深入理解大语言模型的文本数据处理流程
标记化:将文本切分为更小的单位。标记ID映射:将每个标记转换为唯一的整数ID。词嵌入:将标记ID映射为向量表示。特殊标记:引入特殊标记来处理特殊情况。字节对编码(BPE):通过将单词拆分为子单元处理词汇外的单词。数据采样:通过滑动窗口生成输入-输出对。嵌入层:将标记ID转换为嵌入向量供神经网络使用。位置嵌入:为模型注入位置信息,帮助模型理解顺序。通过这些步骤,我们能够将原始文本转化为神经网络能够理
1. 引言:文本数据准备的基本流程
大语言模型(LLM)训练的第一步是文本数据的准备。模型无法直接处理原始的文本数据,因为神经网络处理的是数字数据,而文本是离散的符号。为了让神经网络能够理解和处理文本,我们必须将其转化为数字表示。这个过程包括几个关键步骤:
- 文本标记化:将文本分割成较小的单位,通常是单词或者子词。
- 词嵌入(Word Embeddings):将这些分割出的单位(标记)转换为向量形式。
- 数据采样:通过滑动窗口或其他方法生成训练样本。
- 字节对编码(BPE):一种高级的标记化方法,能够有效处理未登录词(Out-Of-Vocabulary, OOV)。
- 创建标记嵌入:将标记ID映射到向量空间,供模型使用。
这些步骤是整个模型训练的预处理阶段,确保输入数据能被模型正确理解。
2. 词嵌入(Word Embeddings)
LLM不能直接处理原始文本,因为文本是由字符组成的符号,神经网络无法直接理解这些符号。词嵌入是一种将离散的词汇映射到连续向量空间的技术。每个词语(标记)都通过一个嵌入层转化为一个向量,向量的维度通常较高(如300维、768维等),这种表示方法能够捕捉到词汇间的相似性。
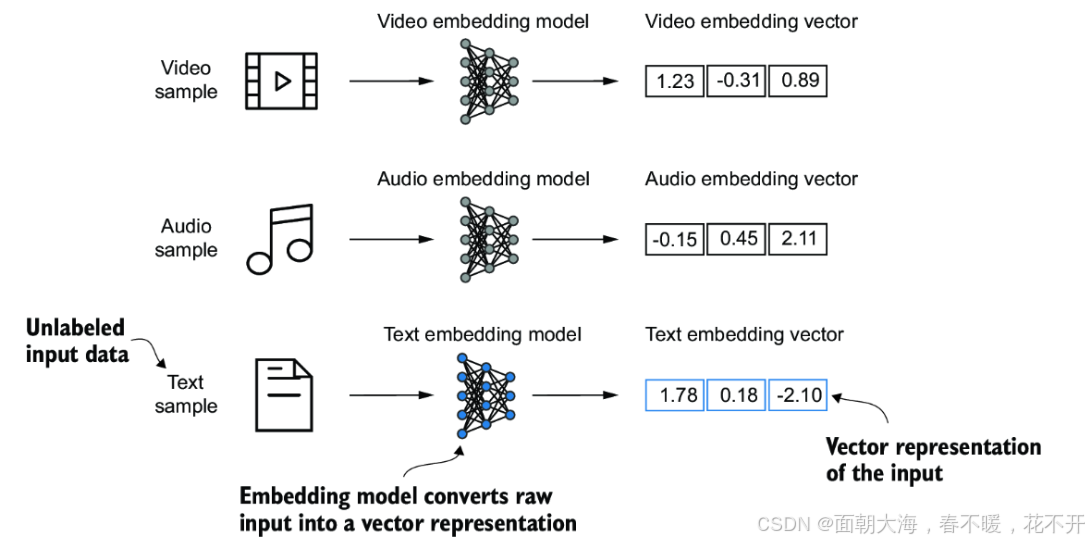
