手把手教你用 Transformers 和 Tokenizers 从头训练新语言模型
本文经AI开发者(ID: okweiwu, 社区地址: https://ai.yanxishe.com)授权转载,禁止二次转载在过去的几周里,我们对 transformers 和 tok...
本文经AI开发者(ID: okweiwu, 社区地址: https://ai.yanxishe.com)
授权转载,禁止二次转载
在过去的几周里,我们对 transformers 和 tokenizers 库进行了一些改进,目的是让从头开始训练新的语言模型变得更加容易。
在本文中,我们将演示如何用世界语训练一个「小」模型(84 M,6 个层,768 个隐藏层,12 个注意力头)——这与 DistilBERT 的层数和注意力头数相同。然后,我们将在词性标记的下游任务上微调模型。
世界语是一种以易学性为目标的结构化语言。我们选择它有几个原因:
-
它是一种资源相对较少的语言(尽管大约有 200 万人使用它),所以这个演示不像训练一个英语模型那样枯燥。
-
它的语法规则性很强(例如所有常用名词都以 -o 结尾,所有形容词都以 -a 结尾),所以即使是在一个小的数据集上,我们也可以得到有趣的结果。
-
最后,语言的总体目标是缩短人与人之间的距离,促进世界和平和国际理解,可以说是与 NLP 社区的目标一致。
PS:你不需要了解世界语就可以理解这篇文章。
我们的模型将被称为…「wait for it… EsperBERTo」。

1. 查找数据集
首先,让我们找到一个世界语文本的语料库。这里我们将使用来自 INRIA 的 OSCAR 语料库(https://traces1.inria.fr/oscar/ )中的世界语部分。
OSCAR 是一个庞大的多语种语料库,它是通过对 Web 上爬取的文本进行语言分类和过滤而获得的。

数据集的世界语部分只有 299M,因此我们将与 Leipzig 语料库集合(https://wortschatz.uni-leipzig.de/en/download )中的世界语子语料库相连接,该语料库由来自新闻、文学和维基百科等不同来源的文本组成。
最终的训练语料库的大小为 3 GB,仍然很小。当然,对于你的模型,你可以获得更多的数据来进行预训练,从而获得更好的结果。
2. 训练标记器
我们选择使用与 RoBERTa 相同的特殊令牌来训练字节级字节对编码标记器(与 GPT-2 相同)。让我们任意选择它的大小,这里设置为 52000。
我们建议训练字节级的 BPE(而不是像 BERT 这样的词条标记器),因为它将从单个字节的字母表开始构建词汇表,所以所有单词都可以分解为标记(不再是 <unk> 标记)。
1#! pip install tokenizers==0.4.2
2from pathlib import Path
3from tokenizers import ByteLevelBPETokenizer
4paths = [str(x) for x in Path("./eo_data/").glob("**/*.txt")]
5
6# Initialize a tokenizer
7tokenizer = ByteLevelBPETokenizer()
8
9# Customize trainingtokenizer.train(files=paths, vocab_size=52_000, min_frequency=2, special_tokens=[
10 "<s>",
11 "<pad>",
12 "</s>",
13 "<unk>",
14 "<mask>",
15])
16
17# Save files to disk
18tokenizer.save(".", "esperberto")这里有一个对输出的捕获,图片稍微进行了加速:
在我们数据集上的训练大约花了 5 分钟。
哇,太快了!⚡️
我们现在有一个 vocab.json,它是按频率排列的最常用标记列表,还有一个 merges.txt 合并列表。
1{
2 "<s>": 0,
3 "<pad>": 1,
4 "</s>": 2,
5 "<unk>": 3,
6 "<mask>": 4,
7 "!": 5,
8 "\"": 6,
9 "#": 7,
10 "$": 8,
11 "%": 9,
12 "&": 10,
13 "'": 11,
14 "(": 12,
15 ")": 13,
16 # ...
17}
18
19# merges.txt
20l a
21Ġ k
22o n
23Ġ la
24t a
25Ġ e
26Ġ d
27Ġ p
28# ...
