小白必看!启智平台轻松搞定 Qwen3 模型推理与训练
本文介绍在启智平台实现 Qwen3 模型推理和训练的方法。登录平台创建云脑任务,选择英伟达 A100 显卡、特定镜像及 qwen3 - 4B 模型。通过安装 swift 推理框架、复制模型文件完成推理;利用相关命令实现 10 分钟单卡 A100 上的模型微调,为模型使用提供操作指南
0.前言
Qwen3是阿里巴巴于2025年4月29日发布的一款开源混合推理模型,其特点和性能在多个方面都取得了显著突破.一张图给大家看懂Qwen3

1.登录启智平台
https://openi.pcl.ac.cn/
输入账号和密码登录
登录后我们进入启智平台云脑任务界面,下面是我之前测试的列表,大家不用管。
2.创建云脑任务
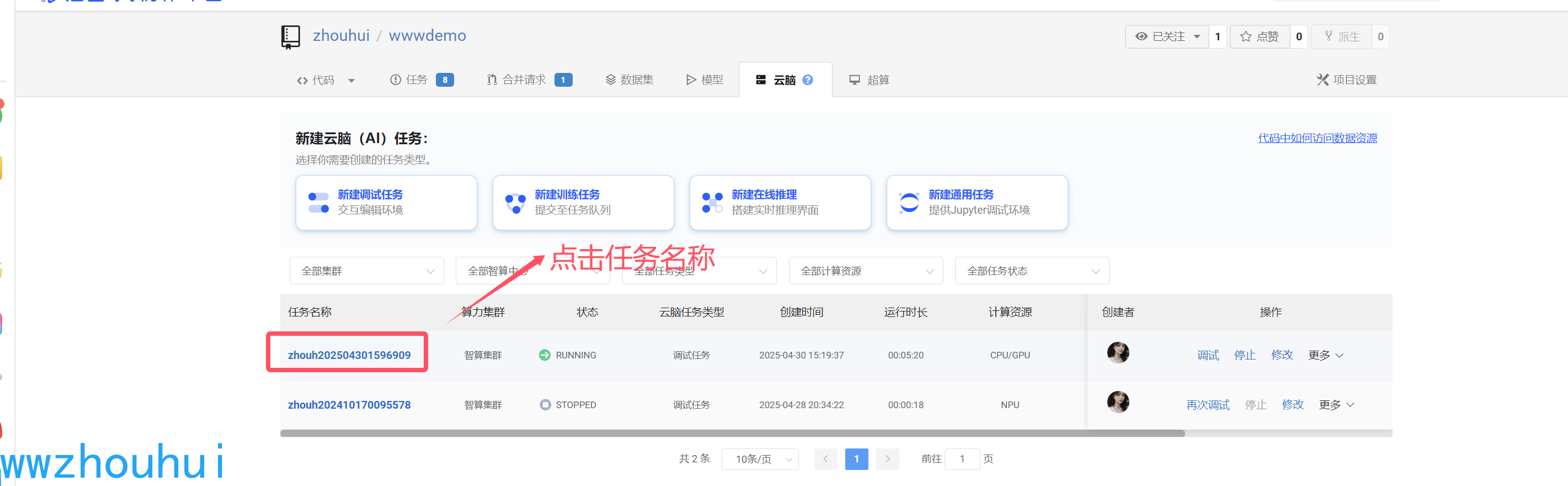