例如,在Word2Vec方法中,如果两个词在上下文中经常一起出现,那么它们的向量表示也会很相似。因此,Word2Vec的核心思想是上下文相似的词具有相似的向量表示。通过训练这样的模型,机器可以理解词语之间的关系和相似度。
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# 假设我们有一个预训练的词嵌入模型
model = Word2Vec.load("word2vec.model")
words = ['dog', 'cat', 'fish', 'bird']
word_vectors = [model[word] for word in words]
# 使用PCA将词向量降维,便于可视化
pca = PCA(n_components=2)
result = pca.fit_transform(word_vectors)
# 可视化词嵌入
plt.scatter(result[:, 0], result[:, 1])
for i, word in enumerate(words):
plt.annotate(word, (result[i, 0], result[i, 1]))
plt.show()
通过这种方式,可以可视化词向量,展示不同词汇在向量空间中的位置。词向量较为相近的词通常代表相似的含义。
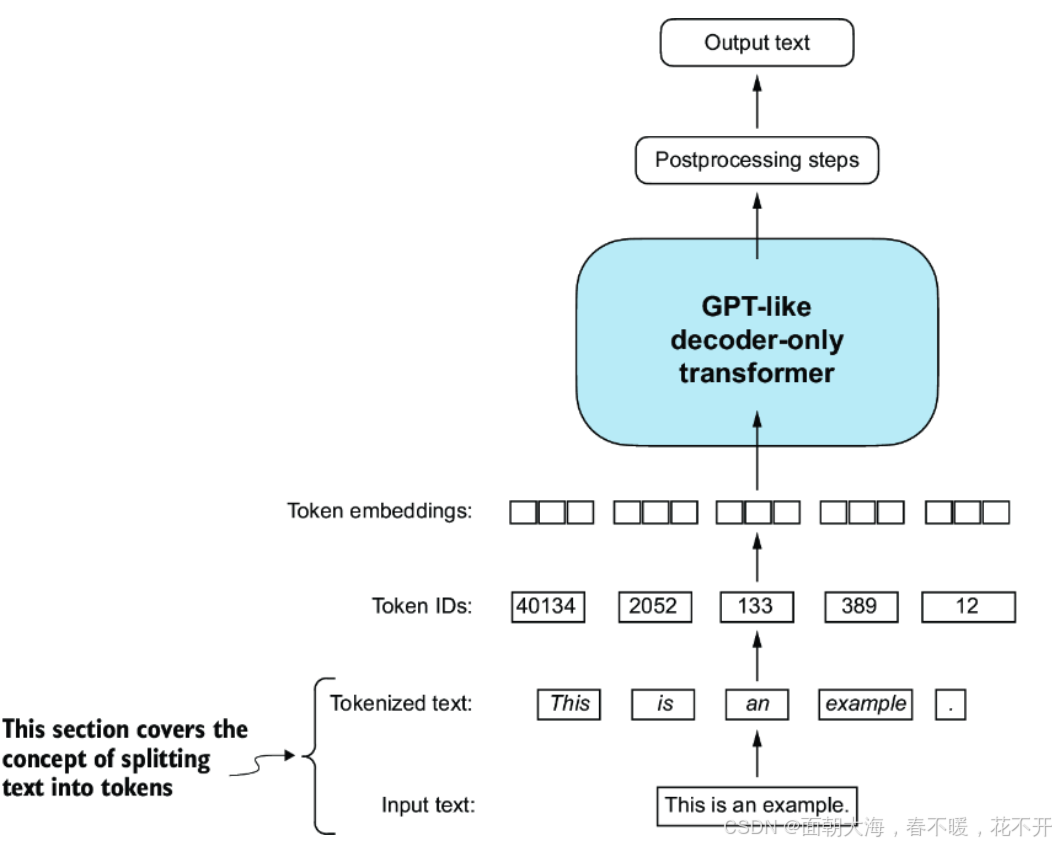
3. 文本标记化
标记化是将原始文本分解为更小的单元(通常是单词或子词)的过程。标记化是处理自然语言的第一步。简单的标记化方法是通过空格、标点符号等字符将文本分割成单个词汇或符号。
标记化的目标是为进一步的处理(如生成词嵌入)提供基础。在标记化过程中,通常会处理一些问题,比如标点符号是否和单词分开、大小写是否统一等。
以下是使用正则表达式(re模块)将文本分割为标记的简单示例:
import re
text = "Hello, world. This is a test."
