论文分享➲ Improving Reasoning Performance in Large Language Models via Represen | 通过表征工程提升大语言模型的推理性能
通过简单的表征工程,无需训练即可提升LLM的推理性能。
IMPROVING REASONING PERFORMANCE IN LARGE LANGUAGE MODELS VIA REPRESENTATION ENGINEERING
通过表征工程提升大语言模型的推理性能

📖导读:本篇博客有
🦥精读版、🐇速读版及🤔思考三部分;精读版是全文的翻译,篇幅较长;如果你想快速了解论文方法,可以直接阅读速读版部分,它是对文章的通俗解读;思考部分是个人关于论文的一些拙见,欢迎留言指正、探讨。
目录
🦥精读版
Abstrct
近年来,大语言模型(LLMs)取得了显著进展,就大语言模型的推理能力而言,其生成的语言越来越接近人类语言。然而,大语言模型中的推理是否本质上具有特殊性,这一问题引发了广泛的争议。我们提出采用一种表征工程方法,在处理推理任务时,从大语言模型的残差流中读取模型的激活值。这些激活值用于生成一个控制向量,在推理阶段将该控制向量作为一种干预手段应用于模型,调节模型的表征空间,从而提升模型在特定任务上的表现。此外,我们还开源了用于生成控制向量和分析模型表征的代码。该方法使我们能够提高模型在推理基准测试中的性能,并通过诸如 KL 散度和熵等指标来评估控制向量如何影响模型最终的 logit 分布。我们将控制向量应用于 Mistral-7B-Instruct 模型以及一系列 Pythia 模型,用于归纳推理、演绎推理和数学推理任务。研究结果表明,在一定程度上,通过调节激活值可以对大语言模型进行控制,从而提升其在推理方面的表现。这种干预方式依赖于在模型正确解决任务时,能够可靠地提取模型的典型状态的能力。我们的研究结果表明,推理性能可以像大语言模型执行的其他信息处理任务一样进行调节,并且证明了我们能够通过对残差流进行简单的干预来提高模型在特定任务上的性能,而无需进行额外的训练。
1. Introduction
人工智能领域,尤其是大语言模型(LLMs)的研究,近期取得了诸多进展,其中许多进展都聚焦于提升大语言模型解决 推理 任务的能力。然而,推理 这一概念极难确切阐释和定义(Chollet,2019 年;Pavlick,2023 年)。尽管归纳推理、演绎推理和溯因推理等各种形式的推理已有明确的定义,但它们通常指的是高层次的思维过程 —— 往往与系统 2 思维相关联 —— 而不是基本的计算机制(Johnson-Laird,2008 年)。大语言模型规模的不断扩大以及更完善的数据整理,使其在标准基准数据集上取得了更好的成绩,这也促使了对大语言模型所采用的推理策略的研究;但这类研究通常关注的是模型的输出,而非其内部状态(Mondorf 和 Plank,2024 年)。因此,对于与大语言模型解决推理任务能力相关的过程或表征学习动态,我们无法得出确切结论。我们提出对简单 “推理过程” 的典型表征进行建模,并利用这些表征来提升在两项推理任务中的推理性能。
近期的研究表明,通过手动调节模型的内部状态,能够诱导出特定类型的行为。研究人员已经评估了在Transformer架构的多层感知器(MLP)层中编辑 LLM 知识的情况(Meng等人,2023a;2023b),并且绘制出了模型内部的完整计算回路(Wang等人,2022)。更有趣的是,有研究显示我们无需研究特定的 MLP 或注意力层,而是可以关注大语言模型的残差流。通过以一种有意义的方式调节残差流,就有可能诱导出不同类型的“行为”特征,比如诚实性、真实性和情感效价。这些类型的行为可以被视为大语言模型表征空间中的不同方向(Liu等人,2023;Hendel等人,2023;Todd等人,2024)。此外,调节残差流的方法还被用于提升经过训练以玩国际象棋和黑白棋等棋盘游戏的Transformer模型的能力(Karvonen,2024;Nanda等人,2023)。Anthropic公司在其 Golden Gate Claude 模型中也采用了类似的方法,他们引导大语言模型模拟金门大桥的“行为”(Templeton等人,2024)。上述研究凸显了这种方法的有效性以及广泛的潜在应用。
作为一项新颖的贡献,我们直接采用表征工程方法来分析提升推理能力的可能性。具体而言,我们要评估大语言模型的残差流是否包含与模型推理能力相关的有价值(且可利用)的信息,以及这些信息能否像相关研究在其他类型行为中所表明的那样,用于提升模型的推理能力。具体来说,我们从大语言模型的隐藏层维度中提取激活值,基于这些激活值创建一个控制向量 (control vector),并评估在推理阶段进行干预是否能够提升模型在我们所分析的特定任务集合上以及跨任务的推理能力。
因此,本文的主要贡献在于分析对残差流进行扰动的有效性,以此来提升模型在一系列与推理相关任务上的表现。具体而言,我们要探究这种方法是否能够在大语言模型的表征空间中找到与推理相关的方向,以及这种干预方式会如何影响模型的表征空间。
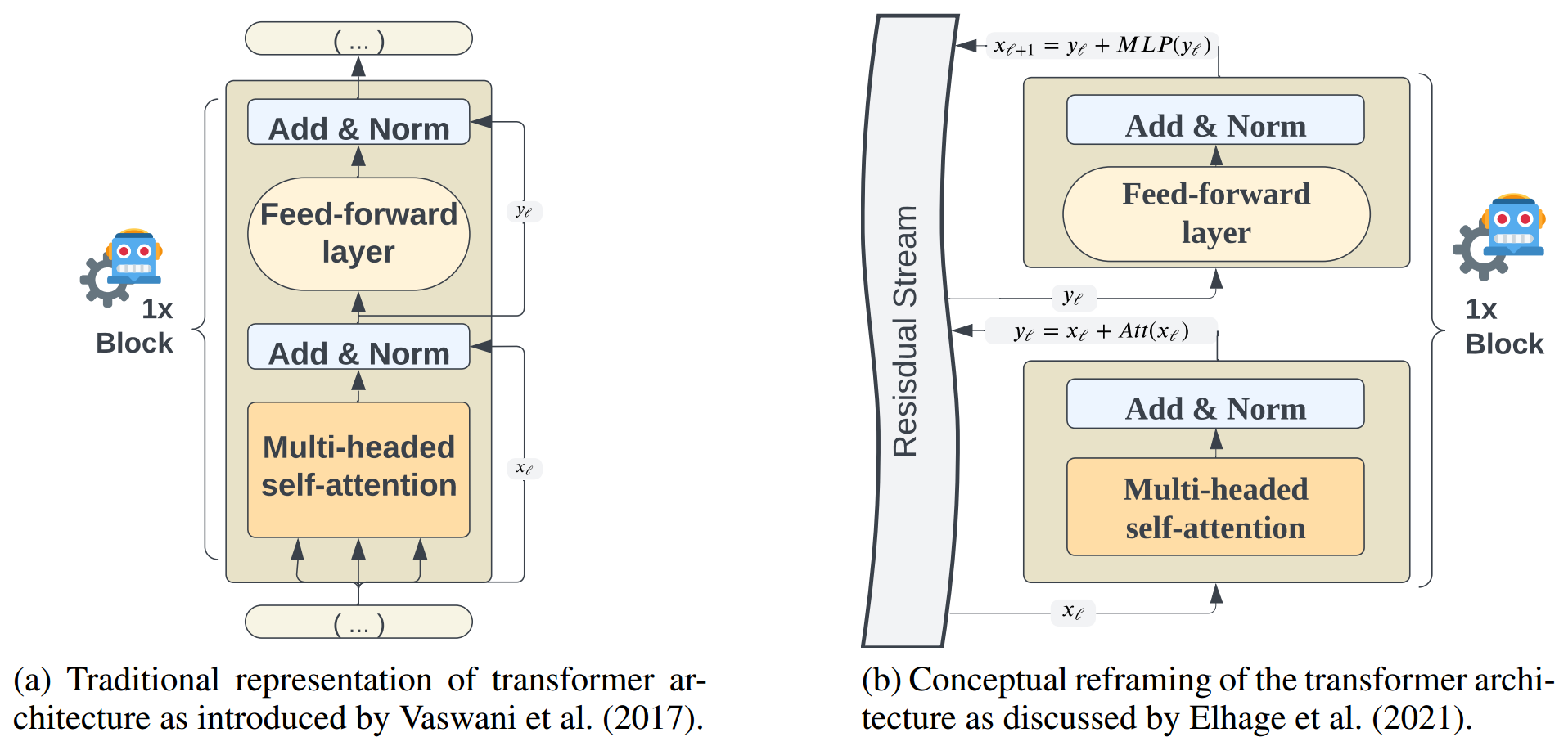
2. 方法
我们采用一种表征工程方法,在执行特定推理任务时,基于模型的典型表征来推导控制向量。这使我们能够评估是否可以像调整模型输出的情感效价等方面(Zou 等人,2023 年)那样,促使模型展现出更好的推理性能。
在大多数大语言模型中,Transformer 架构包含一个嵌入层,随后是 n n n 个计算模块,最后是一个词元 logits 输出层,通过对这些 logits 应用 softmax 函数来生成新的词元(Vaswani 等人,2017 年)。根据 Elhage 等人(2021 年)的观点以及近期的相关研究(Templeton 等人,2024 年),我们强调残差流是 Transformer 架构的关键组成部分,并着重指出 Transformer 的基本操作是表征变换。这种概念上的重新阐释如图 1 所示。在任何给定的 Transformer 架构中,单个层所执行的操作可以用公式 1 来描述,但不包含 c ℓ + α \mathbf{c}_{\ell} + \alpha cℓ+α这一项。

x ℓ x_{\ell} xℓ 是第 ℓ \ell ℓ 层的隐藏维度激活向量, y ℓ \mathbf{y}_{\ell} yℓ 是经过缩放点积注意力机制后的激活值, x ℓ + 1 \mathbf{x}_{\ell + 1} xℓ+1 是经过多层感知机(MLP)变换后的激活值。近期的研究已经说明了分析和操作残差流的有效性,例如使用稀疏自编码器从残差流激活值中提取特征(Huben 等人,2023),这有力地表明,部分由于多义性问题,残差流是一个比单个神经元(或神经元群组)更好的分析层次。针对残差流的操作也被提议作为解决跨层叠加问题的一种方案:跨层叠加是指特征在深度神经网络的许多隐藏层中扩散的概念(Bricken 等人,2023;Templeton 等人,2024)。我们在任务示例的最后一个词元之后提取每层的表征。从这些提取的激活值中,我们推导出特定于层的控制向量。应用控制向量就是将 c ℓ ⋅ α \mathbf{c}_{\ell} \cdot \alpha cℓ⋅α 项简单地添加到标准的 Transformer 操作中,如公式 1 所示。
2.1 控制向量
基于提取的模型激活值,可以通过多种方式训练控制向量。最简单的方法是创建一个读取向量(reading vector),它仅仅是对提取的激活值求平均。给定一组提示词 P P P,一个具有 L L L层的模型,以及 H ℓ ( P i ) H_{\ell}(P_{i}) Hℓ(Pi)表示第 ℓ \ell ℓ层和第 i i i个提示词的残差流隐藏状态,读取向量描述如下:

相关研究表明,若要从 LLM 中提取出期望的行为,最好使用对比对。对比对意味着要考察针对正向提示词和负向提示词的表征。例如,在情感效价方面,它可能涉及 “快乐” 相关提示词的示例以及 “悲伤” 相关提示词的示例。在推理方面,我们会查看成功推理和失败推理的示例——详见3.1小节。这确保了控制向量是基于表征差异构建的(Zou等人,2023)。因此,控制向量可以进行缩放,以引发期望的行为或其相反行为。给定一组正向和负向提示词的对比对 P ± = ( P + , P − ) P^{\pm} = (P^{+}, P^{-}) P±=(P+,P−),我们将控制向量定义为:

另一种训练控制向量的方法是对对比激活值应用主成分分析(PCA)(Zou等人,2023年)。主成分分析可找出数据中能解释最大方差的方向,其中第一主成分表示数据中解释方差最大的方向(direction)。其背后的逻辑是,这些对比表征之间的差异会对激活值的方差产生显著影响,因此第一主成分应能大致逼近激活空间中最能有效区分期望结果与其对比情况的方向。这个方向随后便可作为控制向量。与使用对比对的读取向量类似,PCA 控制向量的定义方式如下。

一个关键的考量因素是希望对表征进行多大程度的调节(由 α \alpha α控制),因为过强的调节可能会导致无意义的输出。在创建读取型控制向量时, α = 1 \alpha = 1 α=1相当于向信号中添加一个 “完整的(full)” 激活向量,因为从公式2可知 ∥ c ℓ ∥ ≃ ∥ H ℓ ∥ \left\lVert \mathbf{c}_{\ell}\right\rVert \simeq \left\lVert H_{\ell}\right\rVert ∥cℓ∥≃∥Hℓ∥ 。然而,应用 PCA 时,我们得到 ∥ c ℓ ∥ = 1 \left\lVert \mathbf{c}_{\ell}\right\rVert = 1 ∥cℓ∥=1 。为了应对这种差异,我们对基于PCA的控制向量进行放大,放大倍数取决于所提取的残差流激活值的实际范数(见附录A.1)。
因此,控制向量的推导是一个相对简单的过程,不会带来很大的计算开销。我们只需在对给定任务进行推理时提取激活值,就能在无需进一步训练的情况下,对 LLMs 的输出进行控制和优化。
3. 评估 & 分析
3.1 实验
对于 IOI,我们针对以下形式的每种情况创建2000个示例:

此任务属于归纳型,因为可能有多个正确答案。不过,我们关注的是控制模型生成一个期望的名字,并将其视为一个归纳推理问题。我们研究四种不同的情况:ABBA(A)、BABA(B)、ABBA - Long(AL)和 BABA - Long(BL)。
bAbI包含多种推理任务,其中一种与演绎推理相关,这类任务有2000个示例。问题格式如下:

GSM8K包含高质量的小学数学问题,即使是能力相对较强的大语言模型在这些问题上也会遇到困难。问题格式如下:

我们在附录A.3中提供了GSM8K数据集中一个问题的完整详细示例。对于GSM8K,我们总共使用400个提示词来推导控制向量。对于每个数据集,我们进行训练集/测试集划分,对标签进行分层,并根据模型在训练集示例上生成输出时的表示来推导控制向量,然后在测试集上应用控制向量来测试模型性能。
为了生成对比对,我们需要正向和负向提示示例。对于正向示例,一种显而易见的方法是选择模型成功解决任务的所有情况,同时确保类别标签均衡,以保证模型不会偏向某个特定答案。然而,用于体现推理失败的提示就没那么明确了。我们提出了多种引出典型 不良推理(poor reasoning) 表征的方案。1) 一种简单的方法是要求模型给出错误答案。但在测试中发现,这是一种不佳的方案,因为按要求给出错误答案可能也被视为一种合理的 推理。2)选取模型答错问题的示例。不过,这种方法也存在缺陷。在某些情况下,答案实际上并非错误,只是并非我们预想的正确标记。例如在IOI任务中,“Mary[A] and John[B] went to the store. John[B] gave the groceries to Carl[C] .” Carl 这个答案不一定是错的,只是不是我们预期的标记。3)第三种方案是直接创建由75个从A到z随机采样的字符串组成的负向提示。虽然这种方案没有引入自然的对比,但它在模型表征方面提供了 “一个参考点”,并且从经验上看,比仅使用读取向量 效果更好。在后续实验中,我们对方案 2)和方案 3)进行了测试。
我们开展了多项实验,在不同的 α \alpha α 尺度下,将干预应用于各种大语言模型中层的残差流,并评估这对三个数据集上的性能有何影响。在推导控制向量时,我们会为每一层得到一个控制向量,不过先前的研究表明,仅将这些向量应用于中间层就足以对模型输出产生显著改变(Templeton 等人,2024年)。一般来说,我们以 0.1 0.1 0.1 的增量评估 α ∈ [ − 1 , 1 ] \alpha \in [-1, 1] α∈[−1,1] 范围内干预的影响,但对于 Mistral - 7B - Instruct 模型,我们考察的范围是 [ − 3 , 3 ] [-3, 3] [−3,3]。
3.2 评估指标
我们通过研究一组受限的潜在响应的输出 logits 来衡量性能。潜在响应是数据集中所有答案的集合,这与 lm - eval 框架中的做法类似(Sutawika等人,2024)。我们不使用完全匹配指标,因为在小语言模型的零样本提示场景中,该指标特别容易出错,在这种场景下,模型不知道输出的期望结构。这就导致模型生成的冗长、平淡的语言,尽管提供了正确答案,也可能被标记为不准确。这个问题在少样本提示中不太明显。
因此,我们在提取激活值时使用任务的少样本示例,部分原因是为了缓解上述问题,但更重要的是因为大语言模型已被证明是上下文学习者(Brown等人,2020)。此外,当改进模型的方法直接源自其自身隐藏状态时,我们不能指望能够在模型无法充分解决的任务上提升它。对于GSM8K任务,模型会生成带有推理过程的完整响应,我们使用解码方案来提取最终答案。
除了对模型输出进行基准测试,我们还旨在了解应用控制向量时分布的变化情况。我们通过检查所得分布的汇总统计信息并将其与原始模型进行比较来分析这一点。我们特别关注在不同 α α α水平下应用和未应用干预的模型之间,logits 分布的 Kullback-Leibler(KL)散度,它为分布变化幅度提供了一个度量:

其中 P P P是原始 logits 分布, P α P_{\alpha} Pα是经过修改的 logits 分布。此外,我们还将模型熵视作 α \alpha α的函数进行研究,以此揭示随着 α \alpha α增大,模型的置信度是提高还是降低:

最后,我们评估正确答案与错误答案的平均概率随 α \alpha α的变化情况。这样做是为了评估干预具体如何影响词元概率分布。

其中, N N N是样本数量, y ^ \hat{y} y^是对输入 x i x_i xi的预测答案,并且 y ^ \hat{y} y^被限定在潜在答案列表中。
这些指标能让我们深入了解控制向量干预对模型状态的影响。如果某一程度的控制导致KL散度出现不成比例的激增,这可能意味着达到了某个阈值,使模型完全脱离其通常状态。我们预计随着 α \alpha α的增加,KL散度会有一定程度的线性增长。熵表示概率分布中包含的不确定性;我们预期,如果控制向量提高了任务准确率,那么随着概率质量集中在正确答案词元上,熵应该会下降。最后,评估集中在正确词元上的概率质量,能具体告诉我们(在众多样本中)是否总体上提高了正确解决任务的能力。
如果我们观察到随着准确率的提高,熵降低且正确词元的概率增加,这表明控制向量干预按预期发挥了作用。然而,如果这些指标不一致,例如我们观察到熵降低但准确率没有提高,这可能表明我们正在以意想不到的方式影响模型。
我们不训练任何模型,而是基于模型的隐藏状态提取控制向量。我们在测试集上评估应用干预后的模型性能,并根据训练集的激活值推导控制向量。我们这样做是为了避免数据污染,尽管我们无法确定所使用模型的训练数据没有受到间接污染。
3.3 模型
我们使用由EleutherAI开发的Pythia系列模型(Biderman等人,2023年)。具体研究两个模型,即Pythia - 1.4B和Pythia - 2.8B。基于初步的基准测试研究,我们选择分析这两个模型,并且这个参数范围使我们能够在不同规模上分析表征工程方法的有效性。此外,我们在Mistral - 7b - Instruct模型上测试该方法,以便将其扩展应用到更大且性能更强的模型,并评估控制向量对经过指令微调模型的影响。
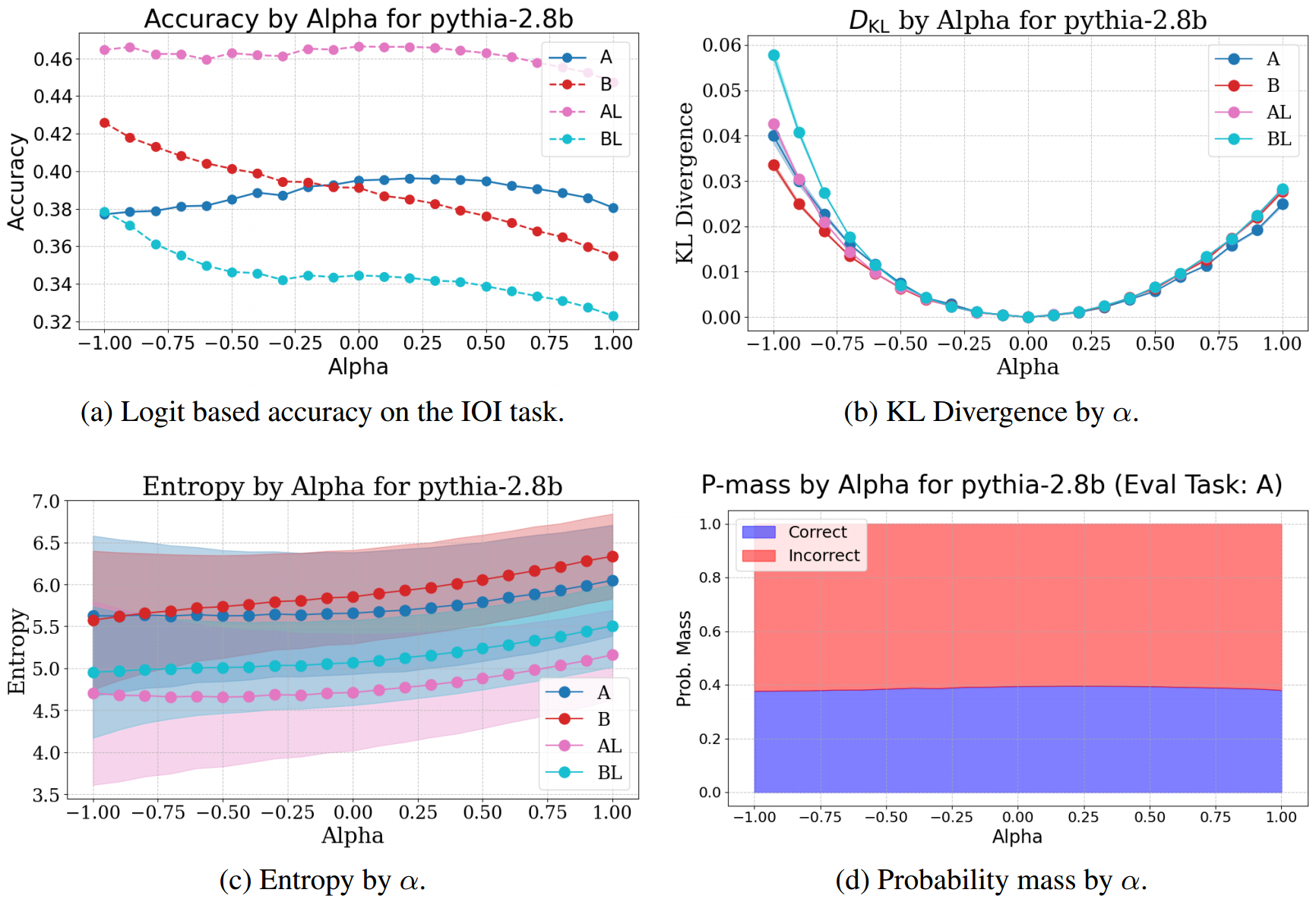
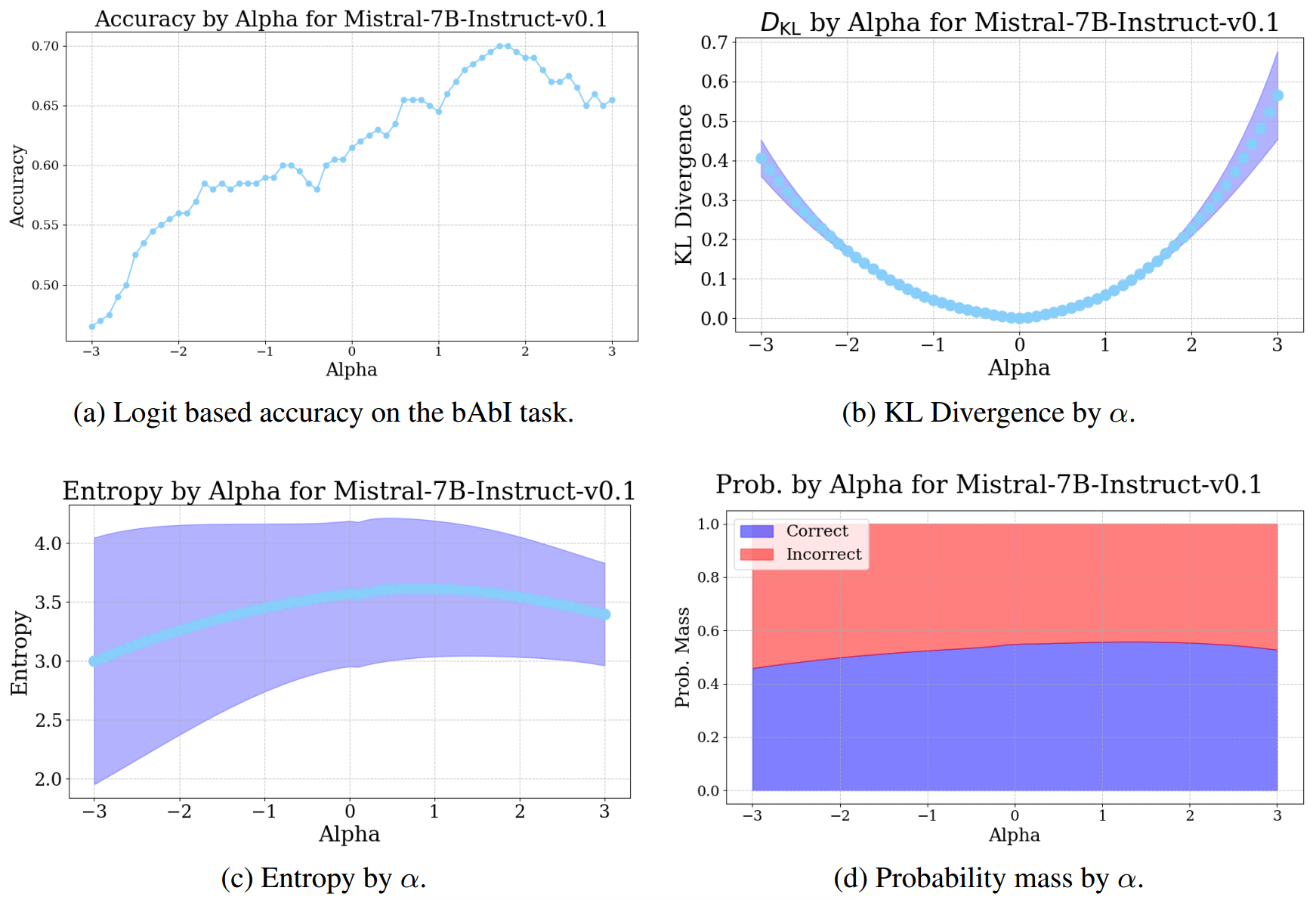
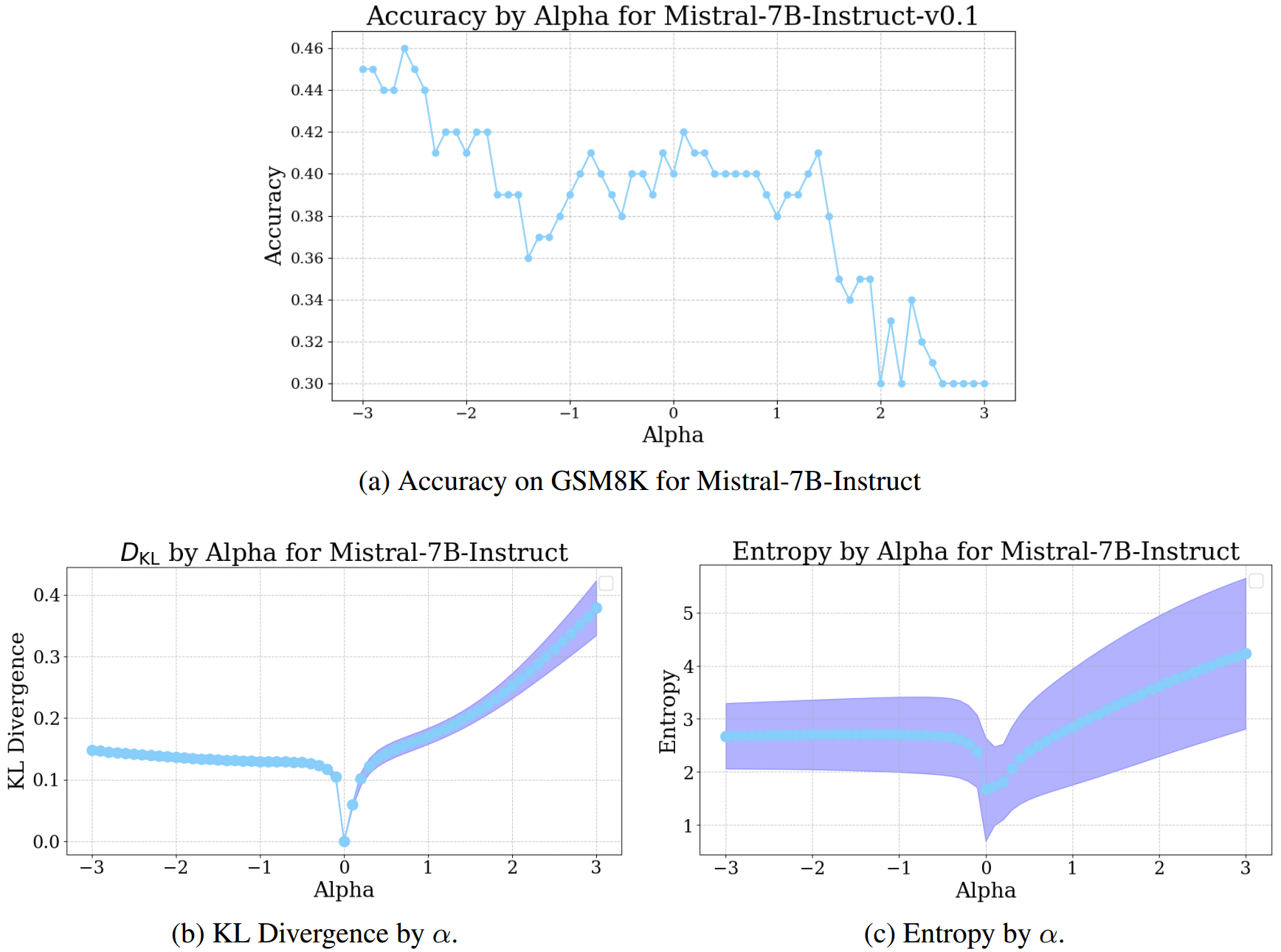
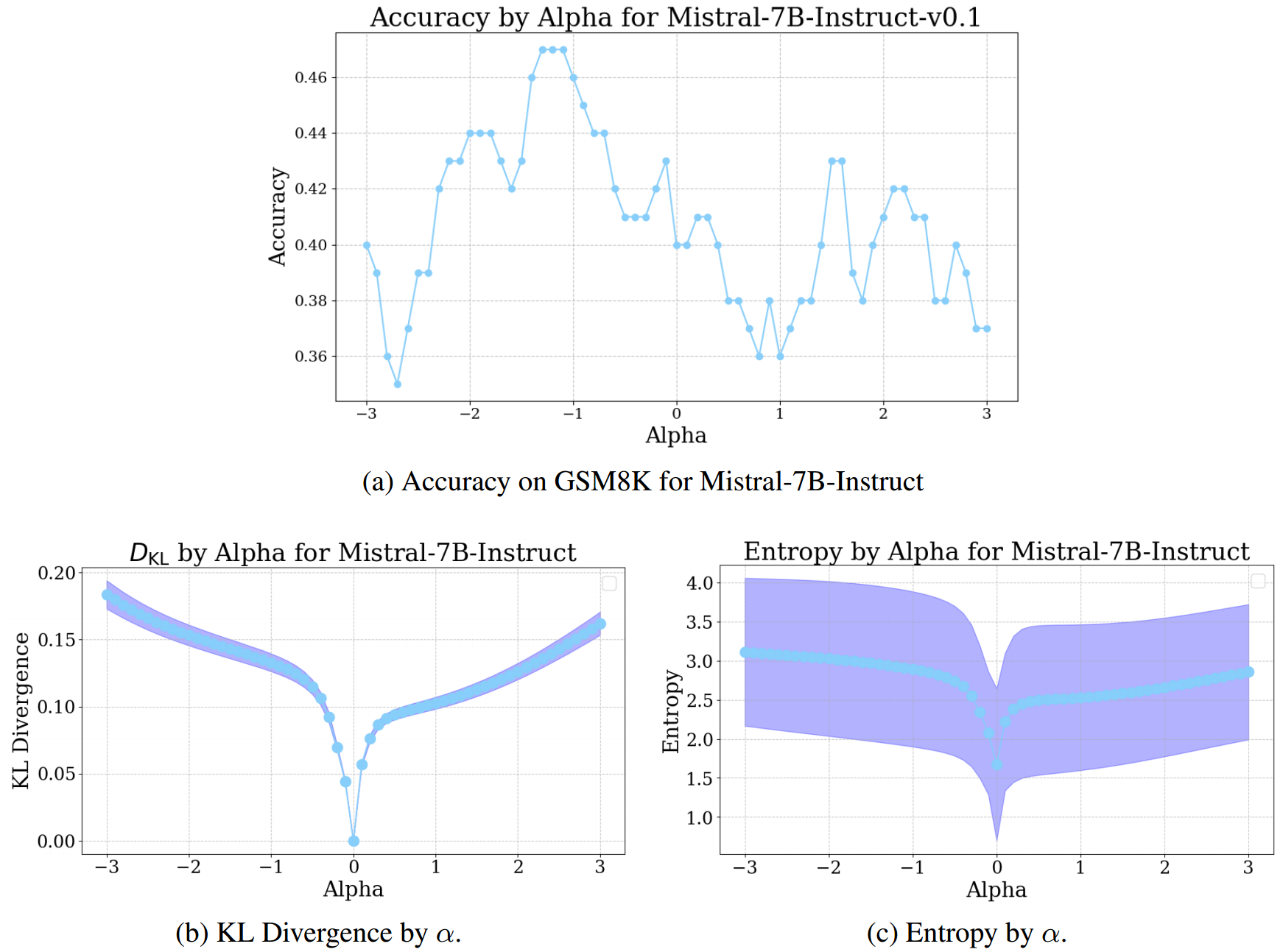