点击右上角“新建云脑任务”
进入创建云脑任务,我们选择一个项目(这块可以提前新建一个项目,项目里面可以为空 就像github里面创建一个空项目类似),点击下一步
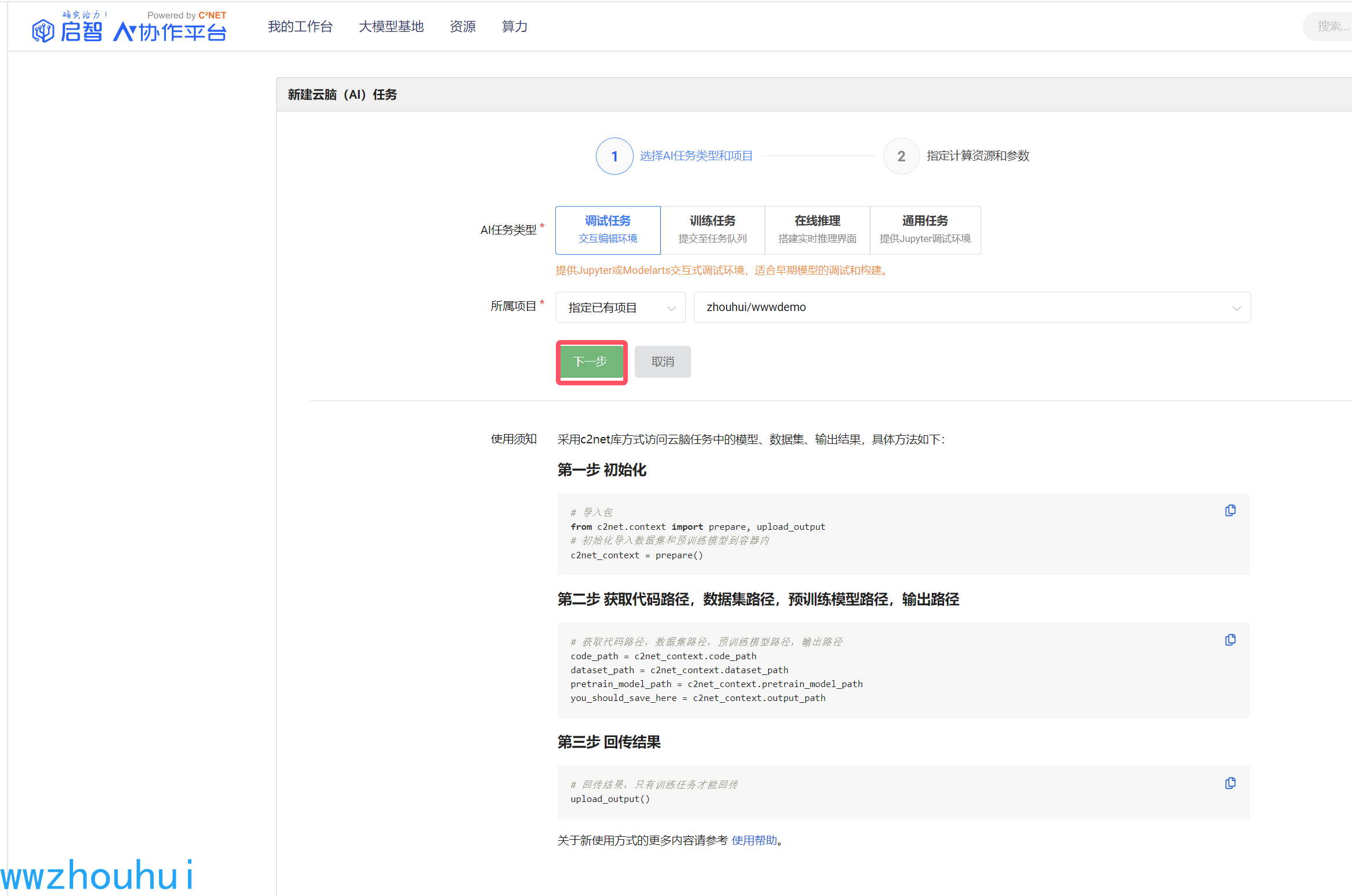
进入设置调试任务,我们选择计算资源,启智平台目前提供多种算力(英伟达、华为昇腾、燧原、寒武纪、海光、天数智芯、沐曦GPGPU),这里面我们先选择英伟达,显卡资源我们选择A100
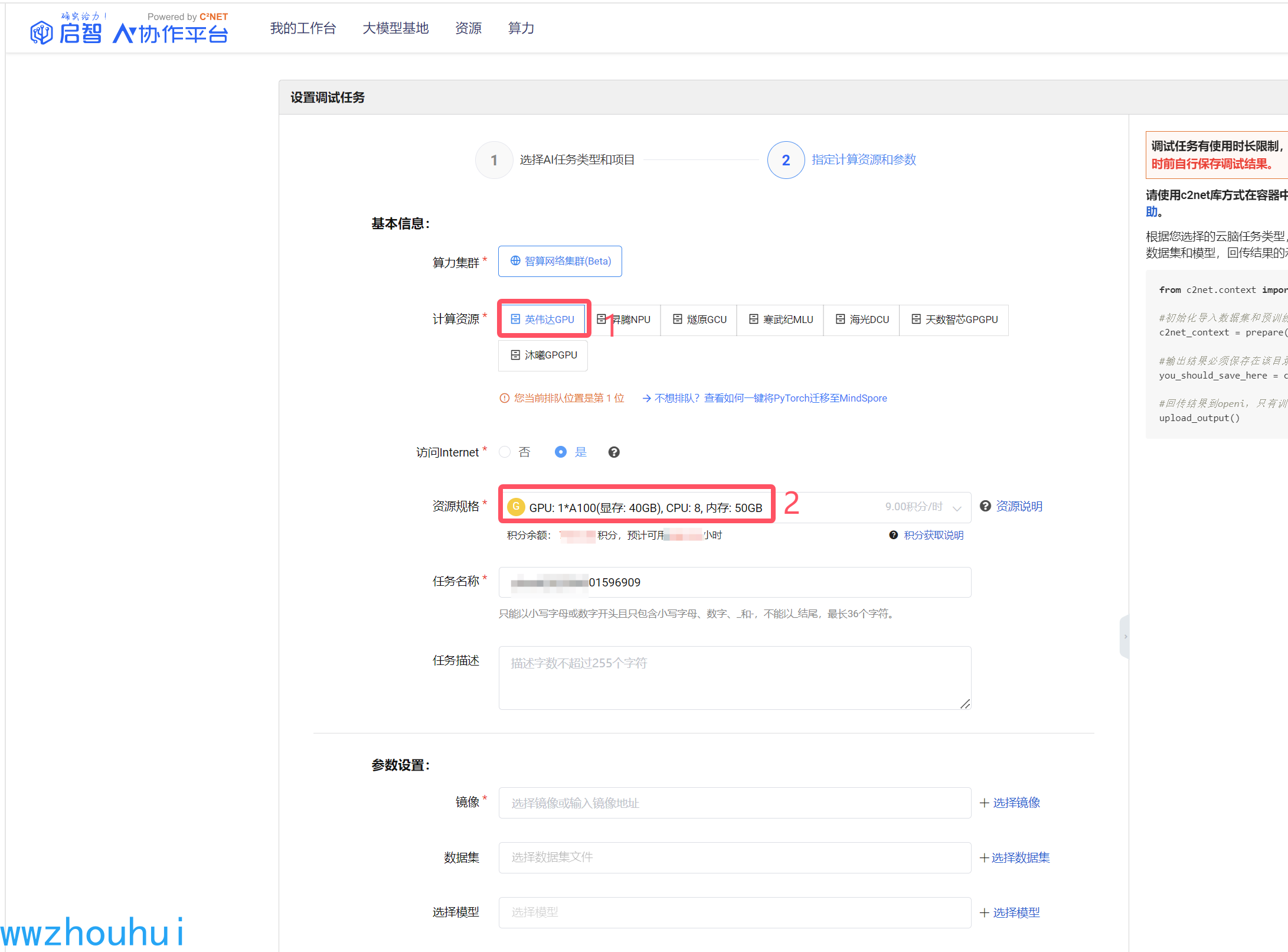
接下来我们选择镜像、数据集、选择模型这块。
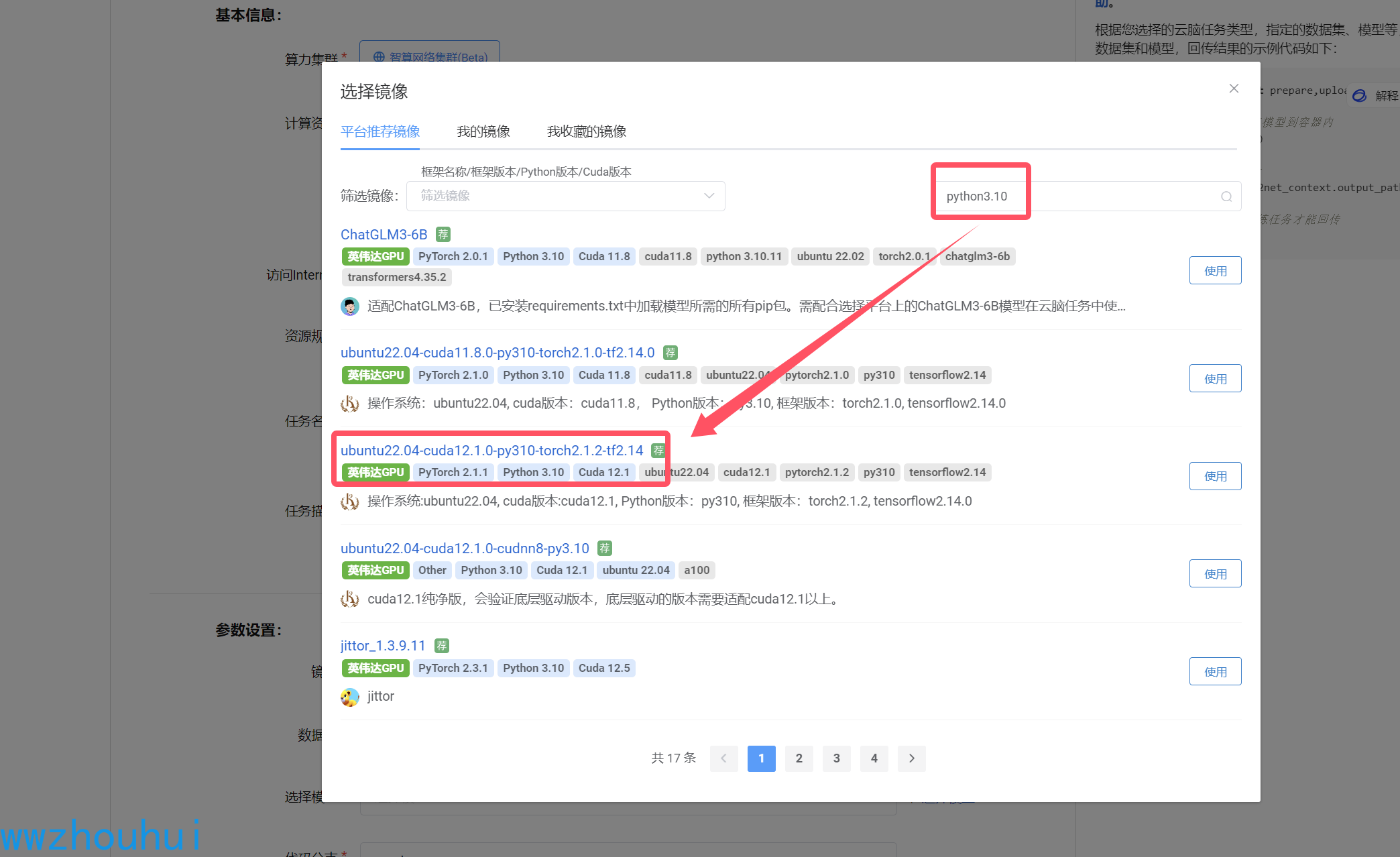
镜像我们输入检索python3.10 ,选择 ubuntu22.04-cuda12.1.0-py310-torch2.1.2-tf2.14
