基于YOLOv8深度学习的船舶识别检测系统(YOLOv8+YOLO数据集+UI界面+Python项目源码+模型)
本项目基于先进的YOLOv8目标检测算法,开发了一套高性能的智能船舶识别与分类系统。系统能够准确识别和分类10类常见船舶,包括散货船(BULK CARRIER)、集装箱船(CONTAINER SHIP)、杂货船(GENERAL CARGO)、成品油轮(OIL PRODUCTS TANKER)、客船(PASSENGERS SHIP)、油轮(TANKER)、拖网渔船(TRAWLER)、拖船(TUG)、
 一、项目介绍
一、项目介绍
摘要
本项目基于先进的YOLOv8目标检测算法,开发了一套高性能的智能船舶识别与分类系统。系统能够准确识别和分类10类常见船舶,包括散货船(BULK CARRIER)、集装箱船(CONTAINER SHIP)、杂货船(GENERAL CARGO)、成品油轮(OIL PRODUCTS TANKER)、客船(PASSENGERS SHIP)、油轮(TANKER)、拖网渔船(TRAWLER)、拖船(TUG)、车辆运输船(VEHICLES CARRIER)以及游艇(YACHT)。项目采用大规模专业数据集进行训练,包含3498张训练图像、1000张验证图像和500张测试图像,确保模型具备优异的泛化能力和鲁棒性。
本系统特别针对海上复杂环境进行了优化,能够有效处理不同光照条件、天气状况和海况下的船舶识别任务。通过深度卷积神经网络和多尺度特征融合技术,系统实现了高精度的船舶检测与分类。系统支持多种部署方式,包括海岸监控系统、船载AIS辅助系统、无人机海事巡查平台等,可广泛应用于海事安全、港口管理、渔业监管和海上搜救等领域。
项目意义
1. 技术创新价值
(1) 多类别船舶识别优化:针对10类船舶在外形、尺寸和特征上的显著差异,设计了专门的网络结构和损失函数,有效解决了类间相似性(如油轮与成品油轮)和类内差异性(如同类船舶不同角度)带来的识别挑战。
(2) 复杂海况适应性:通过特殊的数据增强技术(模拟雾天、浪涌、日照反射等)和注意力机制,显著提升了系统在恶劣海况下的识别稳定性,解决了传统视觉算法在海面反光、目标遮挡等情况下的性能下降问题。
(3) 小目标检测突破:针对远距离船舶呈现的小目标特性,改进了YOLOv8的特征金字塔结构,增强了网络对小尺寸船舶的检测能力。
2. 实际应用价值
海事安全与管理
-
智能港口监控:自动识别进出港船舶类型,辅助港口调度和安全管理
-
海上交通管制:实时监控航道船舶动态,预防碰撞事故
-
禁区船舶识别:自动检测非法进入禁航区或保护区的特定类型船舶
渔业与环境保护
-
渔船活动监测:识别拖网渔船等作业船只,辅助渔业资源管理
-
防污染监管:重点监控油轮等潜在污染源船舶的合规操作
国防与边境安全
-
可疑船只识别:自动筛查未申报或异常活动的船舶
-
海上搜救辅助:快速识别失事海域附近的可用救援船只
商业与物流
-
航运数据分析:统计各类船舶流量,为港口建设和航线规划提供依据
-
船舶自动识别:补充AIS系统的视觉验证功能,防止AIS欺骗行为
3. 社会效益
(1) 提升海上安全:通过全天候自动船舶监控,大幅降低海上碰撞和事故风险,每年可减少数十亿元的经济损失。
(2) 保护海洋环境:加强对油轮等高风险船舶的监控,有效预防原油泄漏等环境灾难,保护海洋生态系统。
(3) 优化航运效率:为港口和航道提供智能化的船舶流量分析,优化物流效率,降低航运成本。
(4) 促进智慧海洋:推动传统海事管理向数字化、智能化转型,加速"智慧港口"和"数字航道"建设。
4. 技术实现亮点
(1) 专业数据集构建:收集涵盖不同海域、季节、天气条件下的船舶图像,确保数据多样性和代表性。采用半自动标注流程,提高标注效率和准确性。
(2) 模型结构创新:
-
引入船舶特征增强模块(SFEM),强化对船舶特有结构(如货舱、烟囱、甲板布局)的特征提取
-
设计多任务学习框架,同时优化检测和分类性能
-
采用自适应锚框机制,适应不同类别船舶的尺寸差异
(3) 部署优化:
-
开发轻量化版本,适配边缘计算设备
-
支持与雷达、AIS等多源数据融合
-
提供API接口,便于集成到现有海事管理系统
5. 未来发展展望
(1) 多模态融合:结合红外成像、雷达数据和AIS信息,构建更全面的船舶感知系统。
(2) 行为分析:从单纯识别扩展到船舶行为模式分析,检测异常活动如非法捕捞、走私等。
(3) 全球船舶数据库:建立覆盖更全面船舶类型的识别系统,纳入更多特种船舶和军用舰艇。
(4) 自主巡查系统:集成到无人艇和无人机平台,实现海域自动化巡查。
结论
本YOLOv8船舶识别检测系统通过深度学习技术实现了高精度、多类别的船舶自动识别,解决了传统海事监控中的诸多痛点问题。系统不仅具备技术创新性,更在海上安全、环境保护、航运管理等领域具有广泛的应用前景。随着海洋经济快速发展,智能船舶识别技术将成为智慧海洋建设的重要支撑,本项目的成功实施为相关应用提供了可靠的技术方案和落地示范。未来通过持续优化和功能扩展,该系统有望成为全球海事管理的基础性技术设施,为海洋安全和可持续发展做出重要贡献。
目录
基于深度学习的船舶类型识别检测系统(YOLOv8+YOLO数据集+UI界面+Python项目源码+模型)_哔哩哔哩_bilibili
