【完整源码+数据集+部署教程】云与太阳检测系统源码和数据集:改进yolo11-convnextv2
【完整源码+数据集+部署教程】云与太阳检测系统源码和数据集:改进yolo11-convnextv2
背景意义
随着全球气候变化的加剧,云层和太阳辐射的监测变得愈发重要。云层的变化不仅影响天气预报,还对太阳能发电的效率产生直接影响。因此,开发一个高效、准确的云与太阳检测系统具有重要的实际意义。传统的云检测方法往往依赖于人工观察或简单的图像处理技术,难以满足实时监测和高精度要求。而深度学习技术的快速发展为解决这一问题提供了新的思路。
YOLO(You Only Look Once)系列模型以其快速和高效的目标检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,结合了先进的卷积神经网络架构,能够在保持高精度的同时实现实时检测。通过对YOLOv11的改进,我们可以更好地适应云与太阳的检测需求,尤其是在复杂的气象条件下。
本研究所使用的数据集“Cloud Master 1.1”包含1200张图像,涵盖了“云”和“太阳”两个类别。这一数据集经过精心标注和预处理,能够为模型的训练提供高质量的输入。数据集的丰富性和多样性使得模型能够学习到不同天气条件下的云层特征,从而提高检测的鲁棒性和准确性。
此外,随着云计算和大数据技术的发展,基于云平台的计算机视觉系统可以实现更高效的数据处理和模型训练。通过将改进的YOLOv11模型与云计算相结合,我们不仅能够实现对云层和太阳的实时监测,还能够为气象研究、环境保护以及可再生能源的利用提供有力支持。
综上所述,基于改进YOLOv11的云与太阳检测系统的研究,不仅具有重要的学术价值,也在实际应用中展现出广阔的前景。通过这一研究,我们希望能够推动计算机视觉技术在气象监测领域的应用,为应对气候变化和推动可持续发展贡献力量。
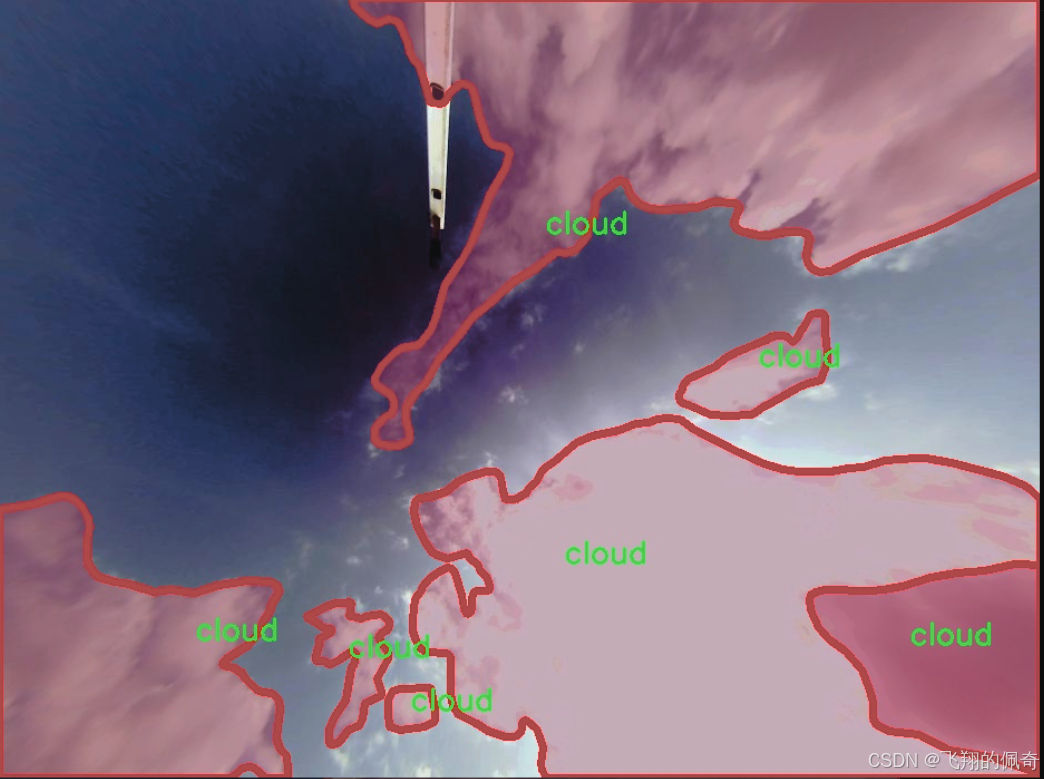
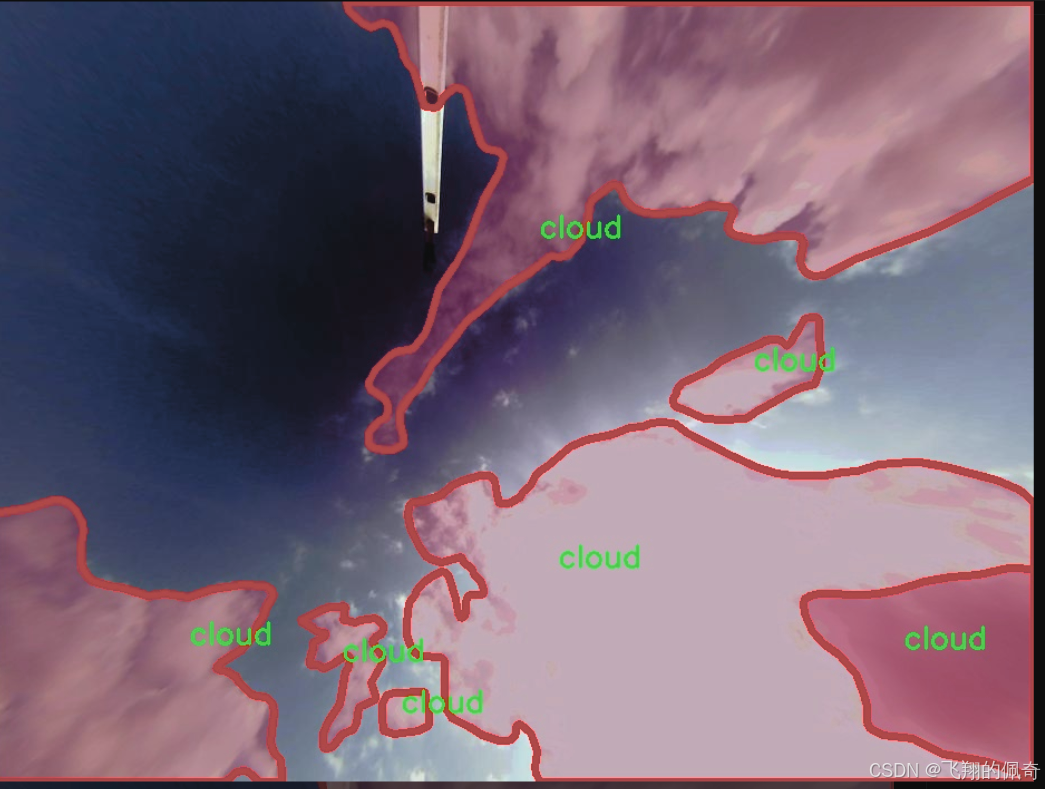
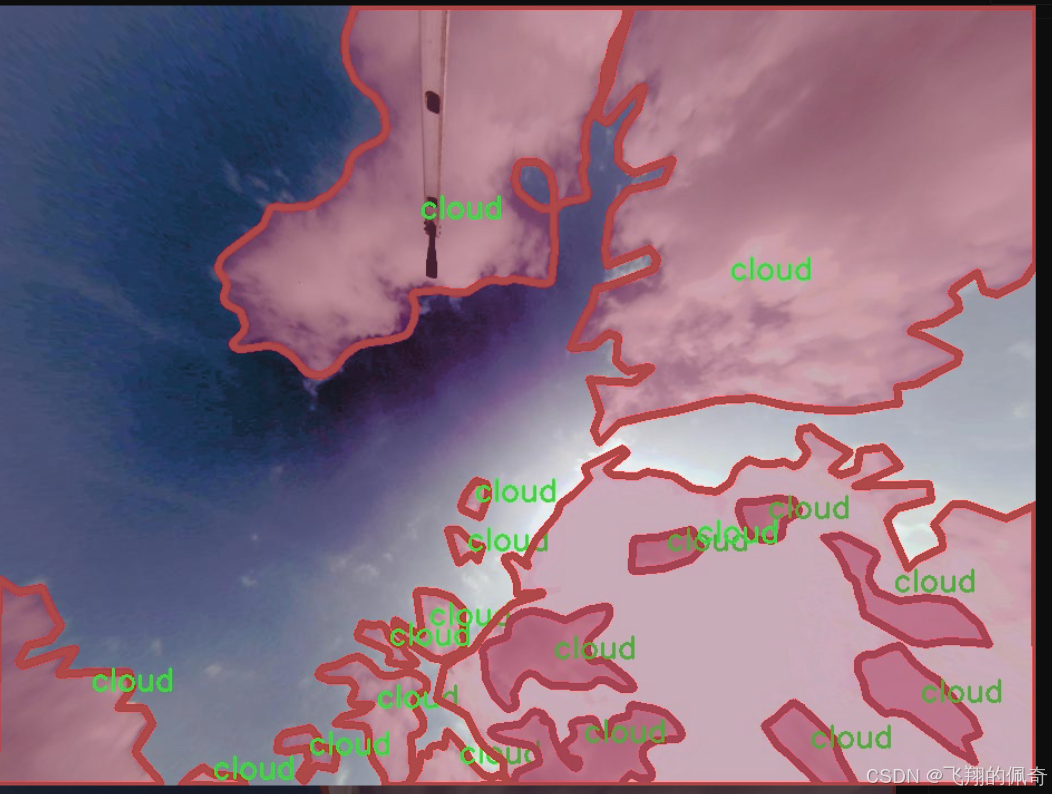
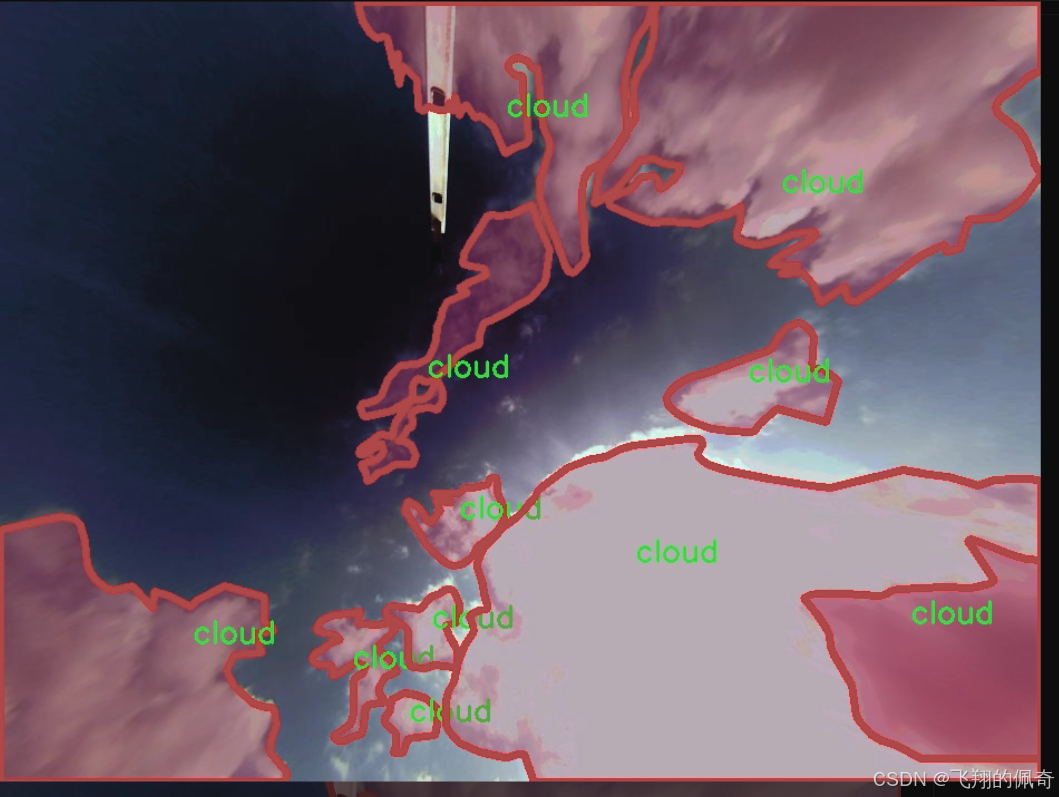
图片效果
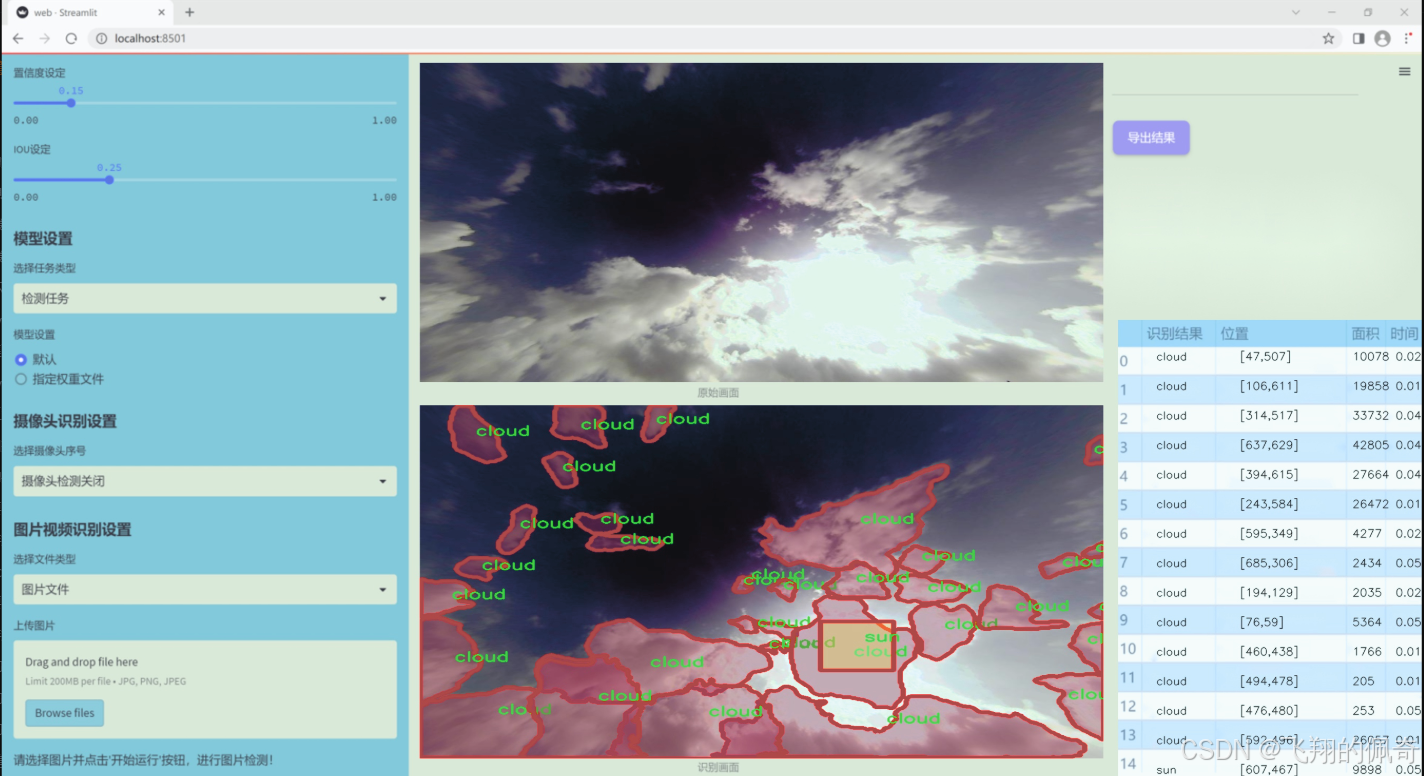
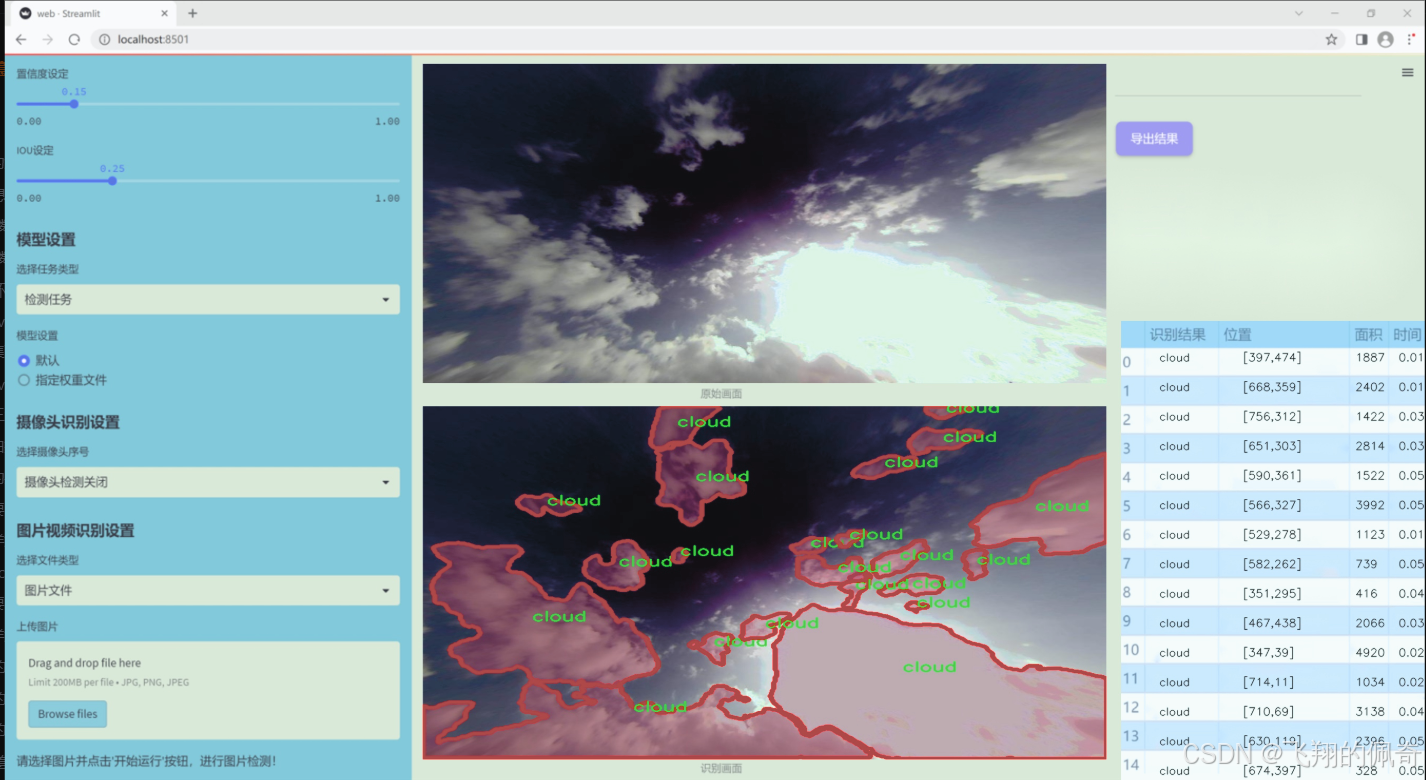