数据集我们先空着。
模型这里我们我们从平台上公开模型中选择qwen3-4B模型
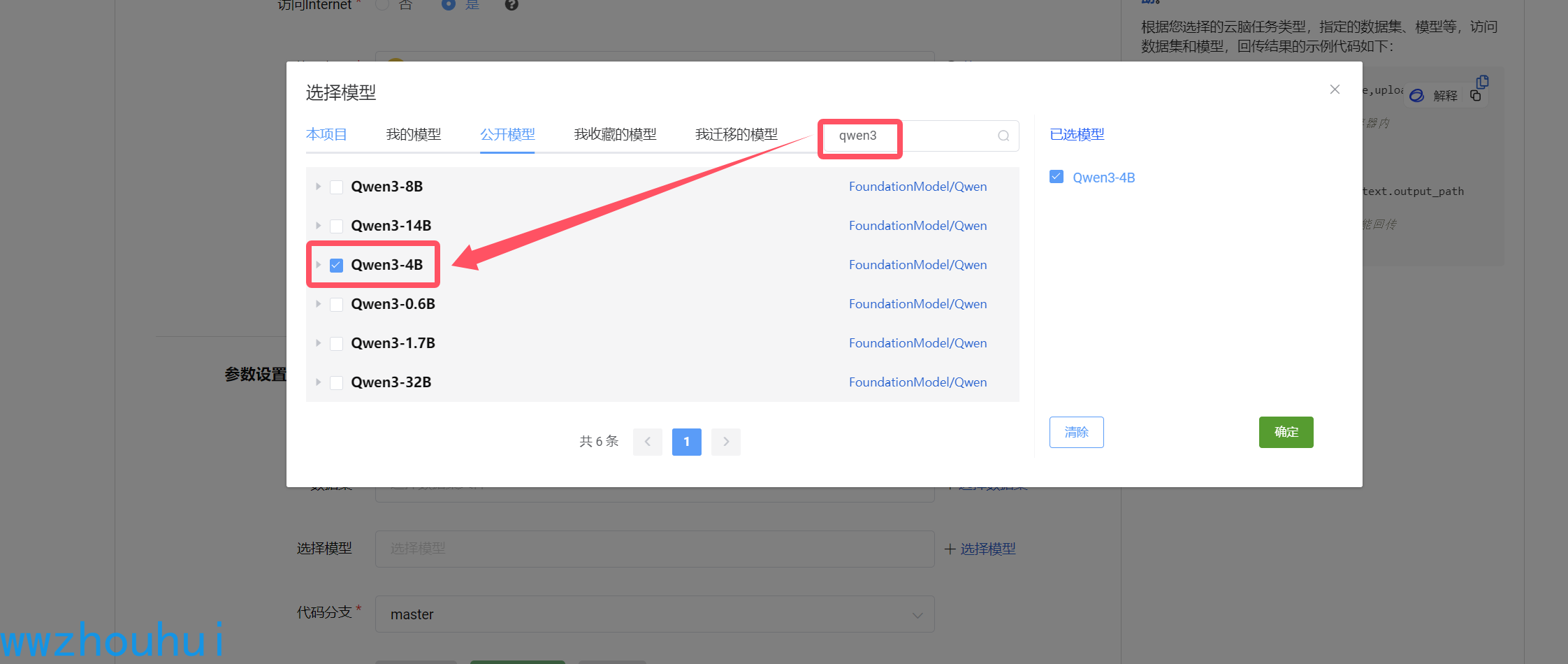
以上设置完成后,我们点击新建任务。等待服务器创建和分配资源。
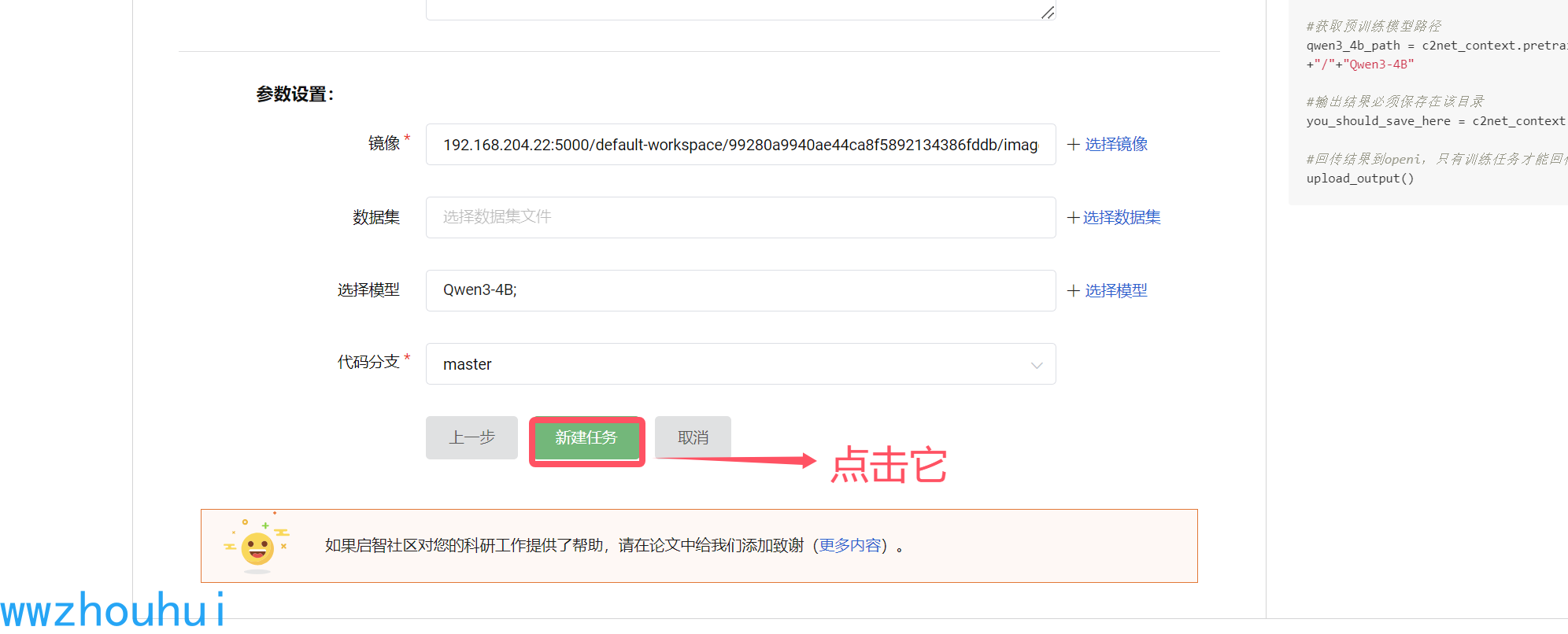
资源分配完成后我们看到如下列表,看到资源running状态,后面有一个调试按钮,后面就可以进入代码调试窗体界面了。
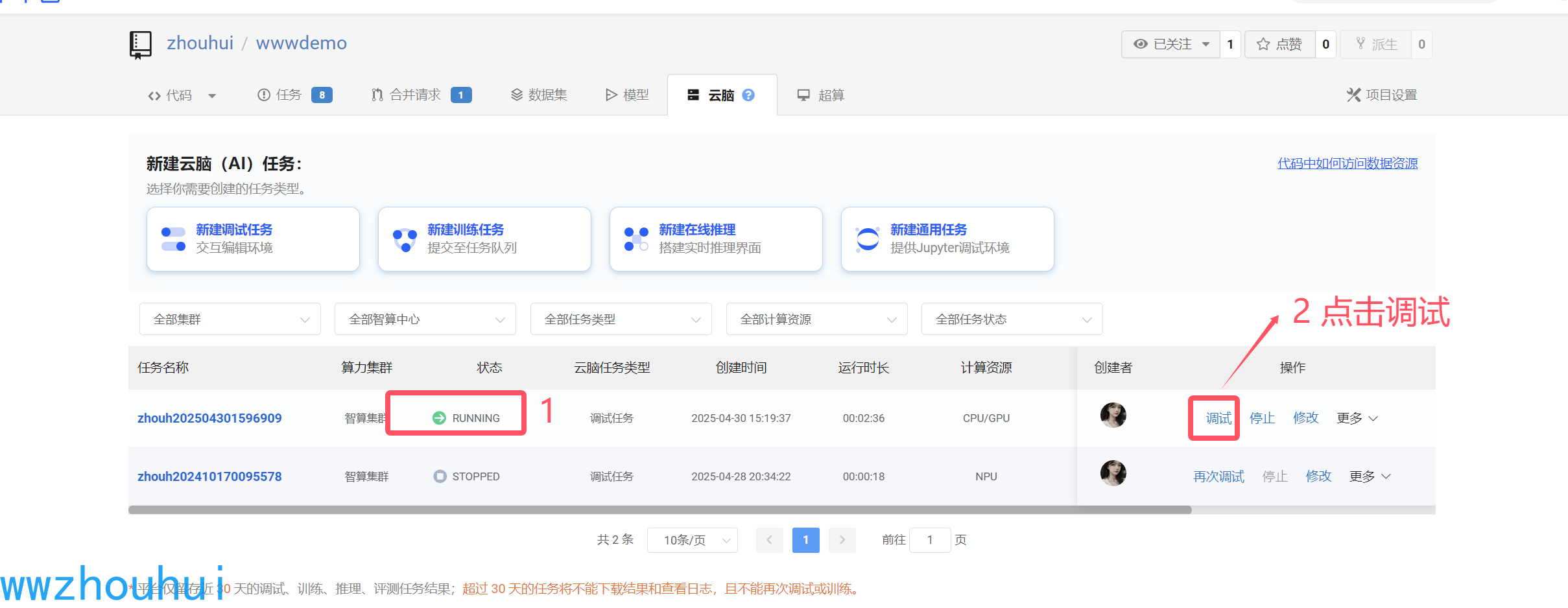
3.模型调试
我们点击调试按钮,进入jupyterlab 调试代码界面
3.1 检查挂载模型
这个时候模型挂载在哪个目录下呢?我们使用启智平台提供的c2net库访问方式,可以在启动界面找到挂载模型路径
