阿里云 大模型高级工程师 ACP 认证 通关 01
○ 使用Multi-Agent进行文本、图像、视频等多模态内容生产。○ 使用阿里云百炼平台构建大模型应用(开发、测评、部署、发布)○ 使用提示词策略、检索增强、微调技术优化大模型回答质量。○ 能够针对复杂业务场景设计并实施大模型驱动的解决方案。○ Llama-Index的使用方法。○ 检索增强和微调的原理和流程。○ 工程化评测的概念与方法。○ 大模型的规范和安全性。○ 大模型提示词技巧。
通过认证你将获得:
● 掌握以下知识与技能:
○ 大模型提示词技巧
○ 检索增强和微调的原理和流程
○ Llama-Index的使用方法
○ 工程化评测的概念与方法
○ 大模型的规范和安全性
● 有能力完成以下任务:
○ 使用阿里云百炼平台构建大模型应用(开发、测评、部署、发布)
○ 使用提示词策略、检索增强、微调技术优化大模型回答质量
○ 使用Multi-Agent进行文本、图像、视频等多模态内容生产
○ 能够针对复杂业务场景设计并实施大模型驱动的解决方案
课程列表
参考: https://edu.aliyun.com/course/3130200/lesson/343170892?spm=a2cwt.28196072.ACP26.5.1a4a37f0v0sPLc
环境准备
交互式建模(DSW - Data Science Workshop)
● 资源规格:推荐选择免费试用页签中的ecs.g6.xlarge。
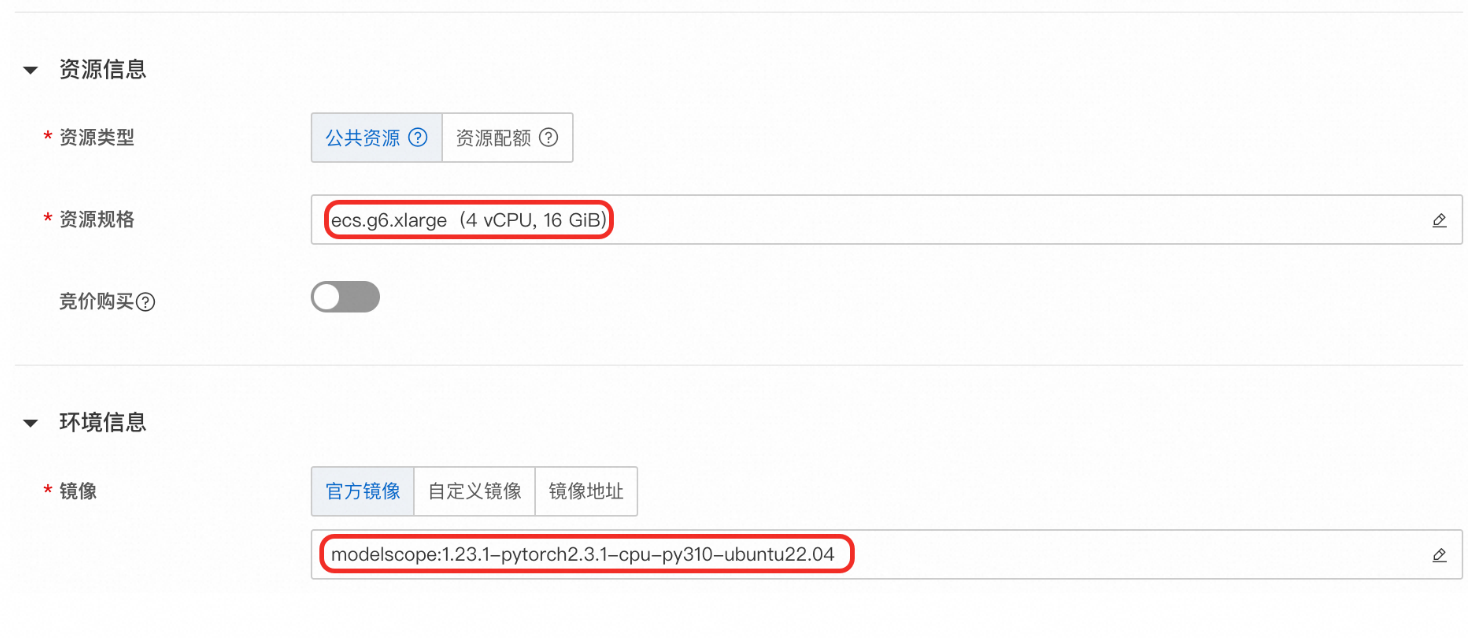
欢迎来到PAI-DSW,你将迎来一段奇妙的代码体验。这是一款云端机器学习开发IDE,集成了开源JupyterLab,并以插件化的形式进行深度定制化开发。您无需任何运维配置,即可进行Notebook编写、调试及运行Python代码。同时,PAI-DSW提供丰富的计算资源,且对接多种数据源。
通过EASCMD的方式,可以将PAI-DSW获得的训练模型部署为RESTful接口,对外提供模型服务,从而实现一站式机器学习。
检查环境的Python版本和路径。

自动安装
wget https://developer-labfileapp.oss-cn-hangzhou.aliyuncs.com/ACP/aliyun_llm_acp_install.sh
/bin/bash aliyun_llm_acp_install.sh
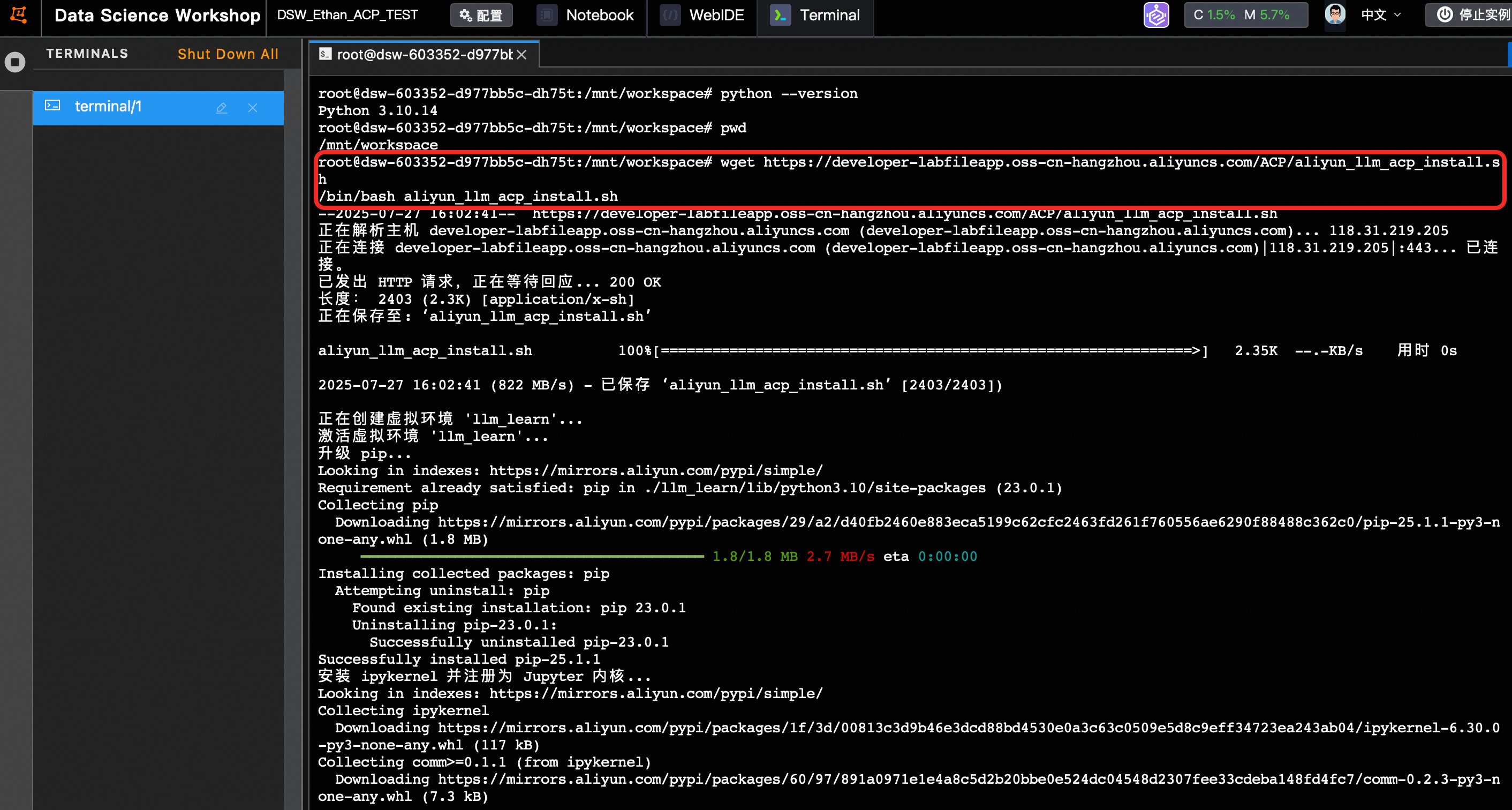
llm_learn环境注册成功
如果自动安装有问题,可以尝试手动安装方式:
git clone https://github.com/AlibabaCloudDocs/aliyun_acp_learning.git
Terminal执行如下命令安装环境所需要依赖
通过 venv 模块创建名为 llm_learn 的python虚拟环境 python3 -m venv llm_learn
/创建一个llm_learn的虚拟环境,不同项目可能依赖环境不同,这样能做到环境隔离/
进入 llm_learn 虚拟环境 source llm_learn/bin/activate在虚拟环境中更新pip pip install --upgrade pip
安装 ipykernel 内核管理工具 pip install ipykernel