3.4 结果
在本节中,我们报告应用基于 PCA 推导的控制向量后,Pythia - 1.4B、Pythia - 2.8B 和Mistral - 7B - Instruct 模型的结果。总体而言,我们观察到各个模型和任务的性能都有所提升,尽管在 α α α 的最优值以及控制向量是进行正向缩放还是负向缩放方面存在差异。
PYTHIA
我们基于从A条件中提取的信号训练控制向量,并将其应用于所有实验条件。如图9a和2a所示,我们观察到Pythia - 1.4B和Pythia - 2.8B在不同任务上都有轻微的泛化能力提升,Pythia - 1.4B的结果见附录A.4。当在不同条件下应用控制向量时,Pythia - 2.8B的准确率略有提高, α α α 存在一定变化,并且随着 α α α 向正负两个方向增大,KL散度呈二次方增长,见图2b。该干预措施在B和BL条件下最为有效,这表明控制向量对要生成的间接宾语的位置敏感信息进行了编码。熵分析结果也证实了这些发现,即随着准确率提高,熵略有下降。然而,我们观察到随着熵下降,KL散度增加。此外,如图2d所示,随着 α α α 增加,平均概率质量在正确答案周围略有累积,尽管正确词元上的平均概率变化很小。由于Pythia模型无法充分解决bAbI或GSM8K任务,我们仅报告其在IOI任务上的结果。
MISTRAL
在bAbI任务上,Mistral模型的结果与Pythia - 2.8B类似,见图3。基于 logits 的准确率有所提高,且KL散度呈二次方增长。然而,我们观察到熵有轻微上升趋势,这与我们预期中干预成功提高模型准确率时对最终 logits 分布的影响相悖。由于相对于该模型的性能,IOI任务过于简单,我们仅在bAbI数据集上评估其性能。
我们还发现,控制向量干预能够提高GSM8K任务的性能;如图4所示,通过负的 α α α 值,该方法成功提升了模型解决任务的能力。虽然模型表征对干预的鲁棒性不是很强(基于锯齿状的趋势线判断),但我们确实发现干预是有效的。对于GSM8K任务,KL散度和熵的度量看起来差异较大,不过这些指标之间似乎存在正相关关系。
最后,我们评估从bAbI任务推导的控制向量如何影响GSM8K评估的性能,反之亦然。在图5中,我们报告了该实验的结果。我们发现,当应用bAbI控制向量时,GSM8K测试集上的准确率几乎有相同程度的提升,并且在KL散度和熵的图表中也看到了类似的趋势。我们还发现,GSM8K控制向量能提高bAbI任务的性能,详见附录A.5。这表明,我们从中推导控制向量的表征,捕捉到了模型在解决推理基准任务时所执行的信息处理的某些方面。
我们还分析了,针对特定模型和任务应用最优 α α α 值的干预时,模型响应会如何变化。图6中给出两个示例,展示了Mistral - 7B - Instruct在应用控制向量(与未应用时相比)时,如何生成不同的推理过程,从而得出正确答案(另见附录A.3中图8的错误示例)。更普遍地,我们观察到不同规模的模型受不同 α α α 水平的影响各异。这究竟是因为较大规模的模型对其表征变化更具鲁棒性,还是仅仅因为仅修改中间层表征对于较大模型而言影响较小,仍是一个有待探讨的问题。
总之,我们发现控制向量能够成功用于修改 LLMs 的表征,以提高所有模型在特定任务上的性能,尽管提升程度有所不同。干预措施在像GSM8K这样复杂的任务中也能发挥作用,这一发现尤其令人鼓舞,而它在不同任务间都能生效的结果更是如此。定性示例表明,应用干预措施能够保留模型生成连贯文本的能力,且并非仅仅诱导生成特定的词元子集,这对于该干预措施在专注于提高基准数据集性能的研究之外的实际应用而言,是一个重要成果。
4. 讨论
在本文中,我们通过将 LLMs 解决推理任务的能力建模为模型残差流中的一个方向,来研究这种能力。从根本上说,训练控制向量依赖于大语言模型所学得的表征,以及以一种能保留模型生成语义有意义文本能力的方式修改这些表征的能力。类似的方法已被用于在保持语义连贯性的同时修改模型输出的 “情感倾向(sentiment)” 。这项研究尤其专注于有效地引发积极和消极情绪,实际上相当于在提示前加上 “Pretend you are feeling [X]” 来创建控制向量(Liu等人,2023;Hendel等人,2023)。我们同样表明,我们能够调节大语言模型的表征空间,以在简单任务上提升性能,同时保持模型生成连贯文本的基本能力。这一发现暗示,大语言模型在推理任务上表现良好的 “能力”,其编码方式与其他模型状态类似,比如生成语义上积极或消极的输出。鉴于先前的文献,我们能够通过残差流修改大语言模型的输出,这本身并非一个惊人的发现;本文的主要贡献在于,我们可以通过将模型推向特定状态,来提升其在不同复杂程度推理任务上的表现。
4.1 意义
尽管关于大语言模型中的推理仍有许多问题有待解答,并且对于我们的发现和实验也存在许多悬而未决的问题,但它们表明,推理性能的调节方式可以与我们调节生成文本的情感效价或模型下象棋的能力类似。过去几年的发展令人印象深刻,在某些方面颠覆了该领域内我们对于仅在文本数据上训练的机器学习模型能力的认知。当前的模型架构是否能够实现类似人类系统思维的任何功能,似乎不太可能,尽管人们正在进行大量工作以使大语言模型 “正确地(properly)” 推理(例如,可参见OpenAI的最新模型(OpenAI,2024)),但这些方法中的任何一种是否等同于传统意义上的推理仍有待商榷,尤其是正如我们所提及的,推理是一个很难确切定义和阐释的术语。
4.2 推理
虽然我们承认围绕推理本质存在深刻的哲学问题,但我们的工作有意采用了一种狭义的实证方法。我们研究对模型表征的特定操纵是否能提升在需要类似推理行为的任务上的表现,而不对推理本身的本质做出强硬断言。我们并不试图定义推理。相反,我们感兴趣的是使用那些被认可并归类为与 “推理” 相关的任务,无论是归纳、演绎、数学推理,或者理论上的其他任何类型。这些任务在提示长度以及正确解决方案的表面程度上有所不同(即解决方案是否需要通过中间步骤或计算进行推理)。在IOI任务中,答案存在于文本中,但需要归纳回忆;在bAbI任务中,答案也在提示中,但需要通过一个或多个中间步骤的计算才能得出答案。最后,在GSM8K任务中,答案不再存在于文本中,并且还需要通过多个中间计算来解析结果。通过这种探索,我们旨在确定可行的策略,以在一系列不同复杂程度的推理任务中提升模型性能,无论推理的正式定义如何。
4.3 局限性
尽管本文展示了表征工程如何成功地在归纳、演绎和数学任务中引导出更好的推理行为,但我们也看到了一些局限性。我们评估的模型范围有限,这些模型比生产级别的最先进模型要小。不过,使用较小的模型为评估随着模型规模扩大能力和对称性的出现提供了机会。使用专门为可解释性研究开发的模型,也为未来研究与大语言模型推理相关的内部模型动态开辟了道路。而且,尽管最大的模型仅有70亿个参数,但Mistral - 7B - Instruct模型的能力相对较强。
此外,IOI推理任务是一个相对简单的任务,这有利有弊。结果表明,像IOI这样的任务甚至可能 过于 简单,无法引出通用的表征。只有当模型不能正确回答每个问题时,这个任务对我们的研究来说才最有趣,而这是一个很难把握的平衡。因此我们转而使用bAbI和GSM8K数据集,以及Mistral - 7B - Instruct模型进行更多实验。然而,简单的任务也限制了潜在错误的范围,这使得我们能更清晰地了解模型行为。
我们还提出了在表征工程研究中创建用于推理的对比对的初步步骤,但我们呼吁未来的工作应专注于研究如何从模型表征中最优地推导控制向量。
4.4 结论
我们成功运用了表征工程技术,首先在与推理相关任务的训练集上训练控制向量,其次在推理过程中对残差流的中间层进行干预。这使我们能够提高Pythia和Mistral模型在简单归纳任务(IOI)、演绎bAbI任务以及GSM8K数据集上的性能。我们展示了如何使用通过对比提示训练的控制向量来控制和引导大语言模型的输出,以及这些修改如何影响这些模型的内部表征。未来的研究方向包括将这种干预应用于更大的模型、更通用的任务,测试不同的对比方案,以及探索将这种方法融入模型的方式。总之,我们的实验表明,推理在一定程度上可以被理解为编码在残差流中,这与情感效价或 Golden Gate 特征在Anthropic开发的模型残差流中的编码方式类似。
可重复性声明
我们致力于推动研究工作的可重复性,并鼓励在该方向上开展更多研究。作为内部框架开发的实现源代码,将与本文一同发布,以助力这一进程。我们的框架是基于PyTorch构建的封装程序,便于提取隐藏维度表征并应用控制向量。3.3节中描述的模型是通过HuggingFace API加载的,模型版本的详细信息在该部分也有说明。2.1节详细介绍了控制向量的训练过程。3.2节全面阐述了实验结果的计算方式,包括所使用的所有指标。关于所使用数据集的信息,包括任何预处理步骤,可在3.1节和附录A.2中找到。
论文发表后,我们将通过GitHub公开代码,并提供文档,指导用户完成实验的设置与执行。
A. 附录
A.1 控制向量范数
从公式2可以得出,任何控制向量的范数都等同于模型给定层隐藏维度激活值的平均值。对于对比对(公式3),它将等同于从 “期望” 状态减去 “相反” 状态时所得到的范数。然而,基于主成分分析(PCA)的控制向量并非如此,因为标准的PCA实现会将输出向量缩放至L2范数为1。我们无法得知 ∥ H ℓ ∥ \left\lVert H_{\ell} \right\rVert ∥Hℓ∥的确切大小,因为这取决于LayerNorm函数中学习到的参数 γ \gamma γ和 β \beta β。假设 γ = 1 \gamma = 1 γ=1且 β = 0 \beta = 0 β=0(这是常见的初始值,Ba等人,2016),隐藏维度 d d d的范数粗略估计为 ∥ H ℓ ∥ = d \left\lVert H_{\ell} \right\rVert = \sqrt{d} ∥Hℓ∥=d,不过该值会因模型和层的不同而有很大差异。因此,我们将PCA控制向量按训练数据的 ∥ H ℓ ∥ \left\lVert H_{\ell} \right\rVert ∥Hℓ∥进行缩放,以便更直接地比较不同的控制向量方法。如图7所示,尽管实际的控制向量不同,但两种方法得到的范数相同。