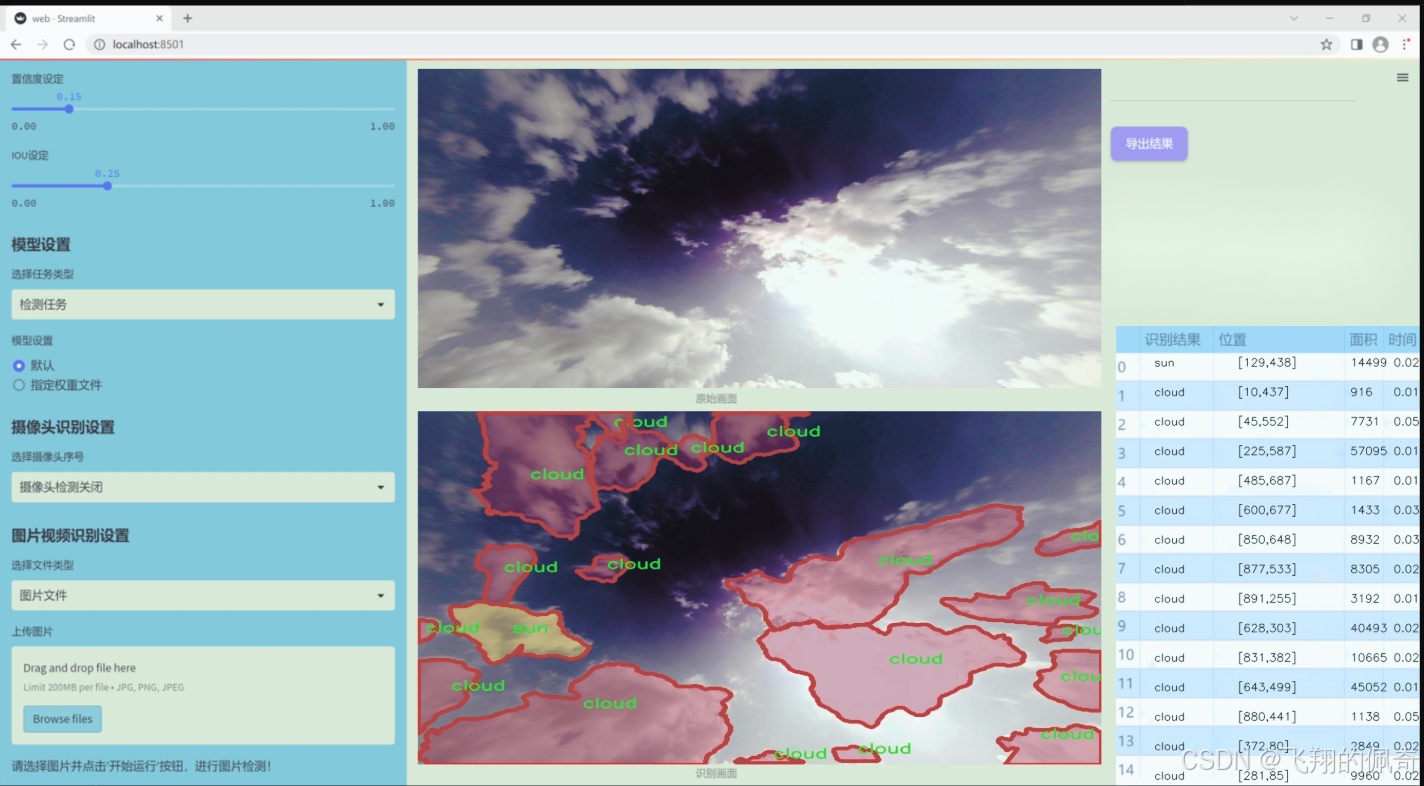
数据集信息
本项目数据集信息介绍
本项目所使用的数据集名为“Cloud Master 1.1”,旨在为改进YOLOv11的云与太阳检测系统提供高质量的训练数据。该数据集专注于两大类目标的识别与分类,具体包括“cloud”(云)和“sun”(太阳),共计包含2个类别。这一数据集的构建旨在提高计算机视觉模型在复杂气象条件下的检测精度,尤其是在多变的天空环境中,云层和太阳的变化对光照和天气预测有着重要影响。
“Cloud Master 1.1”数据集汇集了来自不同气候条件和地理位置的图像,确保了数据的多样性和代表性。数据集中包含的图像不仅涵盖了晴天、阴天、雨天等多种天气情况,还考虑了不同时间段的光照变化,如日出、正午和日落时分。这种多样化的样本选择为模型的训练提供了丰富的背景信息,使其能够在实际应用中更好地适应不同的环境。
此外,数据集中的每一张图像都经过精确标注,确保“cloud”和“sun”这两类目标的边界框清晰可辨。这种高质量的标注不仅提升了模型的学习效率,也为后续的模型评估提供了可靠的基准。通过对“Cloud Master 1.1”数据集的深入分析与训练,期望能够显著提升YOLOv11在云与太阳检测任务中的性能,使其在实时监测和气象分析等领域发挥更大的作用。整体而言,本项目的数据集为实现高效、准确的云与太阳检测系统奠定了坚实的基础。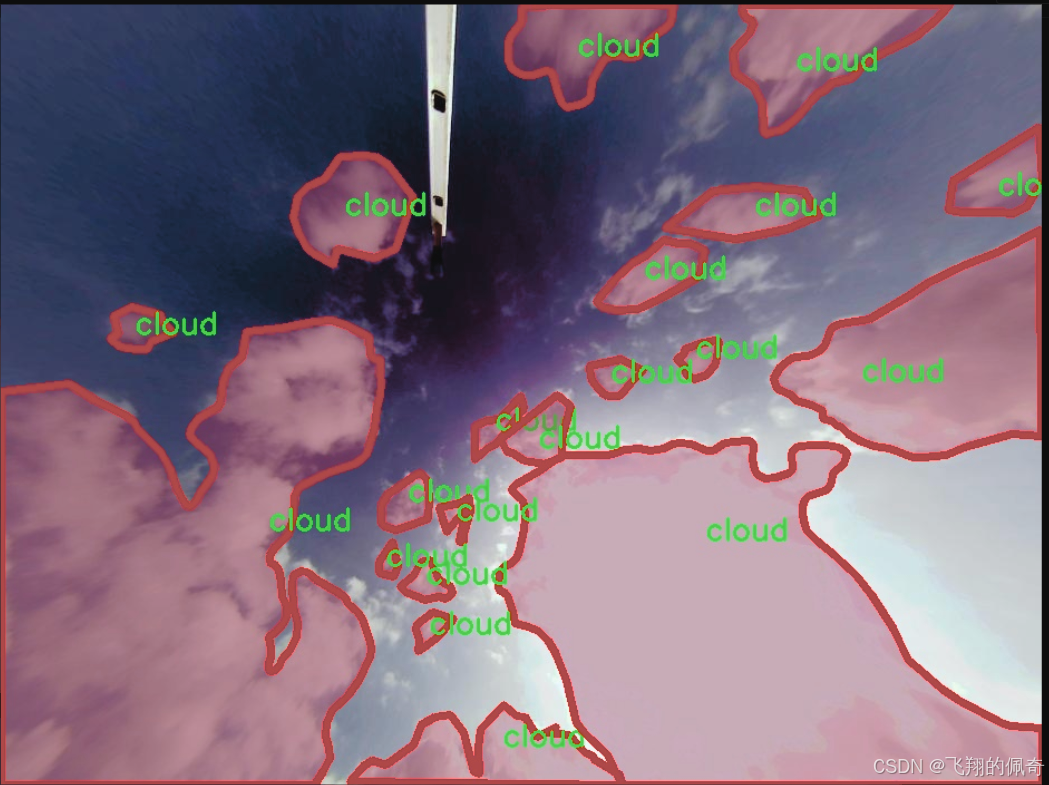
核心代码
以下是保留的核心代码部分,并添加了详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Mlp(nn.Module):
“”" 多层感知机 (MLP) 模块 “”"
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features # 输出特征数
hidden_features = hidden_features or in_features # 隐藏层特征数
self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换
self.act = act_layer() # 激活函数
self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换
