深度学习-长短期记忆网络(LSTM)
LSTM 通过精妙的门控机制解决了 RNN 的长期依赖问题,成为处理文本等时序数据的强大工具。本文从原理出发,结合手动实现和 PyTorch 内置 API 的代码,展示了 LSTM 的工作流程。实际应用中,可根据需求调整隐藏层维度、序列长度等参数,进一步提升模型性能。
从原理到代码:用 LSTM 实现文本预测的全解析
在循环神经网络(RNN)的家族中,长短期记忆网络(LSTM)凭借解决长期依赖问题的能力,成为处理时序数据(如文本、语音)的利器。本文将结合一段基于 PyTorch 的 LSTM 文本预测代码,从原理到实现逐步拆解,带你理解 LSTM 的工作机制。
一、为什么需要 LSTM?
传统 RNN 在处理长序列时,会因梯度消失或梯度爆炸问题,难以记住早期重要信息(比如一句话开头提到的 "他",到句尾可能已被模型遗忘)。LSTM 通过设计门控机制,能自主决定保留、更新或丢弃信息,从而有效捕捉长距离依赖关系。
二、LSTM 的核心结构:四大门控与细胞状态
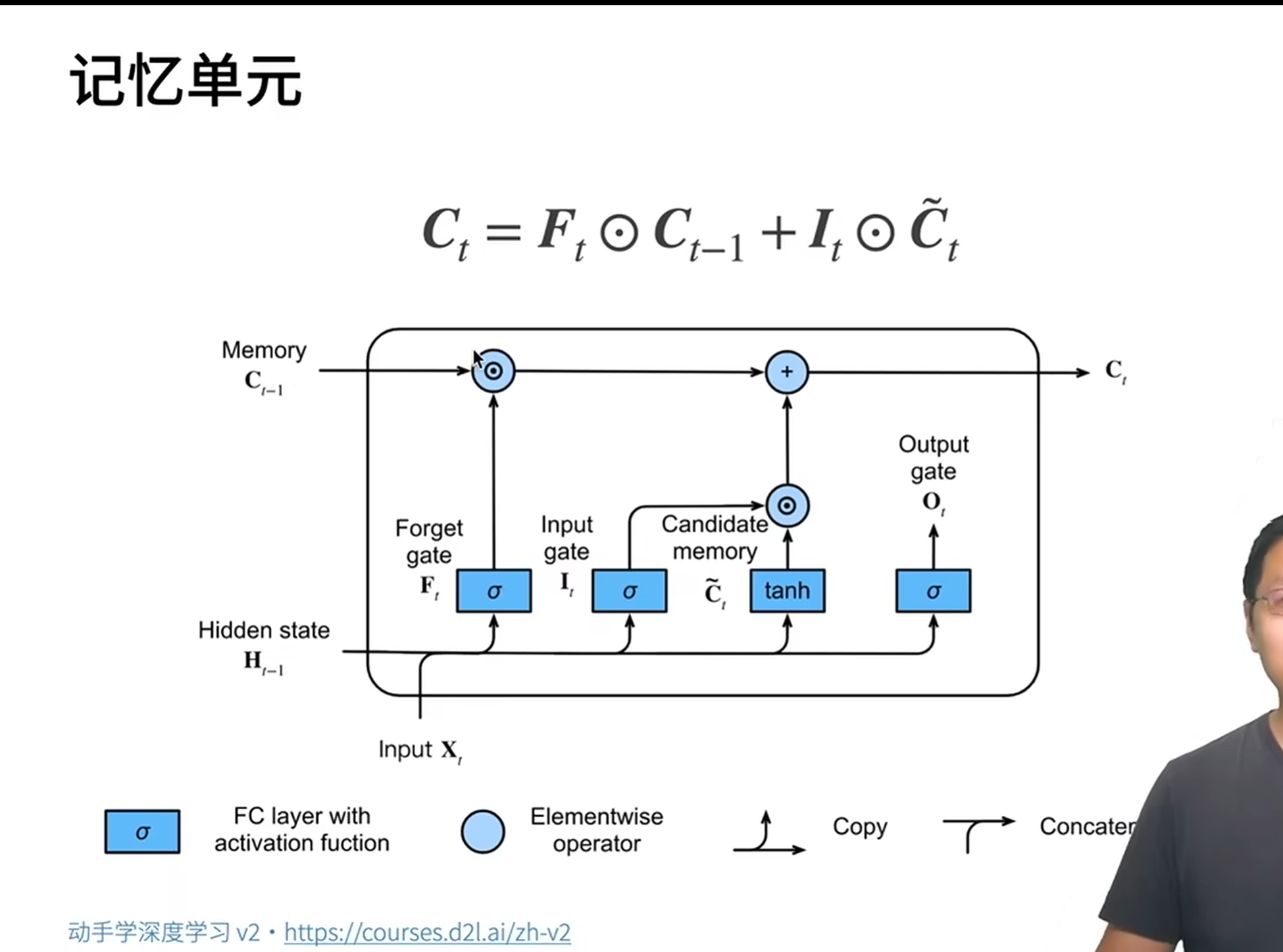
LSTM 的核心是细胞状态(Cell State),类似一条贯穿网络的 "信息高速公路",信息在此处可被选择性修改。而修改的权力由三个门控组件掌控:
1.遗忘门(Forget Gate)
决定从细胞状态中丢弃哪些信息。通过 sigmoid 函数输出 0-1 之间的值,1 表示完全保留,0 表示彻底遗忘。公式为:
2.输入门(Input Gate)
决定哪些新信息会被存入细胞状态。包含两部分:
用 sigmoid 函数筛选需更新的信息:
用 tanh 生成候选更新信息:

3 .细胞状态更新
结合遗忘门和输入门的结果,更新细胞状态:
4 输出门(Output Gate)
决定当前隐藏状态Ht的输出。先用 sigmoid 筛选输出信息,再用 tanh 压缩细胞状态后相乘:
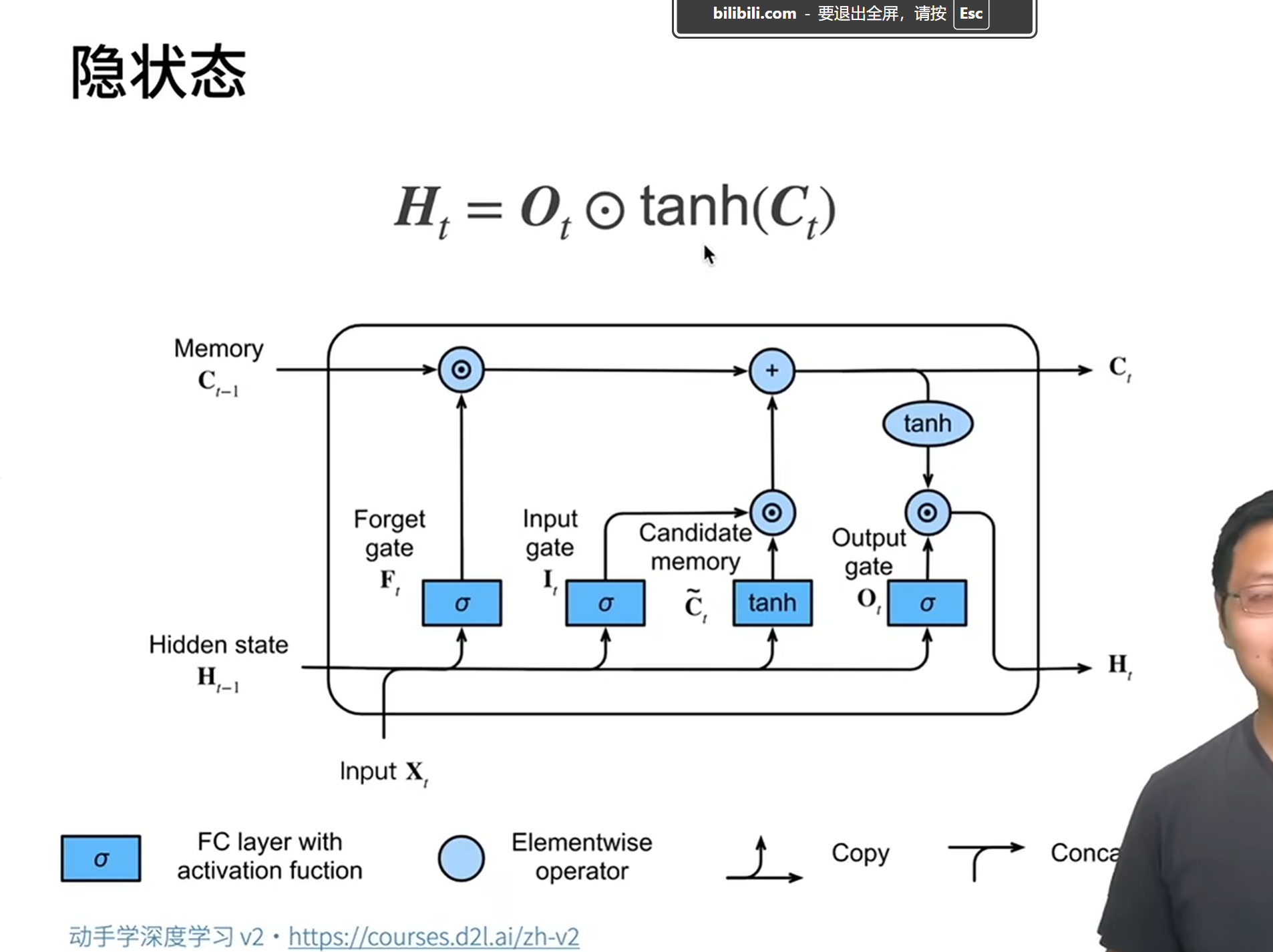
通过这一套机制,LSTM 能灵活控制信息的流动,既保留关键历史信息,又能纳入新内容。
三、代码解析:用 LSTM 预测《时间机器》文本
下面结合代码,看看如何用 LSTM 实现文本预测(以 H.G. 威尔斯的《时间机器》为训练数据)。
1. 数据准备
batch_size, num_steps = 32, 35 # 批量大小、序列长度
train_iter, vocab = NaturalLanguage_Dataset.load_data_time_machine(batch_size, num_steps)load_data_time_machine将文本转换为批量序列:每个样本是长度为num_steps的字符索引,标签是下一个字符的索引(用于预测)。vocab是字符到索引的映射表,方便将文本数字化。