基于深度学习的船舶类型识别检测系统(YOLOv8+YOLO数据集+UI界面+Python项目源码+模型)
二、项目功能展示
系统功能
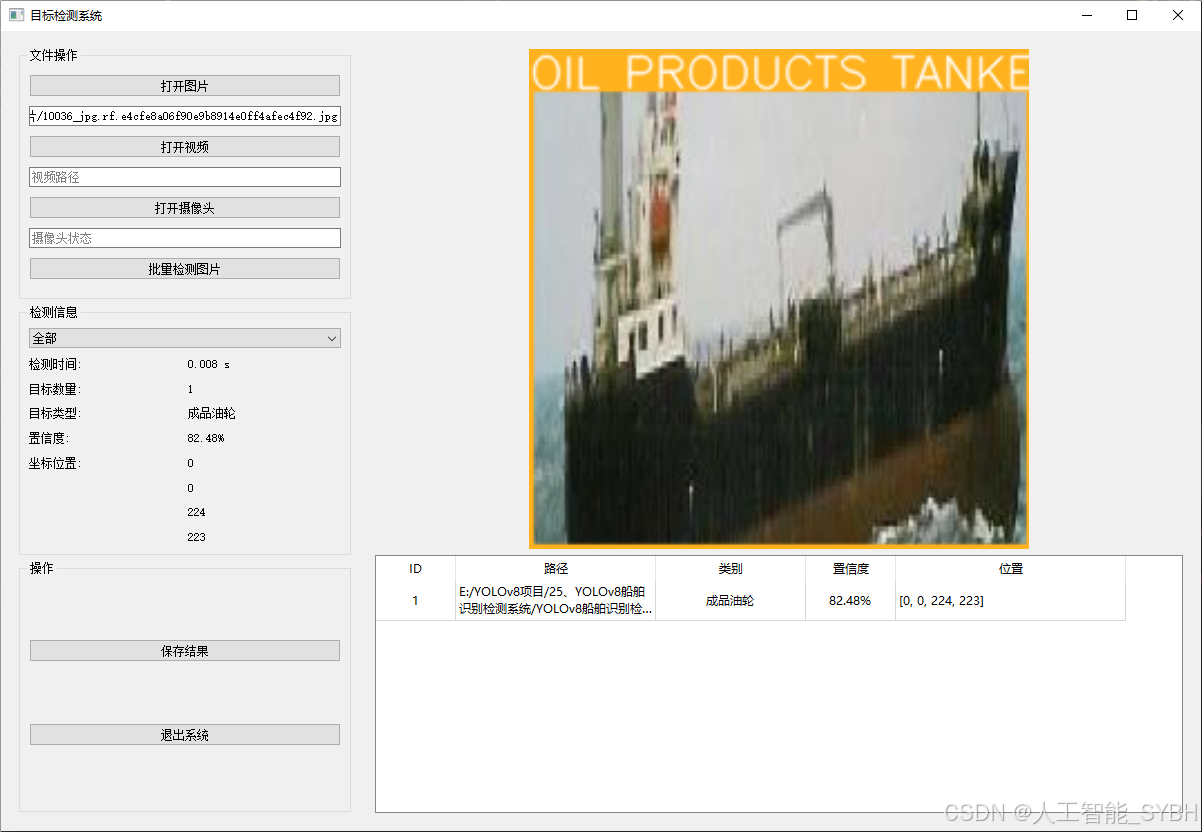
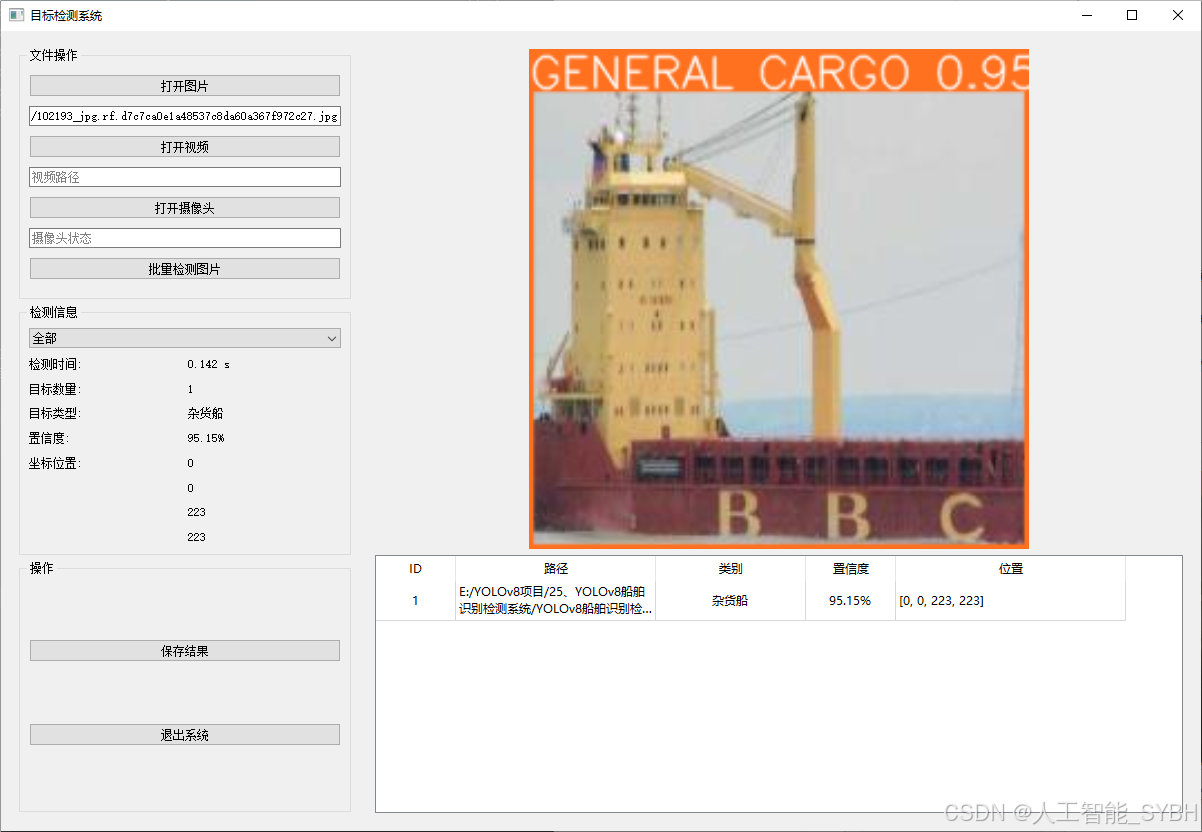
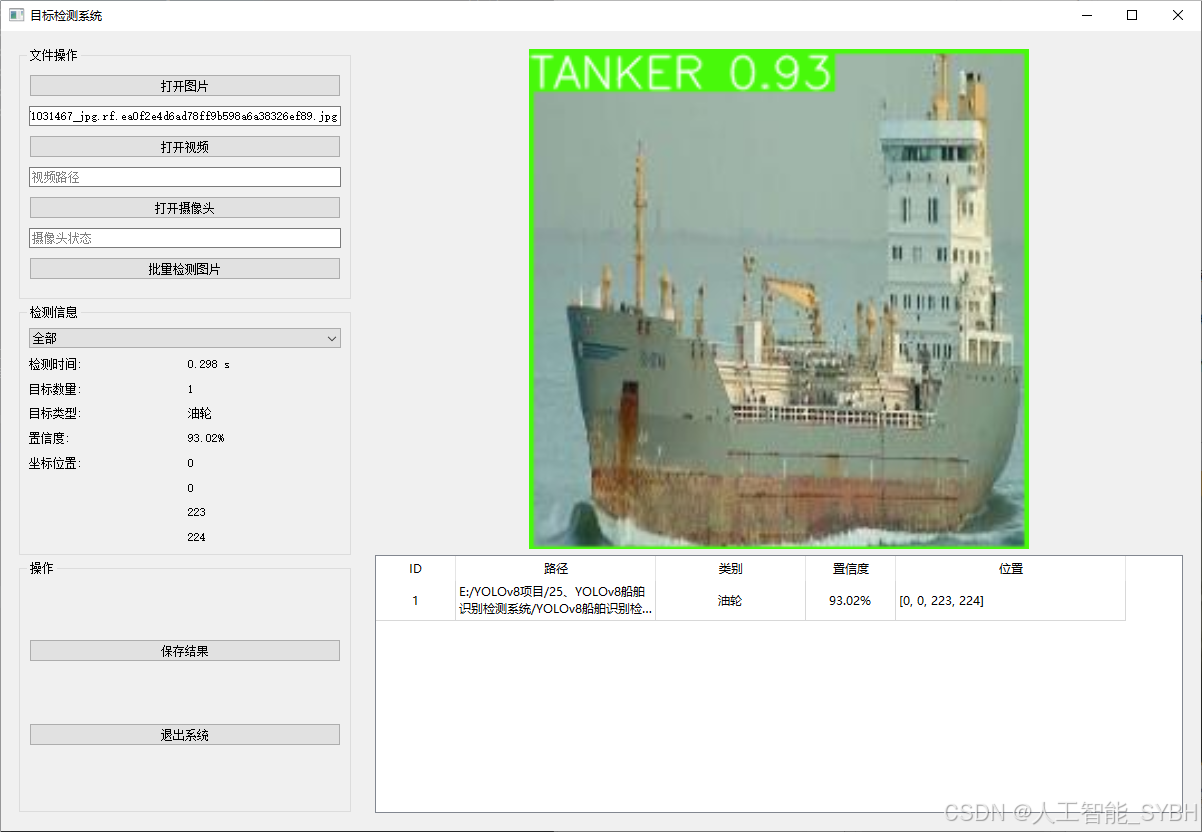
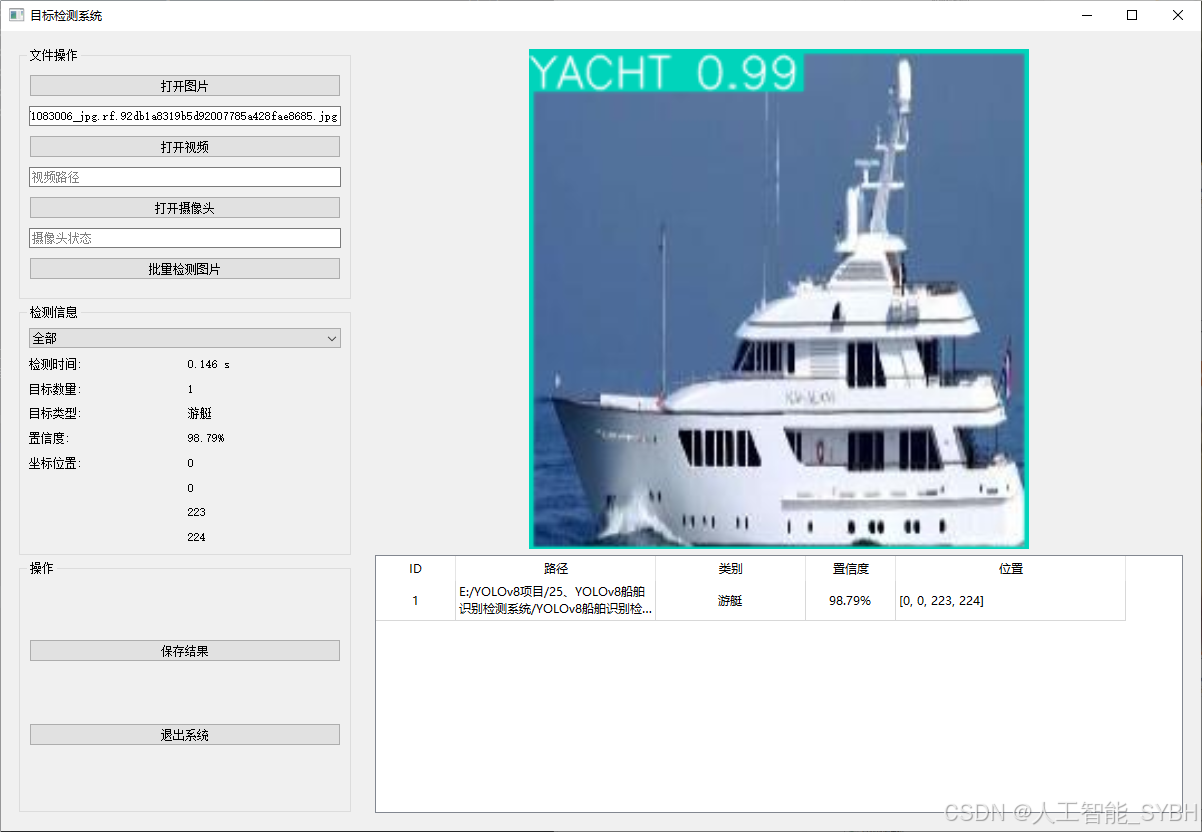
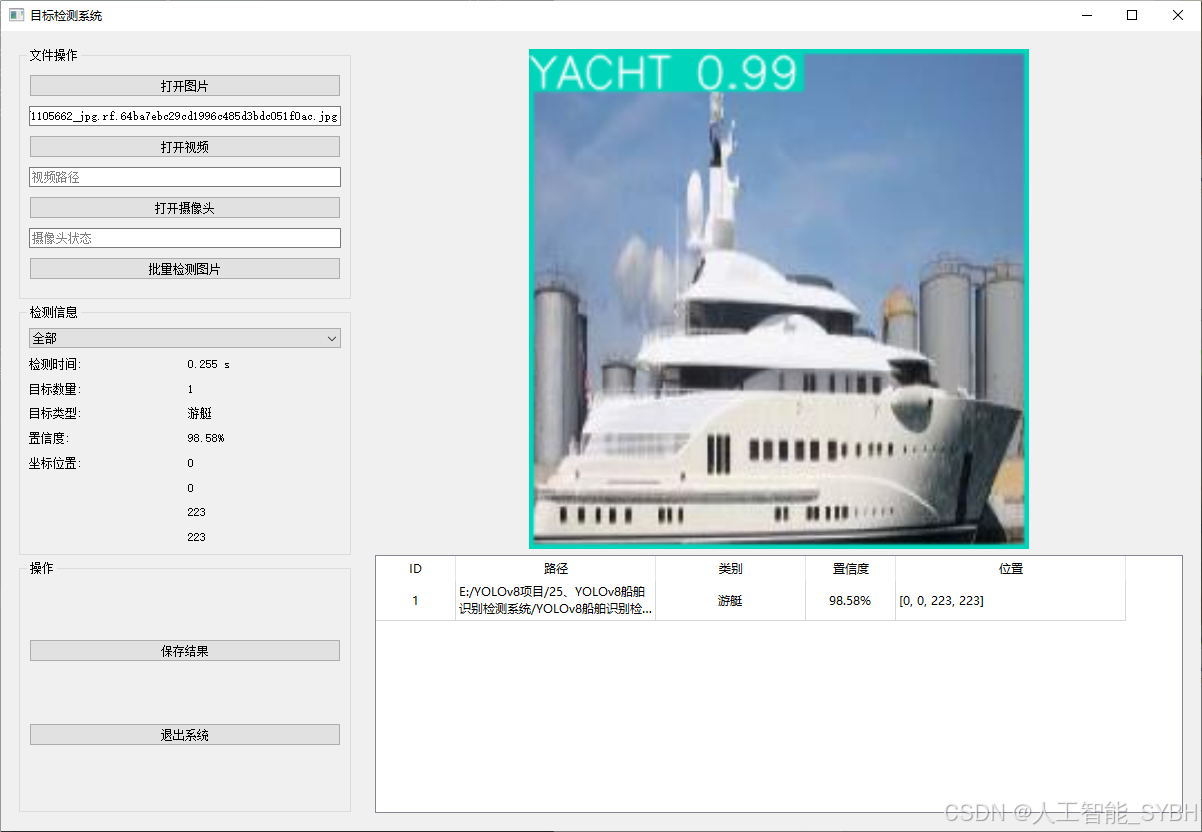
✅ 图片检测:可对单张图片进行检测,返回检测框及类别信息。
✅ 批量图片检测:支持文件夹输入,一次性检测多张图片,生成批量检测结果。
✅ 视频检测:支持视频文件输入,检测视频中每一帧的情况。
✅ 摄像头实时检测:连接USB 摄像头,实现实时监测,
-
图片检测
该功能允许用户通过单张图片进行目标检测。输入一张图片后,YOLO模型会实时分析图像,识别出其中的目标,并在图像中框出检测到的目标,输出带有目标框的图像。批量图片检测
用户可以一次性上传多个图片进行批量处理。该功能支持对多个图像文件进行并行处理,并返回每张图像的目标检测结果,适用于需要大规模处理图像数据的应用场景。
-
视频检测
视频检测功能允许用户将视频文件作为输入。YOLO模型将逐帧分析视频,并在每一帧中标记出检测到的目标。最终结果可以是带有目标框的视频文件或实时展示,适用于视频监控和分析等场景。
-
摄像头实时检测
该功能支持通过连接摄像头进行实时目标检测。YOLO模型能够在摄像头拍摄的实时视频流中进行目标检测,实时识别并显示检测结果。此功能非常适用于安防监控、无人驾驶、智能交通等应用,提供即时反馈。
核心特点:
- 高精度:基于YOLO模型,提供精确的目标检测能力,适用于不同类型的图像和视频。
- 实时性:特别优化的算法使得实时目标检测成为可能,无论是在视频还是摄像头实时检测中,响应速度都非常快。
- 批量处理:支持高效的批量图像和视频处理,适合大规模数据分析。
三、数据集介绍
数据集内容:
-
类别数量 (nc): 10 类
-
类别名称: ['BULK CARRIER', 'CONTAINER SHIP', 'GENERAL CARGO', 'OIL PRODUCTS TANKER', 'PASSENGERS SHIP', 'TANKER', 'TRAWLER', 'TUG', 'VEHICLES CARRIER', 'YACHT']
-
数据总量: 4998 张图像
-
训练集: 3498 张图像
-
验证集: 1000 张图像
-
测试集: 500 张图像
-
数据集来源:
数据集通过多种途径收集,包括公开数据集(如 SeaShips)、卫星图像、无人机拍摄以及实际港口监控图像。为确保数据的多样性和泛化能力,数据集中包含了不同船舶类型、尺寸、颜色以及多种海况和光照条件下的图像。
数据标注:
-
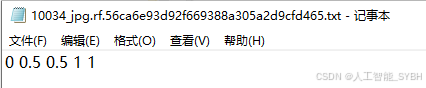
每张图像中的船舶均使用边界框 (Bounding Box) 进行标注,标注格式为 YOLO 格式 (class_id, x_center, y_center, width, height)。
-
标注工具: LabelImg 或 CVAT。
-
标注文件: 每个图像对应一个
.txt文件,存储标注信息。
数据集特点:
-
多样性: 数据集中包含 10 种不同类型的船舶,涵盖了货船、油轮、游艇等多种船舶类型。
-
挑战性: 部分图像包含复杂海况、光照变化、遮挡等干扰因素,以提高模型的鲁棒性。
-
平衡性: 训练集、验证集和测试集的比例合理,确保模型在训练、验证和测试过程中能够充分学习并泛化。







数据集配置文件data.yaml
train: .\datasets\images\train
val: .\datasets\images\val
test: .\datasets\images\test
# Classes
nc: 10
names: ['BULK CARRIER', 'CONTAINER SHIP', 'GENERAL CARGO', 'OIL PRODUCTS TANKER', 'PASSENGERS SHIP', 'TANKER', 'TRAWLER', 'TUG', 'VEHICLES CARRIER', 'YACHT']
数据集制作流程
-
标注数据:使用标注工具(如LabelImg、CVAT等)对图像中的目标进行标注。每个目标需要标出边界框,并且标注类别。
-
转换格式:将标注的数据转换为YOLO格式。YOLO标注格式为每行:
<object-class> <x_center> <y_center> <width> <height>,这些坐标是相对于图像尺寸的比例。 -
分割数据集:将数据集分为训练集、验证集和测试集,通常的比例是80%训练集、10%验证集和10%测试集。
-
准备标签文件:为每张图片生成一个对应的标签文件,确保标签文件与图片的命名一致。
-
调整图像尺寸:根据YOLO网络要求,统一调整所有图像的尺寸(如416x416或608x608)。
