大语言模型在法律领域的颠覆性应用探索
大语言模型在法律领域的颠覆性应用探索
通过使用法律大语言模型,我们可以实现案件自动分析与相似案例查找,提高审判效率,同时律师也能借助这些模型更好地理解法律法规,提供更专业的法律服务,从而推动司法系统向更加智能和公平的方向发展。
一、技术背景

大语言模型在法律领域的应用始于对其技术背景的深入理解。首先,语言模型的发展经历了多个阶段,从最初的统计语言模型到神经网络驱动的现代大规模语言模型。
20世纪中叶开始发展的统计语言模型在七八十年代达到了鼎盛,而随着神经网络的发展,尤其是RNN和LSTM等结构的引入,语言模型进入了第二阶段。
2017年前后,Transformer架构的发布成为BERT、GPT等预训练模型的基础,这标志着第三阶段的到来。
2020年前后,OpenAI发布了包含1750亿参数的GPT-3模型,展现出卓越能力,引领进入第四阶段。这一发展历程奠定了大语言模型在法律领域应用的技术基石,使得复杂语义理解和处理成为可能。
二、训练和评估
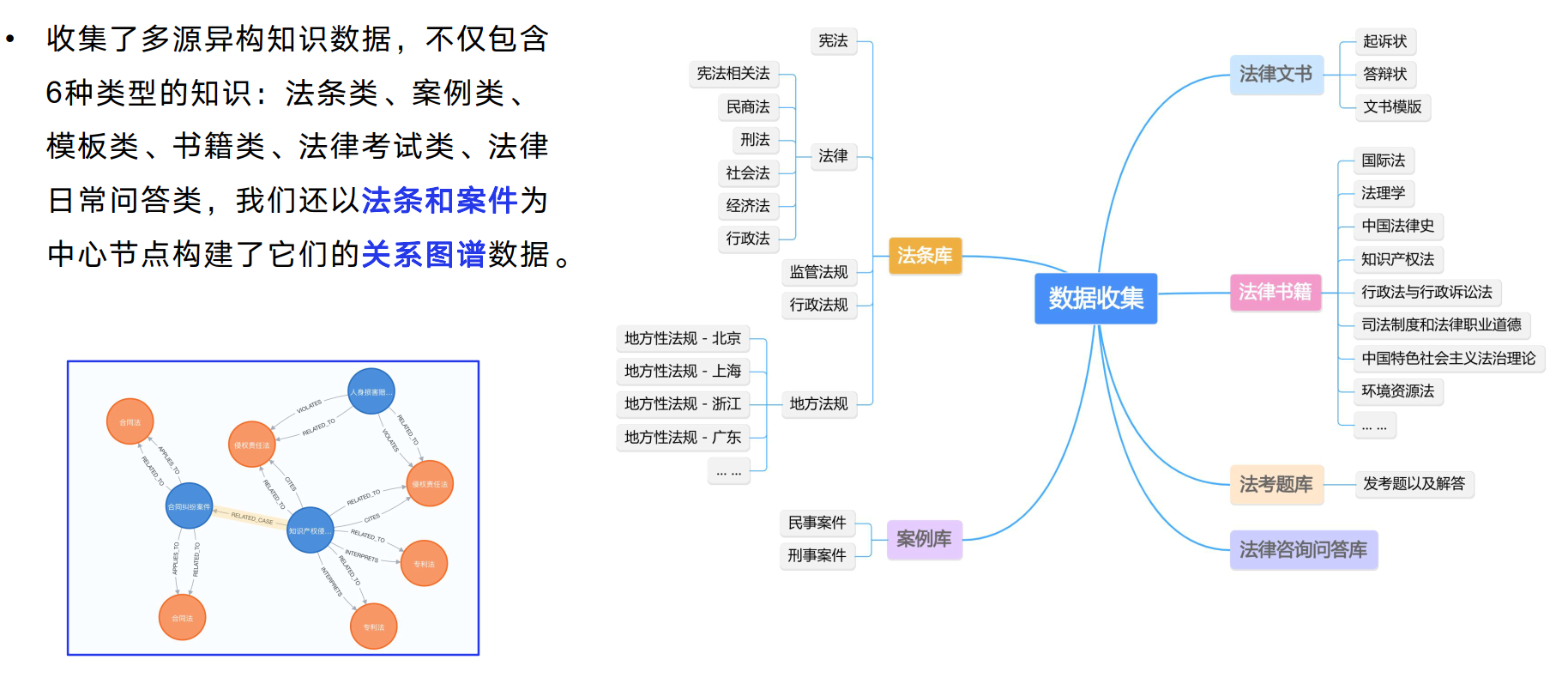
训练和评估是确保法律大语言模型有效性的关键。在训练过程中,需要收集多源异构知识数据,包括法条类、案例类、模板类等六种类型,以法条和案件为中心节点构建关系图谱数据。
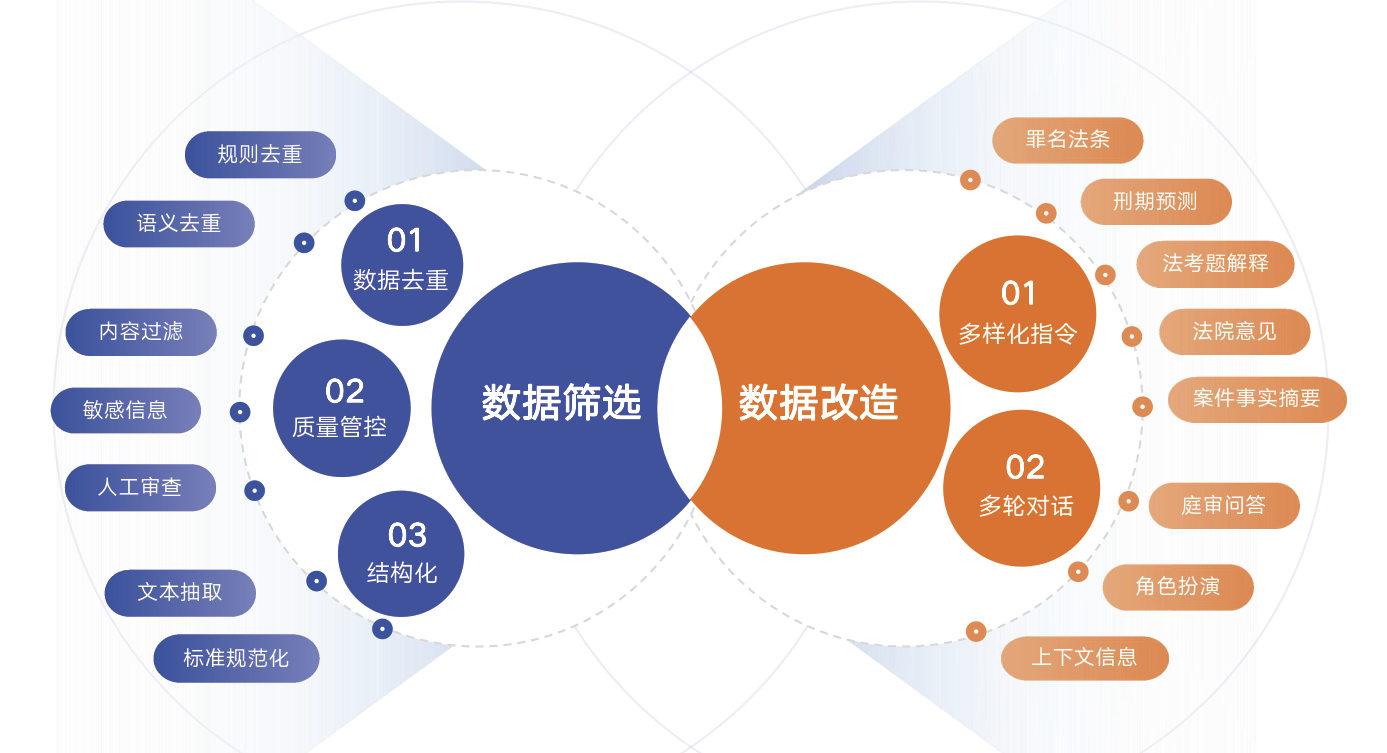