A.2 数据
间接宾语识别(IOI)
IOI任务示例是使用以下模式生成的:
在BABA(B)条件下,模式如下:
我们在此给出一个示例,该示例也在3.1节中展示过。
这些示例被拆分为 ( X , y ) (X,y) (X,y) 对,形式如下,并将X作为输入、y作为正确生成内容输入到模型中:
在提取模型表征时,(X, y) 对会合并为一个包含输入提示和正确答案的字符串。在评估导出的控制向量的性能时,模型仅接收 X,我们会评估潜在答案中 logit 最高的词元是否与正确标签 y 一致。我们采用80/20的训练 - 测试划分来训练和评估控制向量的性能。我们不进行任何额外的预处理。
BABI 数据集
我们使用了bAbI数据集,重点关注任务15,该任务涉及简单的演绎推理。数据集中的每个示例包含:1)一段包含事实陈述的文本段落,2)一个基于该段落的问题,以及 3)正确答案。我们在此给出一个示例。

示例被拆分成以下形式的(X, y)对,将X作为输入、y作为正确生成内容输入到模型中:

在提取模型表征时,(X, y) 对会合并为一个字符串,其中包含输入提示与正确答案。在评估所导出控制向量的性能时,模型仅接收X,我们会判断在所有可能答案中,具有最高 logit 的词元是否等同于正确标签y 。我们采用80:20的比例划分训练集与测试集,以训练和评估控制向量的性能。
我们未进行任何额外的预处理,直接从https://huggingface.co/datasets/Muennighoff/babi下载了数据。
1-shot 提示
在进行 1-shot 提示时,我们仅在输入提示中提供一个如何解决任务的示例。为避免引导模型偏向特定答案,会给出一个分布外的示例。其形式如下:

指令提示
由于经过指令微调的模型能够遵循指令,我们发现提示模型输出一个单词的答案是合理的,并且从实证角度看效果也更好。

A.3 GSM8K翻转响应
以下是使用Mistral - 7B - Instruct模型以及α = - 2.6的PCA对比控制向量进行实验的一个具体示例。此示例展示了应用干预措施时,推理过程仍然会受到影响,并且干预中的某些因素会使模型最终准确得出正确答案3,而非2.5。在模型生成“which is 1 bolt of white fiber”这段文本之前,两个样本中的“推理”过程是相同的。这条额外信息似乎让模型在最终回答问题时能够生成正确答案。
干预前的响应:

干预后的响应:


A.4 额外结果
我们基于从A条件中提取的信号来训练控制向量,并将其应用于各个实验条件。从图9a和图2a中可以看出,对于Pythia - 1.4B和Pythia - 2.8B模型,我们观察到在不同任务间存在一定程度的泛化。当在各条件下以正的 α α α 值应用控制向量时,Pythia - 1.4B的准确率有所提高。正向的KL散度相对稳定,而负向的KL散度则非常不稳定,导致KL散度在负向变得更高且变化更大(图9b)。这些发现得到了熵分析的证实,熵分析表明随着准确率的提高,熵略有下降,但当 α → − 1 α → - 1 α→−1 时,熵下降得更为明显,这表明干预措施正将概率质量推向某个特定的错误词元(图9c)。此外,从图9d中我们还可以看到,平均而言,概率质量是如何在正确答案周围累积的,尽管正α值带来的增长幅度较小。

