AI知识库本地Docker部署--Docker部署LLM大语言模型glm-4-9b-chat
近期有个需求,服务器不能联网,需要本地私有化用docker部署一套AI知识库系统,技术选型如下:FastGPT: FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。
前言
近期有个需求,服务器不能联网,需要本地私有化用docker部署一套AI知识库系统,技术选型如下:
FastGPT: FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。
LLM大语言模型GLM-4-9B-Chat:GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。
Embedding向量模型:Bge-M3 具有多语言性(Multi-Linguality)、多功能性(Multi-Functionality)和多粒度性(Multi-Granularity)的特点。M3-Embedding能够支持超过100种工作语言,为多语言和跨语言检索任务提供了新的最先进性能。它能够同时执行嵌入模型的三种常见检索功能:密集检索(Dense Retrieval)、多向量检索(Multi-Vector Retrieval)和稀疏检索(Sparse Retrieval),为实际的信息检索(IR)应用提供了统一的模型基础。M3-Embedding能够处理不同粒度的输入,从短句到长达8192个标记的长文档。
这篇文章主要讲本地私有化部署AI知识库系统时用Docker部署LLM大语言模型glm-4-9b-chat的部署步骤。
注意:因为服务器不能联网,所以只能部署到docker里面,如果有需要补充的包只能在本地下载好了,再上传到服务器上进行离线安装。
本地服务器配置信息如下:
-
OS: Ubuntu 22.04 (ubuntu官方镜像下载地址:https://releases.ubuntu.com/jammy/ubuntu-22.04.5-desktop-amd64.iso)
-
Memory: 64GB
-
Python: 3.10.12 (推荐) / 3.12.3 均已测试
-
CUDA Version: 12.4
-
GPU Driver: NVIDIA-Linux-x86_64-550.142
-
GPU: NVIDIA GeForce RTX 3090 24G*2
步骤一:下载官方源码
git clone https://github.com/THUDM/GLM-4.git
我的下载目录是:/data/ai/
步骤二:下载大模型文件:
魔塔社区地址:https://modelscope.cn/models?name=glm-4-9b-chat&page=1
#请确保 lfs 已经被正确安装
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/glm-4-9b-chat.git
我的下载目录是:/data/ai/
步骤三:编写Dockerfile文件及下载基础镜像
cd /data/ai/``#创建dockerfile``vi Dockerfile
Dockerfile内容如下
# 使用pytorch镜像作为基础镜像
FROM pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
ARG DEBIAN_FRONTEND=noninteractive
# 设置工作目录
WORKDIR /app
# 更新包索引并安装必要工具
RUN apt-get update && apt-get install -y \
openssh-server \
vim \
curl \
build-essential \
git && \
rm -rf /var/lib/apt/lists/*
# 安装Python依赖
RUN pip config set global.index-url http://mirrors.aliyun.com/pypi/simple