tokens = re.split(r'([,.?_!"()\']|--|\s)', text)
tokens = [item.strip() for item in tokens if item.strip()]
print(tokens)
此代码首先将文本拆分成单独的标记,如单词、标点符号、空格等。为了简化,可以去除空格或不需要的标记。通过这种方式,我们可以得到一个由标记组成的列表。
在更高级的应用中,**字节对编码(BPE)**作为一种基于频率的标记化方法,可以更高效地处理未登录词(OOV)。它通过合并最频繁的字符对来减少词汇表的大小,从而使得模型能够处理更多的单词组合。
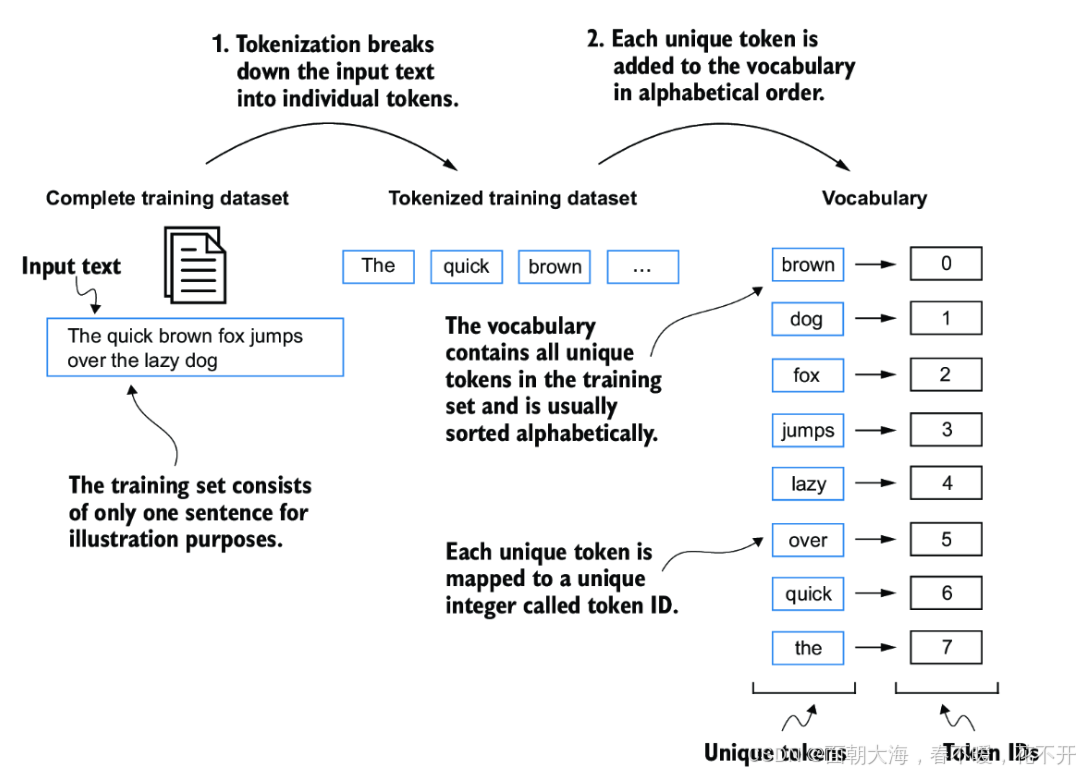
4. 将标记转换为标记ID
标记化的文本并不是直接可以喂给神经网络的。我们需要将每个标记转换为一个唯一的整数ID。这个过程通常通过建立一个**词汇表(Vocabulary)**来实现,词汇表将每个唯一的标记映射到一个整数ID。
all_words = sorted(set(tokens))
vocab = {token: index for index, token in enumerate(all_words)}
print(vocab)
上面的代码将所有标记转换为唯一的整数ID,词汇表中的每个标记都对应一个整数。当我们希望将某个标记(如“hello”)输入到神经网络时,模型会将其转换为词汇表中的对应ID(如0、1、2等)。
这种映射的好处是,它将离散的词汇映射到可以直接输入神经网络的数字表示。
5. 处理特殊上下文标记
在处理文本时,除了普通的单词之外,还需要引入一些特殊标记,这些标记用于处理特殊情况。常见的特殊标记包括:
<|unk|>:表示“未登录词”,用于表示词汇表中没有出现过的词。<|endoftext|>:表示文本的结束,帮助模型知道一段文本的边界。
特殊标记在模型训练时尤为重要,因为它们帮助模型处理异常情况或不同的上下文。
vocab.update({"<|unk|>": len(vocab), "<|endoftext|>": len(vocab)+1})
通过更新词汇表,可以在训练数据中添加这些标记,使得模型能够识别和处理这些特殊情况。
6. 字节对编码(BPE)
字节对编码(BPE)是一种更高级的标记化方法,通过将单词拆解成更小的单元(子词或字符),使得模型能够处理词汇表外的单词。BPE的关键思想是通过合并最常见的字节对(字符组合)来生成子词单元,从而减少词汇表的大小并有效处理OOV单词。
例如,BPE会将词语“unhappiness”拆分为“un”和“happiness”两个子词单元,这样即使模型没有看到“unhappiness”这个词,它也能够通过子词单元来处理。
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
encoded_text = tokenizer.encode("Hello, world!")
