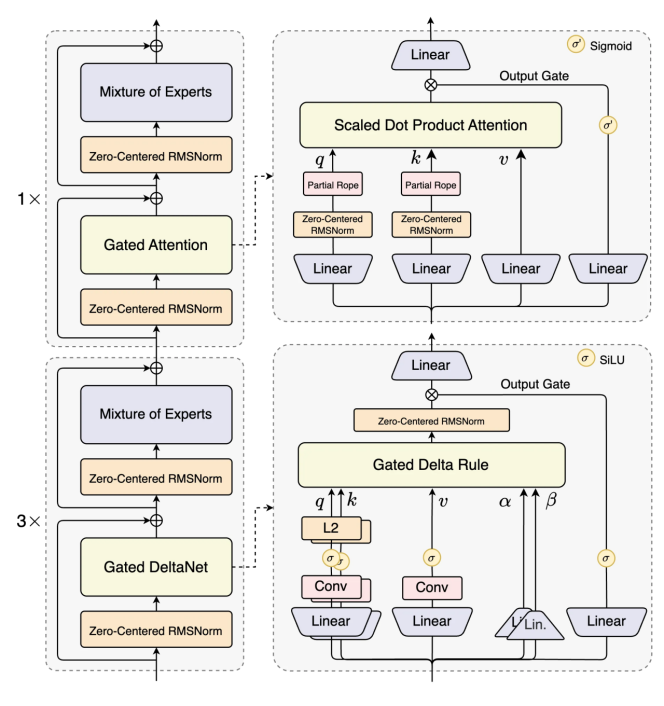
基于Qwen3-Next的模型结构训练的Qwen3-Next-80B-A3B-Base模型,拥有800亿参数仅激活30亿参数。该Base模型实现了与Qwen3-32B dense模型相近甚至略好的性能,而它的训练成本(GPU hours) 仅为Qwen3-32B的十分之一不到,在32k以上的上下文下的推理吞吐则是Qwen3-32B的十倍以上,实现了极致的训练和推理性价比。
基于Qwen3-Next-80B-A3B-Base模型, 千问团队同步开发并发布了Qwen3-Next-80B-A3B-Instruct与Qwen3-Next-80B-A3B-Thinking。
千问团队解决了混合注意力机制+高稀疏度MoE架构在强化学习训练中长期存在的稳定性与效率难题,实现了RL训练效率与最终效果的双重提升。Qwen3-Next-80B-A3B-Instruct与旗舰模型Qwen3-235B-A22B-Instruct-2507表现相当,同时在256K超长上下文处理任务中展现出显著优势。Qwen3-Next-80B-A3B-Thinking在复杂推理任务上表现卓越,不仅优于预训练成本更高的Qwen3-30B-A3B-Thinking-2507与Qwen3-32B-Thinking,更在多项基准测试中超越闭源模型Gemini-2.5-Flash-Thinking,部分关键指标已逼近Qwen3-235B-A22B-Thinking-2507。
接下来,手把手教你基于SGLang在昇腾上进行模型推理。
02
准备运行环境
|
配套 |
版本 |
|
Python |
3.11.10 |
|
torch |
2.6.0 |
|
torch_npu |
2.6.0 |
|
triton_ascend |
3.2.0 |
1. 获取CANN&Sglang安装包&环境准备
• 设备支持:
Atlas 800I/800T A3(8*64G)推理设备:支持的卡数最小为1
Atlas 800I/800T A3(8*64G):https://www.hiascend.com/developer/download/community/result?module=cann
• 环境准备指导:
https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/83RC1alpha001/softwareinst/instg/instg_0002.html?Mode=PmIns&OS=openEuler&Software=cannToolKit
2. CANN安装
# 增加软件包可执行权限,{version}表示软件版本号,{arch}表示CPU架构,{soc}表示昇腾AI处理器的版本。chmod +x ./Ascend-cann-toolkit_{version}_linux-{arch}.runchmod +x ./Ascend-cann-kernels-{soc}_{version}_linux.runchmod +x ./Ascend-cann-nnal_{version}_linux-{arch}.run# 校验软件包安装文件的一致性和完整性./Ascend-cann-toolkit_{version}_linux-{arch}.run --check./Ascend-cann-kernels-{soc}_{version}_linux.run --check./Ascend-cann-nnal{version}_linux-{arch}.run --check# 安装./Ascend-cann-toolkit_{version}_linux-{arch}.run --install./Ascend-cann-kernels-{soc}_{version}_linux.run --install./Ascend-cann-nnal{version}_linux-{arch}.run --torch_atb --install# 设置环境变量source /usr/local/Ascend/ascend-toolkit/set_env.shsource /usr/local/Ascend/nnal/atb/set_env.sh
3. Sglang安装
