EMNLP2025 | SpecVLM无损加速视频语言大模型推理
SpecVLM首次提出“推测解码+词元剪枝”的新范式,将视频语言大模型推理过程的参数瓶颈和词元数量瓶颈统一到一个框架下进行联合优化,同时揭示了视频语言大模型推测解码中草稿模型的独特性质。在降低草稿模型的开销之外,草稿模型的预测准确性也十分重要。一方面,在目标模型的预填充过程中,我们可以获取其对于视频内容的关注重点,来作为草稿模型保留词元的依据;的范式,这就导致每生成一个词元输出,就需要把完整的模型
近年来,视频语言大模型(Vid-LLMs)高速发展,在视频理解领域展现出愈发卓越的性能。想象一下,输入一段视频和一个文本问题,视频语言大模型便能够在空间和时间上全面理解视频的内容,并依照问题精确回答。这样强大的能力已经在视频描述、视频问答等任务中取得了惊人表现。
然而,视频语言大模型的效率问题成为阻碍其应用的关键。现有的视频语言大模型推理瓶颈主要集中在以下几个方面:一是巨量的视频词元(Token),现有模型完整编码一段几分钟的视频往往需要百万级别的词元数量,带来了推理过程中的极大计算开销;二是庞大的模型参数,为了提高视频理解模型的表现,SOTA模型的参数规模不断扩大,逐渐突破数十亿。而视频语言大模型的解码过程又遵循自回归的范式,这就导致每生成一个词元输出,就需要把完整的模型参数连同视频词元对应的KV Cache一起在GPU内容上进行加载和储存,大大增加了推理的延迟。

-
论文:SPECVLM: Enhancing Speculative Decoding of Video LLMs via Verifier-Guided Token Pruning
-
链接:https://arxiv.org/abs/2508.16201
-