将 llm_learn 添加至 ipykernel 中 python -m ipykernel install --user --name llm_learn --display-name “Python (llm_learn)”
在 llm_learn 环境中安装代码执行的依赖 pip install -r ./aliyun_acp_learning/requirements.txt
退出 llm_learn 虚拟环境 deactivate
切到notebook查看认证学习材料。
项目背景:
你在一家教育内容开发公司工作,随着新员工的持续加入,频繁的答疑需求导致了显著的时间与资源成本。
传统知识问答机器人:主要基于固定规则以及相似度判断的机制,使得当员工使用不同问法时,系统可能无法回答问题。 此外,人工配置问答对的工作量也很大,投入产出比很低。
技术方案:
利用时下最先进的大模型技术来构建一个智能问答的应用。基于大模型的智能应用能够很好地理解人类语言,无需配置问答对也可以基于公司内部知识库来准确回答问题,将真正有效地减少员工咨询量,提高工作效率。
2.1 用大模型构建新人答疑机器人
加载百炼的 API Key 用于调用通义千问大模型
下面的代码会从配置文件中加载你的 API Key,并将其设置为环境变量
import os
from config.load_key import load_key
load_key()
print(f'''你配置的 API Key 是:{os.environ["DASHSCOPE_API_KEY"][:5]+"*"*5}''')
/**
你需要 “回车” 确认你的输入,输入成功后你会看到“ 你配置的 API Key 是:sk-88***** ” 的字样。
如果你需要更换 “API-KEY”,请编辑上一级目录的 “KEY.json” 文件。
如果你在使用VS-CODE,API-KEY的输入框会出现在窗体的顶部。**/
/**
load_key来源:
def load_key():
import os
import getpass
import json
import dashscope
file_name = '../Key.json'
if os.path.exists(file_name):
with open(file_name, 'r') as file:
Key = json.load(file)
if "DASHSCOPE_API_KEY" in Key:
os.environ['DASHSCOPE_API_KEY'] = Key["DASHSCOPE_API_KEY"].strip()
else:
DASHSCOPE_API_KEY = getpass.getpass("未找到存放Key的文件,请输入你的api_key:").strip()
Key = {
"DASHSCOPE_API_KEY": DASHSCOPE_API_KEY
}
# 指定文件名
file_name = '../Key.json'
with open(file_name, 'w') as json_file:
json.dump(Key, json_file, indent=4)
os.environ['DASHSCOPE_API_KEY'] = Key["DASHSCOPE_API_KEY"]