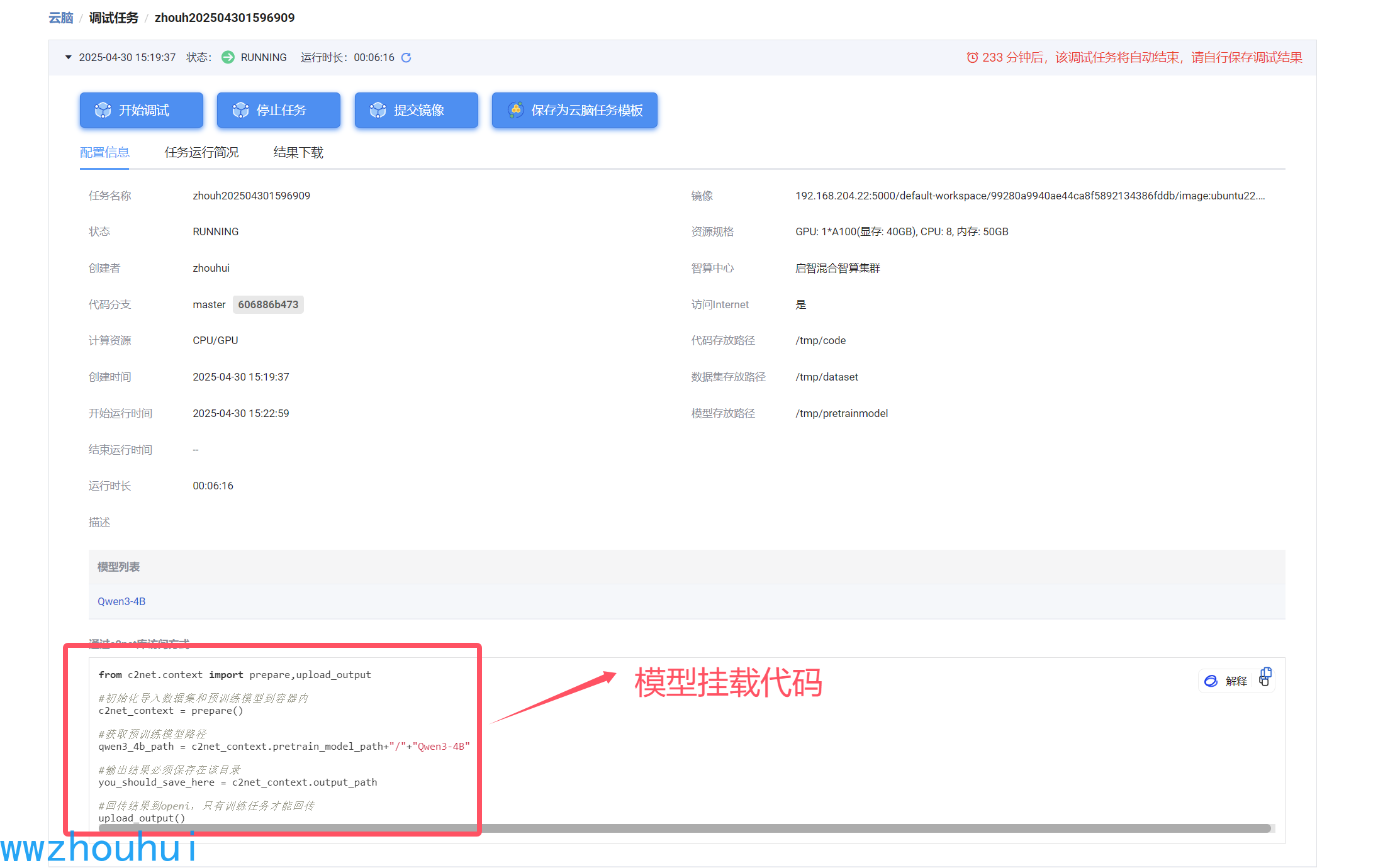
我们会看到图右上角 左边代码区/tmp/code、数据存储区域/tmp/dataset 模型存放区域/tmp/pretrainmodel 3 个文件夹,顾名思义,code 是放代码的;dataset放数据集的;pretrainmodel 就是模型挂载的目录。
我们进入pretrainmodel
cd /tmp/pretrainmodel

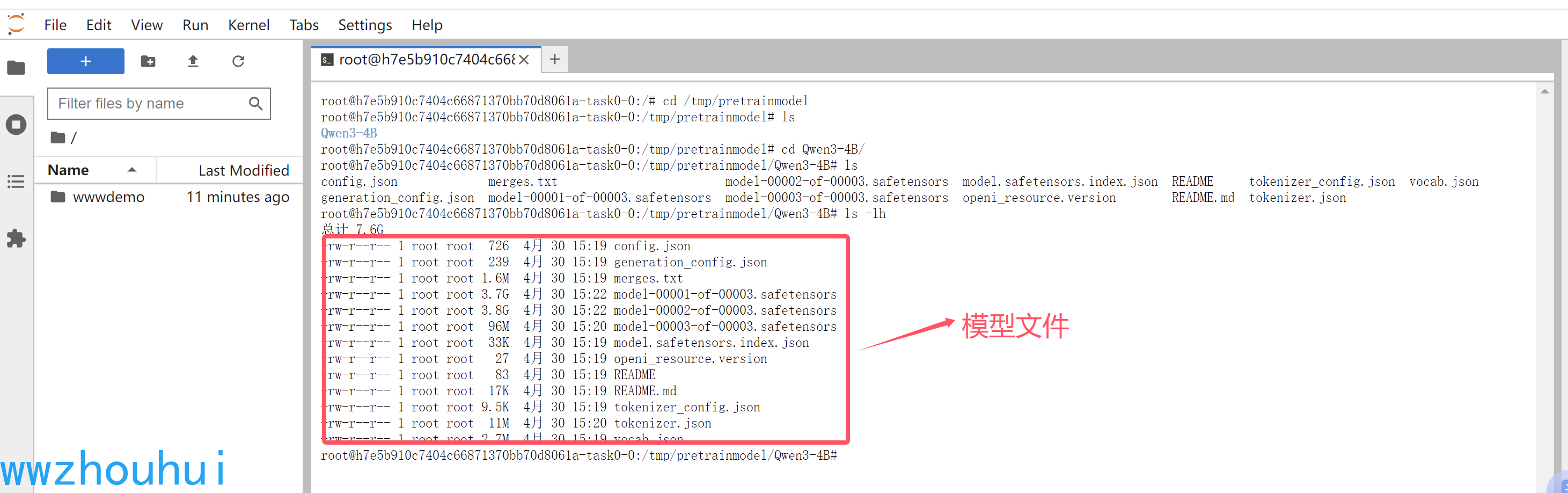
模型已经挂在到上面截图的目录了。
3.2 swift推理
3.2.1 swift推理框架安装
接下来我们需要再code 代码目录下面下载swift推理程序并安装。
cd /tmp/code
git clone https://github.com/modelscope/swift.git