这些数据经过严格的数据清洗,包括规则去重、语义去重和人工审查,以确保质量。在此基础上,通过显卡集群进行微调训练,以合理规划资源提升效率和使得大模型拥有垂直领域的风格。
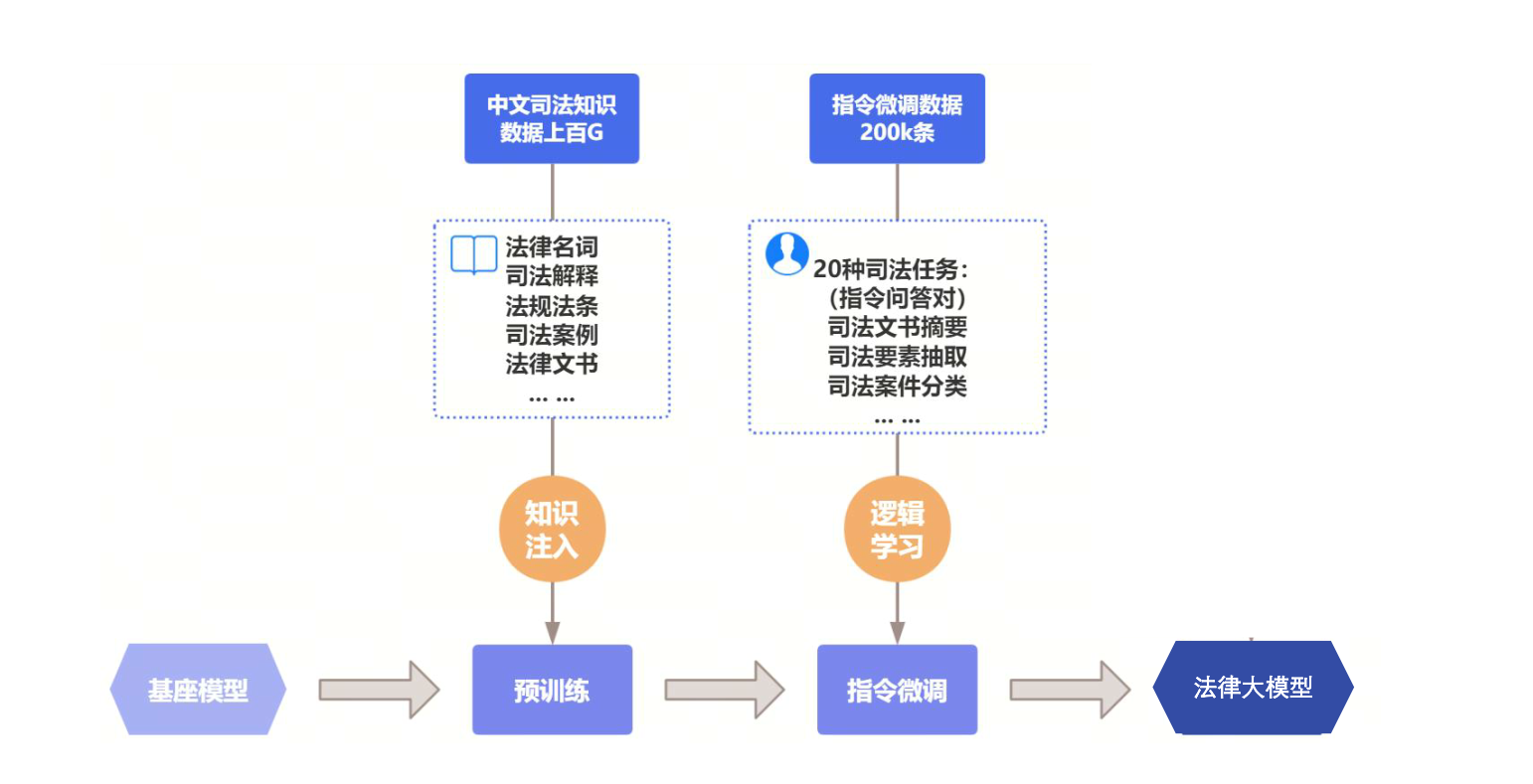
此外,还需进行参数调优,确保获得最佳性能与资源利用效率。
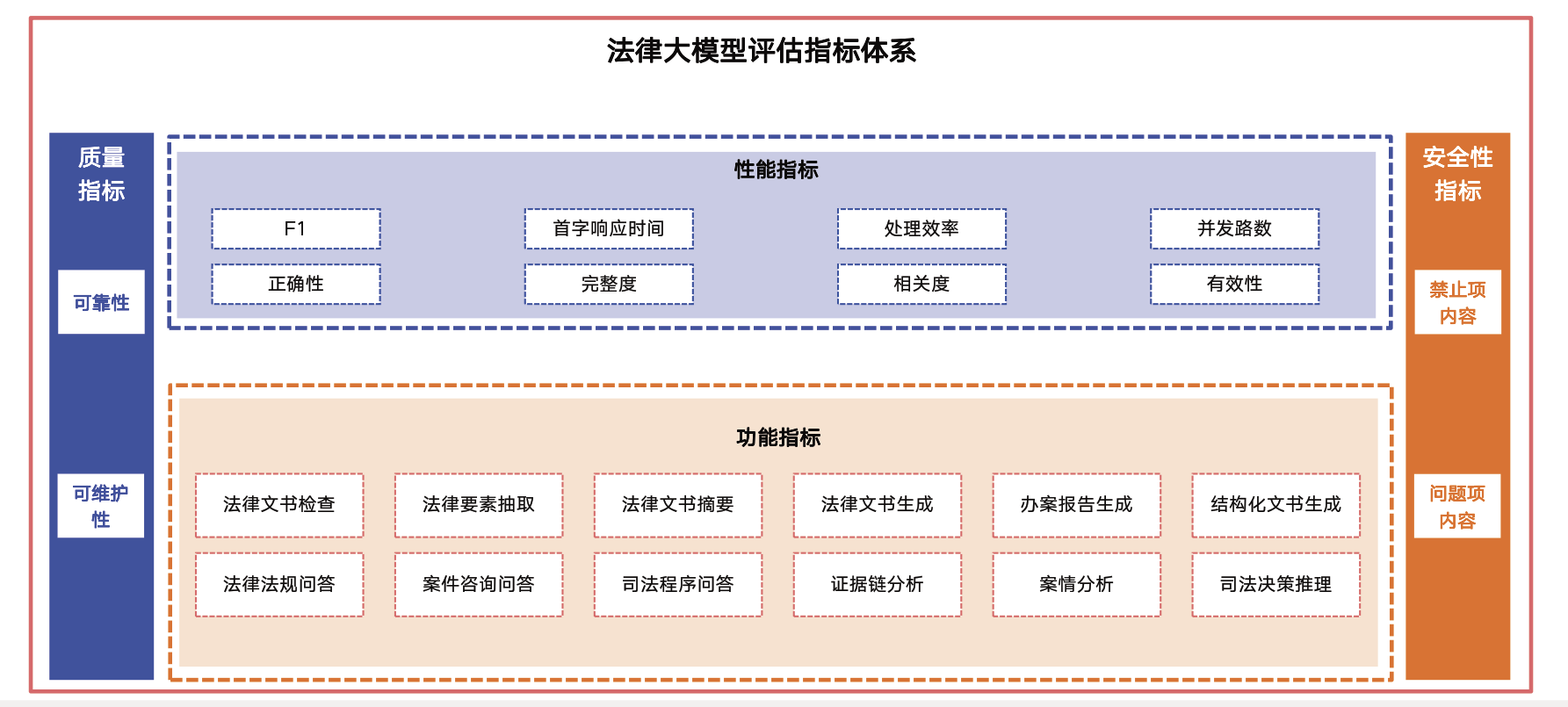
在评估方面,建立了一套完善的指标体系,包括质量指标(如F1正确性)、性能指标(如首字响应时间)以及安全性指标,以全面衡量模型在不同任务中的表现。
通过这样的训练与评估流程,确保法律大语言模型不仅具备强大的语义理解能力,还能在实际应用中保持高效可靠。