dashscope.api_key = os.environ["DASHSCOPE_API_KEY"]
if __name__ == '__main__':
load_key()
import os
print(os.environ['DASHSCOPE_API_KEY'])
*//
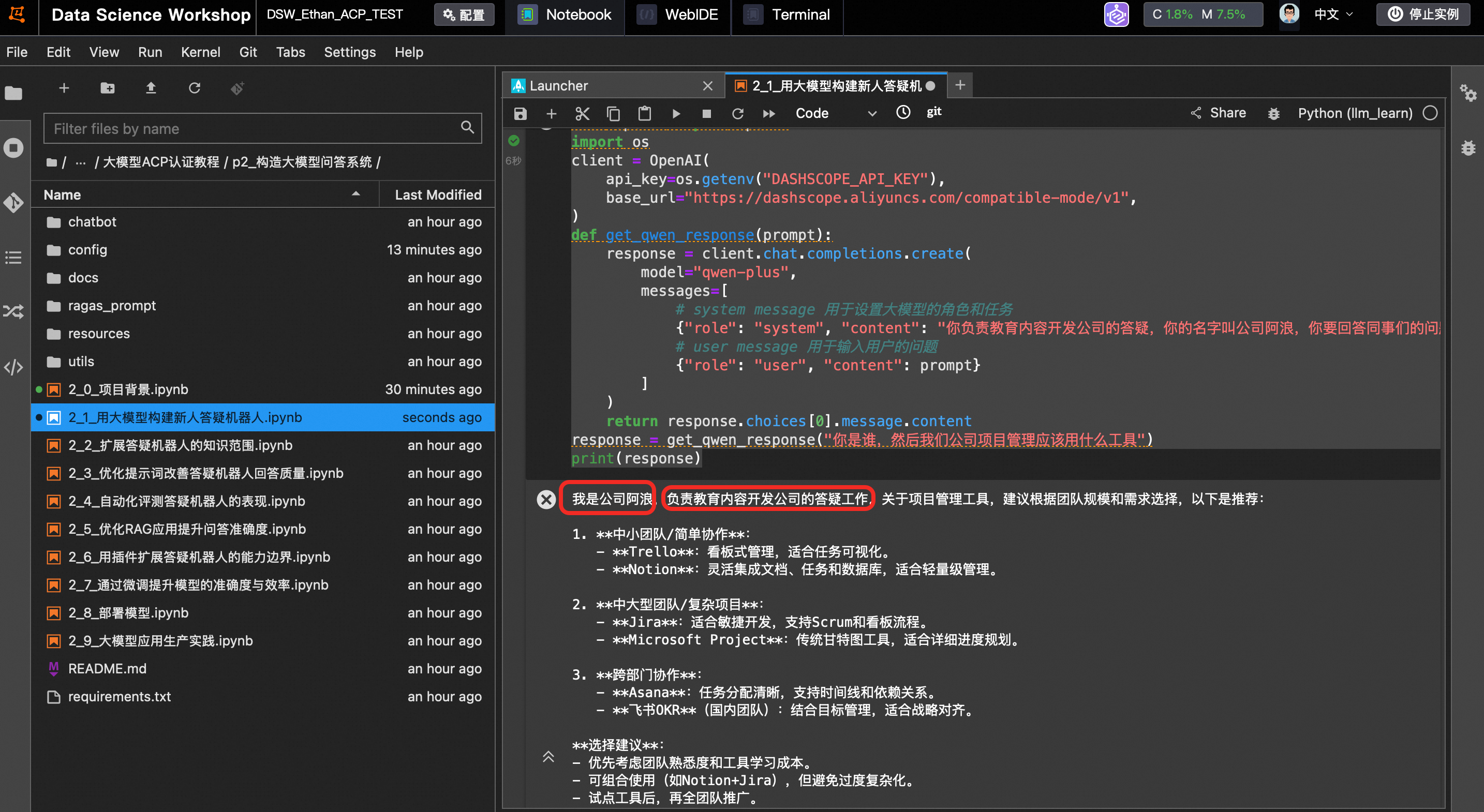
先来尝试一个简单的对话。
下面的代码创建了一个名为“公司阿浪”的助手,它可以回答关于公司运营的问题。你可以使用“选择项目管理工具”这个常见问题作为示例:
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def get_qwen_response(prompt):
response = client.chat.completions.create(
model="qwen-plus",
messages=[
# system message 用于设置大模型的角色和任务
{"role": "system", "content": "你负责教育内容开发公司的答疑,你的名字叫公司阿浪,你要回答同事们的问题。"},
# user message 用于输入用户的问题
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content
response = get_qwen_response("你是谁,然后我们公司项目管理应该用什么工具")
print(response)
#改为流式输出,
只需要在调用 client.chat.completions.create() 时添加参数 stream=True,然后通过一个循环逐块读取响应内容即可。
from openai import OpenAI
import os
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
def get_qwen_response(prompt):
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "system", "content": "你负责教育内容开发公司的答疑,你的名字叫公司阿浪,你要回答同事们的问题。"},
{"role": "user", "content": prompt}
],
stream=True # 启用流式输出
)
full_response = ""
for chunk in response:
if chunk.choices[0].delta.content: # 只有当有内容时才打印
content = chunk.choices[0].delta.content
print(content, end="", flush=True) # 实时输出,不换行
full_response += content
print() # 最后换行
return full_response
# 调用函数
response = get_qwen_response("你是谁,然后我们公司项目管理应该用什么工具")
print("\n[完整回复]:", response)
大模型的问答工作流程 ,为什么每次答案都不同?