代码:https://github.com/zju-jiyicheng/SpecVLM
本篇论文提出的SpecVLM技术,就是旨在解决视频语言大模型应用中以上两个方面的瓶颈。它首次引入大语言模型领域的推测解码(Speculative Decoding)技术,并在此基础上设计了一种目标模型指导的词元剪枝方案(Verifier-Guided Token Pruning),能够大大降低视频语言大模型解码过程的延迟,同时完全保证输出质量无损。实验表明,SpecVLM在多个视频理解基准、多种模型组合上实现了高达2.68倍的解码加速。

背景和动机:现有加速方案的局限性
现有的视频语言大模心推理加速方法通常直接对目标模型采用词元剪枝(Token Pruning),尽可能在损失更少模型表现的前提下减少视频上下文的长度。然而,这样加速同时伴随着固有的局限性:首先是生成质量的下降,且随着剪枝比率的增加越发明显,尤其在需要细粒度视频信息时空语义的场景下更是如此;其次是解码加速的收益低,现有技术往往忽略了针对解码阶段的加速,无法缓解视频语言大模型在参数上的瓶颈。
本文指出,通过引入一个专门为视频语言大模型设计的“推测解码+词元剪枝”框架,可以从根本上解决上述局限,探求更高的性能边界。
核心洞察:草稿模型(Draft Model)对剪枝的低敏感性质
本文提出了两个核心洞察:
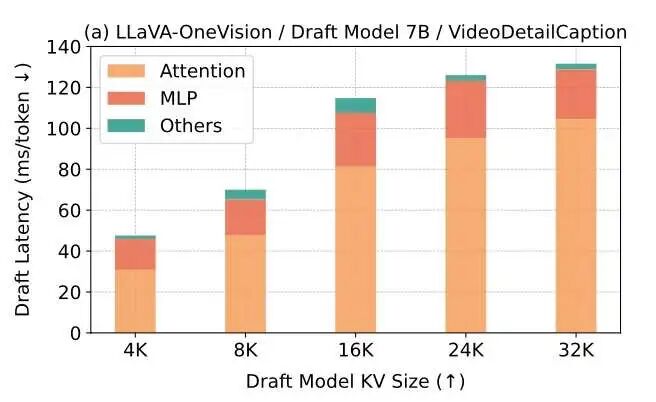
1、影响草稿模型的性能瓶颈
简单来说,推测解码技术旨在设计一种高效的草稿模型,来预测要加速的目标模型的输出,然后通过目标模型一次并行的验证接受多个词元输出,以此获得端到端延迟的减少。在这个过程中,草稿模型的轻量化尤其重要。本文通过理论和实验说明了推测解码在视频语言大模型场景下:
-
