PaddleOCR二次训练,训练属于自己的数据集(linux)
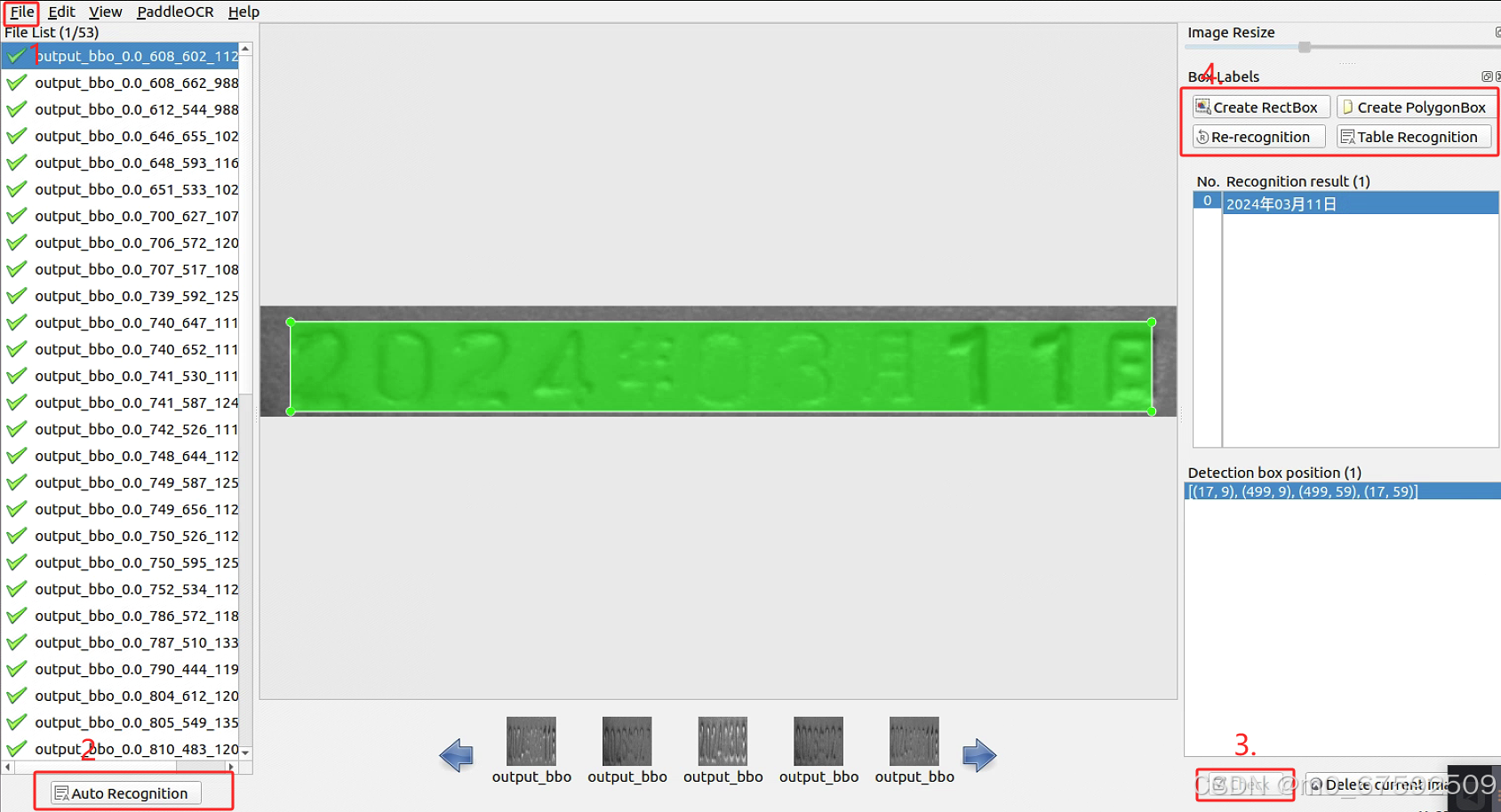
1.1源码安装下载,找到PPOCRlabel.py文件,并运行它。3.点击查看标注内容是否正确,若正确则点击,不正确进行步骤四。下载成功后,运行PPOCRLabel文件,将弹出来标注软件。4.若不正确选择对应的框进行重新标注,并输入正确识别结果。2.自动标注,若有不对可进行人为修改。标注好后,需进行点击生成这三个文件。(需要很多的库,报错就安装)
一:制作数据
1.标注工具的下载
标注工具的安装共两种方式:
1.1源码安装下载,找到PPOCRlabel.py文件,并运行它。
python PPOCRlabel.py(需要很多的库,报错就安装)
1.2.直接安装
pip install PPOCRlabel2.标注
下载成功后,运行PPOCRLabel文件,将弹出来标注软件