# 如果网络慢可以使用下面代理
git clone https://ghfast.top//https://github.com/modelscope/swift.git
cd swift
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装完成后我们检查一下swift是否安装
pip show ms-swift
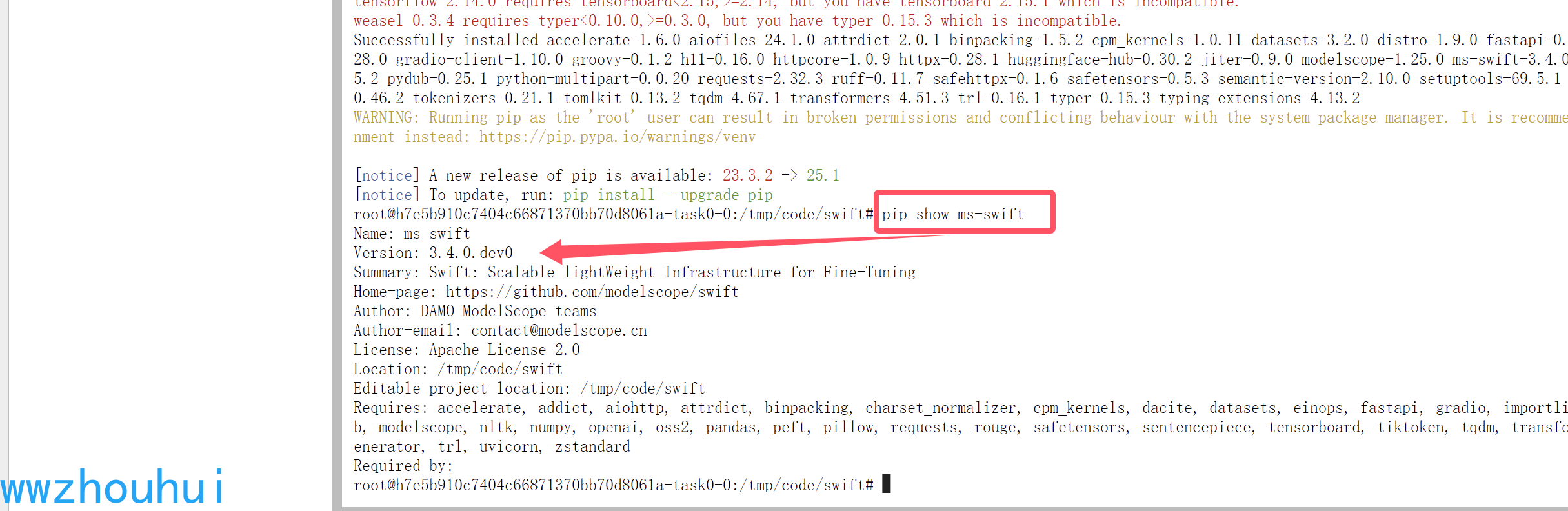
看到有个ms-swift 版本是3.4.0.dev0 版本号, 说明swift 框架已经安装完成。
3.2.2 模型复制
目前启智平台权限控制问题在/tmp/pretrainmodel/ 目录下是只读权限,我们在模型推理的时候需要读写模型文件,所以会到导致报错,所以我们把模型复制到/tmp/code/目录下,避免上述的错误,执行如下命令