最棒的是,我们的标记器为世界语进行了优化。与为英语训练的通用标记器相比,更多的本机单词由一个单独的、未加修饰的标记表示。变音符号,即在世界语中使用的重音字符 -ĉ、ĝ、ĥ、ĵ、ŝ 和 ŭ- 是本机编码的。我们还以更有效的方式表示序列。在这个语料库中,编码序列的平均长度比使用预先训练的 GPT-2 标记器时减小了约 30%。
下面是如何在标记器中使用它的方法,包括处理 RoBERTa 特殊标记——当然,你也可以直接从 transformer 中使用它。
1from tokenizers.implementations import ByteLevelBPETokenizer
2from tokenizers.processors import BertProcessing
3
4tokenizer = ByteLevelBPETokenizer(
5 "./models/EsperBERTo-small/vocab.json",
6 "./models/EsperBERTo-small/merges.txt",
7)
8tokenizer._tokenizer.post_processor = BertProcessing(
9 ("</s>", tokenizer.token_to_id("</s>")),
10 ("<s>", tokenizer.token_to_id("<s>")),
11)
12tokenizer.enable_truncation(max_length=512)
13
14print(
15 tokenizer.encode("Mi estas Julien.")
16)
17# Encoding(num_tokens=7, ...)
18# tokens: ['<s>', 'Mi', 'Ġestas', 'ĠJuli', 'en', '.', '</s>']3. 从头开始训练语言模型
我们现在将使用来自 transformer 的 run_language_modeling.py 脚本(https://github.com/huggingface/transformers/blob/master/examples/run_language_modeling.py )(由 run_lm_finetuning.py 重新命名而来,因为它现在更无缝地支持从头开始的训练)来训练我们的语言模型。只需记住从零开始训练,而不是从现有的模型或检查点开始训练。
我们将训练一个类似于 RoBERTa 的模型,这是一个类似于 BERT 的模型,并进行了一些更改(查看文档https://huggingface.co/transformers/model_doc/roberta.html 了解更多细节)。
由于该模型类似于 BERT,我们将对其进行屏蔽语言建模任务的训练,即预测如何填充我们在数据集中随机屏蔽的任意令牌。这由示例脚本处理。
我们只需要做两件事:
-
实现从文本文件加载数据集的简单子类。
根据你的用例,如果所提供的示例(TextDataset 和 LineByLineTextDataset)中的一个有效,你甚至可能不需要编写自己的 Dataset 子类,但是你可能希望根据你的语料库的实际情况添加许多自定义调整。
-
选择并实验不同的超参数集。
这是我们世界语数据集的一个简单版本。
1class EsperantoDataset(Dataset):
2 def __init__(self, evaluate: bool = false):
3 tokenizer = ByteLevelBPETokenizer(
4 "./models/EsperBERTo-small/vocab.json",
5 "./models/EsperBERTo-small/merges.txt",
6 )
7 tokenizer._tokenizer.post_processor = BertProcessing(
8 ("</s>", tokenizer.token_to_id("</s>")),
9 ("<s>", tokenizer.token_to_id("<s>")),
10 )
11 tokenizer.enable_truncation(max_length=512)
12 # or use the RobertaTokenizer from `transformers` directly.
13
14 self.examples = []
15
16 src_files = Path("./data/").glob("*-eval.txt") if evaluate else Path("./data/").glob("*-train.txt")
17 for src_file in src_files:
18 print("?", src_file)
19 lines = src_file.read_text(encoding="utf-8").splitlines()
20 self.examples += [x.ids for x in tokenizer.encode_batch(lines)]
21
22 def __len__(self):
23 return len(self.examples)
24
25 def __getitem__(self, i):
26 # We’ll pad at the batch level.
27 return torch.tensor(self.examples[i])
如果数据集非常大,可以选择动态加载和标记示例,而不是将其作为预处理步骤。
下面是我们传递给脚本的一组特定的超参数和参数:
1 --output_dir ./models/EsperBERTo-small-v1
2 --model_type roberta
3 --mlm
4 --config_name ./models/EsperBERTo-small
5 --tokenizer_name ./models/EsperBERTo-small
6 --do_train
7 --do_eval
8 --learning_rate 1e-4
9 --num_train_epochs 5
10 --save_total_limit 2
11 --save_steps 2000
12 --per_gpu_train_batch_size 16
13 --evaluate_during_training
14 --seed 42
像往常一样,选择最大的批量大小,你可以适合你的 GPU。
我们开始训练吧!