1.打开文件
2.自动标注,若有不对可进行人为修改
3.点击查看标注内容是否正确,若正确则点击,不正确进行步骤四
4.若不正确选择对应的框进行重新标注,并输入正确识别结果。
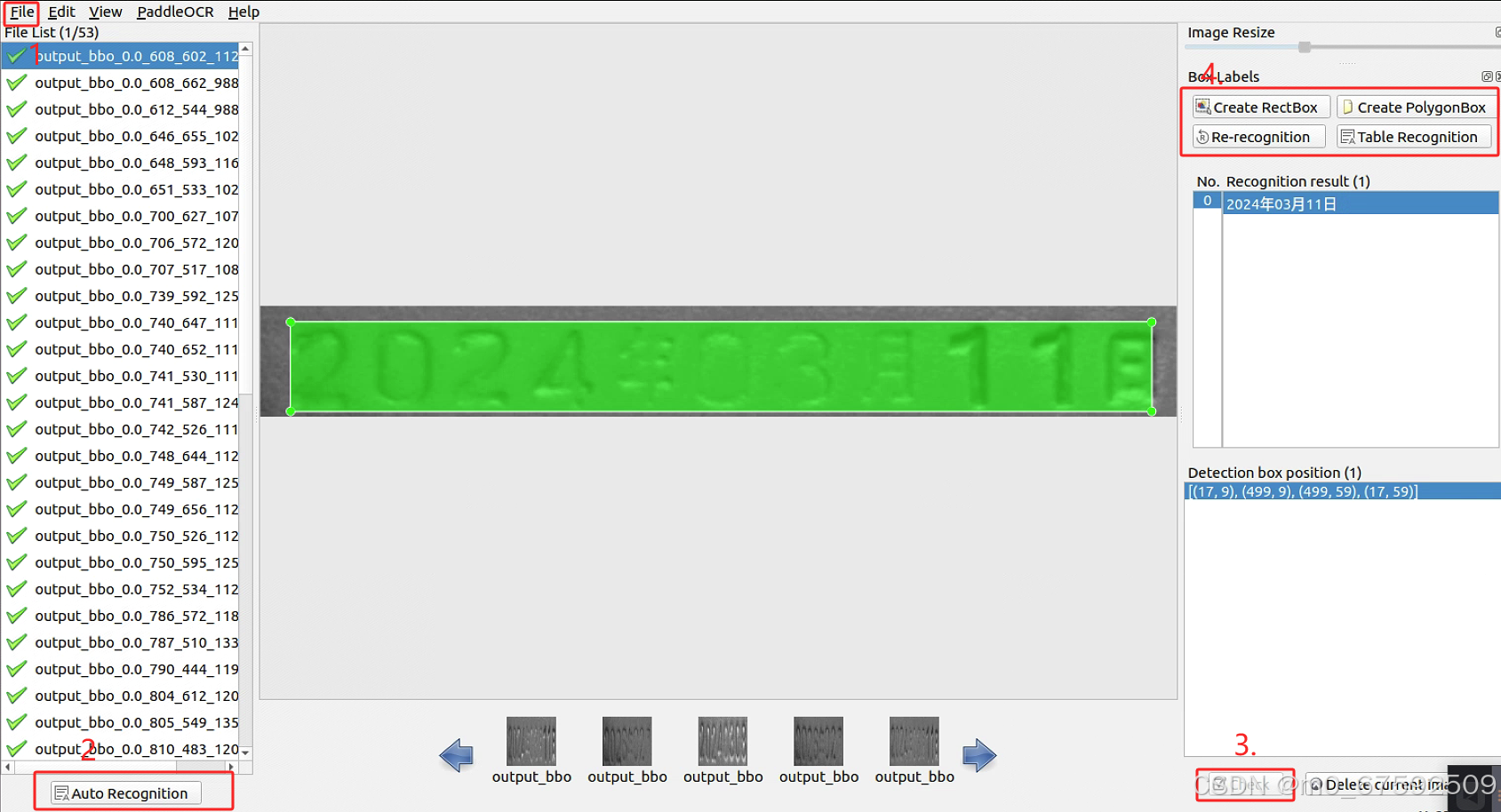
标注好后,需进行点击生成这三个文件
3.划分数据集
最后应该生成以下文件
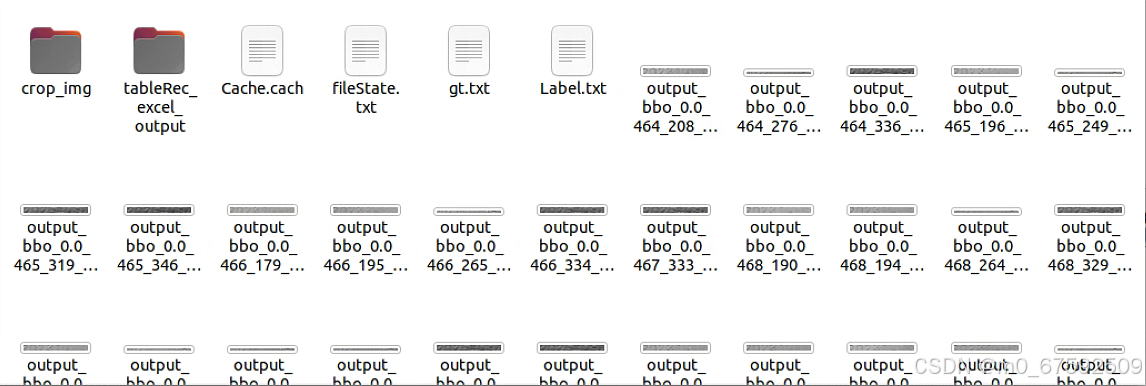
之后进行数据集的划分
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath 1/1#这个是刚刚生成数据的训练集,生成目录为默认目录,则为PPOCRLabel上一级目录生成目录为下图: det是用来训练文字检测的数据集,rec是用来训练文字识别的数据集


二:训练模型
需要训练两个模型,分别为定位和识别,先训练定位模型,再进行识别模型的训练。