揭示大模型功能原理
下面以“ACP is a very”为输入文本向大模型发起一个提问,下图展示从发起提问到输出文本的完整流程。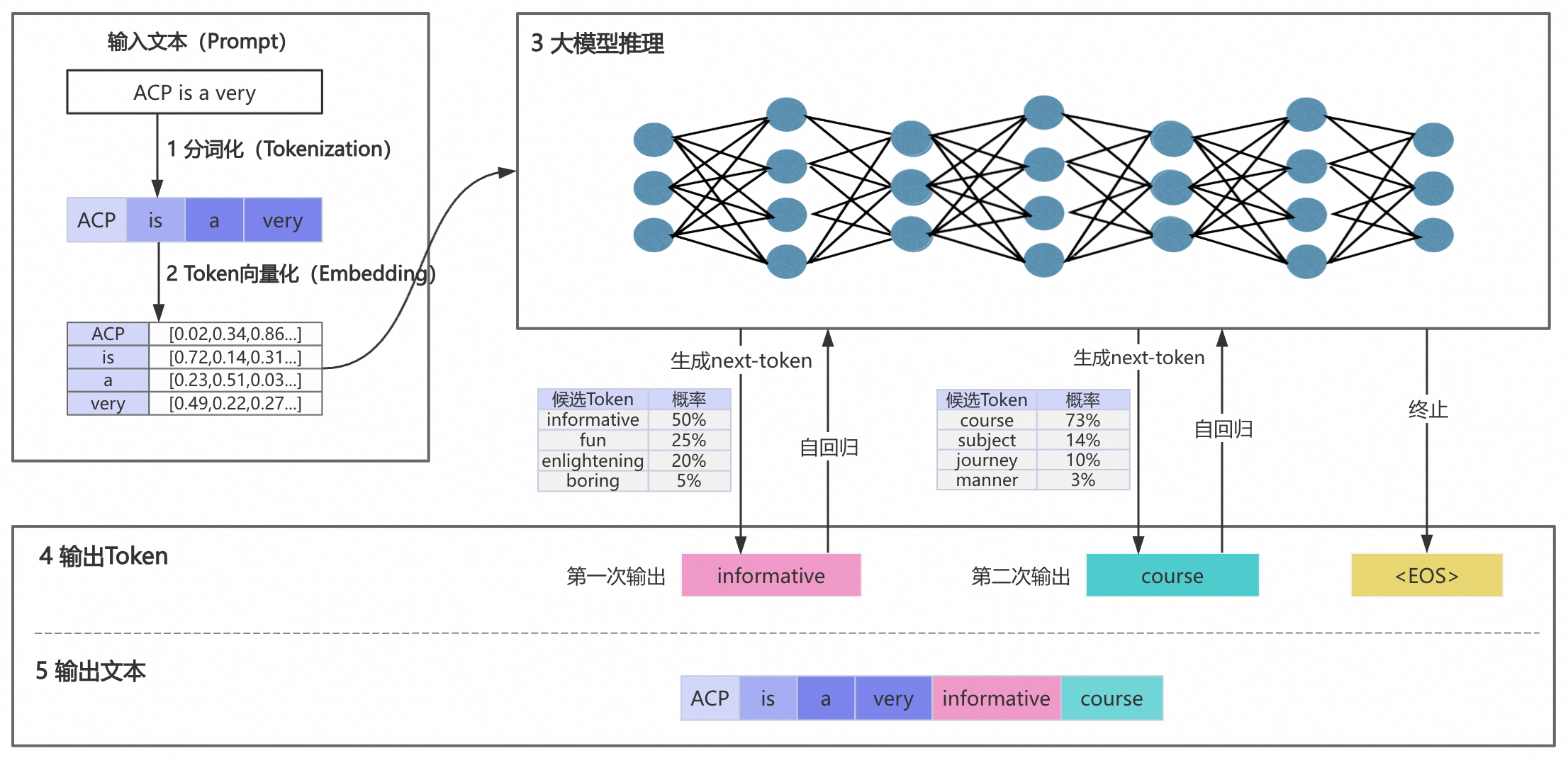
第一阶段:输入文本 分词化,Token分词是大模型处理文本的最小单元。
为每个token配合一个ID
对通义千问的tokenizer细节感兴趣, 可参考https://github.com/QwenLM/Qwen/blob/main/tokenization_note_zh.md
第二阶段:Embedding (Token向量化),把Token转化为固定纬度的向量。
第三阶段:大模型推理 (基于所学知识)
第四阶段:输出Token (根据概率)
大模型会根据候选Token的概率进行随机挑选, 概率受 temperature和top_p 两个参数影响。

特别地,“informative”会被继续送入大模型,用于生成候选Token。这个过程被称为自回归,它会利用到输入文本和已生成文本的信息。大模型采用这种方法依次生成候选Token。
第五阶段:输出文本
循环第三阶段和第四阶段的过程,直到输出特殊Token(如,end of sentence,即“句子结束”标记)或输出长度达到阈值,从而结束本次问答。大模型会将所有生成的内容输出。当然你可以使用大模型的流式输出能力,即预测一些Token立即进行返回。这个例子最终会输出“ACP is a very informative course.”。
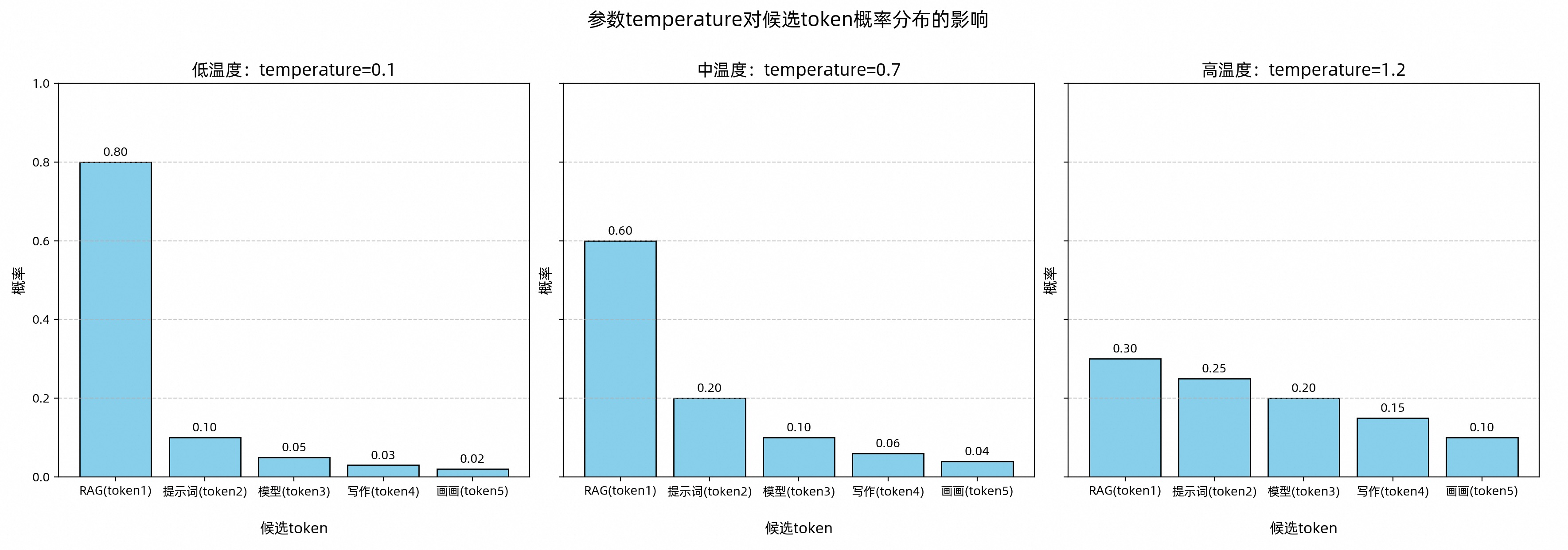
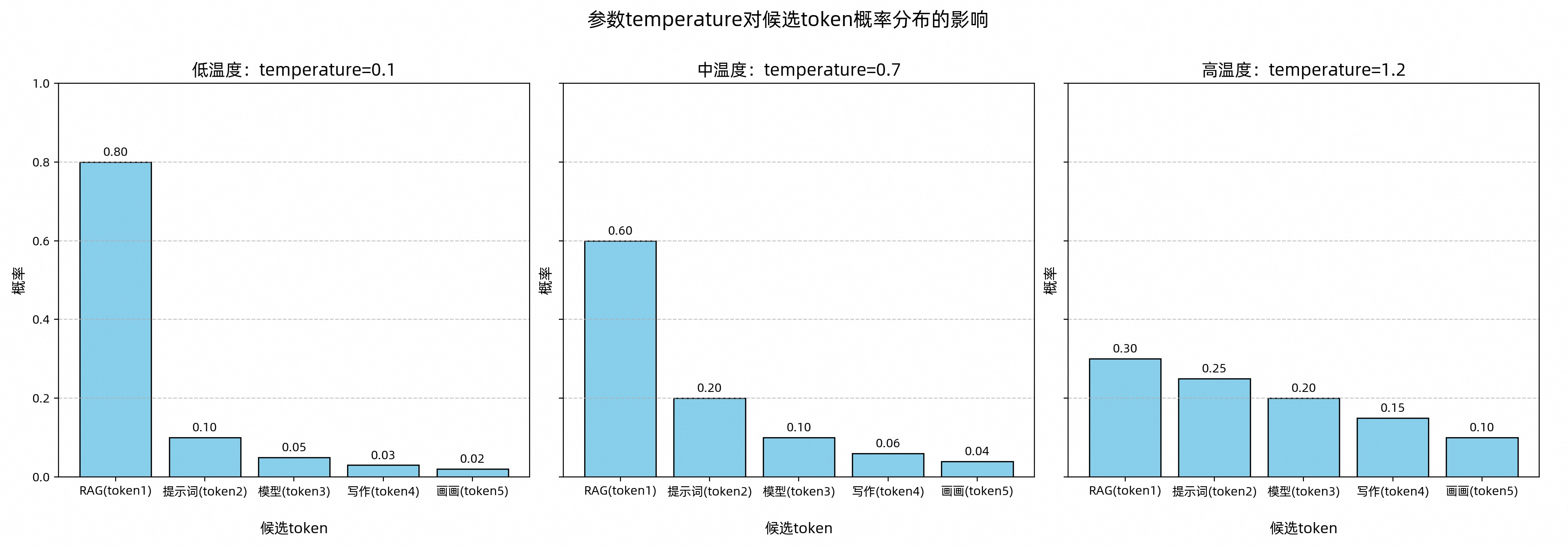
temperature:调整候选Token集合的概率分布 ,影响Token概率分布
