【预训练语言模型】MT-DNN: Multi-Task Deep Neural Networks for Natural Language Understanding
【预训练语言模型】MT-DNN: Multi-Task Deep Neural Networks for Natural Language Understanding 预训练语言模型在下游任务微调时如果可以获得更丰富的训练任务,则提高让预训练语言模型的泛化能力,本文则通过添加多任务训练实现泛化性能的提升。核心要点包括:将NLP划分为四种类型的任务;在BERT预训练的基础上,添加若干多任务的参数,
【预训练语言模型】MT-DNN: Multi-Task Deep Neural Networks for Natural Language Understanding
预训练语言模型在下游任务微调时如果可以获得更丰富的训练任务,则提高让预训练语言模型的泛化能力,本文则通过添加多任务训练实现泛化性能的提升。核心要点包括:
- 将NLP划分为四种类型的任务;
- 在BERT预训练的基础上,添加若干多任务的参数,并采用多任务训练
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | MT-DNN |
| 2 | 发表位置 | ACL 2019 |
| 3 | 所属领域 | 自然语言处理、预训练语言模型 |
| 4 | 研究内容 | 预训练语言模型、多任务学习 |
| 5 | 核心内容 | Multi-task Fine-tuning |
| 6 | GitHub源码 | https://github.com/namisan/mt-dnn |
| 7 | 论文PDF | https://arxiv.org/pdf/1901.11504.pdf |
一、动机
- 学习文本的自然语言理解任务通常可以利用多任务学习和预训练两种途径解决,因此二者的结合可以增强文本理解能力,提出MT-DNN;
- 基于深度学习的多任务学习的优势:(1)Task-specific的标注数据有限,可以借助其他相似的任务的数据实现数据增强、(2)多任务可以作为一种正则化来提升泛化能力;
