30李沐动手学深度学习v2/使用块的网络,VGG
29李沐动手学深度学习v2/使用块的网络,VGG
·
VGG块
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
'''
vgg块, 卷积层数量,输入通道数量,输出通道数量
:param num_convs 块中卷积层数量
:param in_channels 块中输入通道数量
:param out_channels 块中输出通道数量
'''
# vgg块
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
# 前1个卷积层的输出通道是下1个卷积层的输入通道
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
VGG网络
# 5个vgg块,(vgg块中卷积层数量,输出通道数)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
# 给我一个vgg的架构
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
# *tuple入参
return nn.Sequential(
*conv_blks,
# 展平层
nn.Flatten(),
# 最后1个卷积层的输出通道数x最后1个卷积层输出图片宽*高
nn.Linear(out_channels * 7 * 7, 4096),
# 非线性单元
# 简单线性函数模拟复杂非线性函数的根本
# ReLU数值稳定性好,避免梯度消失或爆炸
nn.ReLU(),
# 可以使用复杂的模型,模型容量大的模型,使用正则化方法避免复杂模型过拟合
# 正则化,限制w的取值范围,取得更平滑的曲线,降低过拟合,提高泛化能力
# 丢弃法,以概率p置零隐藏层的全连接层的输出
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 10个类别
nn.Linear(4096, 10))
net = vgg(conv_arch)
# 我们构造一个 单通道数据,来观察每一层输出的形状
X = torch.randn(size=(1, 1, 224, 224))
# !这种方式可以观察每一块的输出的shape,而不用pytorch提供的函数
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t',X.shape)
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
# vgg11(8个卷积层+3个全连接层) 卷积层加全连接层
# 由于VGG-11比AlexNet计算量更大,因此我们构建了一个通道数较少的网络
ratio = 4
# 把输出通道数除4,向下取整
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
# 模型训练
lr, num_epochs, batch_size = 0.05, 10, 128
# Fashion-MNIST图像的分辨率=28x28 < ImageNet的分辨率,reshape到224×224
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
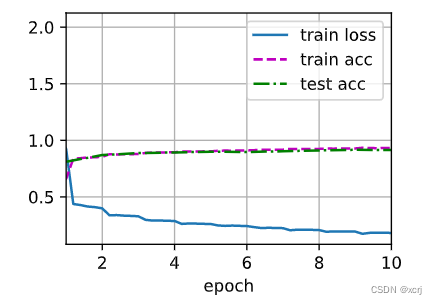
loss 0.182, train acc 0.932, test acc 0.915
2260.1 examples/sec on cuda:0
总结
- vgg超参数,vgg块数量,vgg块中卷积层数量,输出通道数)
- conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)