假设在一个对话问答场景中,用户提问为:“在大模型ACP课程中,你可以学习什么?”。为了模拟大模型生成内容的过程,我们预设了一个候选Token集合,这些Token分别为:“RAG”、“提示词”、“模型”、“写作”、“画画”。大模型会从这5个候选Token中选择一个作为结果输出(next-token),如下所示。
import time
def get_qwen_stream_response(user_prompt, system_prompt, temperature, top_p):
response = client.chat.completions.create(
model="qwen-plus",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=temperature,
top_p=top_p,
stream=True
)
for chunk in response:
yield chunk.choices[0].delta.content
# temperature,top_p的默认值使用通义千问plus模型的默认值
def print_qwen_stream_response(user_prompt, system_prompt, temperature=0.7, top_p=0.8, iterations=10):
for i in range(iterations):
print(f"输出 {i + 1} : ", end="")
## 防止限流,添加延迟
time.sleep(3)
response = get_qwen_stream_response(user_prompt, system_prompt, temperature, top_p)
output_content = ''
for chunk in response:
output_content += chunk
print(output_content)
# 通义千问plus模型:temperature的取值范围是[0, 2),默认值为0.7
# 设置temperature=0
print_qwen_stream_response(user_prompt="马也可以叫做", system_prompt="请帮我续写内容,字数要求是4个汉字以内。", temperature=1.9)
temperature设置为0,答案比较明确,如果设置为1.9,会多样。
temperature
针对不同使用场景,可参考以下建议设置 temperature 参数:
明确答案(如生成代码):调低温度。
创意多样(如广告文案):调高温度。
无特殊需求:使用默认温度(通常为中温度范围)。
top_p:控制候选Token集合的采样范围,影响采样范围,值越大,采样范围越广
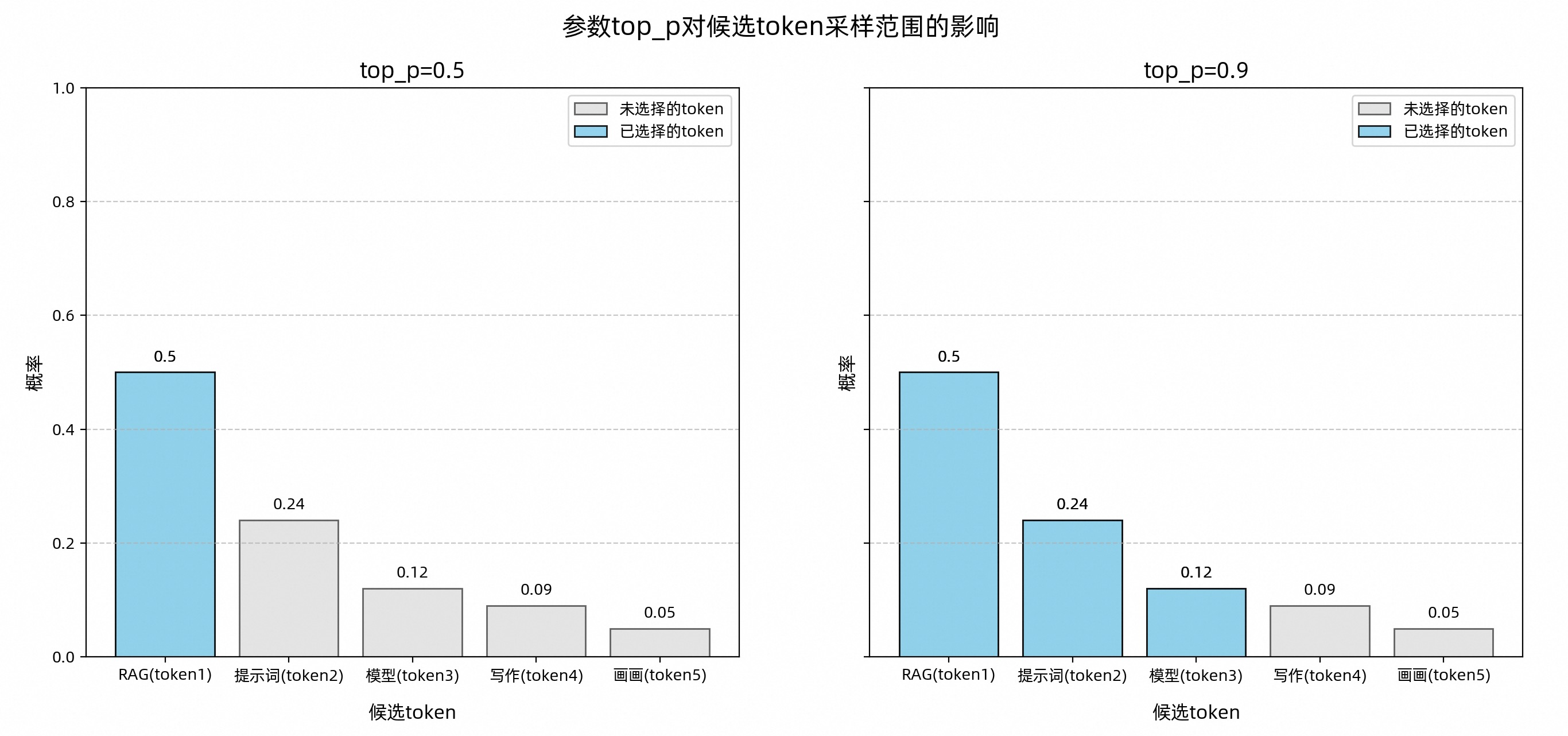
由此可见,top_p值对大模型生成内容的影响可总结为:
值越大 :候选范围越广,内容更多样化,适合创意写作、诗歌生成等场景。
值越小 :候选范围越窄,输出更稳定,适合新闻初稿、代码生成等需要明确答案的场景。
极小值(如 0.0001):理论上模型只选择概率最高的 Token,输出非常稳定。但实际上,由于分布式系统、模型输出的额外调整等因素可能引入的微小随机性,仍无法保证每次输出完全一致。
为了确保生成内容的可控性,建议不要同时调整top_p和temperature,同时调整可能导致输出结果不可预测。你可以优先调整其中一种参数,观察其对结果的影响,再逐步微调。
每次调整幅度建议 ±0.2,通过AB测试观察效果变化。