2. 手动实现 LSTM(理解底层逻辑)
(1)初始化参数
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size # 输入/输出维度=词汇表大小
def normal(shape): # 正态分布初始化参数
return torch.randn(size=shape, device=device) * 0.01
def three(): # 生成门控参数(输入权重、隐藏层权重、偏置)
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
# 遗忘门、输入门、输出门、候选记忆参数
w_xi, w_hi, b_i = three() # 输入门
w_xf, w_hf, b_f = three() # 遗忘门
w_xo, w_ho, b_o = three() # 输出门
w_xc, w_hc, b_c = three() # 候选记忆
# 输出层参数(从隐藏状态映射到词汇表)
w_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
params = [w_xi, w_hi, b_i, w_xf, w_hf, b_f, w_xo, w_ho, b_o,
w_xc, w_hc, b_c, w_hq, b_q]
for param in params:
param.requires_grad_(True) # 开启梯度计算
return params- 每个门控都需要三组参数:输入
X的权重、上一隐藏状态H的权重、偏置项。 - 参数通过正态分布初始化,保证初始值较小且随机,避免梯度问题。
(2)初始化隐藏状态
def init_lstm_params(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), # 隐藏状态H
torch.zeros((batch_size, num_hiddens), device=device)) # 细胞状态C- LSTM 的隐藏状态包含两部分:
H(用于输出)和C(细胞状态),初始均设为 0。
(3)LSTM 前向传播逻辑
def lstm(inputs, state, params):
# 解析参数和状态
w_xi, w_hi, b_i, w_xf, w_hf, b_f, w_xo, w_ho, b_o,
w_xc, w_hc, b_c, w_hq, b_q = params
(H, C) = state # 上一时刻的隐藏状态和细胞状态
outputs = []
for X in inputs: # 遍历序列中的每个时间步
# 1. 计算输入门、遗忘门、输出门
I = torch.sigmoid((X @ w_xi) + (H @ w_hi) + b_i) # 输入门