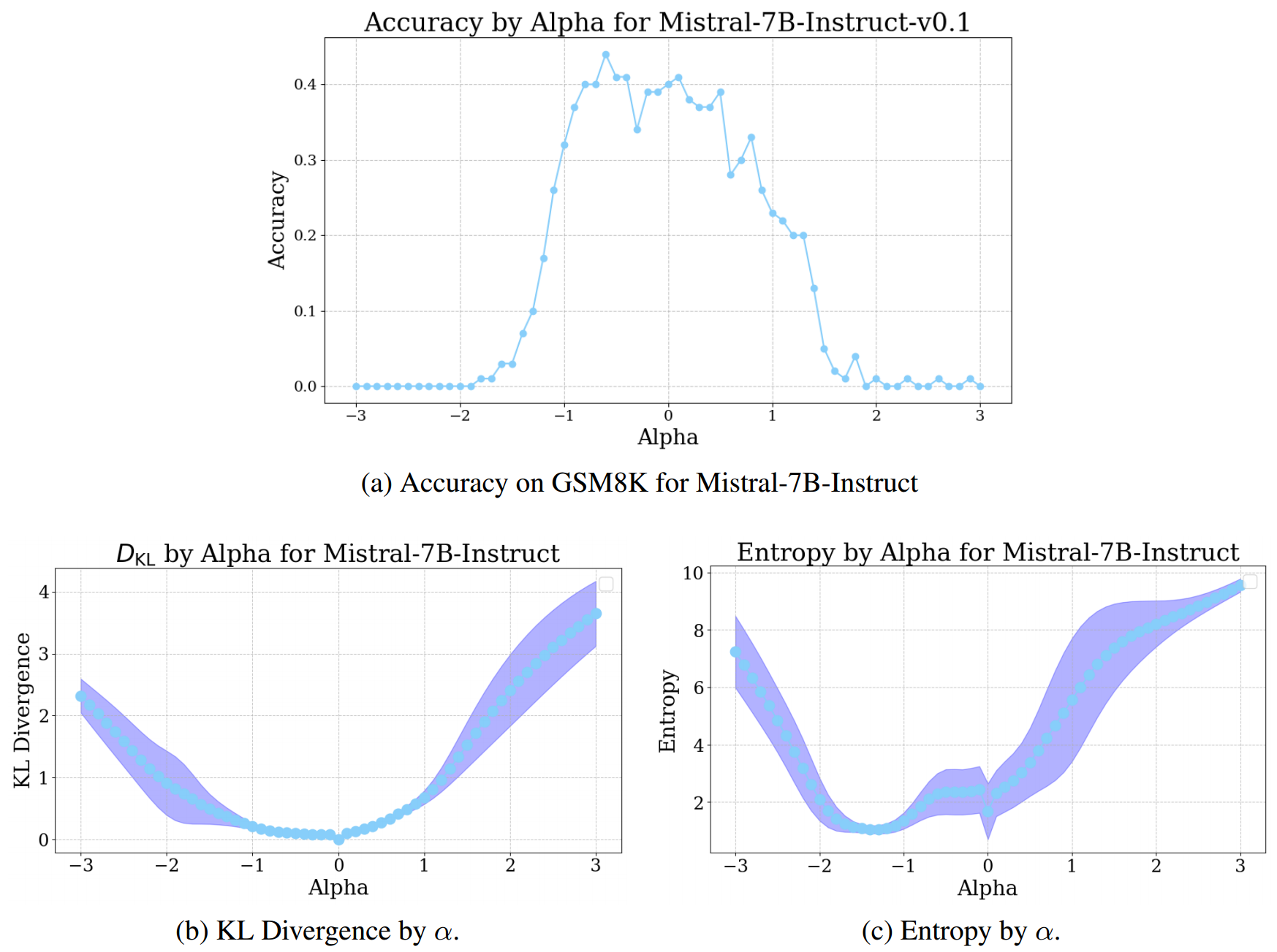
A.5 控制向量跨任务结果

🐇速读版
1. 论文要解决什么问题?
背景
如何提升大语言模型(LLMs)的推理能力,一直以来都是人们所关注的。先前的一些研究通常是从模型的输出角度入手对其推理性能进行研究,但是模型推理过程中的内部状态却很少有人研究,这导致对LLMs的推理过程或其表征学习动态无法得出确切结论。因此,这篇文章从LLMs的内部状态入手,通过一种表征工程方法来提升LLMs的推理能力,并且这是一种Training-free的方法。
【注】什么是LLMs的推理(Reasoning)?
首先先要理解什么是推理(Reasoning),推理是从一个或多个已知的判断(前提)得出新判断(结论)的思维过程。常见的推理形式有归纳推理、演绎推理和溯因推理等。
LLMs的推理(Reasoning)是指模型基于所学到的知识和模式,对输入的信息进行理解、分析、推断和得出结论的能力。
Daniel Kahneman 在 Thinking, Fast and Slow 一书中人类的思维归纳为两大思考系统:系统1的运行是无意识且快速的,不怎么费脑力,没有感觉,完全处于自主控制状态;系统2将注意力转移到需要费脑力的大脑活动上来,例如复杂的运算。而目前一种普遍观点认为,当前的LLMs的思维更像是系统1,而不具备系统2。
2. 如何解决的?
思路
先前一些关于LLMs可解释性方面的研究表明,通过手动调节模型的内部状态,能够诱导出特定类型的行为。这里需要了解一些先前的相关工作,由于篇幅原因,在这里仅简单介绍一下这些工作,想了解详情的读者可以点击链接阅读原文献:
| 相关文献 | 简介 |
|---|---|
| Locating and Editing Factual Associations in GPT [NeurIPS 2022] | 大语言模型将事实信息(如“The Eiffel Tower is in → Paris”这类事实知识)存储在哪里?这篇文章通过“因果追踪”方法定位到事实知识被存储在主语最后一个token(如“Tower”)中间层(如第15层)的MLP模块中,并进一步对MLP模块进行编辑从而修改事实知识。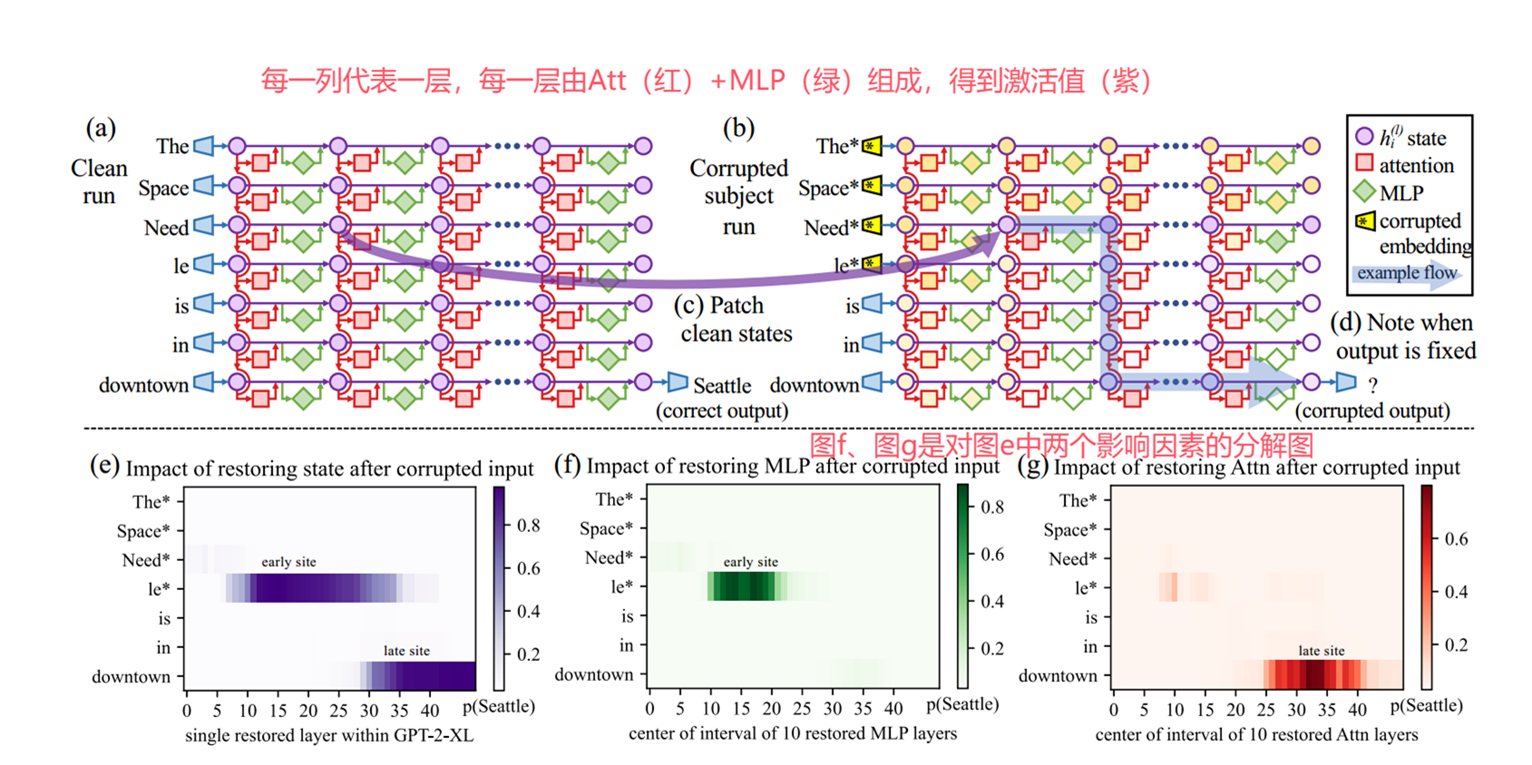 |
| INTERPRETABILITY IN THE WILD: A CIRCUIT FOR INDIRECT OBJECT IDENTIFICATION IN GPT-2 SMALL [ICLR2023] | 这篇论文从mechanistic层面理解GPT – 2 small是如何执行间接宾语识别(IOI)这项任务的。论文通过精细的逆向工程(如Path Patching),揭示了GPT-2 small执行IOI任务的内部电路。 |
| In-Context Learning Creates Task Vectors[EMNLP 2023]、In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering[ICML2024]、FUNCTION VECTORS IN LARGE LANGUAGE MODELS[ICLR 2024] | 这三篇文章都是对LLM的上下文学习机制进行了研究,均证明了上下文学习可以通过模型内部表征进行控制。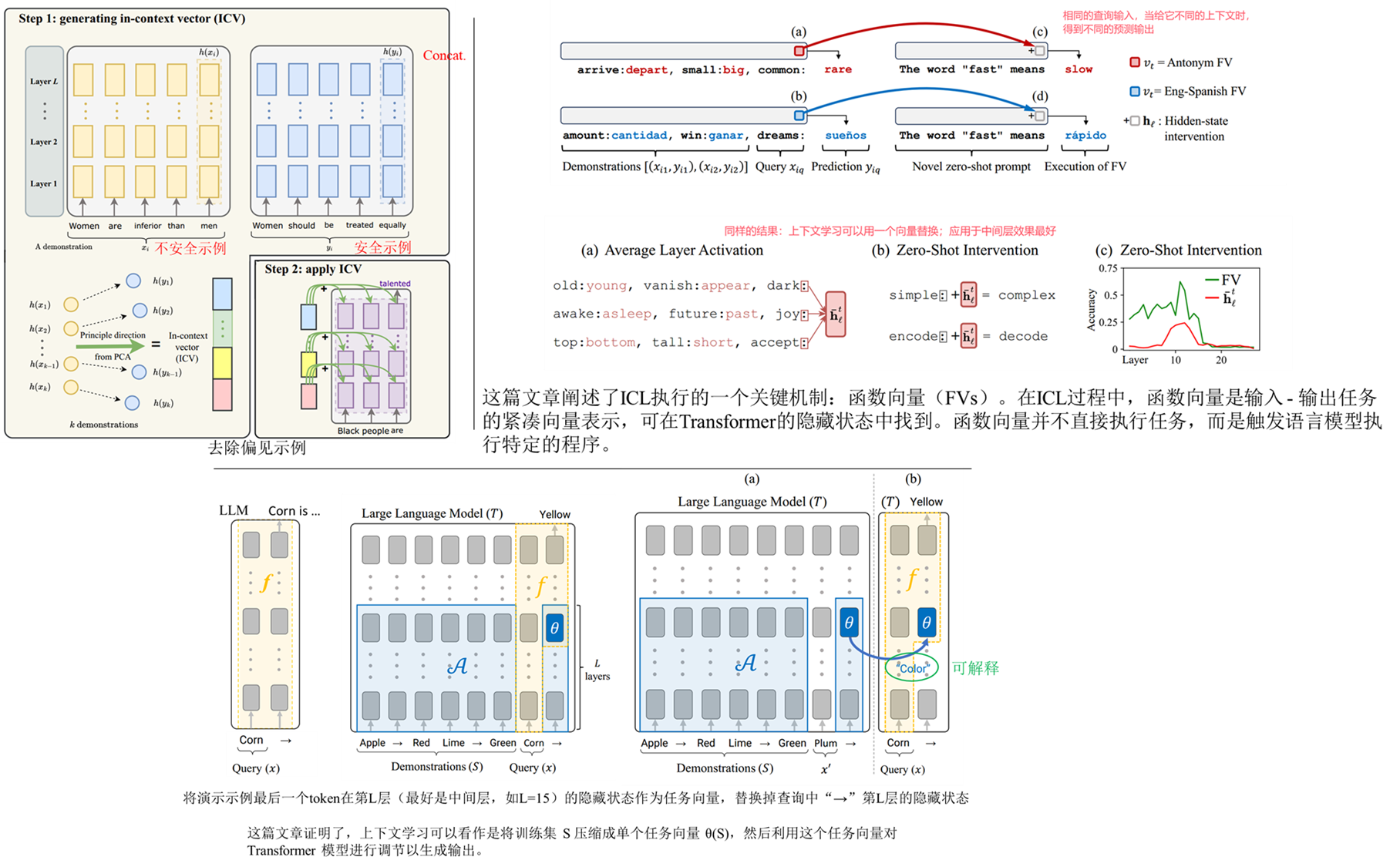 |
| Emergent World Models and Latent Variable Estimation in Chess-Playing Language Models[COLM 2024] | 这篇文章想研究LLM到底是虚假的统计还是真的对世界进行内部建模,为了简化研究,论文从一个狭窄的视角——棋类游戏中窥探LLM的内部表征。 |
| Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet[Article by Anthropic] | 这是一篇Anthropic公司很有意思的报告,首次对生产级别的LLM进行可解释性研究,从中提取了数百万个特征,并且验证了这些特征是可操控的,可以人为地放大或抑制它们。 |
总的来说,先前这些研究都表明,通过以一种有意义的方式调节LLM的内部状态(残差流),就有可能诱导出不同类型的“行为”特征,比如诚实性、真实性和情感效价。这里要介绍一个概念:残差流(Residual Stream)。
残差流(Residual Stream)这个概念也是由Anthropic这个公司在21年发布的一篇报告 A Mathematical Framework for Transformer Circuits 中被提出的。残差流本质就是隐藏层状态,也就是每层的embedding,它只是对这些概念性的重新阐释,之所以重新阐释,是因为与传统的transformer认知不同,传统的transformer关注每个计算模块所执行的操作,而残差流这种阐释方式强调每个计算模块是从残差流中读取信息,并向残差流写入信息,而残差流在 Transformer 模型的隐藏层维度中得以体现。以这下面张图(右)为例来从残差流的视角看一下模型的信息流动情况。右图是基于transformer的模型内部的单个层,假设这是第 l + 1 l+1 l+1 层,首先,当信息到达这一层时,它会先从残差流中读取上一层,也就是第 l l l 层的输出 x l x_l xl,然后先经过第一个子模块,也就是多头自注意力模块,得到 A t t ( x l ) Att(x_l) Att(xl)这部分的输出值,然后通过残差连接与原本的输入相加,这时候会将这个整体输出再写进残差流,传送到下一个子模块,然后这个子模块从残差流中读取之前的输出值 y l y_l yl,再经过第二个子模块,MLP层,同样通过残差连接得到最终整个层的输出 x l + 1 x_{l+1} xl+1,然后这个输出同样会被写进残差流中,传送到下一层。