RUN pip config set install.trusted-host mirrors.aliyun.com
RUN pip install jupyter && \
pip install --upgrade ipython && \
ipython kernel install --user
# 安装Node.js 和 pnpm
RUN cd /tmp && \
curl -fsSL https://deb.nodesource.com/setup_22.x -o nodesource_setup.sh && \
bash nodesource_setup.sh && \
apt-get install -y nodejs && \
rm -rf nodesource_setup.sh && \
node -v
RUN npm config set registry https://registry.npmmirror.com
RUN npm install -g pnpm
RUN node -v && pnpm -v
# 复制依赖到容器
RUN mkdir -p /app/GLM-4
RUN mkdir -p /app/glm-4-9b-chat
RUN mkdir -p /app/bge-m3
COPY GLM-4/composite_demo/requirements.txt /app/GLM-4/composite_demo
COPY GLM-4/basic_demo/requirements.txt /app/GLM-4/basic_demo
COPY GLM-4/finetune_demo/requirements.txt /app/GLM-4/finetune_demo
# 安装GLM-4依赖
WORKDIR /app/GLM-4
RUN pip install --verbose --use-pep517 -r composite_demo/requirements.txt
RUN pip install --verbose --use-pep517 -r basic_demo/requirements.txt
RUN pip install --verbose --use-pep517 -r finetune_demo/requirements.txt
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
#RUN pip install vllm>=0.5.2
RUN pip install nvidia-nccl-cu12>=2.22.3
# 暴露端口
EXPOSE :8501
注意:如果基础镜像下载不下来,需要单独执行(或者通过科学上网的方式获取):
docker pull pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
# 如果下载不下来可以添加docker镜像源:
vi /etc/docker/daemon.json
# registry-mirrors内容如下:
{
"data-root": "/home/docker",
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://noohub.ru",
"https://huecker.io",
"https://dockerhub.timeweb.cloud",
"https://0c105db5188026850f80c001def654a0.mirror.swr.myhuaweicloud.com",
"https://5tqw56kt.mirror.aliyuncs.com",
"https://docker.1panel.live",
"http://mirrors.ustc.edu.cn/",
"http://mirror.azure.cn/",
"https://hub.rat.dev/",
"https://docker.ckyl.me/",
"https://docker.chenby.cn",