草稿模型的开销主要由参数(体现在MLP)和输入(体现在注意力计算)两方面组成;
-
随着输入视频长度增加,草稿模型的瓶颈逐渐从参数转移到输入上,上下文长度逐渐主导了开销
这为我们提供了一个直观的insight:通过词元剪枝(Token Pruning)技术来为草稿模型剪枝,可以大大提高草稿模型的效率。
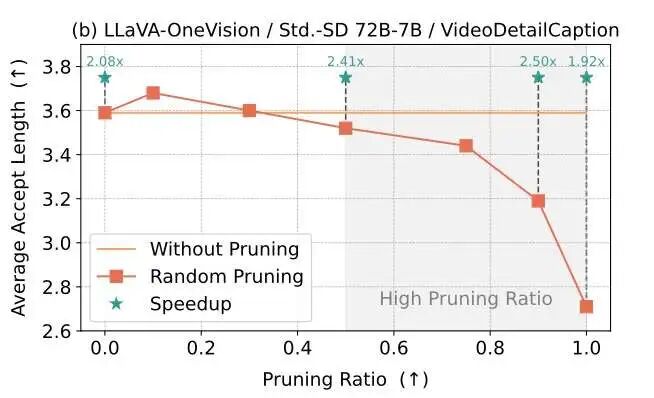
2、草稿模型对剪枝的低敏感性
在降低草稿模型的开销之外,草稿模型的预测准确性也十分重要。如果为草稿模型进行剪枝,尽管开销是减少了,但是会潜在降低草稿模型的预测准确性。为了系统研究这一问题,本文设计了一个实验验证:通过随机词元剪枝,观察不同剪枝率下草稿模型的预测准确性。可以发现:
-
在低剪枝率下,草稿模型对于剪枝并不敏感,其预测的平均接受长度没有显著降低;
-
在高剪枝率下,草稿模型开始出现预测准确率下降的问题;
上述实验为方法设计铺平了道路:能够利用草稿模型的上述性质,设置一个合适的剪枝率,在大大减少草稿模型输入长度的同时保证其预测准确性?这就是SpecVLM提出“推测解码+词元剪枝”的出发点。
方法设计:二阶段草稿模型词元剪枝技术
基于以上先导研究,SpecVLM提出了目标模型指导的词元剪枝技术。一方面,在目标模型的预填充过程中,我们可以获取其对于视频内容的关注重点,来作为草稿模型保留词元的依据;另一方面,这种设计可以在草稿模型预填充之前先进行目标模型的预填充,使得草稿模型只需要填充剪枝后的词元。
阶段一:高信息词元的Top-P保留
本文还观察到,目标模型对于视频词元有着独特的注意力模式:
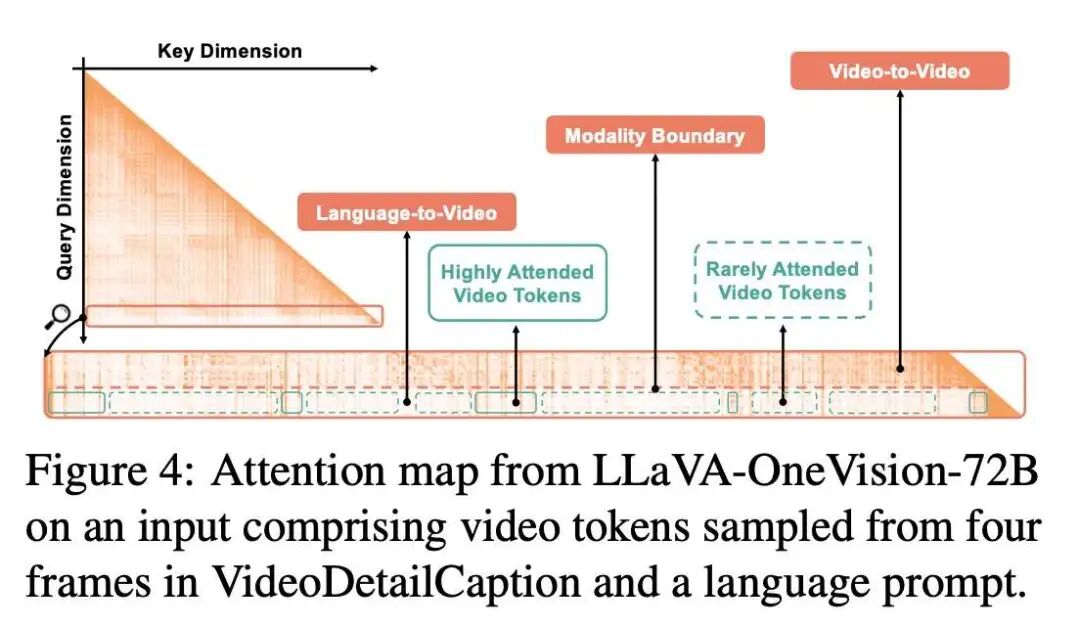