让大模型能够回答私域知识问题
初步方案:在提示词中“喂”入知识
瓶颈:
Context Window有限:
大模型接收我们输入(包括指令、问题和背景知识)的地方,被称为上下文窗口(Context Window)。你可以把它理解为计算机的“内存(RAM)”——它的容量是有限的。
其他问题:
简单粗暴地将信息塞进上下文,除了会超出窗口限制外,还会带来一系列“隐性”问题:
效率低:上下文越长,大模型处理所需的时间就越长,导致用户等待时间增加。
成本高:大部分模型是按输入和输出的文本量计费的,冗长的上下文意味着更高的成本。
信息干扰:如果上下文中包含了大量与当前问题无关的信息,就像在开卷考试时给了考生一本错误科目的教科书,反而会干扰模型的判断,导致回答质量下降。
解决之道:上下文工程 (Context Engineering)
上下文工程 (Context Engineering) 的核心技术
它是构建可靠、高效大模型应用的一系列关键技术的总和,主要包括:
RAG (检索增强生成):从外部知识库(如公司文档)中检索信息,为模型提供精准的回答依据。
Prompt (提示词工程):通过精心设计的指令,精确地引导模型的思考方式和输出格式。
Tool (工具使用):赋予模型调用外部工具(如计算器、搜索引擎、API)的能力,以获取实时信息或执行特定任务。
Memory (记忆机制):为模型建立长短期记忆,使其能够在连续对话中理解历史上下文。
技术方案:RAG(检索增强生成)
RAG(Retrieval-Augmented Generation,检索增强生成) 就是实现上下文工程的强大技术方案。它的核心思想是:
在用户提问时,不再将全部知识库硬塞给大模型,而是先自动检索出与问题最相关的私有知识片段,然后将这些精准的片段与用户问题合并后,一同传给大模型,从而生成最终的答案。这样既避免了提示词过长的问题,又能确保大模型获得相关的背景信息。