"https://docker.hpcloud.cloud",
"https://registry.docker-cn.com"
]
}
# 重新加载配置文件
systemctl daemon-reload
sudo systemctl restart docker
Docker导出镜像文件命令:
docker save -o pytorch-2.5.1-cuda12.4-cudnn9-runtime.tar pytorch/pytorch:2.5.1-cuda12.4-cudnn9-runtime
Docker导入镜像文件命令:
docker load < pytorch-2.5.0-cuda12.4-cudnn9-runtime.tar
步骤四:制作docker大模型启动镜像
#在Dockerfile所在目录/data/ai/下执行命令:
docker build -t chatglm4:v1.0 .
# 制作好镜像后将镜像导出到目标服务器:
# 导出镜像文件
docker save -o chatglm4-v10.tar chatglm4:v1.0
# 导入镜像文件
docker load < chatglm4-v10.tar
步骤五:启动glm-4-9b-chat大模型(Web访问的方式启动)
注意:文件composite_demo/src/main.py中的模型地址需要修改为:
MODEL_PATH = os.environ.get(‘MODEL_PATH’, ‘/app/glm-4-9b-chat’)
docker run -it --gpus all --privileged --name glm-web --shm-size=1g -d -it \
-p 8501:8501 \
-v /data/ai/GLM-4:/app/GLM-4 \
-v /data/ai/glm-4-9b-chat:/app/glm-4-9b-chat \
-e CHAT_MODEL_PATH=/app/glm-4-9b-chat \
-e CUDA_VISIBLE_DEVICES=0,1 \
chatglm4:v1.0 streamlit run composite_demo/src/main.py
docker参数的意思见第六步docker参数解释。
启动成功后访问 http://127.0.0.1:8501:
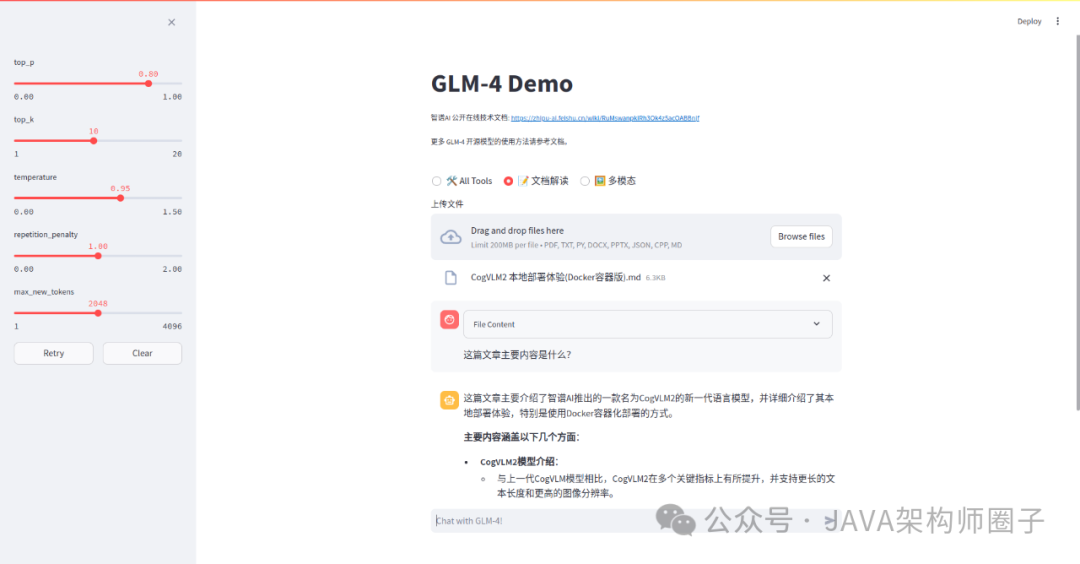
步骤六:启动glm-4-9b-chat大模型(openai api 方式启动)
注意:GLM-4\basic_demo\openai_api_server.py中的模型地址需要修改为docker中映射的目录:MODEL_PATH=os.environ.get(‘MODEL_PATH’,‘/app/glm-4-9b-chat’)
docker run --privileged --name glm-bge-api \
--shm-size=1g -d -it --gpus all \
-e CUDA_VISIBLE_DEVICES=0,1 \
-e NCCL_IB_DISABLE=1 \
-e NCCL_P2P_DISABLE=1 \
-p 8000:8000 \
-v /data/ai/GLM-4:/app/GLM-4 \
-v /data/ai/glm-4-9b-chat:/app/glm-4-9b-chat \
-e CHAT_MODEL_PATH=/app/glm-4-9b-chat \
-e CHAT_MODEL_PATH=/app/bge-m3 \
chatglm4:v1.0 python basic_demo/openai_api_server.py
下面还有步骤七,继续阅读。。。。
下面是docker命令每个参数的解释:
-
--privileged:以特权模式运行容器,这允许容器内运行的进程获得比普通容器更多的权限,接近宿主机的权限。 -
--name glm-bge-api:为容器指定一个名称,这里是glm-bge-api。 -
--shm-size=1g:设置容器的共享内存大小为1GB。共享内存(shm)用于某些进程间通信和内存映射文件。 -