在这里,你可以查看我们的 Tensorboard(https://tensorboard.dev/experiment/8AjtzdgPR1qG6bDIe1eKfw/#scalars )以获取一组特定的超参数:
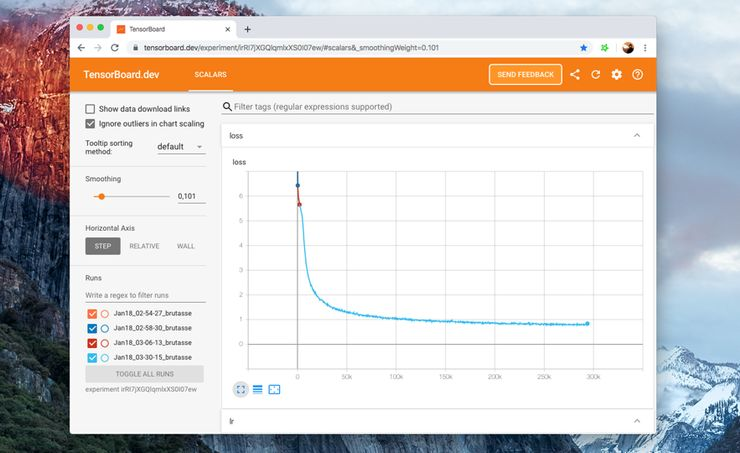
默认情况下,我们的示例脚本会登录到 Tensorboard 格式,在 runs/ 下。然后,要查看你的面板,只需运行 tensorboard dev upload --logdir runs,这将设置 tensorboard.dev,它是一个 Google 托管的版本,允许你与任何人共享 ML 实验。
4. 检查 LM 是否受过训练
除了观察正在下降的训练和评估损失之外,检查我们的语言模型是否学习到了有趣的东西的最简单方法是使用 FillMaskPipeline。
管道是标记器和模型周围的简单包装器,「填充掩码」允许你输入一个包含屏蔽令牌的序列(这里是 <mask>),并返回一个最可能填充序列的列表及其概率。
1from transformers import pipeline
2
3fill_mask = pipeline(
4 "fill-mask",
5 model="./models/EspertBERTo-small",
6 tokenizer="./models/EspertBERTo-small"
7)
8
9# The sun <mask>.
10# =>
11
12result = fill_mask("La suno <mask>.")
13
14# {'score': 0.2526160776615143, 'sequence': '<s> La suno brilis.</s>', 'token': 10820}
15# {'score': 0.0999930202960968, 'sequence': '<s> La suno lumis.</s>', 'token': 23833}
16# {'score': 0.04382849484682083, 'sequence': '<s> La suno brilas.</s>', 'token': 15006}
17# {'score': 0.026011141017079353, 'sequence': '<s> La suno falas.</s>', 'token': 7392}
18# {'score': 0.016859788447618484, 'sequence': '<s> La suno pasis.</s>', 'token': 4552}
OK,使用简单的语法就可以了。让我们尝试一个更有趣的提示:
1fill_mask("Jen la komenco de bela <mask>.")
2
3# This is the beginning of a beautiful <mask>.