四、项目环境配置
创建虚拟环境
首先新建一个Anaconda环境,每个项目用不同的环境,这样项目中所用的依赖包互不干扰。
终端输入
conda create -n yolov8 python==3.9

激活虚拟环境
conda activate yolov8

安装cpu版本pytorch
pip install torch torchvision torchaudio

pycharm中配置anaconda


安装所需要库
pip install -r requirements.txt

五、模型训练
训练代码
from ultralytics import YOLO
model_path = 'yolov8s.pt'
data_path = 'datasets/data.yaml'
if __name__ == '__main__':
model = YOLO(model_path)
results = model.train(data=data_path,
epochs=500,
batch=64,
device='0',
workers=0,
project='runs/detect',
name='exp',
)根据实际情况更换模型 yolov8n.yaml (nano):轻量化模型,适合嵌入式设备,速度快但精度略低。 yolov8s.yaml (small):小模型,适合实时任务。 yolov8m.yaml (medium):中等大小模型,兼顾速度和精度。 yolov8b.yaml (base):基本版模型,适合大部分应用场景。 yolov8l.yaml (large):大型模型,适合对精度要求高的任务。
--batch 64:每批次64张图像。--epochs 500:训练500轮。--datasets/data.yaml:数据集配置文件。--weights yolov8s.pt:初始化模型权重,yolov8s.pt是预训练的轻量级YOLO模型。
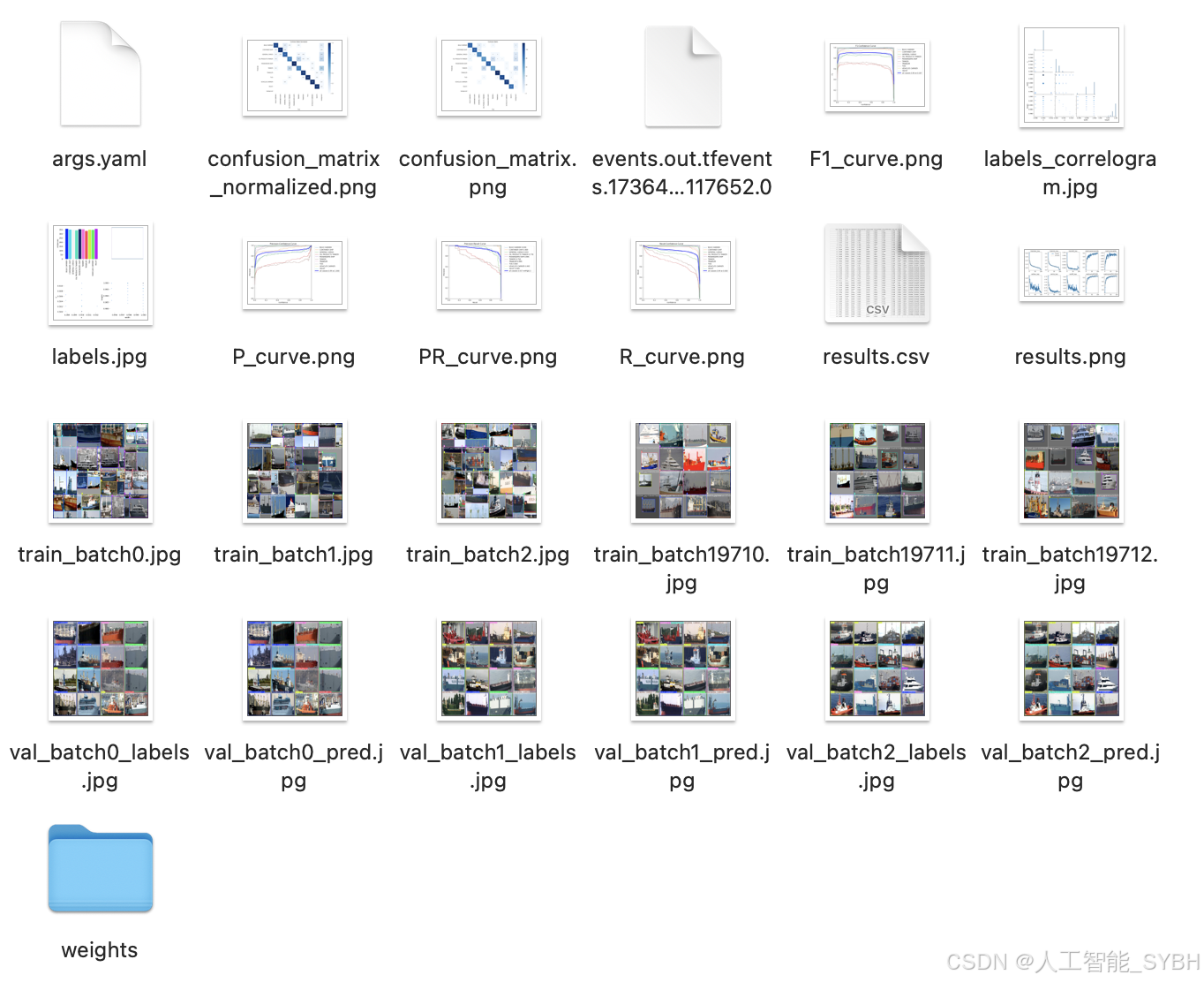
训练结果
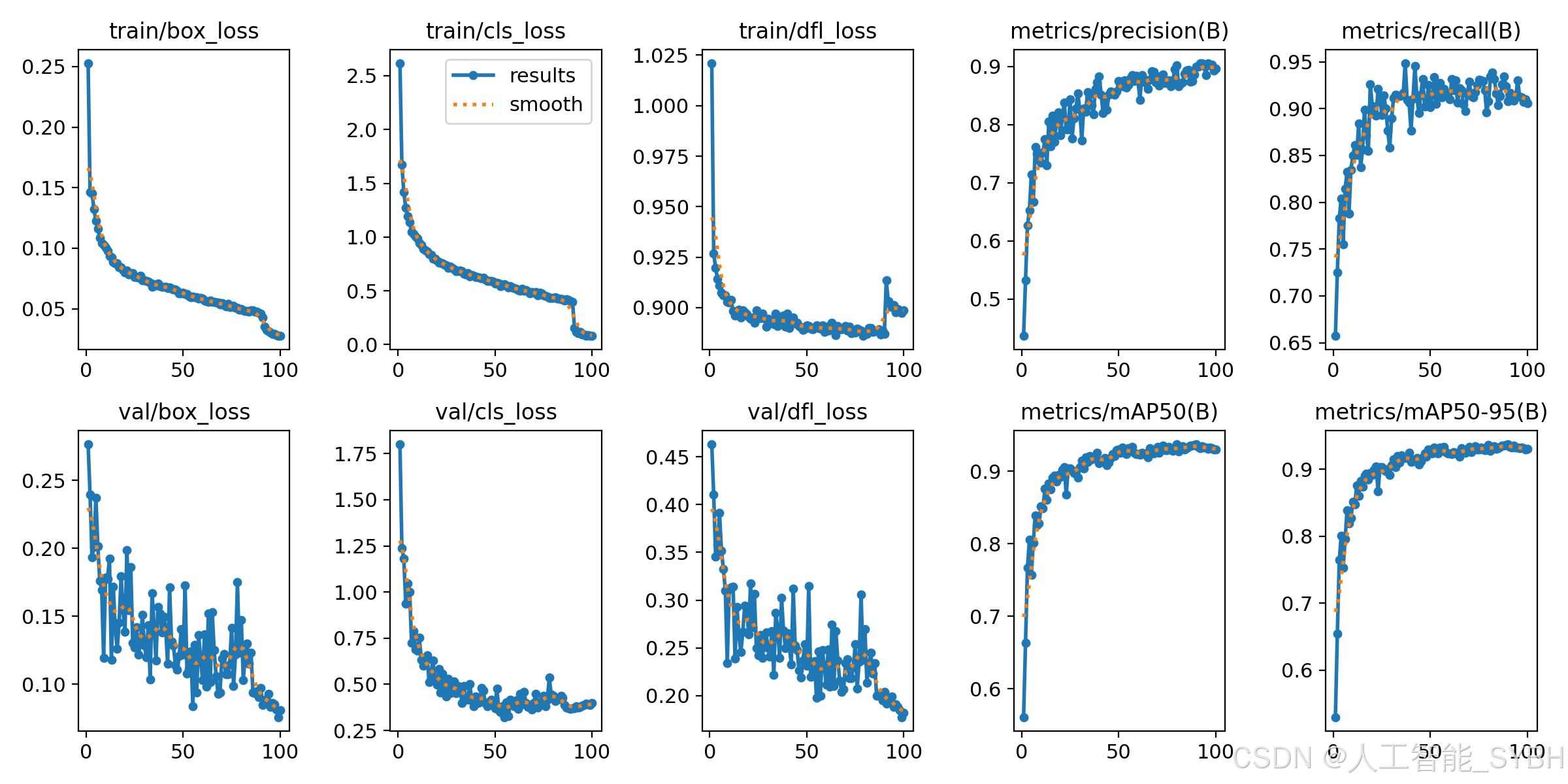
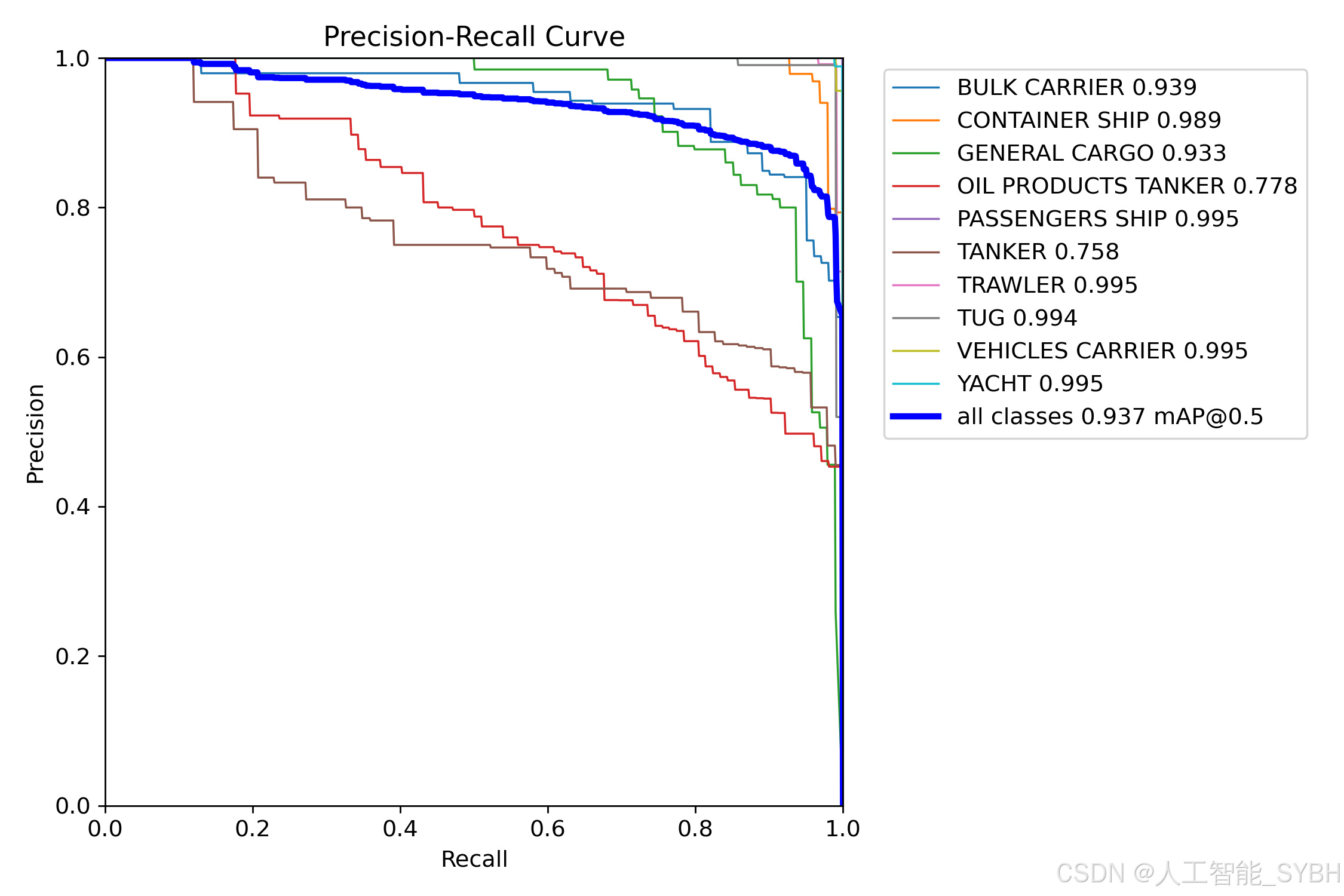
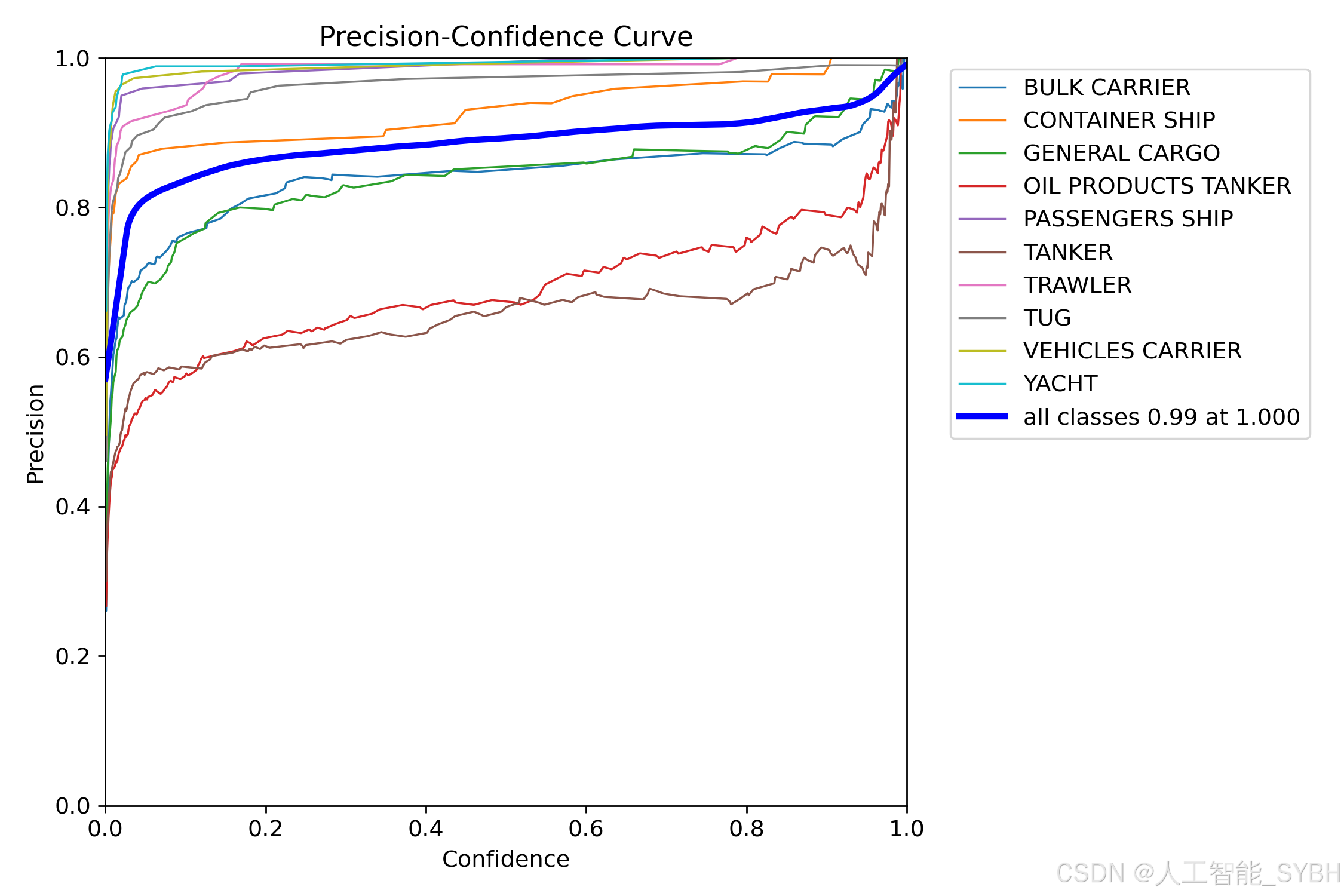
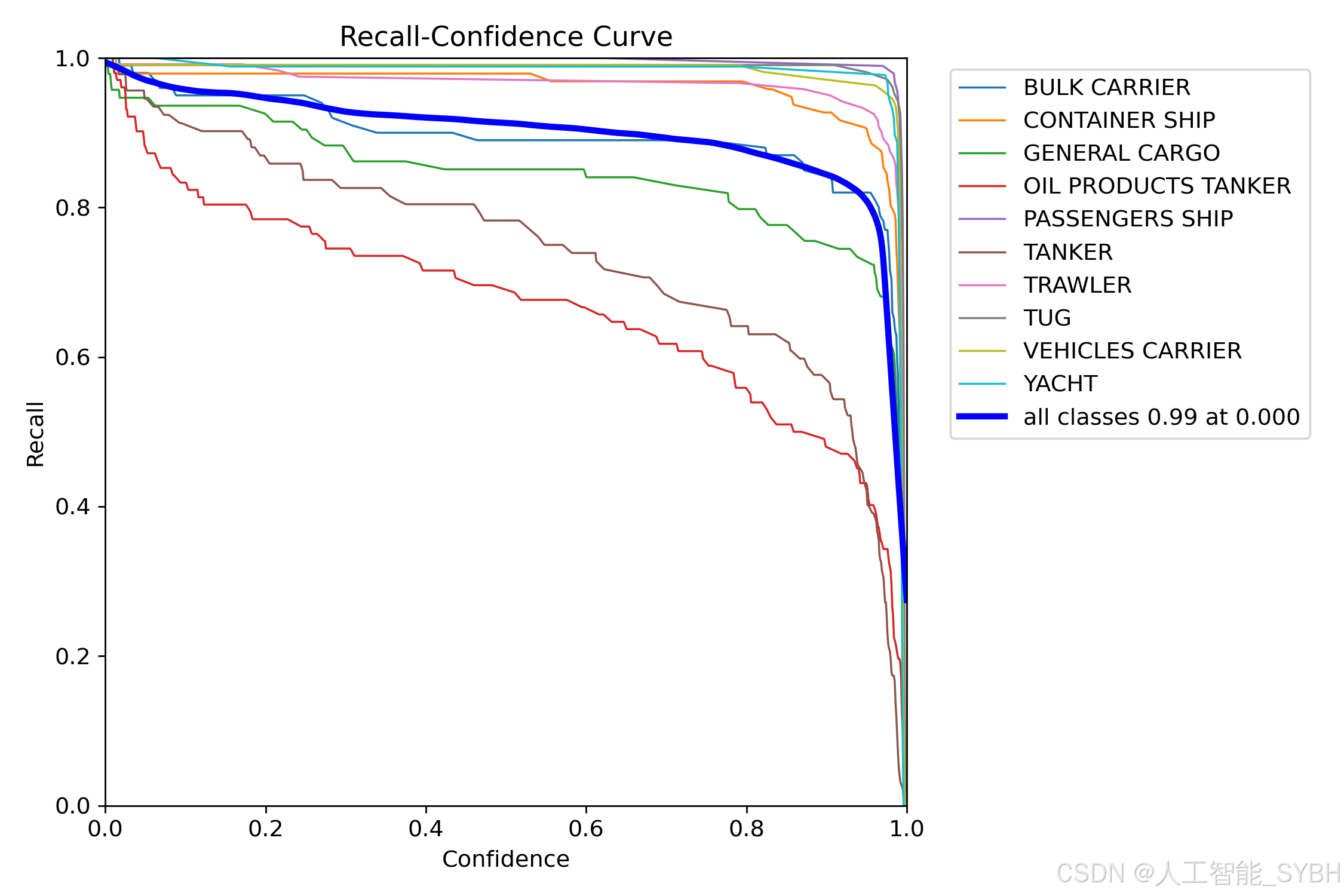






六、核心代码
# -*- coding: utf-8 -*-
import os
import sys
import time
import cv2
import numpy as np
from PIL import ImageFont
from PyQt5.QtCore import Qt, QTimer, QThread, pyqtSignal, QCoreApplication
from PyQt5.QtWidgets import (QApplication, QMainWindow, QFileDialog,
QMessageBox, QWidget, QHeaderView,
QTableWidgetItem, QAbstractItemView)
from ultralytics import YOLO
# 自定义模块导入
sys.path.append('UIProgram')
from UIProgram.UiMain import Ui_MainWindow
from UIProgram.QssLoader import QSSLoader
from UIProgram.precess_bar import ProgressBar
import detect_tools as tools
import Config
class DetectionApp(QMainWindow):
def __init__(self, parent=None):
super().__init__(parent)
self.ui = Ui_MainWindow()
self.ui.setupUi(self)
# 初始化应用
self._setup_ui()
self._connect_signals()
self._load_stylesheet()
# 模型和资源初始化
self._init_detection_resources()
def _setup_ui(self):
"""初始化UI界面设置"""
self.display_width = 700
self.display_height = 500
self.source_path = None
self.camera_active = False
self.video_capture = None
# 配置表格控件
table = self.ui.tableWidget
table.verticalHeader().setSectionResizeMode(QHeaderView.Fixed)
table.verticalHeader().setDefaultSectionSize(40)
table.setColumnWidth(0, 80) # ID列