-d:以分离模式运行容器,即在后台运行。 -
-it:这两个参数通常一起使用,-i保持容器的标准输入(STDIN)打开,-t分配一个伪终端。 -
--gpus all:允许容器访问宿主机上的所有GPU资源。 -
-e CUDA_VISIBLE_DEVICES=0,1:设置环境变量CUDA_VISIBLE_DEVICES,指定容器可以使用的GPU设备编号,这里是0和1。 -
-e NCCL_IB_DISABLE=1和-e NCCL_P2P_DISABLE=1:设置环境变量,禁用NCCL(NVIDIA Collective Communications Library)的InfiniBand和点对点通信,这通常用于多GPU训练时优化通信。 -
-p 8000:8000:将容器内部的8000端口映射到宿主机的8000端口,这样可以通过宿主机的8000端口访问容器的服务。 -
-v /data/ai/GLM-4:/app/GLM-4:将宿主机的/data/ai/GLM-4目录挂载到容器的/app/GLM-4目录,用于数据共享。 -
-v /data/ai/glm-4-9b-chat:/app/glm-4-9b-chat:将宿主机的/data/ai/glm-4-9b-chat目录挂载到容器的/app/glm-4-9b-chat目录。 -
-v /data/ai/bge-m3:/app/bge-m3:将宿主机的/data/ai/bge-m3目录挂载到容器的/app/bge-m3目录。 -
-e CHAT_MODEL_PATH=/app/glm-4-9b-chat和-e CHAT_MODEL_PATH=/app/bge-m3:设置环境变量CHAT_MODEL_PATH,指定聊天模型的路径,这里指定了两个路径。 -
chatglm4:v1.0:指定要使用的 Docker 镜像名称和标签,这里是chatglm4镜像的v1.0版本。 -
python basic_demo/openai_api_server.py:在容器启动后执行的命令,这里是运行python命令执行basic_demo/openai_api_server.py脚本。
步骤七:Docker同时启动LLM模型glm-4-9b-chat和向量模型bge-m3
注意:GLM-4\basic_demo\openai_api_server.py中的模型地址需要修改为docker中映射的目录:MODEL_PATH=os.environ.get(‘MODEL_PATH’,‘/app/glm-4-9b-chat’)
在GLM-4\basic_demo\glm_server.py文件中添加以下代码:
import os
import tiktoken
from sentence_transformers import SentenceTransformer
# set Embedding Model path
EMBEDDING_PATH = os.environ.get('EMBEDDING_PATH', '/app/bge-m3')
## for Embedding
class EmbeddingRequest(BaseModel):
input: List[str]
model: str
class EmbeddingResponse(BaseModel):
data: list
model: str
object: str
usage: dict
@app.post("/v1/embeddings", response_model=EmbeddingResponse)
async def get_embeddings(request: EmbeddingRequest):
embeddings = [embedding_model.encode(text) for text in request.input]
embeddings = [embedding.tolist() for embedding in embeddings]
def num_tokens_from_string(string: str) -> int:
"""
Returns the number of tokens in a text string.
use cl100k_base tokenizer
"""
encoding = tiktoken.get_encoding('cl100k_base')
num_tokens = len(encoding.encode(string))
return num_tokens
response = {
"data": [
{
"object": "embedding",
"embedding": embedding,
"index": index
}
for index, embedding in enumerate(embeddings)
],
"model": request.model,
"object": "list",
"usage": {
"prompt_tokens": sum(len(text.split()) for text in request.input), # how many characters in prompt
"total_tokens": sum(num_tokens_from_string(text) for text in request.input), # how many tokens (encoding)
},
}
logger.debug(f"==== response ====\n{response}")
return response
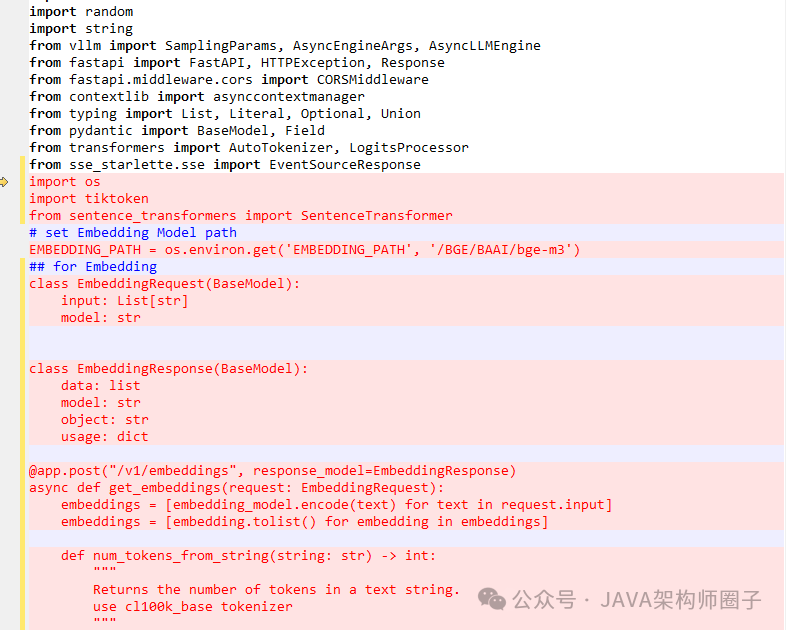
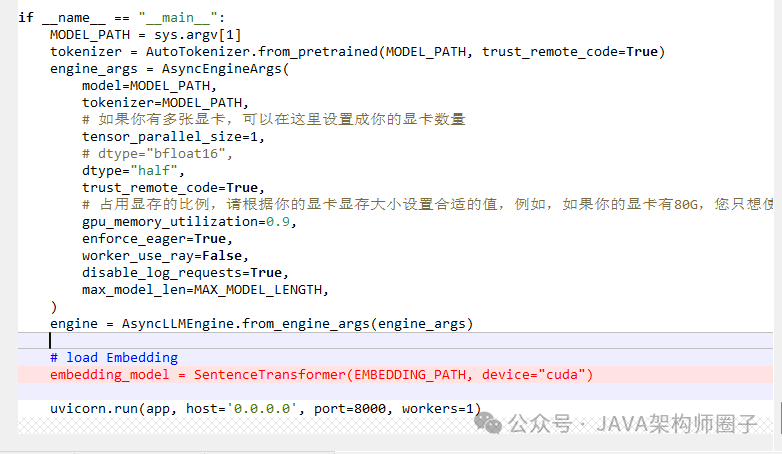
在GLM-4\basic_demo\glm_server.py的main方法中添加
# load Embedding
embedding_model = SentenceTransformer(EMBEDDING_PATH, device="cuda")
如图所示:
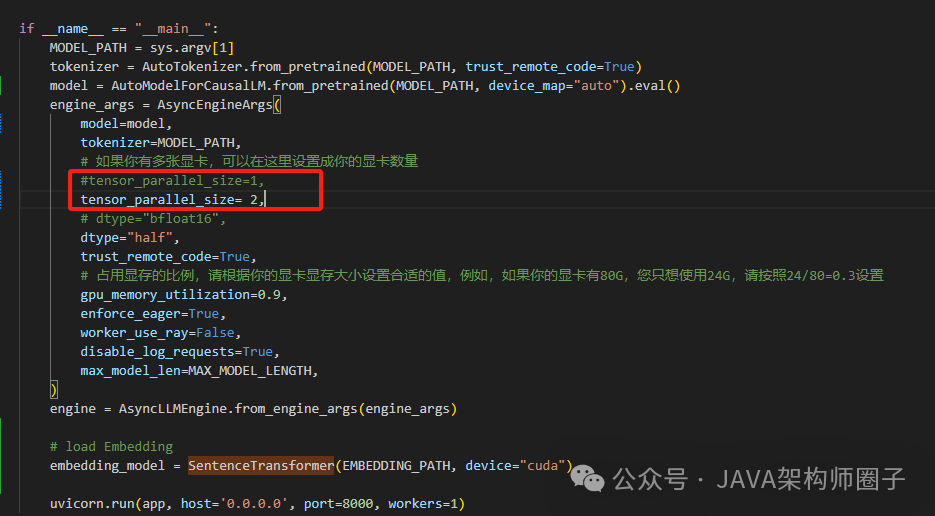
注意:如果是多张显卡,还需要修改GLM-4\basic_demo\glm_server.py中main方法中的 tensor_parallel_size=2,
修改完GLM-4\basic_demo\glm_server.py文件后,启动docker容器:
openai api方式:
docker run --privileged --name glm-bge-api --shm-size=1g -d -it --gpus all \
-e CUDA_VISIBLE_DEVICES=0,1 \
-e NCCL_IB_DISABLE=1 \
-e NCCL_P2P_DISABLE=1 \
-p 8000:8000 \
-v /data/ai/GLM-4:/app/GLM-4 \
-v /data/ai/glm-4-9b-chat:/app/glm-4-9b-chat \
-v /data/ai/bge-m3:/app/bge-m3 \
-e CHAT_MODEL_PATH=/app/glm-4-9b-chat \
-e CHAT_MODEL_PATH=/app/bge-m3 chatglm4:v1.0 \
python basic_demo/openai_api_server.py
这时候大模型聊天接口和向量模型接口都启动起来了。
聊天模型接口:
/v1/chat/completions
向量模型接口:
/v1/embeddings
步骤八:Docker部署FastGPT
参考官方文档:https://doc.tryfastgpt.ai/docs/development/docker/
后面有时间再详细写FastGPT应用的部署方式。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 17
17 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)