cp -r /tmp/pretrainmodel/Qwen3-4B/ /tmp/code/
执行上述命令后,我们在/tmp/code 目录下看到Qwen3-4B
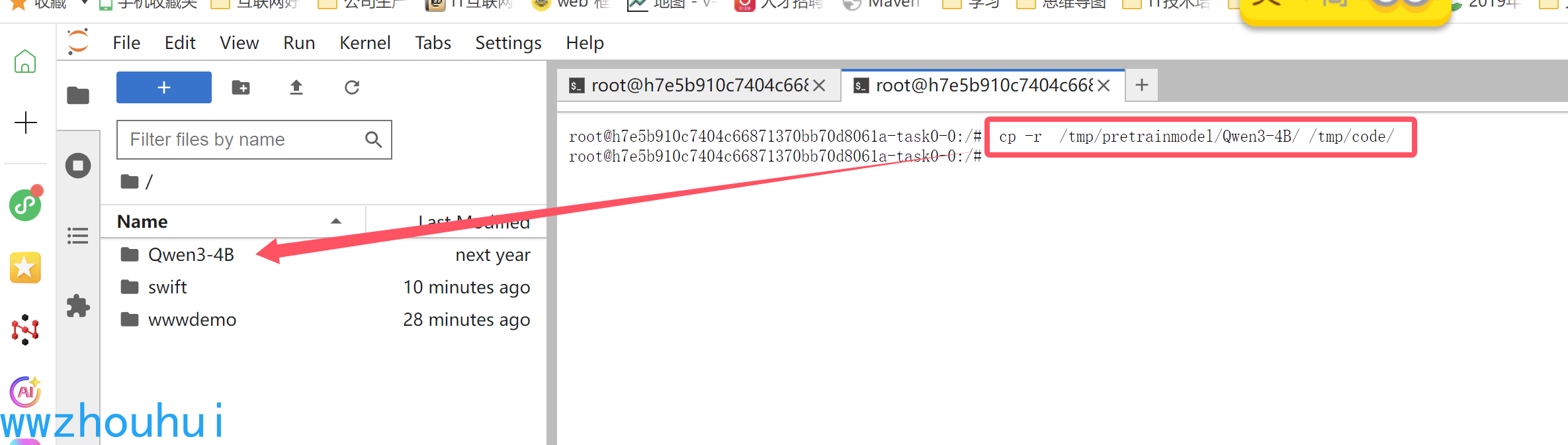
打开Qwen3-4B 可以看到模型文件列表
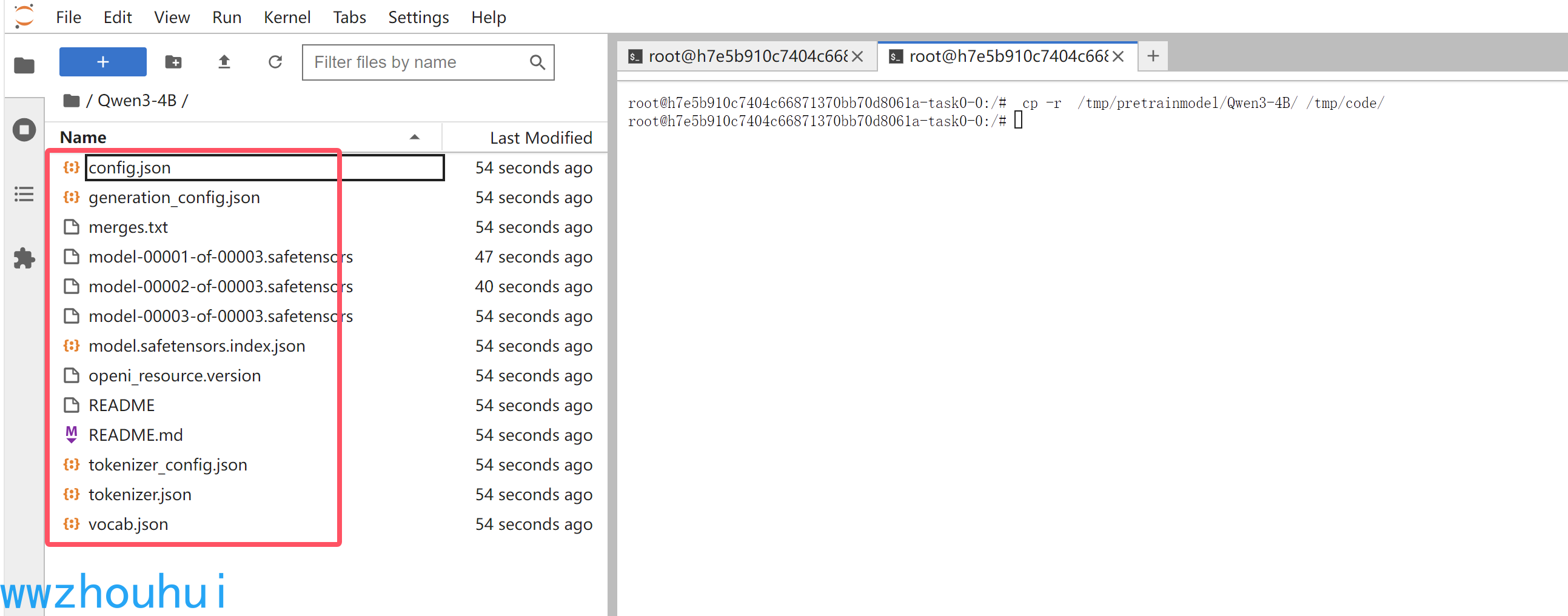
3.2.3 swift推理
swift infer --model_type qwen3 --model /tmp/code/Qwen3-4B --stream true
我们成功实现了模型推理
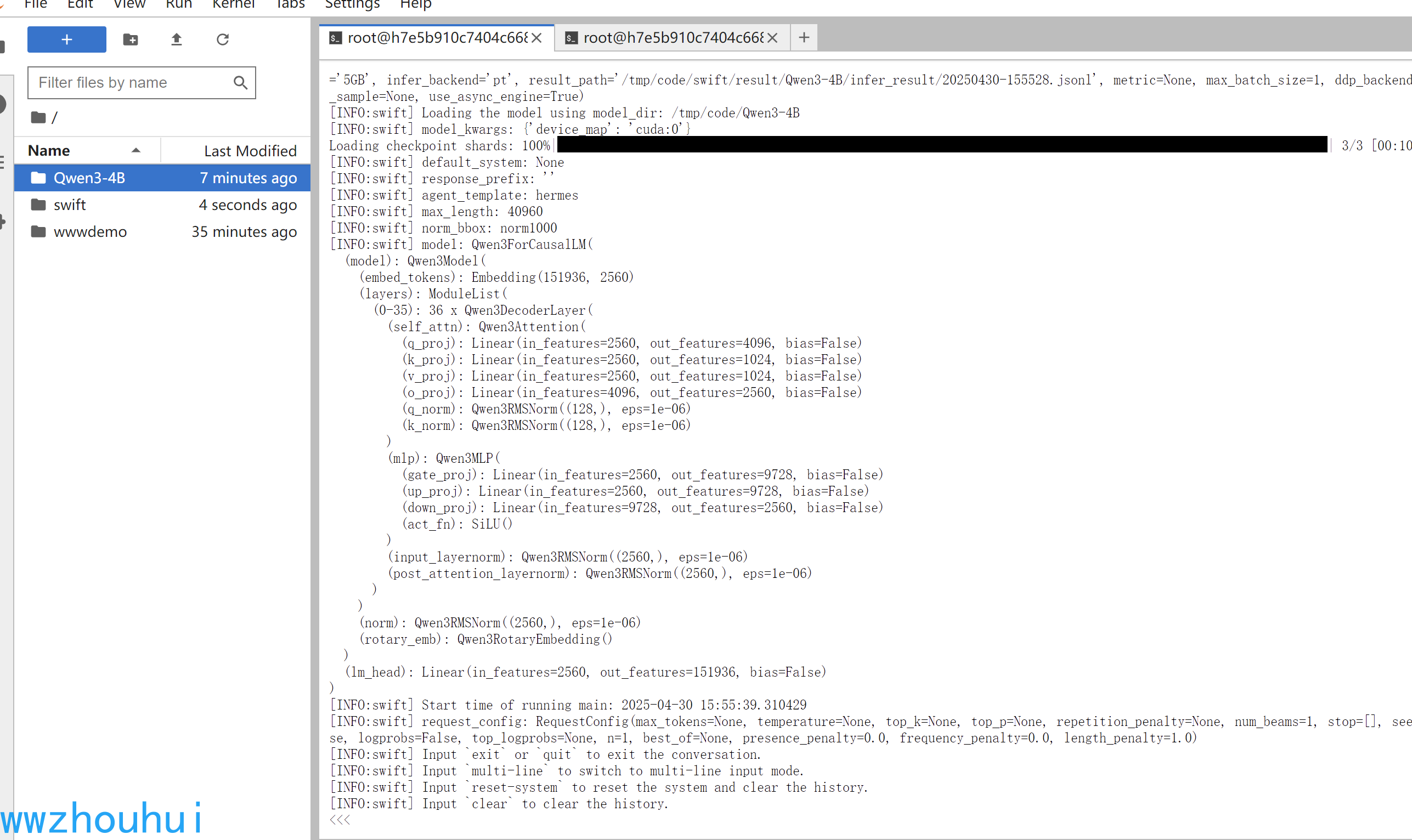
3.2.4 swift推理测试
我的问题
你好,你是谁?