self.drop = nn.Dropout(drop) # Dropout层
def forward(self, x):
""" 前向传播 """
x = self.fc1(x) # 线性变换
x = self.act(x) # 激活
x = self.drop(x) # Dropout
x = self.fc2(x) # 线性变换
x = self.drop(x) # Dropout
return x
class WindowAttention(nn.Module):
“”" 基于窗口的多头自注意力 (W-MSA) 模块 “”"
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim # 输入通道数
self.window_size = window_size # 窗口大小
self.num_heads = num_heads # 注意力头数
# 定义相对位置偏置参数表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 位置偏置表
# 计算相对位置索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 生成坐标网格
coords_flatten = torch.flatten(coords, 1) # 展平坐标
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 计算相对坐标
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 变换维度
relative_coords[:, :, 0] += self.window_size[0] - 1 # 偏移
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # 计算相对位置索引
self.register_buffer("relative_position_index", relative_position_index) # 注册为缓冲区
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 线性变换用于生成Q, K, V
self.attn_drop = nn.Dropout(attn_drop) # 注意力权重的Dropout
self.proj = nn.Linear(dim, dim) # 输出线性变换
self.proj_drop = nn.Dropout(proj_drop) # 输出的Dropout
self.softmax = nn.Softmax(dim=-1) # Softmax层
def forward(self, x, mask=None):
""" 前向传播 """
B_, N, C = x.shape # B_: 批量大小, N: 窗口内的token数, C: 通道数
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # 计算Q, K, V
q, k, v = qkv[0], qkv[1], qkv[2] # 提取Q, K, V
q = q * (self.dim // self.num_heads) ** -0.5 # 缩放Q
attn = (q @ k.transpose(-2, -1)) # 计算注意力权重
# 添加相对位置偏置
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # 计算相对位置偏置
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # 变换维度
attn = attn + relative_position_bias.unsqueeze(0) # 加入偏置
attn = self.softmax(attn) # Softmax归一化
attn = self.attn_drop(attn) # Dropout
x = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 计算输出
x = self.proj(x) # 线性变换
x = self.proj_drop(x) # Dropout
return x
class SwinTransformer(nn.Module):
“”" Swin Transformer 主体 “”"
def __init__(self, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], window_size=7):
super().__init__()
self.embed_dim = embed_dim # 嵌入维度
self.num_layers = len(depths) # 层数
