深入解析模型评估指标:从准确率到AUC,如何选择最合适的评估指标?
模型评估指标的选择直接影响模型的优化和最终效果。在实际项目中,理解各个评估指标的含义,并根据任务特性选择合适的指标,是提升模型效果的关键。通过掌握准确率、精确率、召回率、F1 分数、AUC 等常见评估指标的计算和应用方法,你可以更加高效地评估和优化你的模型,提升模型的泛化能力和实际应用效果。希望通过本文的讲解,能够帮助你更深入理解模型评估指标的选择和应用,从而在机器学习项目中做出更明智的决策。机器
目录
深入解析模型评估指标:从准确率到AUC,如何选择最合适的评估指标?
在机器学习和深度学习中,评估模型的好坏是一个至关重要的步骤。一个模型在训练过程中的表现并不能直接反映其在实际应用中的效果,因此如何选择合适的评估指标,合理地评估模型性能,是每一个机器学习从业者都需要掌握的核心能力。
本文将深入探讨常见的模型评估指标,并结合代码示例详细讲解它们的应用场景和优缺点,帮助大家在实际项目中更好地选择评估指标。
一、常见的模型评估指标
1.1 准确率(Accuracy)
准确率是最直观的评估指标之一,表示模型预测正确的样本占所有样本的比例。其计算公式为:
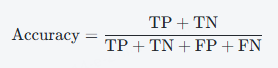
其中:
- TP(True Positive):真正例,模型正确预测为正类的样本数
- TN(True Negative):真负例,模型正确预测为负类的样本数
- FP(False Positive):假正例,模型错误预测为正类的样本数
- FN(False Negative):假负例,模型错误预测为负类的样本数
优点:简单易懂,适用于数据集类别平衡的情况。
缺点:在类别不平衡的情况下,准确率可能无法全面反映模型的真实性能。例如,在一个99%为负类的数据集中,即使模型总是预测负类,准确率也可能达到99%。
1.2 精确率(Precision)
精确率衡量的是所有被预测为正类的样本中,实际为正类的比例。计算公式为:
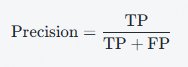
优点:精确率适用于对假正例(FP)特别敏感的任务,例如垃圾邮件分类。
缺点:精确率忽略了假负例(FN),在某些应用中可能不够全面。
1.3 召回率(Recall)
召回率衡量的是所有实际为正类的样本中,被正确预测为正类的比例。计算公式为:
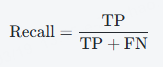
优点:召回率适用于对假负例(FN)特别敏感的任务,例如医学诊断。
缺点:召回率忽略了假正例(FP),可能导致过多的假正例。
1.4 F1 分数(F1-Score)
F1 分数是精确率和召回率的调和平均数,能够综合考虑这两个指标。其计算公式为:
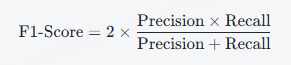
优点:F1 分数在精确率和召回率之间取得平衡,适用于对精确率和召回率要求同等的情况。
缺点:F1 分数不能单独反映模型在某一类指标上的表现。
1.5 ROC 曲线与 AUC 值
ROC(Receiver Operating Characteristic)曲线是通过绘制模型在不同分类阈值下的真正例率(TPR)和假正例率(FPR)来展示模型性能的一种工具。TPR 也就是召回率,FPR 计算公式为:
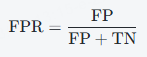
AUC(Area Under Curve)是 ROC 曲线下的面积,反映了模型分类性能的整体情况。AUC 值的取值范围为 0 到 1,越接近 1,模型性能越好。
优点:AUC 不受类别不平衡的影响,能够全面评估模型的分类性能。
缺点:AUC 只是一个宏观的评估指标,无法提供精确的类别评估。
1.6 混淆矩阵(Confusion Matrix)
混淆矩阵通过一个二维表格展示模型在不同类别上的预测情况,包括 TP、TN、FP、FN 等信息。这对于多分类问题尤为重要,能够提供细粒度的评估信息。
二、模型评估指标的选择
不同的任务和数据集特征可能需要不同的评估指标。以下是一些常见场景下的评估指标选择指南:
- 数据集类别平衡:当数据集类别平衡时,准确率通常是一个良好的评估指标。但在类别不平衡时,准确率可能不够全面,应该优先考虑精确率、召回率或 F1 分数。
- 对假正例或假负例的敏感度:如果应用对假正例特别敏感,例如垃圾邮件过滤,应优先考虑精确率。如果对假负例特别敏感,例如癌症检测,应优先考虑召回率。
- 多分类问题:在多分类问题中,混淆矩阵能够帮助我们更细致地分析各类别的预测情况,而宏平均(macro average)和微平均(micro average)方法可以在不同类别不平衡时提供综合的评估结果。
三、代码实现:如何计算这些指标?
在 Python 中,我们可以使用 sklearn 库来计算各种评估指标。以下是一些常见评估指标的计算代码:
3.1 准确率、精确率、召回率、F1 分数
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 假设 y_true 是真实标签,y_pred 是预测标签
y_true = [0, 1, 0, 1, 1, 0, 1, 0]
y_pred = [0, 1, 0, 0, 1, 0, 1, 1]
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")
3.2 混淆矩阵
from sklearn.metrics import confusion_matrix
conf_matrix = confusion_matrix(y_true, y_pred)
print(conf_matrix)
3.3 ROC 曲线与 AUC 值
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# 假设 y_true 和 y_scores 为真实标签和预测的概率值
y_scores = [0.1, 0.9, 0.3, 0.8, 0.7, 0.2, 0.6, 0.4]
fpr, tpr, thresholds = roc_curve(y_true, y_scores)
roc_auc = auc(fpr, tpr)
# 绘制 ROC 曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (area = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc='lower right')
plt.show()
print(f"AUC: {roc_auc}")
四、总结
模型评估指标的选择直接影响模型的优化和最终效果。在实际项目中,理解各个评估指标的含义,并根据任务特性选择合适的指标,是提升模型效果的关键。通过掌握准确率、精确率、召回率、F1 分数、AUC 等常见评估指标的计算和应用方法,你可以更加高效地评估和优化你的模型,提升模型的泛化能力和实际应用效果。
希望通过本文的讲解,能够帮助你更深入理解模型评估指标的选择和应用,从而在机器学习项目中做出更明智的决策。
推荐阅读:

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 12
12 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)