三、应用框架
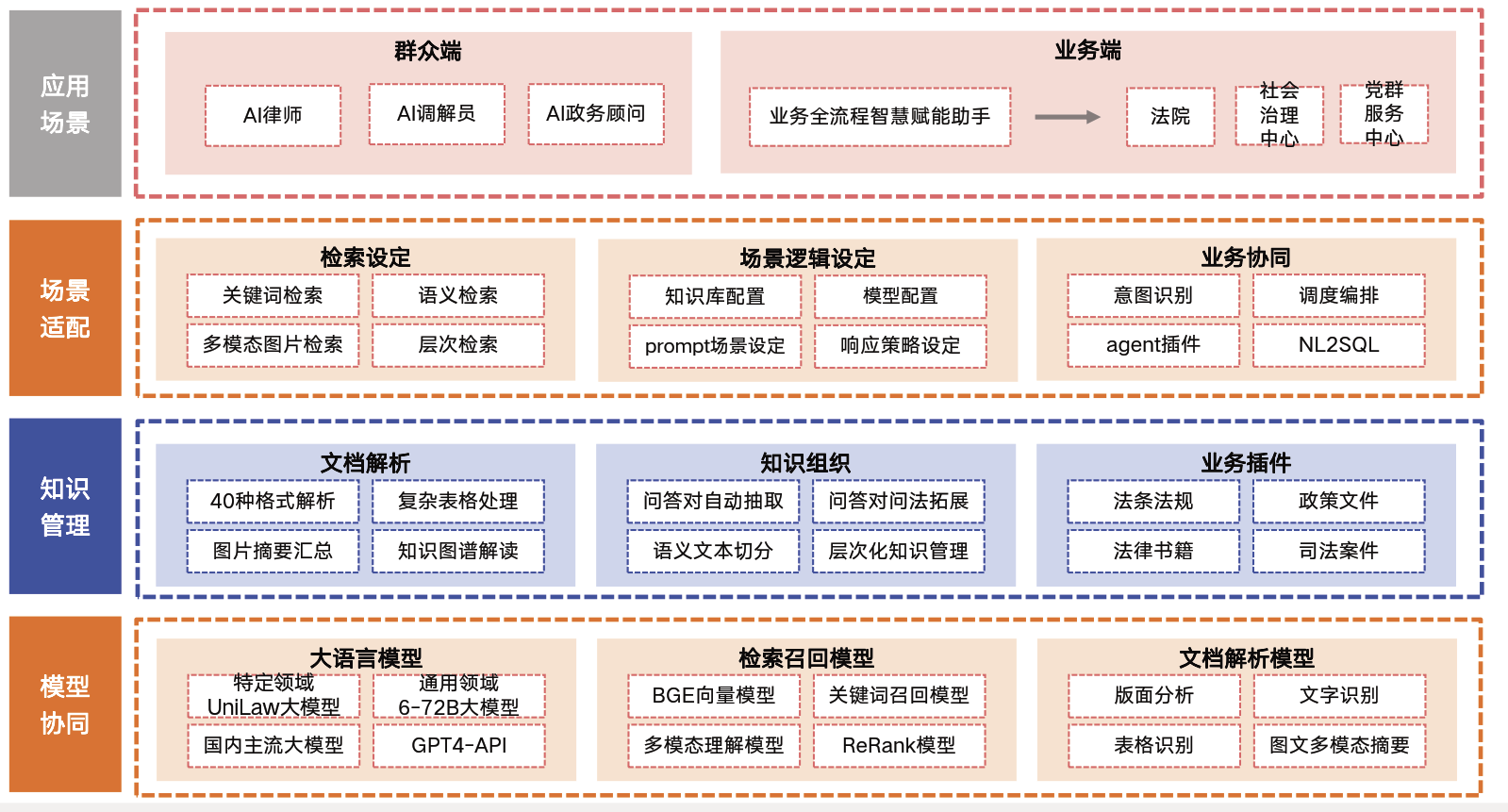
法律大语言模型的应用框架设计旨在实现多场景适配与业务协同。系统架构包括群众端和业务端两大模块,如AI律师、AI调解员等角色,通过意图识别与调度编排实现业务全流程智慧赋能。
在知识管理方面,通过知识库配置与prompt场景设定,实现精准响应策略。此外,还利用检索召回模型,如BGE向量模型和关键词召回模型,加强多模态理解与文档解析能力。
这一框架不仅提升了系统可扩展性与可维护性,也确保用户交互体验流畅智能,为法律服务提供更高效支持。
四、应用案例