# 构建各层
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
dim=int(embed_dim * 2 ** i_layer),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size)
self.layers.append(layer)
def forward(self, x):
""" 前向传播 """
for layer in self.layers:
x = layer(x) # 逐层传递
return x # 返回最终输出
代码说明
Mlp 类:实现了一个简单的多层感知机,包含两层线性变换和激活函数。
WindowAttention 类:实现了窗口自注意力机制,计算注意力权重并考虑相对位置偏置。
SwinTransformer 类:构建了Swin Transformer的主要结构,包含多个基本层(BasicLayer),每层包含自注意力和前馈网络。
这个程序文件实现了Swin Transformer模型的主要结构,Swin Transformer是一种基于Transformer的视觉模型,具有层次化和窗口注意力机制。文件中定义了多个类和函数,以便构建和使用Swin Transformer。
首先,程序导入了必要的库,包括PyTorch和一些用于构建神经网络的模块。接着,定义了一个多层感知机(Mlp)类,它包含两个线性层和一个激活函数,支持dropout以防止过拟合。
接下来,定义了两个辅助函数:window_partition和window_reverse。window_partition将输入特征图分割成多个窗口,而window_reverse则将这些窗口合并回原来的特征图形状。这种窗口划分的方式是Swin Transformer的核心思想之一,有助于降低计算复杂度。
WindowAttention类实现了窗口基础的多头自注意力机制(W-MSA),它支持相对位置偏置。该类的构造函数中定义了查询、键、值的线性变换,以及相对位置偏置的参数表。前向传播函数计算了注意力权重,并将其应用于输入特征。
SwinTransformerBlock类是Swin Transformer的基本构建块,包含一个窗口注意力层和一个前馈网络。它还实现了循环移位的功能,以便在计算注意力时考虑邻近窗口的信息。