可以看到,如果选择注意力图中“文本对视频”的区域,这时的注意力模型是清晰、集中的。换言之,文本对部分视频词元展现出集中的关注,而对其他视频词元的注意力值则十分低,这为词元剪枝提供了十分有效的依据。
基于此,SpecVLM优先保留“文本对视频”注意力高所对应的视频词元,直到这部分保留的词元注意力之和达到一定的阈值。
阶段二:低信息词元的空间均匀剪枝
然而,由于视频编码对应的词元数目过于庞大,往往极少的词元占据了很大的注意力权重,体现出一种长尾分布:
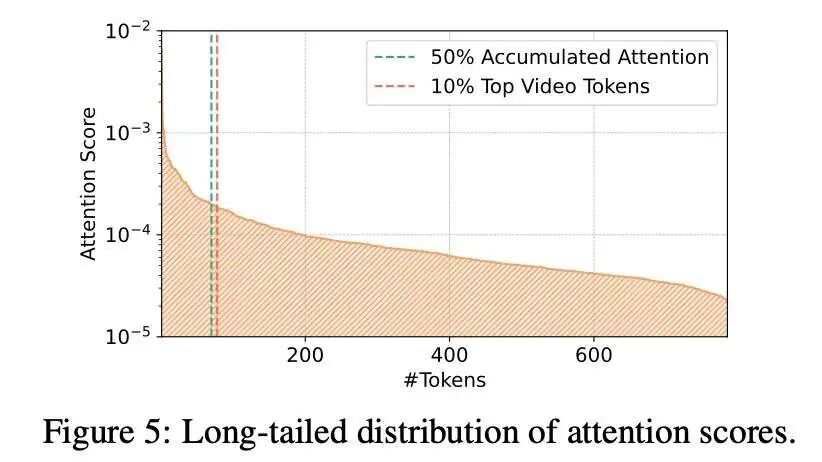
这就导致,如果只按照注意力来保留词元,实际保留的后半部分已经是注意力很低的部分,并没有区分度。为了缓解这个问题,SpecVLM做了一个补充:在阶段一保留部分高注意力词元之后,不再继续根据注意力选择,而是在空间上均匀地选择剩余词元,来得到最终剪枝率下的词元组合。这种方式还能够潜在保证视频的整体空间信息结构得到保留,避免注意力的偏好(bias)等问题。
实验结果与分析
实验设置:模型、基准与基线
-
模型:LLaVA-OneVision和Qwen2.5-VL系列
-
基准:使用4个视频理解数据集(VideoDetailCaption等)来进行视频描述
-
基线:普通自回归推理、朴素的推测解码、随机剪枝+推测解码等
实验设置:推测解码设置
为了更加全面的评估与应用,本文设计了两种推测解码设置,对应不同的使用场景:
-
标准推测解码(Std-SD):使用同系列小模型作为草稿模型来加速大模型,缓解参数瓶颈,获取更高的加速收益;
-
自推测解码(Self-SD):使用词元剪枝后的模型自身来作为草稿模型,无需引入额外模型;
主实验结果:全面提高解码速度
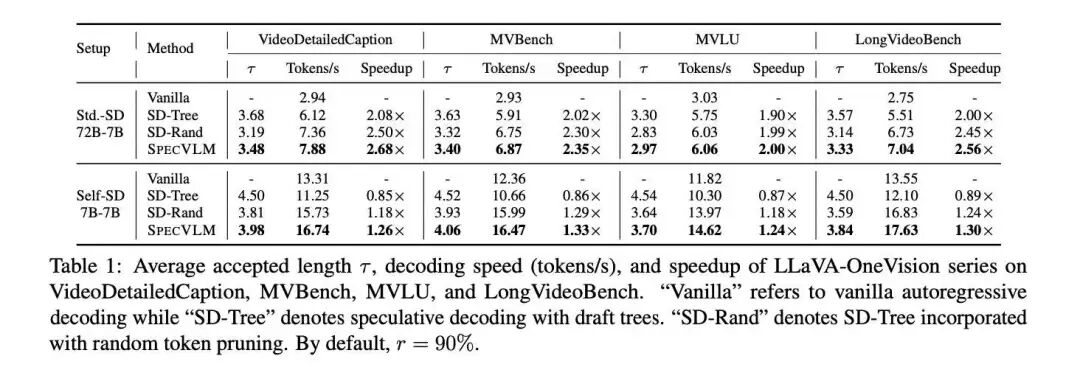
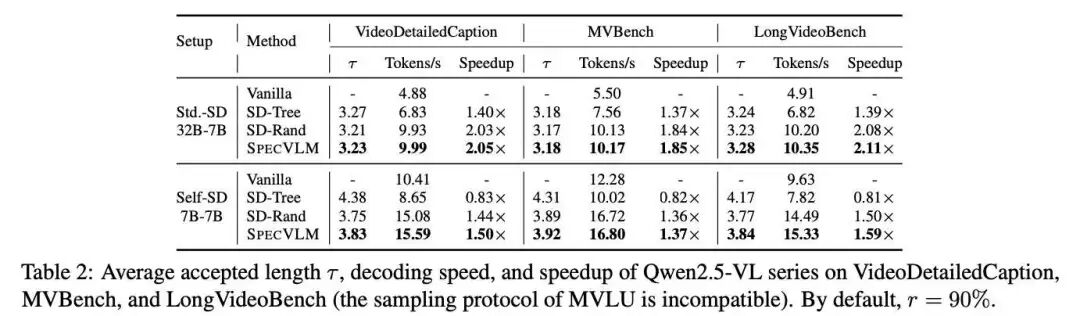