本次要解读的这篇论文的思路就是在先前这些研究的成果上,将其应用于LLM的推理中,看看模型的推理是否也想模型情感、真实性等一样可以进行干预调整。
论文方法
论文的方法相对简单,如下图所示,以残差流的视角看,transformer中单层所执行的操作如公式1所示(不包含 c ℓ ⋅ α \mathbf{c}_{\ell} \cdot \alpha cℓ⋅α这一项),本文旨在从隐藏层维度中提取激活值,基于这些激活值创建一个控制向量 (control vector),并评估在推理阶段进行干预是否能够提升模型的推理能力。具体来说就是在任务示例的最后一个词元之后提取每层的表征。从这些提取的激活值中,推导出特定于层的控制向量。应用控制向量就是将 c ℓ ⋅ α \mathbf{c}_{\ell} \cdot \alpha cℓ⋅α 项简单地添加到标准的 Transformer 操作中。
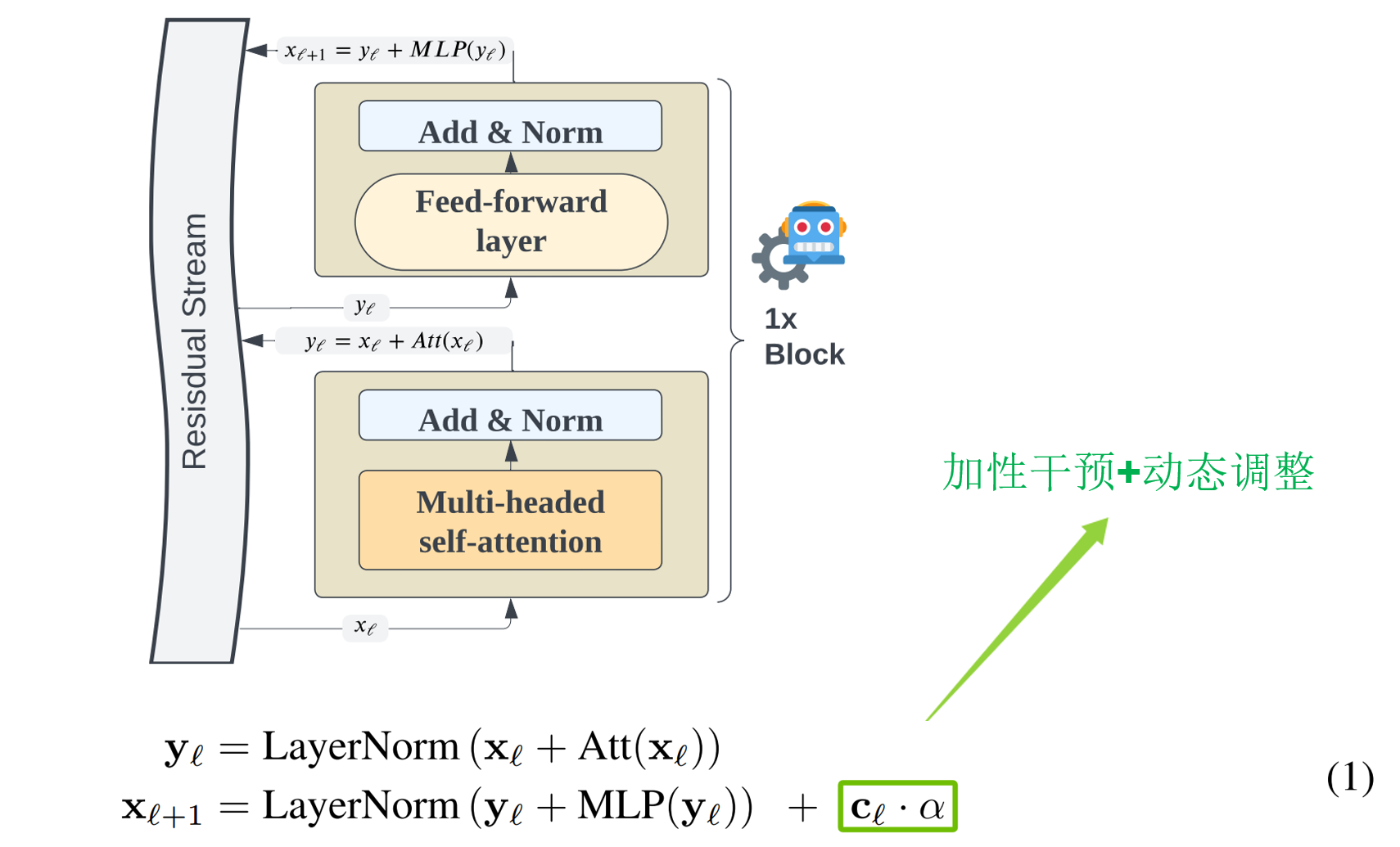
为了更好理解,这里用一张动图来展示论文的具体方法,整体分为2步,第一步先在模型能够正确推理的样本上进行一次前向传播,得到输入句子的最后一个token的中间层隐藏状态,用于生成控制向量(具体如何生成下面会讲到);然后第二步就是模型在一些原本无法正确推理的问题上进行测试时,将得到的控制向量加到模型对应层后,模型变得能够正确推理,就相当于用一个“正确推理的方向”来引导模型,从而提升了模型的推理能力,整个过程无需训练。
那控制向量具体如何得到?论文给出了三种方法:
以上就是这篇论文所提出的提升LLM推理性能方法,关于实验细节建议阅读本篇博客🦥精读版部分。下面是笔者写的一个该方法的实现Demo,以供进一步理解论文方法:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
import numpy as np
from sklearn.decomposition import PCA
model_name = "LLM/pythia-1.4b"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
target_layers = model.gpt_neox.layers[10:16]
layer_indices = list(range(10, 16))
activations = {idx: [] for idx in layer_indices}
def get_activation(layer_idx):
def hook(module, input, output):
last_token_activation = output[0][:, -1, :].detach().cpu().numpy()
activations[layer_idx].append(last_token_activation)
return hook
handles = []
for idx, layer in zip(layer_indices, target_layers):
handles.append(layer.register_forward_hook(get_activation(idx)))
def extract_activations(prompts):
for k in activations.keys():
activations[k].clear()
for prompt in prompts:
inputs = tokenizer(prompt, return_tensors="pt", padding=True).to("cuda")
with torch.no_grad():
model(**inputs)
return {
idx: np.concatenate(activations[idx], axis=0)
for idx in layer_indices
}
positive_prompts = [
"What is the capital of France?",
"What is the sum of three and six?",
"Who invented the light bulb?",
]
negative_prompts = [
"sKpDmTqGfBhJwYxNzLpRsVeUaHnFbC",
"VwYjBkTqNgHfLpUaMsXrCzIeJwQnFh",
"YgJbKxLhTqCmFpWsNvRzEaUfIwDnQk",
]
positive_activations = extract_activations(positive_prompts)
negative_activations = extract_activations(negative_prompts)
for handle in handles:
handle.remove()
control_vectors = {}
for idx in layer_indices:
contrastive_diffs = positive_activations[idx] - negative_activations[idx]
pca = PCA(n_components=1)
pca.fit(contrastive_diffs)
cv = pca.components_[0]
layer_norm_weight = model.gpt_neox.layers[idx].input_layernorm.weight
cv = cv * np.linalg.norm(layer_norm_weight.detach().cpu().numpy())
control_vectors[idx] = torch.tensor(cv, dtype=torch.float16).to("cuda")
def intervene_inference(prompt, alpha=1.0):
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
original_output = model.generate(**inputs, max_length=133)
original_text = tokenizer.decode(original_output[0], skip_special_tokens=True)
original_text = original_text[len(prompt):].strip()
intervention_handles = []
for idx, layer in zip(layer_indices, target_layers):
cv = control_vectors[idx]
def make_intervention_hook(cv, alpha):