PatchMerging类用于将特征图中的补丁合并,以降低特征图的分辨率。BasicLayer类则是Swin Transformer中的一个基本层,包含多个Swin Transformer块,并在必要时进行下采样。
PatchEmbed类负责将输入图像划分为补丁并进行嵌入。SwinTransformer类是整个模型的主类,负责将各个层组合在一起,并实现前向传播。
最后,update_weight函数用于更新模型的权重,SwinTransformer_Tiny函数则是一个工厂函数,用于创建一个小型的Swin Transformer模型,并可选择加载预训练权重。
整体来看,这个程序文件提供了Swin Transformer模型的完整实现,涵盖了从图像嵌入到多层注意力机制的各个方面,适合用于图像分类、目标检测等视觉任务。
10.4 utils.py
以下是经过简化和详细注释的核心代码部分:
import torch
import torch.nn.functional as F
def multi_scale_deformable_attn_pytorch(
value: torch.Tensor,
value_spatial_shapes: torch.Tensor,
sampling_locations: torch.Tensor,
attention_weights: torch.Tensor,
) -> torch.Tensor:
“”"
多尺度可变形注意力机制。
参数:
- value: 输入特征图,形状为 (批量大小, 通道数, 头数, 嵌入维度)
- value_spatial_shapes: 特征图的空间形状,形状为 (层数, 2)
- sampling_locations: 采样位置,形状为 (批量大小, 查询数, 头数, 层数, 采样点数, 2)
- attention_weights: 注意力权重,形状为 (批量大小, 查询数, 头数, 层数, 采样点数)
返回:
- output: 经过多尺度可变形注意力机制处理后的输出,形状为 (批量大小, 查询数, 头数 * 嵌入维度)
"""
bs, _, num_heads, embed_dims = value.shape # 获取输入特征图的形状
_, num_queries, _, num_levels, num_points, _ = sampling_locations.shape # 获取采样位置的形状