实际应用中,大语言模型展现出强大的赋能潜力。例如,在社会治理中,通过数字化赋能提升司法行政效率,实现法治政府建设目标。在智慧审判方面,通过快速生成准确法律文书,提高工作效率。而在案情分析中,则结合知识库进行深度分析,为案件处理提供智能支持。此外,在类案推荐中,大语言模型将过往案例转化为可用工具,为基层工作人员提供参考依据,大幅提升工作处理效率。
比如:华院RAG平台
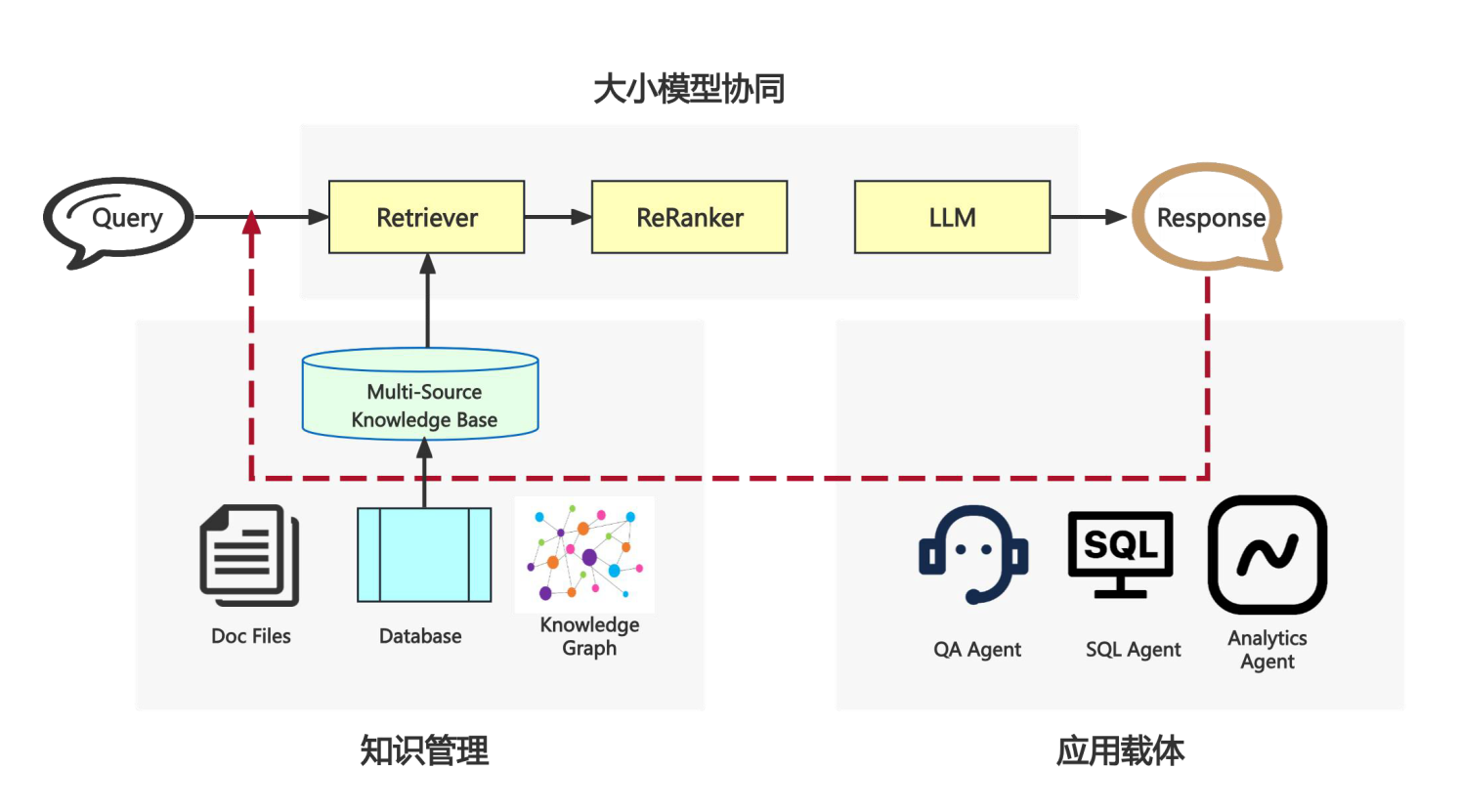
华院RAG平台是一个结合了检索增强生成技术的创新应用平台,主要用于提升大语言模型在特定领域的表现。该平台通过将检索模型与生成模型相结合,提高了生成内容的相关性和质量。华院计算在法律领域应用了这一技术,通过构建本地专有知识融合与性能优化,使得法律大语言模型能够更好地处理案情分析、法条推荐、法律文书生成及法律问答等任务。