print(encoded_text)
这种方法不仅能够处理未登录词,还能够提高模型的训练效率,因为它减少了词汇表的大小,并通过细粒度的分割提高了模型对不同组合的理解能力。
7. 使用滑动窗口进行数据采样
在训练过程中,我们需要将标记化后的文本转换为输入-输出对。一个常用的方法是滑动窗口方法,它通过提取连续的文本片段来创建这些输入-输出对。在这个过程中,窗口的大小(context_size)决定了每个输入片段包含多少个标记。

context_size = 4
x = encoded_text[:context_size]
y = encoded_text[1:context_size+1]
print(f"x: {x}, y: {y}")
在这个例子中,x是输入标记序列,y是模型应该预测的下一个标记。通过这种方法,我们可以将长文本分割成多个训练样本,使得模型能够学习到从一组标记预测下一个标记的能力。
8. 创建标记嵌入
标记ID是整数,但神经网络不能直接处理整数。为了让神经网络能够处理这些标记,我们需要将标记ID转换为向量表示。这通常通过**嵌入层(Embedding Layer)**来实现。
在深度学习模型中,嵌入层是一个查找表,它将标记ID映射到连续的向量空间。这些向量是通过训练不断调整的,能够捕捉到词汇之间的相似性。
import torch
embedding_layer = torch.nn.Embedding(6, 3)
input_ids = torch.tensor([2, 3, 5, 1])
embedded_vectors = embedding_layer(input_ids)
print(embedded_vectors)
通过这种方式,模型将每个标记ID映射到一个向量表示,这些向量可以帮助模型理解标记之间的关系和含义。
9. 编码单词位置
LLM的自注意力机制(如Transformer架构)是位置无关的,即它无法识别输入标记的顺序。因此,我们需要为每个标记添加位置嵌入,以便模型能够理解标记在序列中的顺序。
pos_embedding_layer = torch.nn.Embedding(4, 256)
pos_embeddings = pos_embedding_layer(torch.arange(4))
input_embeddings = embedded_vectors + pos_embeddings
print(input_embeddings)
在这种方式下,每个标记的向量表示都会加上一个位置向量,帮助模型理解标记的顺序。通过这种方式,模型不仅可以理解标记的含义,还能理解它们在序列中的相对位置。
10. 总结
大语言模型(LLM)训练的文本数据准备过程是一个复杂的过程,涉及到多个步骤:
- 标记化:将文本切分为更小的单位。
- 标记ID映射:将每个标记转换为唯一的整数ID。
- 词嵌入:将标记ID映射为向量表示。
- 特殊标记:引入特殊标记来处理特殊情况。
- 字节对编码(BPE):通过将单词拆分为子单元处理词汇外的单词。
- 数据采样:通过滑动窗口生成输入-输出对。
- 嵌入层:将标记ID转换为嵌入向量供神经网络使用。
- 位置嵌入:为模型注入位置信息,帮助模型理解顺序。
通过这些步骤,我们能够将原始文本转化为神经网络能够理解和处理的数字表示。这为后续的模型训练奠定了基础,确保了模型能够学习到有效的语言表示。
这次的解释更加详细地涵盖了每一步的理论和背景,帮助你理解每个概念的意义及其在大语言模型中的作用。如果你有任何问题或需要进一步的讨论,随时告诉我!

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)