Ⅰ:定位
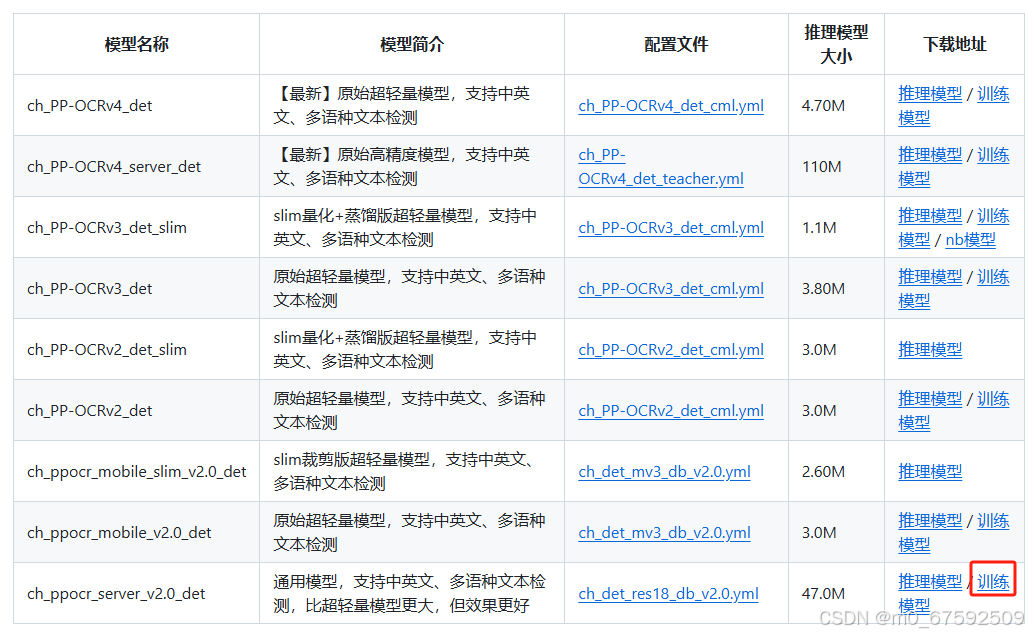
1.下载模型
从官网下载模型(网站)
PaddleOCR/doc/doc_ch/models_list.md at release/2.7 · PaddlePaddle/PaddleOCR · GitHub
之后下载此文件,添加到PaddleOCR-release-2.7(选择自己的源码)
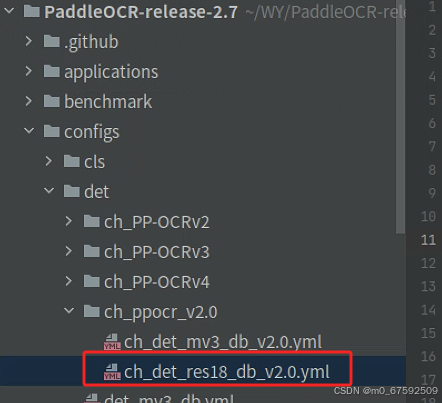
2.配置文件
因为选择的是上面的文件,配置文件则需要下面的配置文件
修改下列基本参数
use_gpu:是否应用gpu
wpoch_num:训练的周期
save_model_dir:保存模型的路径
pretrained_model:预训练模型的路径
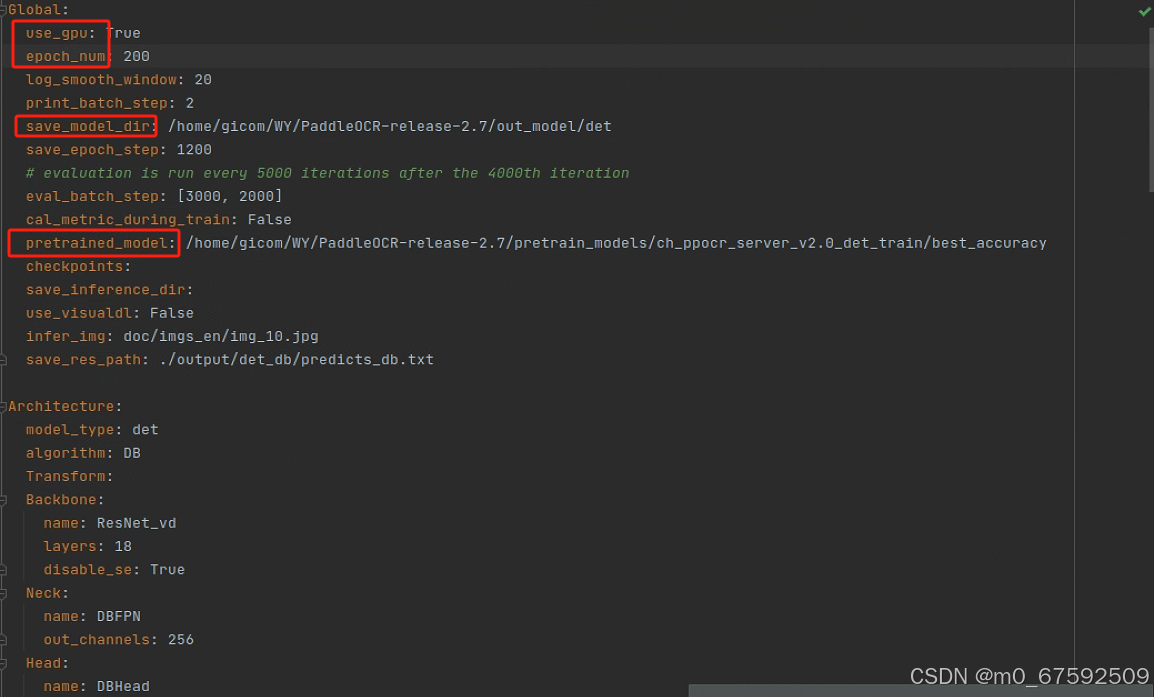
data_dir:训练图片的路径