F = torch.sigmoid((X @ w_xf) + (H @ w_hf) + b_f) # 遗忘门
O = torch.sigmoid((X @ w_xo) + (H @ w_ho) + b_o) # 输出门
# 2. 计算候选细胞状态
C_tilta = torch.tanh((X @ w_xc) + (H @ w_hc) + b_c)
# 3. 更新细胞状态(遗忘旧信息+加入新信息)
C = F * C + I * C_tilta
# 4. 更新隐藏状态
H = O * torch.tanh(C)
# 5. 计算当前时间步的输出(预测下一个字符)
Y = (H @ w_hq) + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C) # 拼接所有输出,返回新状态- 这段代码严格对应 LSTM 的数学公式:每个时间步都按 "门控计算→状态更新→输出预测" 的流程执行。
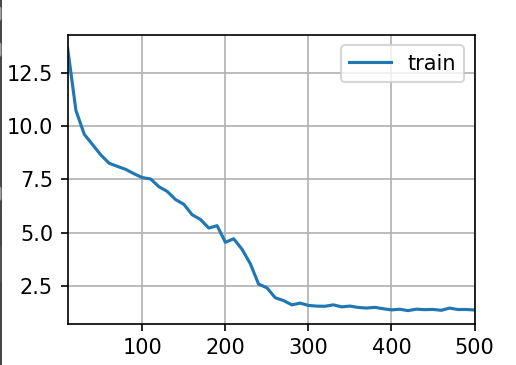
开始训练:
vocab_size,num_hiddens,device=len(vocab),256,d2l.try_gpu()
num_epochs,lr=500,1
model=RNNFromScratch.RNNModuleScratch(vocab_size,num_hiddens,device,get_lstm_params,init_lstm_params,lstm)
RNNFromScratch.train_ch8(model,train_iter,vocab,lr,num_epochs,device)
plt.show()输出结果:

3. 简洁实现(用 PyTorch 内置 LSTM)
手动实现有助于理解原理,实际应用中可直接使用 PyTorch 的nn.LSTM:
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens) # 内置LSTM层
model = RNNSimple.RNNModule(lstm_layer, len(vocab)) # 封装为预测模型
model = model.to(device)nn.LSTM已优化了底层实现,支持批量处理和双向循环等功能,使用时只需指定输入维度和隐藏层维度。
4. 训练与预测
num_epochs, lr = 500, 1 # 训练轮次、学习率
RNNFromScratch.train_ch8(model, train_iter, vocab, lr, num_epochs, device)- 训练过程通过最大化预测下一个字符的概率来优化模型参数。
- 训练完成后,模型可根据输入的前缀字符,自动生成类似《时间机器》风格的文本。
输出结果:
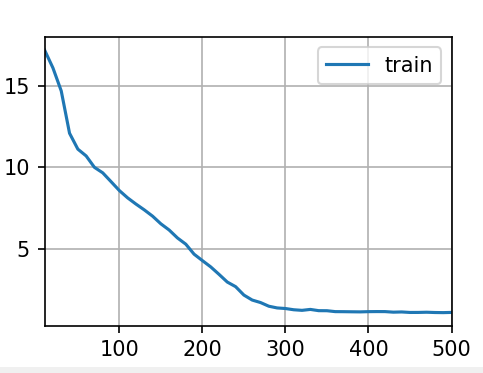

注:由于我的d2l版本里面不存在train_ch8()这个函数,RNNModule类以及相关的,所以我是用的是我自己编写的函数,这样子虽然是可以直接调用,但是效率是没有别人写的代码效率高,所以第二次的困惑度还是1.4。
import NaturalLanguage_Dataset
import RNNFromScratch
import RNNSimple
上面这些python文件的导入就是为了方便可以直接调用LSTM相关的方法,而不需要一个一个重新去实现。
四、总结
LSTM 通过精妙的门控机制解决了 RNN 的长期依赖问题,成为处理文本等时序数据的强大工具。本文从原理出发,结合手动实现和 PyTorch 内置 API 的代码,展示了 LSTM 的工作流程。实际应用中,可根据需求调整隐藏层维度、序列长度等参数,进一步提升模型性能。
五、代码汇总
import torch
from torch import nn
from d2l import torch as d2l
import NaturalLanguage_Dataset
import RNNFromScratch
import RNNSimple
import matplotlib.pyplot as plt
batch_size,num_steps=32,35
train_iter,vocab=NaturalLanguage_Dataset.load_data_time_machine(batch_size,num_steps)
#初始化模型参数
def get_lstm_params(vocab_size,num_hiddens,device):
num_inputs=num_outputs=vocab_size
def normal(shape):
return torch.randn(size=shape,device=device)*0.01
def three():
return (normal((num_inputs,num_hiddens)),
normal((num_hiddens,num_hiddens)),
torch.zeros(num_hiddens,device=device))
w_xi,w_hi,b_i=three()#输入门参数
w_xf,w_hf,b_f=three()#遗忘门参数
w_xo,w_ho,b_o=three()#输出门参数
w_xc,w_hc,b_c=three()#候选记忆门参数
w_hq=normal((num_hiddens,num_outputs))
b_q=torch.zeros(num_outputs,device=device)
params=[w_xi,w_hi,b_i,w_xf,w_hf,b_f,w_xo,w_ho,b_o,w_xc,w_hc,b_c,w_hq,b_q]