# 将输入特征图按照空间形状分割成多个特征图
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1)
# 将采样位置转换到[-1, 1]的范围
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = [] # 用于存储每个层的采样值
for level, (H_, W_) in enumerate(value_spatial_shapes):
# 对每个层的特征图进行处理
value_l_ = value_list[level].flatten(2).transpose(1, 2).reshape(bs * num_heads, embed_dims, H_, W_)
# 获取当前层的采样网格
sampling_grid_l_ = sampling_grids[:, :, :, level].transpose(1, 2).flatten(0, 1)
# 使用双线性插值从特征图中采样
sampling_value_l_ = F.grid_sample(
value_l_, sampling_grid_l_, mode="bilinear", padding_mode="zeros", align_corners=False
)
sampling_value_list.append(sampling_value_l_) # 存储当前层的采样值
# 处理注意力权重
attention_weights = attention_weights.transpose(1, 2).reshape(
bs * num_heads, 1, num_queries, num_levels * num_points
)
# 计算最终输出
output = (
(torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights)
.sum(-1)
.view(bs, num_heads * embed_dims, num_queries)
)
return output.transpose(1, 2).contiguous() # 返回最终输出,调整维度顺序
代码注释说明:
函数定义:multi_scale_deformable_attn_pytorch 函数实现了多尺度可变形注意力机制,接收特征图、空间形状、采样位置和注意力权重作为输入。
参数解析:通过解构输入张量的形状,获取批量大小、头数、嵌入维度等信息。