- 不同于BERT、GPT等模型,MT-DNN可以利用多任务学习和预训练实现文本标注;
二、MT-DNN方法
2.1 模型架构
模型架构如下图所示,low-layer为Share模块,top-layer为Task-specific模块。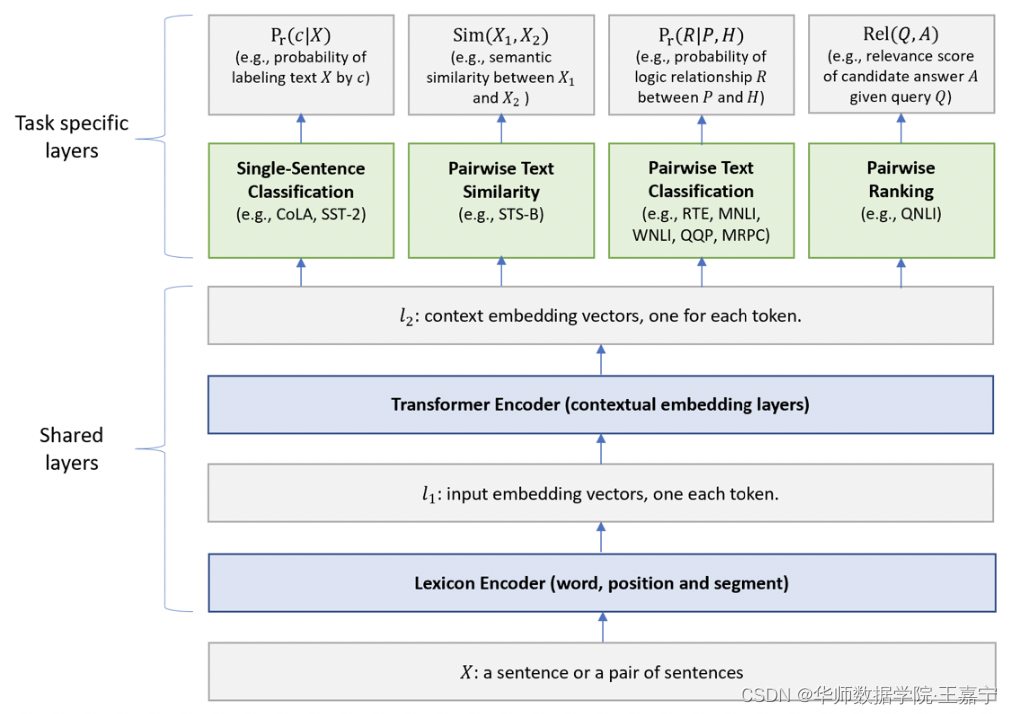
Share部分
- Lexicon Encoder:输入一个句子(一个句子对),遵循BERT的输入,添加[CLS]、[SEP]等标签,并加入word、segment和position representation;
- Transformer Encoder:与BERT一样使用多层Transformer模型;
Task-specific部分
- Single-Sentence Classification:对单一的文本进行分类。[CLS]的embedding喂入线性层+softmax进行分类。任务目标函数为 p r ( c ∣ X ) = s o f t m a x ( W S S T T ⋅ x ) p_r(c|X) = softmax(\mathbf{W}_{SST}^T\cdot \mathbf{x}) pr(c∣X)=softmax(WSSTT⋅x);
- Text Similarity:对两个输入文本计算回归值。[CLS]的embedding喂入线性层计算未归一化的相似度。目标函数为 S i m ( X 1 ∣ X 2 ) = W S T S T ⋅ x Sim(X_1|X_2) = \mathbf{W}_{STS}^T\cdot \mathbf{x} Sim(X1∣X2)=WSTST⋅x;
- Pairwise Text Classification:对输入的两个文本进行分类匹配。完全使用 stochastic answer network (SAN)模型解决文本匹配问题(例如NLI);
- Relevance Ranking:输入一个文本Q,以及若干候选文本A,Q与每个A进行拼接后并计算得分:最后根据所有得分取最大对应的A作为预测结果。目标函数为 R e l ( Q , A ) = g ( W Q N L I T ⋅ x ) Rel(Q, A) = g(\mathbf{W}_{QNLI}^T\cdot \mathbf{x}) Rel(Q,A)=g(WQNLIT⋅x)。