table.setColumnWidth(1, 200) # 路径列
table.setColumnWidth(2, 150) # 类别列
table.setColumnWidth(3, 90) # 置信度列
table.setColumnWidth(4, 230) # 位置列
table.setSelectionBehavior(QAbstractItemView.SelectRows)
table.verticalHeader().setVisible(False)
table.setAlternatingRowColors(True)
def _connect_signals(self):
"""连接按钮信号与槽函数"""
self.ui.PicBtn.clicked.connect(self._handle_image_input)
self.ui.comboBox.activated.connect(self._update_selection)
self.ui.VideoBtn.clicked.connect(self._handle_video_input)
self.ui.CapBtn.clicked.connect(self._toggle_camera)
self.ui.SaveBtn.clicked.connect(self._save_results)
self.ui.ExitBtn.clicked.connect(QCoreApplication.quit)
self.ui.FilesBtn.clicked.connect(self._process_image_batch)
def _load_stylesheet(self):
"""加载CSS样式表"""
style_file = 'UIProgram/style.css'
qss = QSSLoader.read_qss_file(style_file)
self.setStyleSheet(qss)
def _init_detection_resources(self):
"""初始化检测相关资源"""
# 加载YOLOv8模型
self.detector = YOLO('runs/detect/exp/weights/best.pt', task='detect')
self.detector(np.zeros((48, 48, 3))) # 预热模型
# 初始化字体和颜色
self.detection_font = ImageFont.truetype("Font/platech.ttf", 25, 0)
self.color_palette = tools.Colors()
# 初始化定时器
self.frame_timer = QTimer()
self.save_timer = QTimer()
def _handle_image_input(self):
"""处理单张图片输入"""
self._stop_video_capture()
file_path, _ = QFileDialog.getOpenFileName(
self, '选择图片', './', "图片文件 (*.jpg *.jpeg *.png)")
if not file_path:
return
self._process_single_image(file_path)
def _process_single_image(self, image_path):
"""处理并显示单张图片的检测结果"""
self.source_path = image_path
self.ui.comboBox.setEnabled(True)
# 读取并检测图片
start_time = time.time()
detection_results = self.detector(image_path)[0]
processing_time = time.time() - start_time
# 解析检测结果
boxes = detection_results.boxes.xyxy.tolist()
self.detection_boxes = [list(map(int, box)) for box in boxes]
self.detection_classes = detection_results.boxes.cls.int().tolist()
confidences = detection_results.boxes.conf.tolist()
self.confidence_scores = [f'{score * 100:.2f}%' for score in confidences]
# 更新UI显示
self._update_detection_display(detection_results, processing_time)
self._update_object_selection()
self._show_detection_details()
self._display_results_table(image_path)
def _update_detection_display(self, results, process_time):