这样我们就完成了模型在swift框架实现qwen3-4b模型的推理的。
3.3 模型微调
10分钟在单卡A100上对qwen3-4b进行自我认知微调:
命令行
# 22GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model /tmp/code/Qwen3-4B \
--train_type lora \
--dataset 'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 5 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--system '你是一个周辉小助手' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author zhouhui \
--model_name 周辉机器人
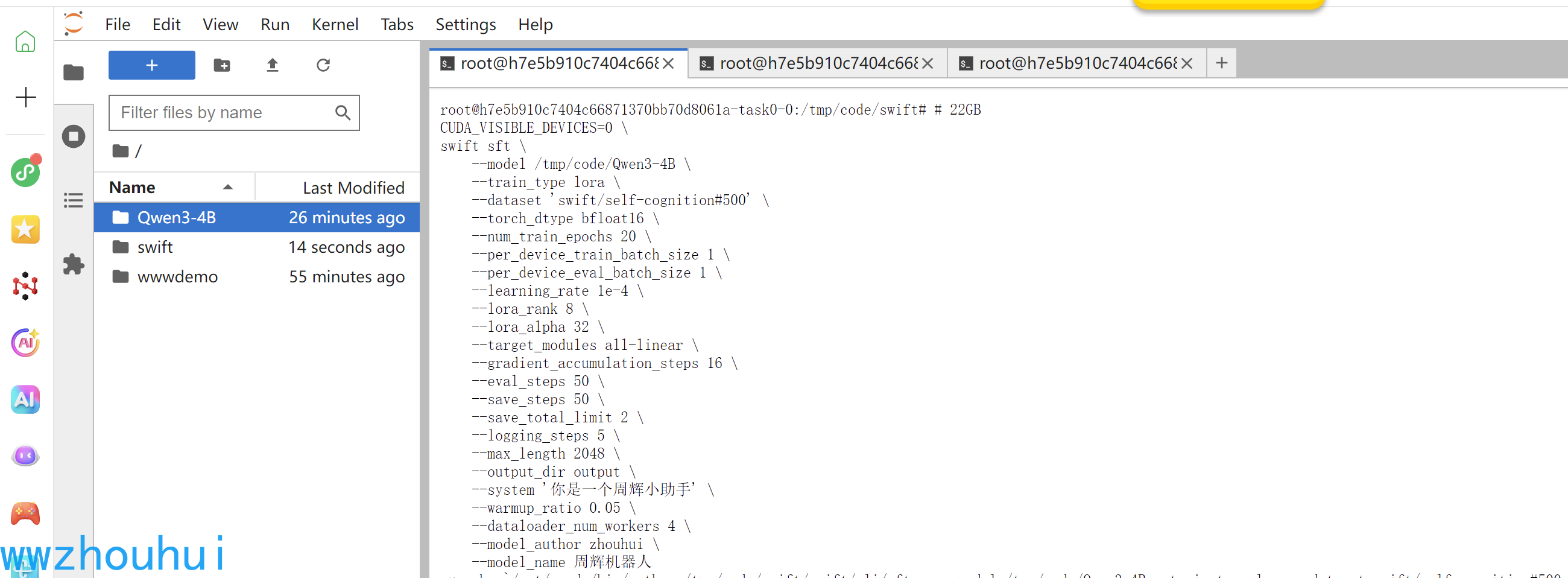
模型下载数据集后等待模型加载 后面就进入模型微调,这个时间会稍微有点长。等待即可。
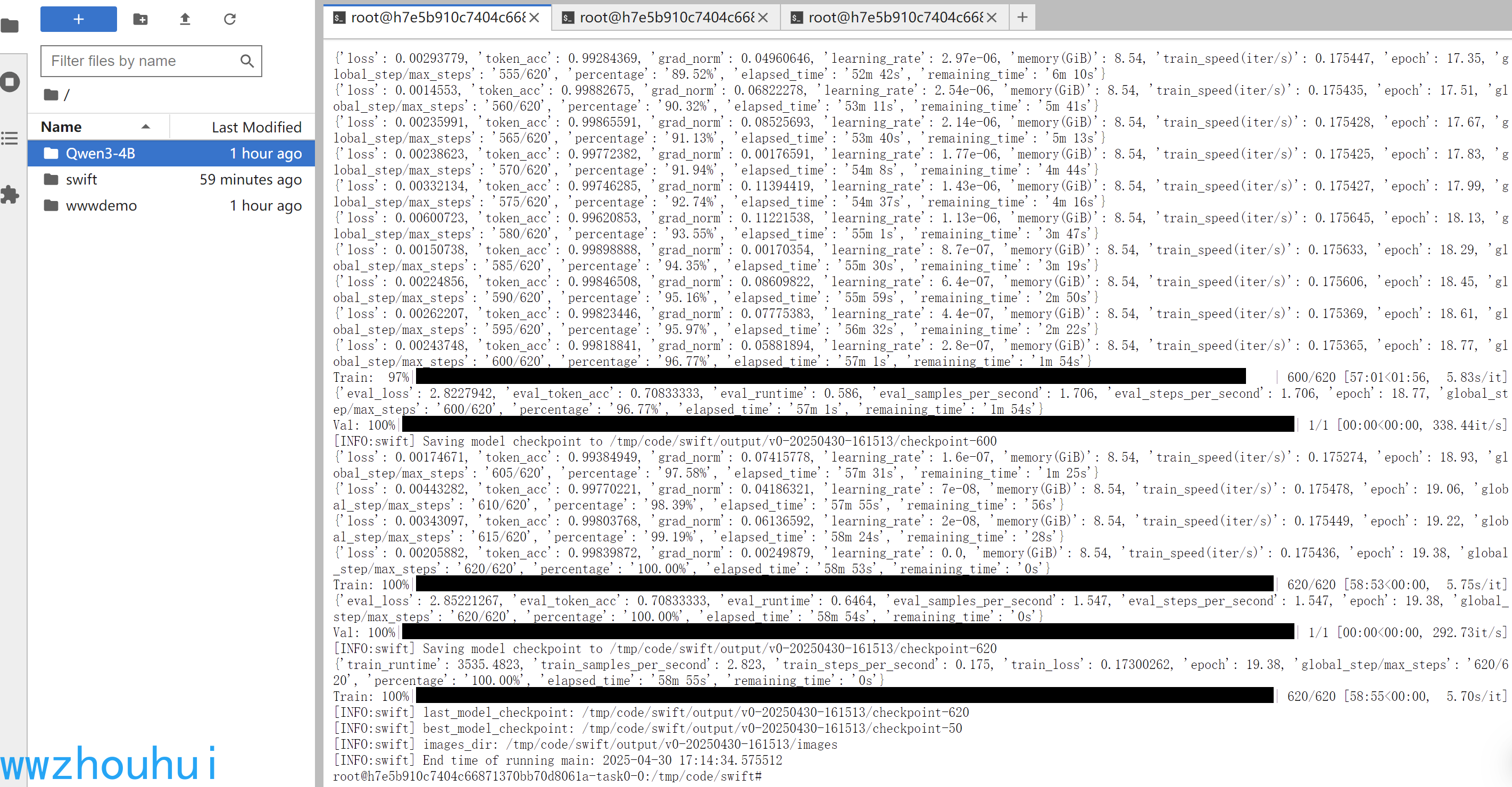
看到上面的训练结果,说明模型已经微调完成(我这个修改了num_train_epochs 导致训练时间过长)
我们看一下微调的模型权重输出在 tmp/code/swift/output/v0-20250430-161513/checkpoint-620
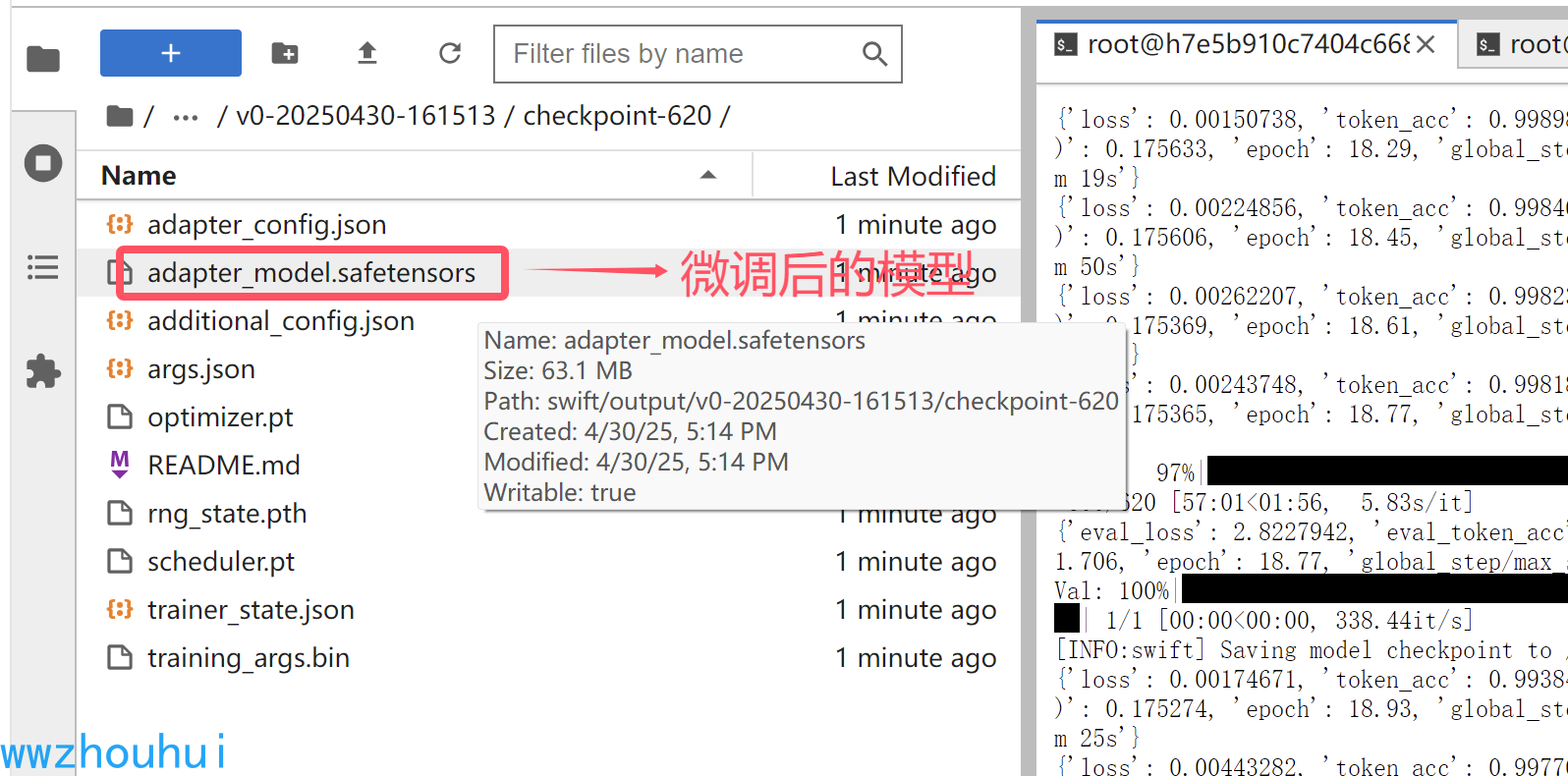