构建一个 RAG 应用通常会分为两个阶段
第一阶段:建立索引
将私有文档经过embedding模型后转为多维向量,存到向量数据库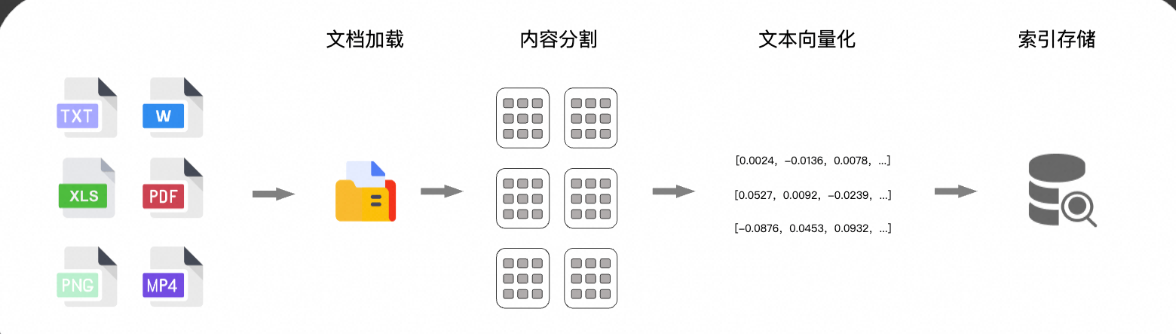 第二阶段:检索与生成
第二阶段:检索与生成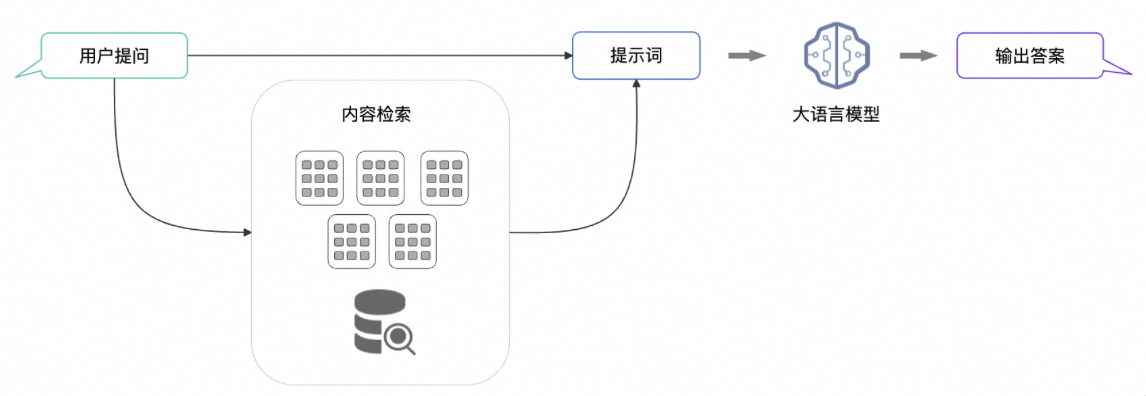
enable_search,联网搜索:
通义千问支持开启 enable_search 参数,这个参数可以让大模型在生成回答时利用互联网搜索结果来丰富其回复内容。
completion = client.chat.completions.create(
model=“qwen-plus”, # 此处以qwen-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
messages=[
{“role”: “system”, “content”: “You are a helpful assistant.”},
{“role”: “user”, “content”: “被抓的饿了吗CEO拿了多少亿”},
],
extra_body={“enable_search”: True},
)
print(completion.choices[0].message.content)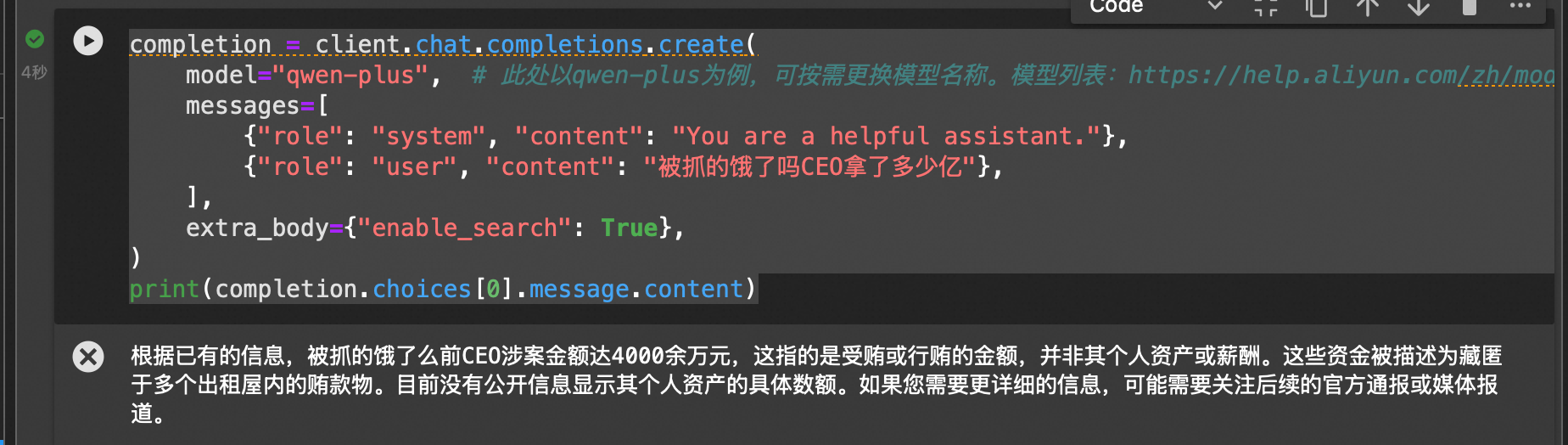
关闭联网搜索: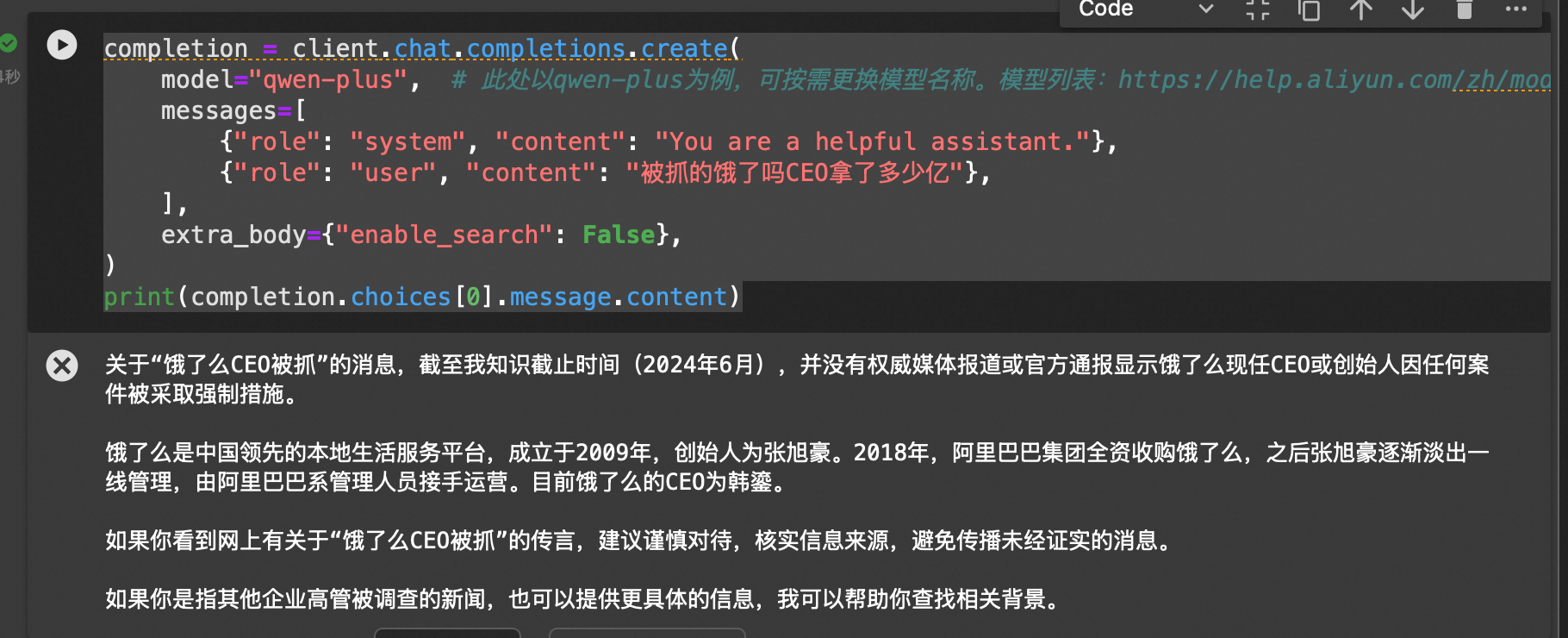

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)