"""更新检测结果显示"""
# 显示处理时间
self.ui.time_lb.setText(f'{process_time:.3f} s')
# 获取带标注的图像
annotated_img = results.plot()
self.current_result = annotated_img
# 调整并显示图像
width, height = self._calculate_display_size(annotated_img)
resized_img = cv2.resize(annotated_img, (width, height))
qimage = tools.cvimg_to_qpiximg(resized_img)
self.ui.label_show.setPixmap(qimage)
self.ui.label_show.setAlignment(Qt.AlignCenter)
self.ui.PiclineEdit.setText(self.source_path)
# 更新检测数量
self.ui.label_nums.setText(str(len(self.detection_classes)))
def _calculate_display_size(self, image):
"""计算适合显示的图像尺寸"""
img_height, img_width = image.shape[:2]
aspect_ratio = img_width / img_height
if aspect_ratio >= self.display_width / self.display_height:
width = self.display_width
height = int(width / aspect_ratio)
else:
height = self.display_height
width = int(height * aspect_ratio)
return width, height
def _update_object_selection(self):
"""更新目标选择下拉框"""
options = ['全部']
target_labels = [
f'{Config.names[cls_id]}_{idx}'
for idx, cls_id in enumerate(self.detection_classes)
]
options.extend(target_labels)
self.ui.comboBox.clear()
self.ui.comboBox.addItems(options)
def _show_detection_details(self, index=0):
"""显示检测目标的详细信息"""
if not self.detection_boxes:
self._clear_detection_details()
return
box = self.detection_boxes[index]
self.ui.type_lb.setText(Config.CH_names[self.detection_classes[index]])
self.ui.label_conf.setText(self.confidence_scores[index])
self.ui.label_xmin.setText(str(box[0]))
self.ui.label_ymin.setText(str(box[1]))
self.ui.label_xmax.setText(str(box[2]))
self.ui.label_ymax.setText(str(box[3]))
def _clear_detection_details(self):
"""清空检测详情显示"""
self.ui.type_lb.setText('')
self.ui.label_conf.setText('')
self.ui.label_xmin.setText('')
self.ui.label_ymin.setText('')
self.ui.label_xmax.setText('')
self.ui.label_ymax.setText('')
def _display_results_table(self, source_path):
"""在表格中显示检测结果"""
table = self.ui.tableWidget
table.setRowCount(0)
table.clearContents()
for idx, (box, cls_id, conf) in enumerate(zip(
self.detection_boxes, self.detection_classes, self.confidence_scores)):
row = table.rowCount()
table.insertRow(row)
# 添加表格项
items = [
QTableWidgetItem(str(row + 1)), # ID
QTableWidgetItem(source_path), # 路径