特征图分割:根据空间形状将输入特征图分割成多个层,以便后续处理。
采样位置转换:将采样位置从 [0, 1] 的范围转换到 [-1, 1],以适应 grid_sample 函数的要求。
双线性插值采样:对每个层的特征图进行双线性插值采样,获取对应的采样值。
注意力权重处理:调整注意力权重的形状,以便与采样值进行逐元素相乘。
输出计算:将所有层的采样值与注意力权重相乘并求和,最终得到输出结果,并调整维度顺序。
这个程序文件 utils.py 是一个用于实现多种实用功能的模块,主要用于深度学习模型,特别是与 YOLO(You Only Look Once)相关的任务。该模块包含了一些函数和工具,帮助进行模型的初始化、操作张量等。
首先,文件导入了一些必要的库,包括 copy、math、numpy 和 torch,后者是一个流行的深度学习框架。接着,定义了一个 _get_clones 函数,该函数用于创建一个给定模块的深拷贝列表,这在构建复杂模型时非常有用,能够确保每个模块都是独立的实例。
接下来,bias_init_with_prob 函数用于根据给定的先验概率初始化卷积或全连接层的偏置值。这个函数通过对数几率的转换来计算偏置值,以便在训练时更好地控制模型的输出。
linear_init 函数则用于初始化线性模块的权重和偏置。它使用均匀分布来初始化权重,确保权重的初始值在一个合理的范围内,以促进模型的收敛。
inverse_sigmoid 函数计算张量的反 sigmoid 函数。它首先将输入限制在 [0, 1] 的范围内,然后计算反 sigmoid 值,这在某些模型中可能用于处理概率值。
最后,multi_scale_deformable_attn_pytorch 函数实现了多尺度可变形注意力机制。该函数接受多个输入,包括值张量、空间形状、采样位置和注意力权重。函数内部首先对输入进行维度拆分和重组,然后使用 F.grid_sample 函数进行双线性插值,获取在指定采样位置的值。最后,通过对采样值和注意力权重的加权求和,生成最终的输出。
整体来看,这个模块提供了一些基础的工具和函数,旨在支持深度学习模型的构建和训练,尤其是在处理注意力机制和初始化方面。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 28
28 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)