Sglang社区代码: https://github.com/sgl-project/sglang
git clone https://github.com/sgl-project/sglang.gitcd sglangpip install -e "python[srt_npu]"
4. triton_ascend安装
快速安装指南⏩️
• 安装包bisheng: https://sglang-ascend.obs.cn-east-3.myhuaweicloud.com/sglang/Ascend-BiSheng-toolkit_aarch64.run?AccessKeyId=HPUAXT4YM0U8JNTERLST&Expires=1788772129&Signature=NDiPdW4C7P6Af4sog/irX8pLch0%3D
• 安装包triton_ascend:https://sglang-ascend.obs.cn-east-3.myhuaweicloud.com/sglang/triton_ascend-3.2.0%2Bgitb0ea0850-cp311-cp311-linux_aarch64.whl?AccessKeyId=HPUAXT4YM0U8JNTERLST&Expires=1788772152&Signature=LGDphSSSRjhGtlx/F4oLADafVTI%3D
pip install triton_ascend-3.2.0+gitb0ea0850-cp311-cp311-linux_aarch64.whl./Ascend-BiSheng-toolkit_aarch64.run --installsource /usr/local/Ascend/ascend-toolkit/latest/bisheng_toolkit/set_env.sh
5. torch_npu安装
下载 pytorch_v{pytorchversion}_py{pythonversion}.tar.gz
tar -xzvf pytorch_v{pytorchversion}_py{pythonversion}.tar.gz# 解压后,会有whl包pip install torch_npu-{pytorchversion}.xxxx.{arch}.whl
03
下载权重
Qwen3-Next-80B-A3B-Instruct 权重及配置文件说明:
Huggingface:
https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct/tree/main
04
运行指导
单机混部(8卡16die)
cd /home/sglang# cann环境source /usr/local/Ascend/ascend-toolkit/set_env.shsource /usr/local/Ascend/nnal/set_env.sh# 运行命令python -m sglang.launch_server --model-path {权重路径} --host 127.0.0.1 --port 6688 --trust-remote-code --nnodes 1 --node-rank 0 --attention-backend hybrid_linear_attn --device npu --max-running-requests 32 --context-length 8192 --disable-radix-cache --chunked-prefill-size 32768 --max-prefill-tokens 28000 --tp-size 16 --mem-fraction-static 0.5 --disable-cuda-graph
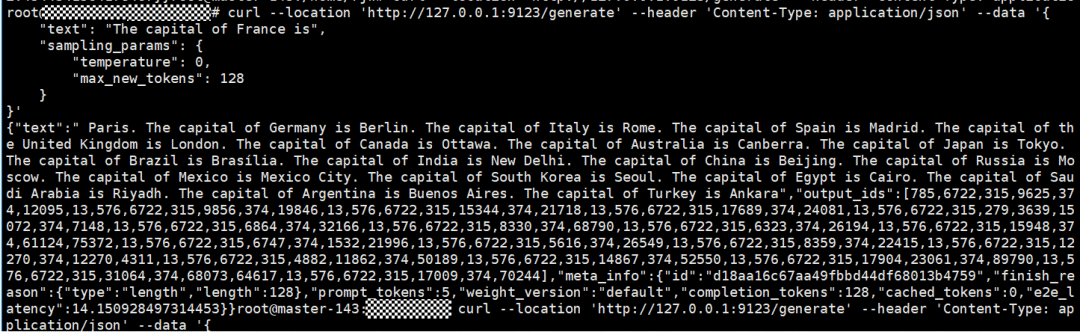
curl测试结果
对昇腾和SGLang推理框架感兴趣的开发者,欢迎扫码入群交流!


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)