QTableWidgetItem(Config.CH_names[cls_id]), # 类别
QTableWidgetItem(conf), # 置信度
QTableWidgetItem(str(box)) # 位置坐标
]
# 设置文本居中
for item in [items[0], items[2], items[3]]:
item.setTextAlignment(Qt.AlignCenter)
# 添加到表格
for col, item in enumerate(items):
table.setItem(row, col, item)
table.scrollToBottom()
def _process_image_batch(self):
"""批量处理图片"""
self._stop_video_capture()
folder = QFileDialog.getExistingDirectory(self, "选择图片文件夹", "./")
if not folder:
return
self.source_path = folder
valid_extensions = {'jpg', 'png', 'jpeg', 'bmp'}
for filename in os.listdir(folder):
filepath = os.path.join(folder, filename)
if (os.path.isfile(filepath) and
filename.split('.')[-1].lower() in valid_extensions):
self._process_single_image(filepath)
QApplication.processEvents() # 保持UI响应
def _update_selection(self):
"""更新用户选择的检测目标显示"""
selection = self.ui.comboBox.currentText()
if selection == '全部':
boxes = self.detection_boxes
display_img = self.current_result
self._show_detection_details(0)
else:
idx = int(selection.split('_')[-1])
boxes = [self.detection_boxes[idx]]
display_img = self.detector(self.source_path)[0][idx].plot()
self._show_detection_details(idx)
# 更新显示
width, height = self._calculate_display_size(display_img)
resized_img = cv2.resize(display_img, (width, height))
qimage = tools.cvimg_to_qpiximg(resized_img)
self.ui.label_show.clear()
self.ui.label_show.setPixmap(qimage)
self.ui.label_show.setAlignment(Qt.AlignCenter)
def _handle_video_input(self):
"""处理视频输入"""
if self.camera_active:
self._toggle_camera()
video_path = self._get_video_path()
if not video_path:
return
self._start_video_processing(video_path)
self.ui.comboBox.setEnabled(False)
def _get_video_path(self):
"""获取视频文件路径"""
path, _ = QFileDialog.getOpenFileName(
self, '选择视频', './', "视频文件 (*.avi *.mp4)")
if path:
self.source_path = path
self.ui.VideolineEdit.setText(path)
return path
return None
def _start_video_processing(self, video_path):
"""开始处理视频流"""
self.video_capture = cv2.VideoCapture(video_path)
self.frame_timer.start(1)
self.frame_timer.timeout.connect(self._process_video_frame)
def _stop_video_capture(self):
"""停止视频捕获"""
if self.video_capture:
self.video_capture.release()
self.frame_timer.stop()
self.camera_active = False