for param in params:
param.requires_grad_(True)
return params
#定义模型
def init_lstm_params(batch_size,num_hiddens,device):
return (torch.zeros((batch_size,num_hiddens),device=device),
torch.zeros((batch_size,num_hiddens),device=device))
def lstm(inputs,state,params):
w_xi, w_hi, b_i, w_xf, w_hf, b_f, w_xo, w_ho, b_o, w_xc, w_hc, b_c, w_hq, b_q=params
(H,C)=state
outputs=[]
for X in inputs:
I=torch.sigmoid((X@w_xi)+(H@w_hi)+b_i)
F=torch.sigmoid((X@w_xf)+(H@w_hf)+b_f)
O=torch.sigmoid((X@w_xo)+(H@w_ho)+b_o)
C_tilta=torch.tanh((X@w_xc)+(H@w_hc)+b_c)
C=F*C+I*C_tilta
H=O*torch.tanh(C)
Y=(H@w_hq)+b_q
outputs.append(Y)
return torch.cat(outputs,dim=0),(H,C)
vocab_size,num_hiddens,device=len(vocab),256,d2l.try_gpu()
num_epochs,lr=500,1
model=RNNFromScratch.RNNModuleScratch(vocab_size,num_hiddens,device,get_lstm_params,init_lstm_params,lstm)
# RNNFromScratch.train_ch8(model,train_iter,vocab,lr,num_epochs,device)
# plt.show()
#简洁实现
num_inputs=vocab_size
lstm_layer=nn.LSTM(num_inputs,num_hiddens)
model=RNNSimple.RNNModule(lstm_layer,len(vocab))
model=model.to(device)
RNNFromScratch.train_ch8(model,train_iter,vocab,lr,num_epochs,device)
plt.show()

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)