比如:判决文书生成
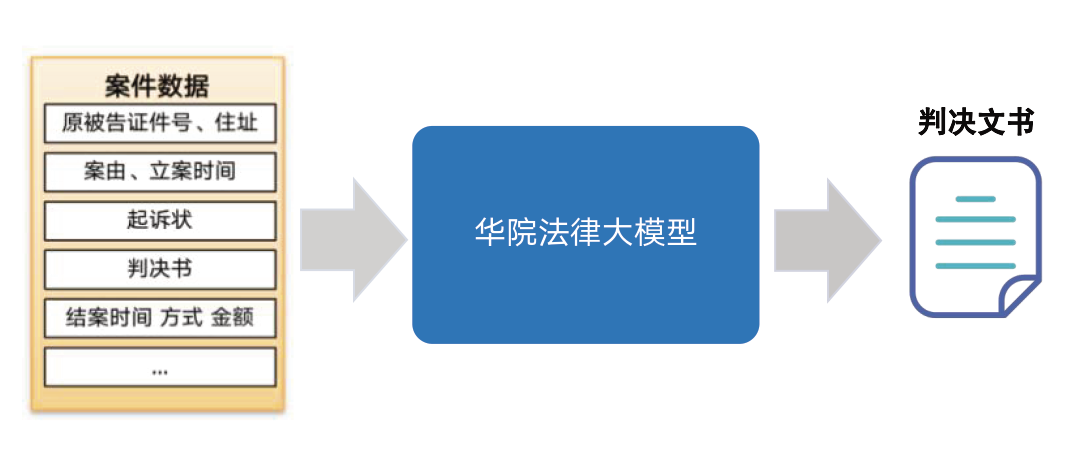
- 背景问题:
法院面临的挑战包括案件数量多、审理周期长,法官在庭审结束后难以及时制作判决书,容易遗漏庭审细节。
- 解决方案:
通过导入起诉状、答辩状、证据证物等材料,利用文本抽取算法理解材料内容,再借助大模型的总结归纳能力,生成判决书。
- 效率提升:
生成的判决书只需小幅修改即可发布为正式文件,这不仅提高了判决书制作的精度,还大幅提升了工作人员的工作效率。
这些具体案例展示出大语言模型在不同法律场景中的广泛适用性,不仅提高了工作效率,也增强了法律服务质量。
五、总结展望
大语言模型在法律领域的应用,确实有着翻天覆地的变化。它们不仅能够快速解答用户的基本法律问题,还能够协助律师进行案例分析、合同起草等工作,显著提升法律服务的效率与准确性。
通过智能化匹配和数据分析,这些模型还能帮助找到更合适的法律资源,甚至预测潜在的风险,使得法律服务更加贴近个体需求。
这种智能化与个性化的结合,有望打破传统法律服务的局限,让正义得以更公平地传播,尤其是在偏远地区,这样的智能法律助手能够填补专业法律服务的空白,让更多人享受到高质量的法律保护。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)