self.ui.CaplineEdit.setText('摄像头未开启')
self.video_capture = None
def _process_video_frame(self):
"""处理视频帧"""
ret, frame = self.video_capture.read()
if not ret:
self._stop_video_capture()
return
# 执行目标检测
start_time = time.time()
results = self.detector(frame)[0]
processing_time = time.time() - start_time
# 解析结果
self.detection_boxes = results.boxes.xyxy.int().tolist()
self.detection_classes = results.boxes.cls.int().tolist()
self.confidence_scores = [f'{conf * 100:.2f}%' for conf in results.boxes.conf.tolist()]
# 更新显示
self._update_detection_display(results, processing_time)
self._update_object_selection()
self._show_detection_details()
self._display_results_table(self.source_path)
def _toggle_camera(self):
"""切换摄像头状态"""
self.camera_active = not self.camera_active
if self.camera_active:
self.ui.CaplineEdit.setText('摄像头开启')
self.video_capture = cv2.VideoCapture(0)
self._start_video_processing(0)
self.ui.comboBox.setEnabled(False)
else:
self.ui.CaplineEdit.setText('摄像头未开启')
self.ui.label_show.clear()
self._stop_video_capture()
def _save_results(self):
"""保存检测结果"""
if not self.video_capture and not self.source_path:
QMessageBox.information(self, '提示', '没有可保存的内容,请先打开图片或视频!')
return
if self.camera_active:
QMessageBox.information(self, '提示', '无法保存摄像头实时视频!')
return
if self.video_capture:
self._save_video_result()
else:
self._save_image_result()
def _save_video_result(self):
"""保存视频检测结果"""
confirm = QMessageBox.question(
self, '确认',
'保存视频可能需要较长时间,确定继续吗?',
QMessageBox.Yes | QMessageBox.No)
if confirm == QMessageBox.No:
return
self._stop_video_capture()
saver = VideoSaverThread(
self.source_path, self.detector,
self.ui.comboBox.currentText())
saver.start()
saver.update_ui_signal.connect(self._update_progress)
def _save_image_result(self):
"""保存图片检测结果"""
if os.path.isfile(self.source_path):
# 处理单张图片
filename = os.path.basename(self.source_path)
name, ext = filename.rsplit(".", 1)
save_name = f"{name}_detect_result.{ext}"
save_path = os.path.join(Config.save_path, save_name)
cv2.imwrite(save_path, self.current_result)
QMessageBox.information(
self, '完成',
f'图片已保存至: {save_path}')
else:
# 处理文件夹中的图片
valid_exts = {'jpg', 'png', 'jpeg', 'bmp'}
for filename in os.listdir(self.source_path):
if filename.split('.')[-1].lower() in valid_exts:
filepath = os.path.join(self.source_path, filename)
name, ext = filename.rsplit(".", 1)
save_name = f"{name}_detect_result.{ext}"
save_path = os.path.join(Config.save_path, save_name)
results = self.detector(filepath)[0]
cv2.imwrite(save_path, results.plot())
QMessageBox.information(
self, '完成',
f'所有图片已保存至: {Config.save_path}')
def _update_progress(self, current, total):
"""更新保存进度"""
if current == 1:
self.progress_dialog = ProgressBar(self)
self.progress_dialog.show()
if current >= total:
self.progress_dialog.close()
QMessageBox.information(
self, '完成',
f'视频已保存至: {Config.save_path}')
return
if not self.progress_dialog.isVisible():
return
percent = int(current / total * 100)
self.progress_dialog.setValue(current, total, percent)
QApplication.processEvents()
class VideoSaverThread(QThread):
"""视频保存线程"""
update_ui_signal = pyqtSignal(int, int)
def __init__(self, video_path, model, selection):
super().__init__()
self.video_path = video_path
self.detector = model
self.selection = selection
self.active = True
self.colors = tools.Colors()
def run(self):
"""执行视频保存"""
cap = cv2.VideoCapture(self.video_path)
fourcc = cv2.VideoWriter_fourcc(*'XVID')
fps = cap.get(cv2.CAP_PROP_FPS)
size = (
int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
filename = os.path.basename(self.video_path)
name, _ = filename.split('.')
save_path = os.path.join(
Config.save_path,
f"{name}_detect_result.avi")
writer = cv2.VideoWriter(save_path, fourcc, fps, size)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
current_frame = 0
while cap.isOpened() and self.active:
current_frame += 1
ret, frame = cap.read()
if not ret:
break
# 执行检测
results = self.detector(frame)[0]
frame = results.plot()
writer.write(frame)
self.update_ui_signal.emit(current_frame, total_frames)
# 释放资源
cap.release()
writer.release()
def stop(self):
"""停止保存过程"""
self.active = False
if __name__ == "__main__":
app = QApplication(sys.argv)
window = DetectionApp()
window.show()
sys.exit(app.exec_())七、项目源码
演示与介绍视频:
基于深度学习的船舶类型识别检测系统(YOLOv8+YOLO数据集+UI界面+Python项目源码+模型)_哔哩哔哩_bilibili
基于深度学习的船舶类型识别检测系统(YOLOv8+YOLO数据集+UI界面+Python项目源码+模型)

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 21
21 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)