4# =>
5
6# {
7# 'score':0.06502299010753632
8# 'sequence':'<s> Jen la komenco de bela vivo.</s>'
9# 'token':1099
10# }
11# {
12# 'score':0.0421181358397007
13# 'sequence':'<s> Jen la komenco de bela vespero.</s>'
14# 'token':5100
15# }
16# {
17# 'score':0.024884626269340515
18# 'sequence':'<s> Jen la komenco de bela laboro.</s>'
19# 'token':1570
20# }
21
22#
23 {
24# 'score':0.02324388362467289
25# 'sequence':'<s> Jen la komenco de bela tago.</s>'
26# 'token':1688
27# }
28# {
29# 'score':0.020378097891807556
30# 'sequence':'<s> Jen la komenco de bela festo.</s>'
31# 'token':4580
32# }
通过更复杂的提示,你可以探究你的语言模型是否捕获了更多的语义知识,甚至某种统计常识推理。
5. 在下游任务上微调 LM
我们现在可以在词性标注的下游任务上微调我们的新的世界语语言模型。
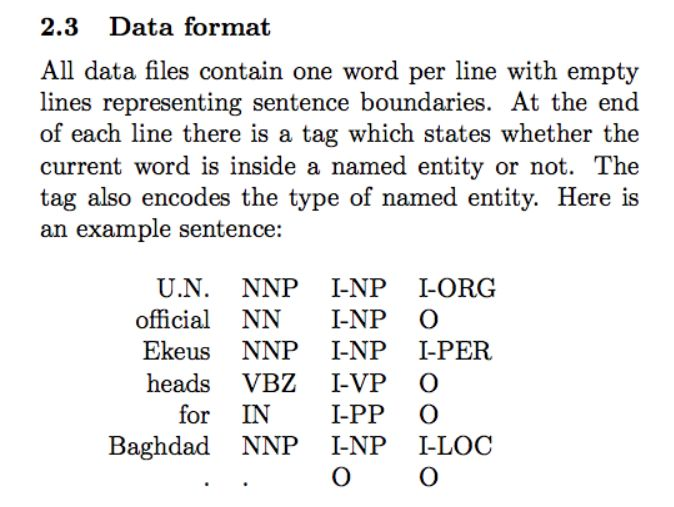
如前所述,世界语是一种规则性很强的语言,词尾通常制约着词性的语法部分。使用 CoNLL-2003 格式的带注释的世界语 POS 标记数据集(见下面的示例),我们可以使用 transformer 中的 run_ner.py(https://github.com/huggingface/transformers/blob/master/examples/run_ner.py )脚本。
POS 标记和 NER 一样是一个令牌分类任务,因此我们可以使用完全相同的脚本。
再次强调,这里是这个微调的托管 Tensorboard。我们使用每 GPU 64 的批处理大小训练 3 个阶段。
训练和评估损失会收敛到很小的残值,因为任务相当简单:语言是规则的,能够端到端地训练。
这次,让我们使用 TokenClassificationPipeline:
1from transformers import TokenClassificationPipeline, pipeline
2
3MODEL_PATH = "./models/EsperBERTo-small-pos/"
4
5nlp = pipeline(
6 "ner",
7 model=MODEL_PATH,
8 tokenizer=MODEL_PATH,
9)
10# or instantiate a TokenClassificationPipeline directly.
11
12nlp("Mi estas viro kej estas tago varma.")
13
14# {'entity': 'PRON', 'score': 0.9979867339134216, 'word': ' Mi'}
15# {'entity': 'VERB', 'score': 0.9683094620704651, 'word': ' estas'}
16# {'entity': 'VERB', 'score': 0.9797462821006775, 'word': ' estas'}
17# {'entity': 'NOUN', 'score': 0.8509314060211182, 'word': ' tago'}
18# {'entity': 'ADJ', 'score': 0.9996201395988464, 'word': ' varma'}
看起来很有效!
6. 分享你的模型
最后,当你有一个好的模型时,请考虑与社区分享:
-
使用 CLI 上载模型:transformers CLI upload
-
编写 README.md 模型卡并将其添加到 model_cards/ 下的存储库中。理想情况下,你的模型卡应包括:
模型描述
训练参数(数据集、预处理、超参数)
评估结果
预期用途和限制
任何其他有用的
➡️ 你的模型在 http://huggingface.co/models 上有一个页面,每个人都可以使用 AutoModel.from_pretrained(“用户名/模型名”)加载它。
* 凡来源非注明“机器学习算法与Python学习原创”的所有作品均为转载稿件,其目的在于促进信息交流,并不代表本公众号赞同其观点或对其内容真实性负责。
推荐阅读


魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐



 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)