def hook(module, input, output):
modified_output = output[0].clone()
# modified_output[:, -1, :] += alpha * cv
modified_output += alpha * cv
return (modified_output,) + output[1:]
return hook
hook = make_intervention_hook(cv, alpha)
intervention_handles.append(layer.register_forward_hook(hook))
with torch.no_grad():
intervened_output = model.generate(**inputs, max_length=120)
for handle in intervention_handles:
handle.remove()
intervened_text = tokenizer.decode(intervened_output[0], skip_special_tokens=True)
intervened_text = intervened_text[len(prompt):].strip()
return original_text, intervened_text
# 示例使用
prompt = "During the exciting school talent show, Emily performed a beautiful dance routine that received thunderous applause from the audience. After she finished, the host, Mr. Brown, walked onto the stage with a big smile. He held a small trophy in his hand and said, \"This amazing performance deserves a special recognition. Now, I'm going to give this trophy to...\" What's the most likely name of the person he will mention next to receive the trophy?"
original, intervened = intervene_inference(prompt, alpha=0.2)
print("原始输出:", original)
print("干预后的输出:", intervened)
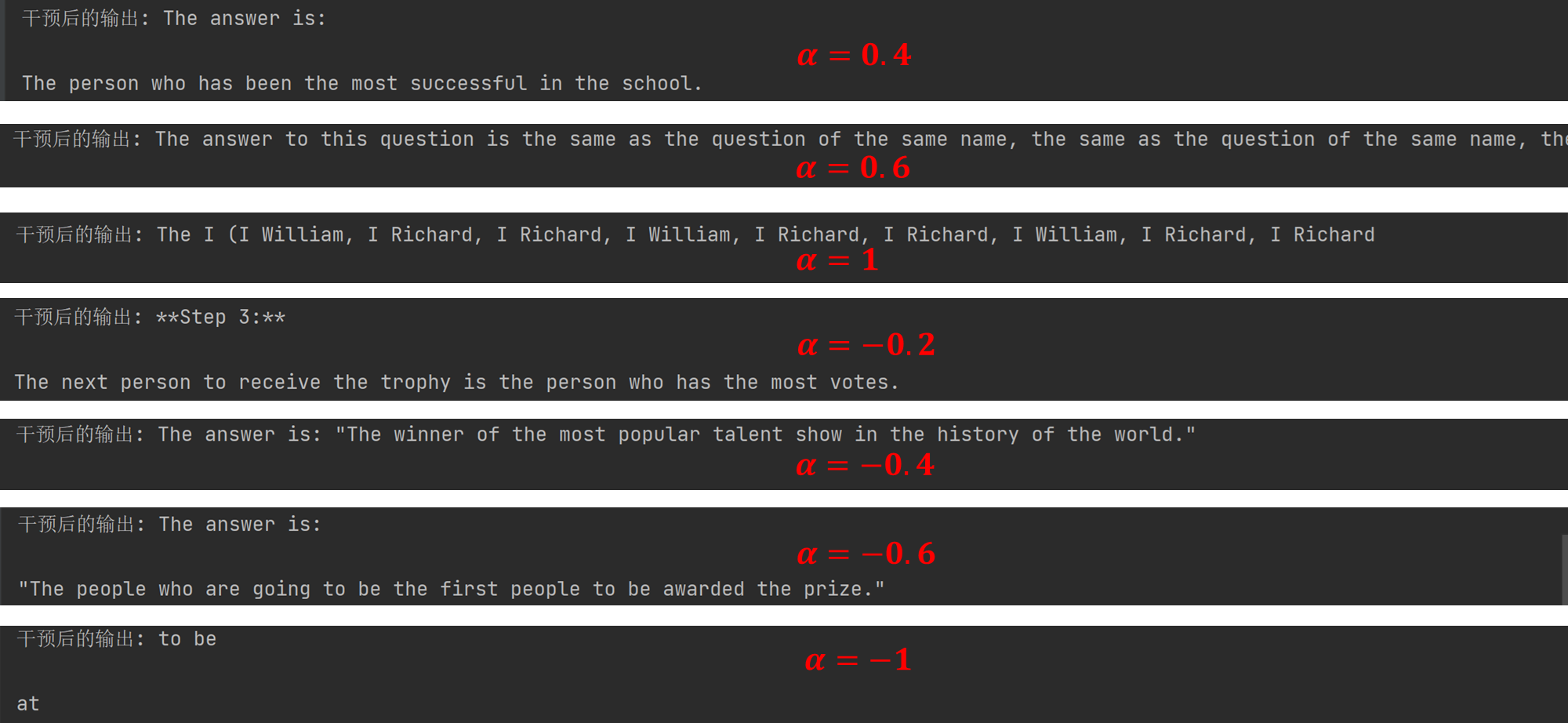
这里罗列一些实验结果: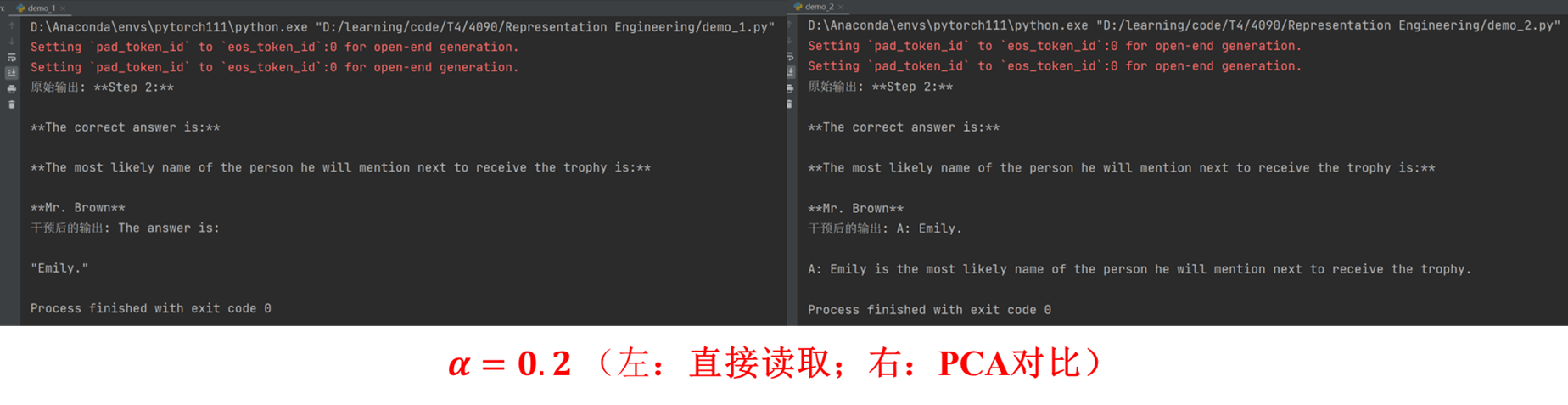
🤔思考
这篇文章证明了推理性能可以像大语言模型执行的其他信息处理任务一样进行调节。这与先前的相关研究结论一致,如情感效价分析、文本风格转换、引导学习下棋等任务中那样,对模型内部的残差流实施干预措施,能够有效改善模型的输出。但个人认为也存在一些局限性:
- 应用灵活性较低:实际部署中𝛼该如何取值?不同类型的LLM可能需要精心设置不同的𝛼值。这里给出一些可能的思路:①先构建一个开发集,在开发集上找到最佳参数𝛼,然后应用,但这种方法效率、灵活性均较低;②针对不同任务自适应设置𝛼取值,这种思路可能需要进一步探究参数的自适应算法;找出𝛼在不同任务或者模型规模中有哪些“定律”,从而成为在实践中𝛼 取值的依据;
- 模型规模局限性:论文中实验测试仅限于较小的模型(最多 7B 参数),这可能会限制结论的适用性。较大的模型可能会以不同的方式捕捉推理动态,并在类似的干预下产生不同的结果。
另外,顺便说一下这篇文章的写作,不是太严谨。比如A、B、AL、BL的概念没有解释;正文和附录中均没有提到随机对比对这个方案的实验结果,但却给了一张结果图,却没有任何对此图的分析(实际上对比这幅图可以分析得出: GSM8K 方案 2 上的 Mistral-7B 实际上在提高性能方面效果更好)等等。但总体来说瑕不掩瑜,是一个合格的文章。笔者在读这篇论文的时候,论文还处于盲审阶段,目前已经被ICLR2025会议接收。
论文中提到Pythia模型仅在IOI上评估,并没有在更复杂的bAbI和GSM8K上测试,作者在论文中给出的解释是:“由于Pythia模型无法充分解决bAbI或GSM8K任务,我们仅报告其在IOI任务上的结果。”这似乎也侧面说明了模型无法突破Scaling Law,这也是为什么作者在论文中提到“此外,当改进模型的方法直接源自其自身隐藏状态时,我们不能指望能够在模型无法充分解决的任务上提升它。”,因为在这些无法解决的任务上,压根就找不到正样本示例来构建控制向量。这里给出一个可能的改进方法:可以尝试提取更大参数的模型(如llama、deepseek等开源模型的大参数版本)的控制向量,应用到较小模型上,看看小模型是否能突破其性能。这类似于知识蒸馏的思想,但是原理不同(知识蒸馏的原理是使用较大参数教师模型的logit来训练较小参数学生模型),且不需要训练。
最后,在读这篇文章的时候,论文方法给我的感觉与前几年流行的soft-prompt范式在思路上很像,二者都致力于通过隐式表征调整实现与显式干预等效的效果。这也让我回想起最近几年语言模型的发展,从监督微调(SFT)、提示学习(Prompt)、软提示(Soft-prompt)、上下文学习(ICL)、上下文向量(ICV)、思维链(CoT)等等,再到这篇文章提出的表征工程(RE),可以发现,随着语言模型(LM)的参数规模与通用能力持续提升,其优化技术路线呈现出两大关键演变趋势:① 引导形式:文本(显式) → 向量(隐式);②适配方式:Training → Training-free。此外,这些技术也再逐渐从盲目变得可解释,希望未来可以打开神经网络的黑盒,实现对神经网络内部复杂机制从现象认知到深度理解的转变,为后续模型优化、性能提升以及风险可控奠定坚实基础 。
参考文献
@inproceedings{
hjer2025improving,
title={Improving Reasoning Performance in Large Language Models via Representation Engineering},
author={Bertram H{\o}jer and Oliver Simon Jarvis and Stefan Heinrich},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=IssPhpUsKt}
}

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)