SpecVLM在多个基准上展现了卓越的加速比,尤其在LLaVA-OneVision-72B / 7B的设置上,获得了高达2.68倍的加速收益。除此之外,SpecVLM与随机剪枝策略、朴素推测解码策略的对比也说明了SpecVLM剪枝策略的高效。
消融实验:
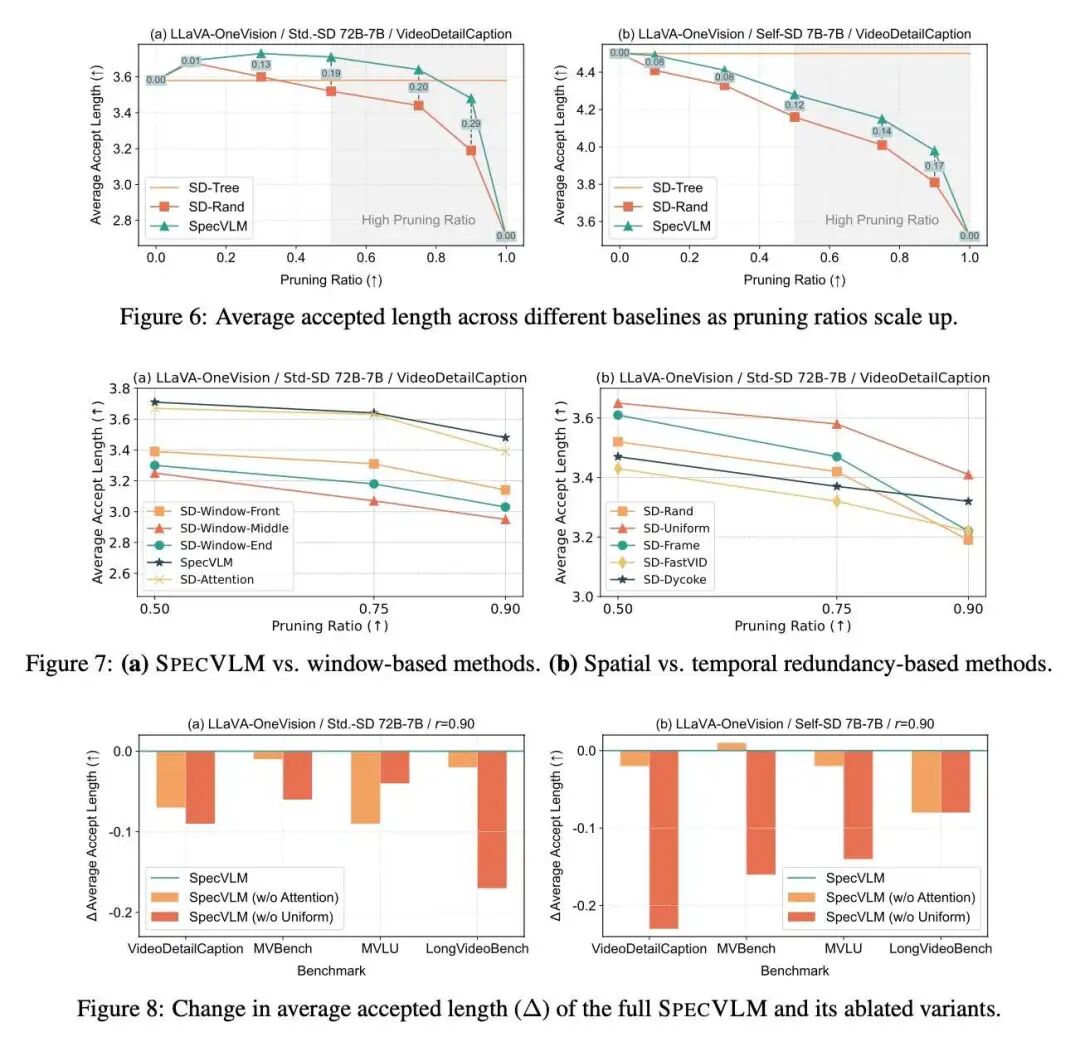

本文进行了全面的消融实验来验证方法的有效性。具体而言,本文依次实验了:
-
不同剪枝率下SpecVLM草稿模型的预测准确度;
-
不同的剪枝策略的对比(滑动窗口、时间均匀剪枝等);
-
二阶段剪枝的各自消融实验
-
不同解码步骤的接受率变化
通过全方位的评估,证明了SpecVLM的性能高效性、词元剪枝策略的有效性。
讨论
SpecVLM首次提出“推测解码+词元剪枝”的新范式,将视频语言大模型推理过程的参数瓶颈和词元数量瓶颈统一到一个框架下进行联合优化,同时揭示了视频语言大模型推测解码中草稿模型的独特性质。未来工作可以探索如何进一步减小草稿模型的参数量,来寻求更加极致的加速比。
结论
本论文提出一种针对视频语言大模型的无损推理加速方案。其贡献总结如下
-
首次提出针对视频语言大模型的推测解码范式,将推测解码与词元剪枝技术深度融合;
-
揭示了草稿模型对于词元剪枝的低敏感性质,通过二阶段剪枝剪去90%的词元,同时依旧保持预测的准确性;
-
实验测试证明,SpecVLM能够无损地为视频语言大模型提供高达2.68倍的解码加速,拓宽了其性能边界。



魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 9
9 0
0- 0



 已为社区贡献134条内容
已为社区贡献134条内容

所有评论(0)