一步步教你大模型部署,本地部署,本地调用 or远程调用全知晓
大模型部署和调用,本地&远程,
·
本机部署,同项目代码里引用大模型
transformers:
https://huggingface.co/models
选择喜欢的模型,进入模型详情页-》use this model -> transformers
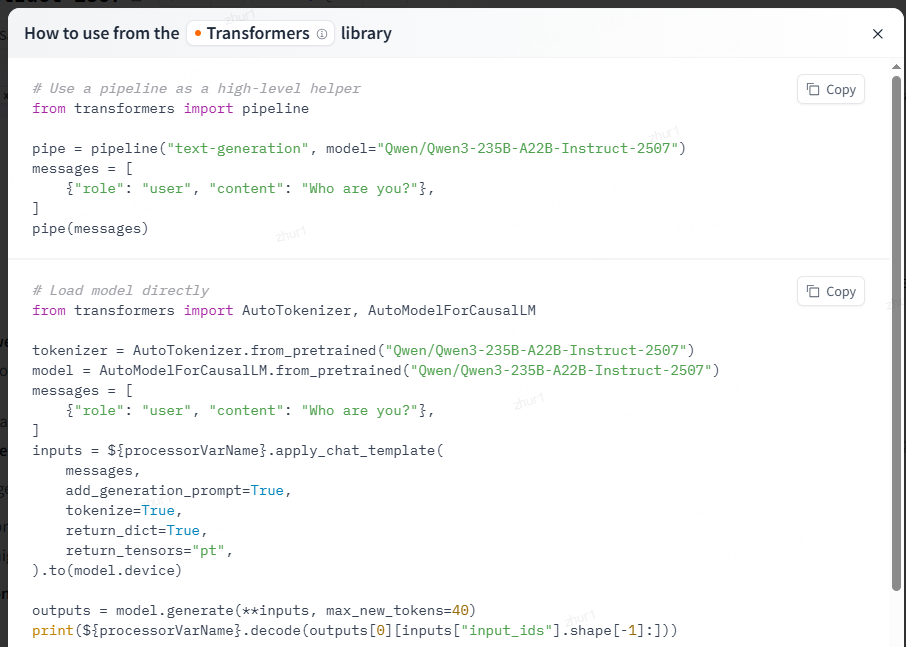
# 读取pipeline
from transformers import pipeline
pipe = pipeline("text-generation", model="Qwen/Qwen3-235B-A22B-Instruct-2507")
messages = [
{"role": "user", "content": "Who are you?"},
]
pipe(messages)
# 直接load模型
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-235B-A22B-Instruct-2507")
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-235B-A22B-Instruct-2507")
messages = [
{"role": "user", "content": "Who are you?"},
]
inputs = ${processorVarName}.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(${processorVarName}.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
SGlang
from sg_lang import load_model
model = load_model("path_to_model")
result = model.predict("Your input text here")
print(result)
vllm
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-2-7b-chat-hf")
response = llm(prompt="Hello, how are you?", sampling_params=SamplingParams(temperature=0.7))
print(response)
本机部署,远程代码里调用大模型
部署
部署方式一:vllm库
https://huggingface.co/models
选择喜欢的模型,进入模型详情页-》use this model -> vLLM
pip install vllm
# 自动下载模型并启动vllm部署
vllm serve "moonshotai/Kimi-K2-Instruct"
# 用curl在部署的机器上发个指令试一下是否部署好了:
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "moonshotai/Kimi-K2-Instruct",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'
使用自己已经下载好的模型,指定端口和服务名称served-model-name
model_path=/data/qwen/Qwen3-14B
tp=4 四张卡
python -m vllm.entrypoints.openai.api_server --model $model_path \
--served-model-name qwen3 --tensor-parallel-size $tp --trust-remote-code \
--port 30000 --host 0.0.0.0 --enable-prefix-caching --enable-auto-tool-choice --tool-call-parser hermes
部署方式二:sglang
sglang仓库地址:
首先按照sglang仓库的说明安装SGLang,官方安装说明
CUDA_VISIBLE_DEVICES=0 python3 -m sglang.launch_server --model path/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 1 --host 0.0.0.0 --port 20000
--model 表示要部署的模型路径,此处直接填写模型保存的路径即可。
--trust-remote-code 表示信任远程代码,防止被阻拦而运行失败。
--tp 表示张量并行使用的GPU数量,这里设置为1表示用单卡部署,当模型需求超过显存的时候,可以设置tp值高一些将模型拆分到多卡上,如70B模型部署需要四张卡则可以设置tp为4。
--host 为指定服务所监听的ip地址,该步骤对服务器部署deepseek至关重要,关乎于其他用户能否远程访问服务,设置为0.0.0.0表示为监听所有的网络接口,设置为其他数值(如192.168.***.***)则表示监听指定ip。
--port 为监听指定端口号,一般来说一个服务只能持续监听一个端口且不能被占用,当需要访问时则直接从另一个电脑发送请求到服务主机所在的ip地址+端口号即可(后文会给出如何使用工具从外部访问服务)。特别地,如果是在decoker中部署服务,则另外需要进行端口映射,即在创建docker便将容器端口映射到主机端口(这里可以将容器端口的20000直接映射到主机端口20000方便管理),然后便可用同样的方法访问。
sglang还有其他的参数,如设置最大并行请求数,防止服务器过载,详情可见:服务器参数 — SGLang
部署方式三:ollama部署
通过官方脚本安装ollama:
curl -fsSL https://ollama.com/install.sh | sh
注意:若担心脚本安全性,可先下载查看内容:
curl -fsSL https://ollama.com/install.sh -o install_ollama.sh
cat install_ollama.sh # 确认无误后执行
bash install_ollama.sh
启动服务并验证
sudo systemctl start ollama
sudo systemctl status ollama # 确认状态为“active (running)”

https://ollama.com/search
选择喜欢的模型,点进去详情页就有这个模型部署的代码。例如:
ollama run deepseek-r1:671b # 首次运行自动下载模型
之后出现交互式窗口,输入自己的问题即可
如果想用自己自定义的模型或者已经下载好的模型
1. 创建自定义模型
编写Modelfile(示例):
FROM llama2
SYSTEM """你是一名高级Python开发者,回答简洁且包含示例代码。"""
PARAMETER temperature 0.5
构建并运行自定义模型:
ollama create mycoder -f Modelfile
ollama run mycoder
如果想能够外网访问,需要修改模型保存路径,进行如下笑操作
编辑文件
vi /etc/systemd/system/ollama.service
在 [Service] 增加如下配置
Environment="OLLAMA_HOST=0.0.0.0:11434" # 监听所有IP,端口可自定义
Environment="OLLAMA_ORIGINS=*" # 允许所有跨域请求