接下来我们验证一下。
# 使用交互式命令行进行推理
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters /tmp/code/swift/output/v0-20250430-161513/checkpoint-620 \
--stream true \
--temperature 0 \
--max_new_tokens 2048
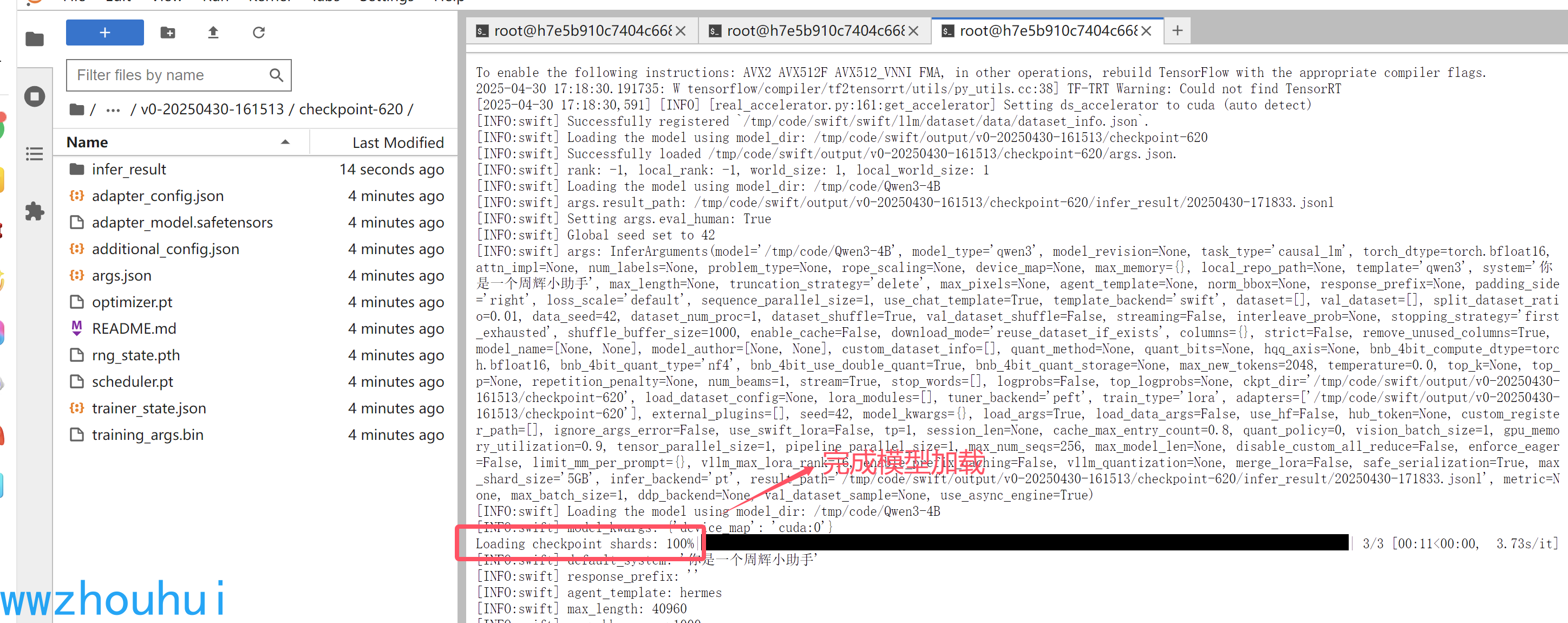
我们的问题
你好,你是谁?


以上我们就完成了一个简单的模型微调了,把qwen3模型改成增加的模型名称了。当然只是把它名字给该了,其他都没有动。
4.总结:
本次我们在利用启智平台提供的免费的算力,使用了英伟达A100显卡,使用阿里swift 推理框架实现了Qwen3-4B模型的推理和微调。关于模型的能力这块,因为网上一定有很多人对它进行测评,我这里就不过多介绍了。咱们介绍它如何实现推理,如果实现微调(偏技术一点)本次阿里推出了Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B、Qwen3-32B、 以及Qwen3-30B-A3B、Qwen3-235B-A22B。因为时间关系这里每个模型没办法一一测试。 感兴趣的小伙伴可以按照我文档中将8B及以下模型实现推理部署。今天分享就到这里,感兴趣小伙伴可以留言、点赞、收藏加关注。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)