label_file_list:训练图片txt的路径
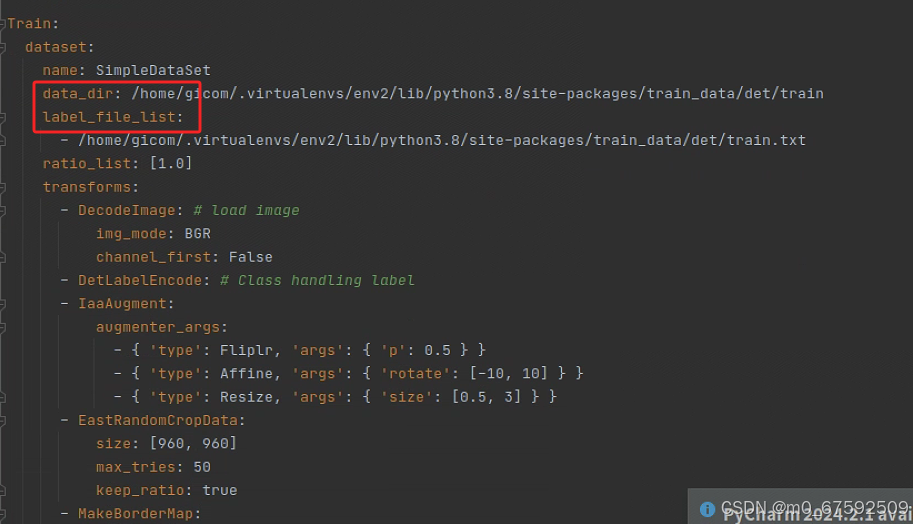
data_dir:val图片的路径
label_file_list:val txt的路径
3.开始训练
python tools/train.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml训练成功后生成最好的的模型会存放到上面所写的保存路径里面

4.进行预测
python tools/infer_det.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o Global.pretrained_model=/home/gicom/WY/PaddleOCR-release-2.7/out_model/det/best_model/model.pdparams #训练最好结果模型的路径Global.infer_img=/home/gicom/WY/gicomocr/result/1#预测图片的文件夹路径预测后在默认文件夹保存

Ⅱ:识别
此步骤和定位步骤相似
1.下载模型
PaddleOCR/doc/doc_ch/models_list.md at release/2.7 · PaddlePaddle/PaddleOCR · GitHub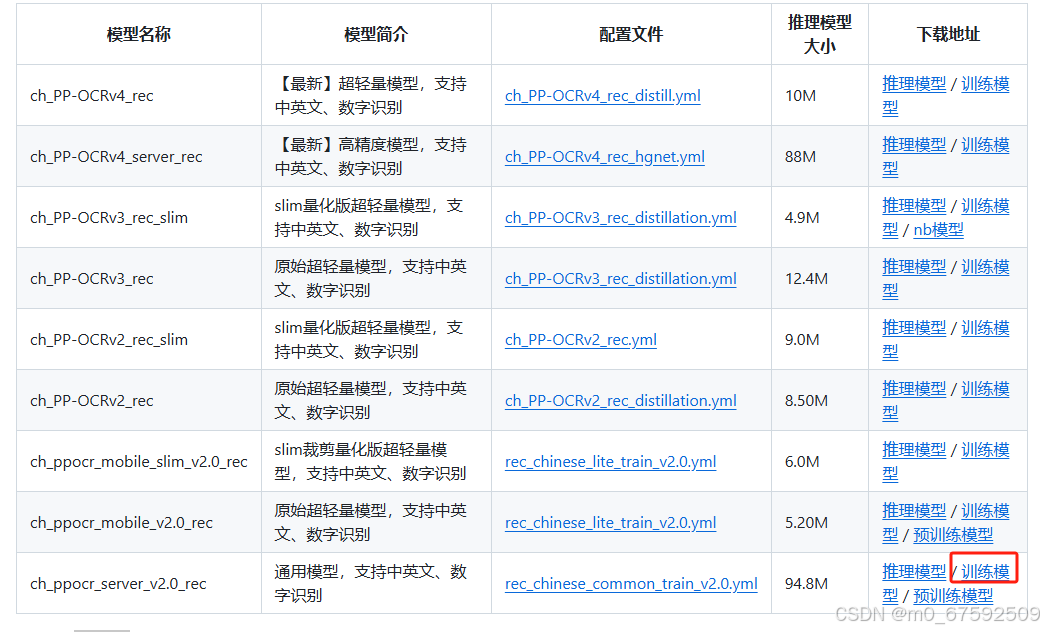
2.配置文件
配置里面的内容和定位一致,这里不加赘述
3.开始训练
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml #ch_PP-OCRv3_rec.yml的路径
魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)