上述四种类型任务的损失函数为:
-
Single-sentence、Pairwise text classification:使用交叉信息熵:
− ∑ c 1 ( X , c ) log ( p r ( c ∣ X ) ) -\sum_c\mathbb{1}(X,c)\log(p_r(c|X)) −c∑1(X,c)log(pr(c∣X)) -
Text similarity:使用均方损失:
( y − S i m ( X 1 , X 2 ) ) 2 (y - Sim(X_1, X_2))^2 (y−Sim(X1,X2))2 -
relevance-to-rank:给定一个positive和若干个negative,目标是最小化positive对应的负对数似然函数:
− ∑ ( Q , A + ) p r ( A + ∣ Q ) - \sum_{(Q, A^+)}p_r(A^+|Q) −(Q,A+)∑pr(A+∣Q)
其中:
2.2 Traning Procedure
MT-DNN属于continual pre-training的方法,其中包括两个步骤:
- pre-training:遵循BERT在MLM和NSP两个任务上进行预训练,得到的参数作为Share部分的初始化;
- multi-task learning:采用SGD进行训练,将9个Task混合起来,并每次喂入一个mini-batch,根据样本所属的Task类型,更新对应的Task-specific部分参数以及Share部分参数。算法如下图:

三、实验
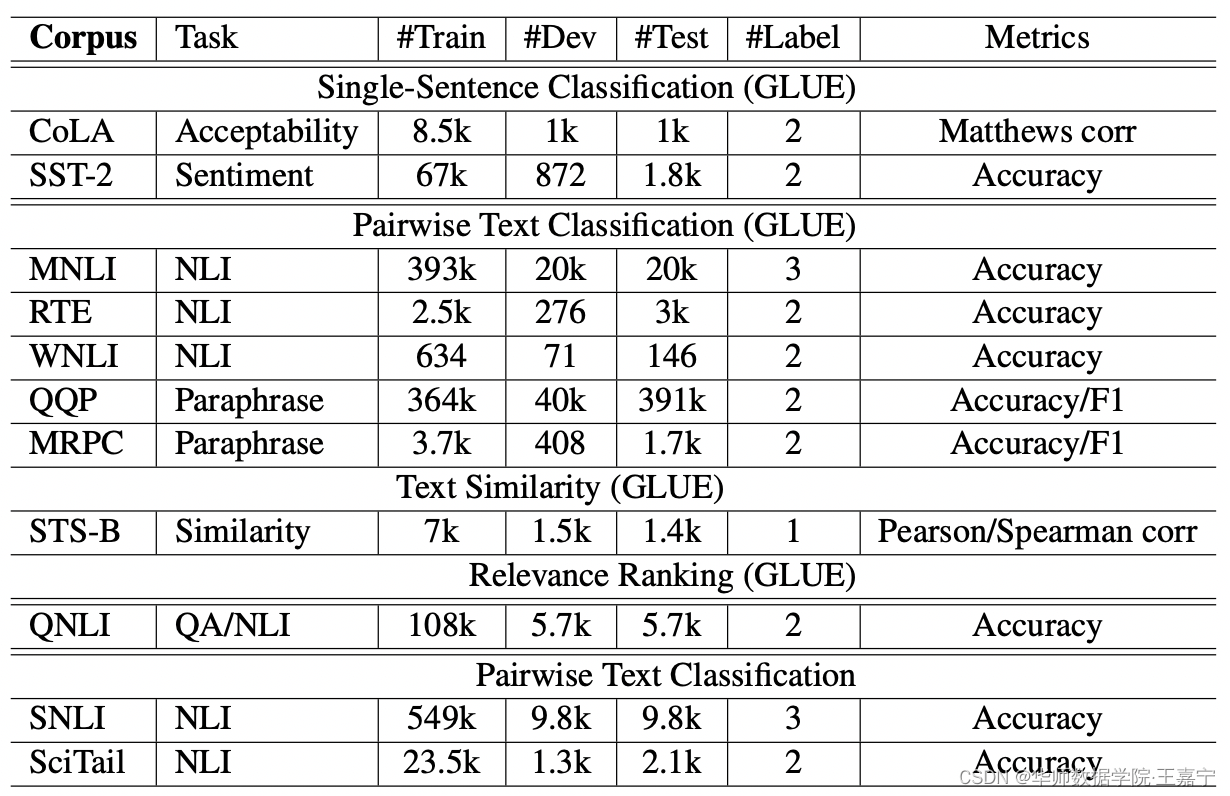
数据集及对应的评测指标
实验设置
使用pytorch版本BERT模型,使用Adamax优化器,学习率为5e-5、batch_size=32、max_len=512。
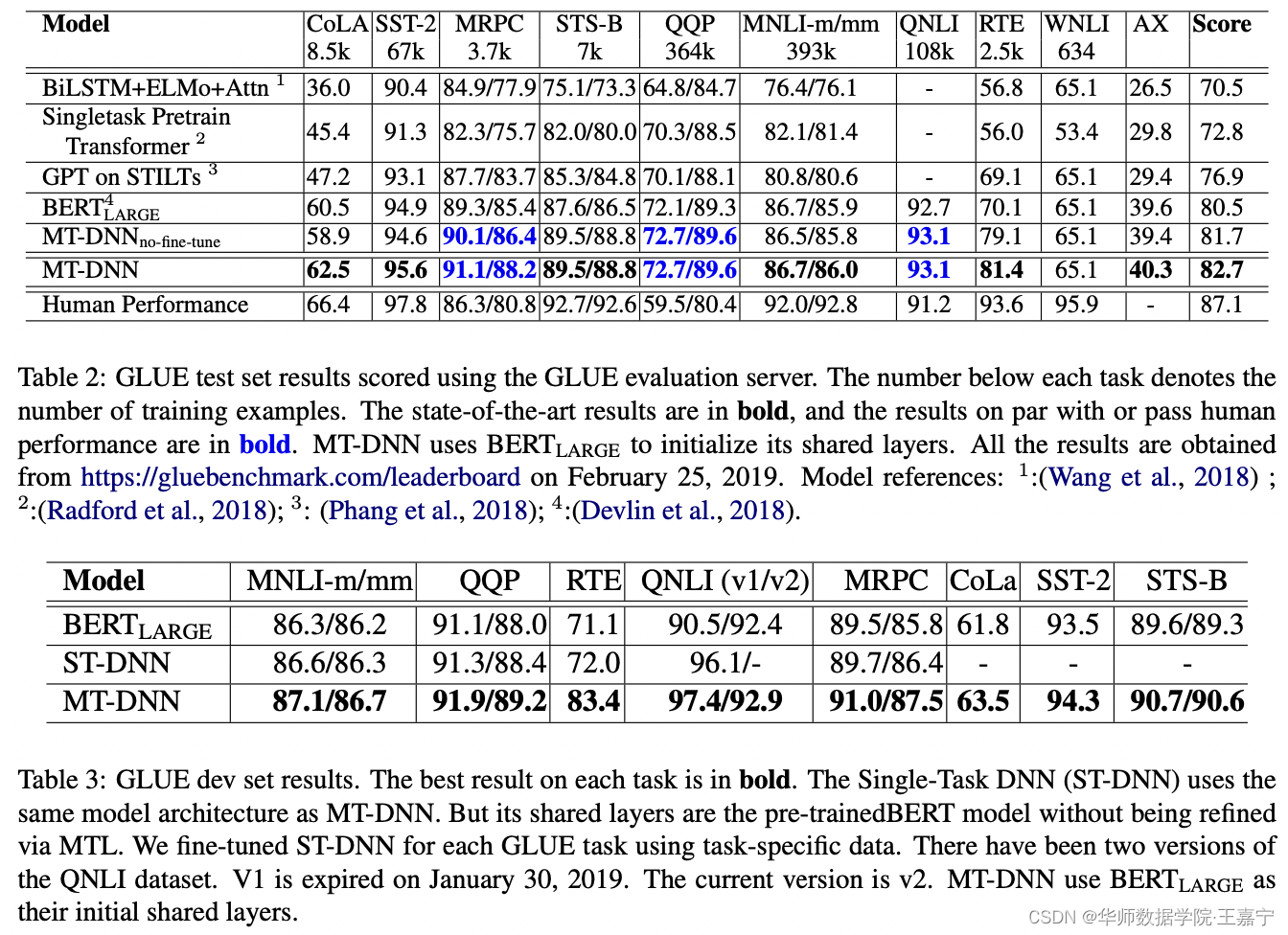
实验结果

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)