Environment="OLLAMA_MODELS=/data/ollama/models" # 模型下载存储路径,一般为挂载的数据盘
远程调用
远程调用方式一:hugginface库
import os
from huggingface_hub import InferenceClient
client = InferenceClient(
provider="auto",
api_key=os.environ["HF_TOKEN"],
)
completion = client.chat.completions.create(
model="moonshotai/Kimi-K2-Instruct",
messages=[
{
"role": "user",
"content": "What is the capital of France?"
}
],
)
print(completion.choices[0].message)
远程调用方式二:openai库
from openai import OpenAI
openai_api_key = "EMPTY=="
openai_api_base = "http://ip:host/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
print(model)
def process_one(prompt, user_input):
stream = False
chat_completion = client.chat.completions.create(
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": "".join(prompt),
}
],
},
{
"role": "user",
"content": [
{
"type": "text",
"text": user_input,
}
],
}
],
model="DeepSeek-R1",
max_completion_tokens=2048,
temperature=0,
max_tokens = 8196
)
if stream:
for chunk in chat_completion:
print(chunk.choices[0].delta.content, end="")
return chunk.choices[0].delta.content
else:
result = chat_completion.choices[0].message.content
print(result)
return result
远程调用方式三:ollama库
Ollama提供本地API(默认端口11434):
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "用Python写一个快速排序函数",
"stream": false
}'
自动化脚本示例(Python)
import requests
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "llama2", "prompt": "解释递归的优缺点", "stream": False}
)
print(response.json()["response"])
远程调用方式四:服务并行与端口转发
该部分讲述如何在一个docker中部署多个服务并统一用一个端口控制转发,增大用户吞吐量。
首先我们假设部署了四个并行的大模型服务(分别监听端口19997~20000,各自使用一张GPU),我们现在需要实现持续监听某一个固定端口(如12345),然后将服务转发给目前利用率低的GPU对应的服务,实现统一管理,具体可以使用如下代码实现:
from aiohttp import web
import aiohttp
import pynvml
import random
pynvml.nvmlInit()
def get_least_used_gpu():
device_count = pynvml.nvmlDeviceGetCount()
rand_gpu = random.randint(0, 3)
handle = pynvml.nvmlDeviceGetHandleByIndex(rand_gpu)
util = pynvml.nvmlDeviceGetUtilizationRates(handle).gpu
min_util = util
min_gpu = 0
for i in range(device_count):
handle = pynvml.nvmlDeviceGetHandleByIndex(i)
util = pynvml.nvmlDeviceGetUtilizationRates(handle).gpu
if util < min_util:
min_util = util
min_gpu = i
return min_gpu
async def forward_request(request):
try:
# 获取最低负载的GPU
gpu_id = get_least_used_gpu()
target_port = 19997 + int(gpu_id/2)*2
target_url = f'http://192.168.***.***:{target_port}{request.path_qs}'
# 复制并修改请求头
headers = dict(request.headers)
headers['Host'] = f'192.168.***.***:{target_port}'
# 读取原始请求体
data = await request.read()
# 异步转发请求
async with aiohttp.ClientSession() as session:
async with session.request(
method=request.method,
url=target_url,
headers=headers,
data=data,
timeout=aiohttp.ClientTimeout(total=3600)
) as resp:
# 构建流式响应
response = web.StreamResponse(
status=resp.status,
headers=resp.headers
)
await response.prepare(request)
# 流式传输数据
async for chunk in resp.content.iter_chunked(1024):
await response.write(chunk)
return response
except Exception as e:
return web.Response(status=500, text=str(e))
app = web.Application()
app.add_routes([web.route('*', '/v1/chat/completions', forward_request)])
if __name__ == '__main__':
web.run_app(app, host='0.0.0.0', port=12345)
上述的代码使用的负载均衡算法为简单优化的随机均衡调度算法,这里可以修改为其他算法如响应速度均衡算法,可以进一步提高吞吐量。
更进一步,如果部署的模型有多种(如deepseek-Qwen蒸馏模型与QWQ模型两种),则可以在端口转发脚本中添加根据data字段中model关键字的值(该部分的值与下文中Chatbox设置里面的自定义模型名相同)进行不同的转发,如此便可以实现用户在自定义模型名中填写对应的值来指定模型服务。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)