如何训练使用——电力设施红外检测数据集 1 输电线路绝缘子红外数据集 2 输电线路过热红外数据集 3 光伏板缺陷红外数据集 4 变压器红外数据集 5 开关柜设备红外检测数据集 绝缘套管红外数据集
如何训练使用——电力设施红外检测数据集 1 输电线路绝缘子红外数据集2 输电线路过热红外数据集 3 光伏板缺陷红外数据集4 变压器红外数据集 5 开关柜设备红外检测数据集绝缘套管红外数据集

步骤一:数据准备与预处理
数据集组织:确保您的数据集按照标准的机器学习项目结构进行组织。通常,这包括将数据分为训练集、验证集和测试集,并且每组数据都应有一个相应的子文件夹。
数据预处理:根据数据集的具体要求进行预处理,比如调整图像大小、亮度调节、旋转等。对于某些数据集,可能还需要进行额外的数据增强操作,以增加模型的鲁棒性。
数据标注:确认所有图像都有正确的标注。如果数据集是以Pascal VOC格式提供的,那么您应该检查XML文件是否正确地描述了每个对象的位置和类别。
步骤二:选择合适的框架和模型
选择框架:选择适合您需求的深度学习框架,如PyTorch、TensorFlow等。
选择模型:基于您的任务类型(图像分类、物体检测等)选择适当的模型。对于图像分类任务,常用的模型有ResNet、Inception、MobileNet等。
步骤三:编写代码
加载数据集:编写代码来加载并处理您的数据集。这通常涉及到创建数据加载器(DataLoader),以便高效地迭代数据。
构建模型:根据所选框架和模型,编写代码实现模型的构建。如果您是初学者,可以从官方文档或GitHub上的开源项目中获取模板代码。
设置训练参数:确定超参数,如学习率、批次大小、优化器等。
训练模型:运行训练循环,监控训练过程中的指标变化,如准确率、损失值等。
验证与测试:在验证集上评估模型性能,必要时调整模型或训练参数。最终,在测试集上评估模型的实际表现。
步骤四:部署与应用
保存模型:训练结束后,保存最佳模型权重,以便后续使用或部署。
部署模型:根据实际应用场景,将模型部署到服务器或其他平台上。
持续监测与更新:在实际应用过程中,持续收集反馈,根据需要更新和优化模型。
注意事项
数据质量:确保使用的数据集具有高质量,避免过度拟合或欠拟合的问题。
计算资源:考虑所需的计算资源,合理分配GPU内存和其他硬件资源。
安全合规:遵守相关的法律法规,特别是在处理敏感数据时。
通过遵循上述步骤,您可以有效地利用电力设施红外检测数据集来进行图像分类等相关深度学习项目的研究和开发工作。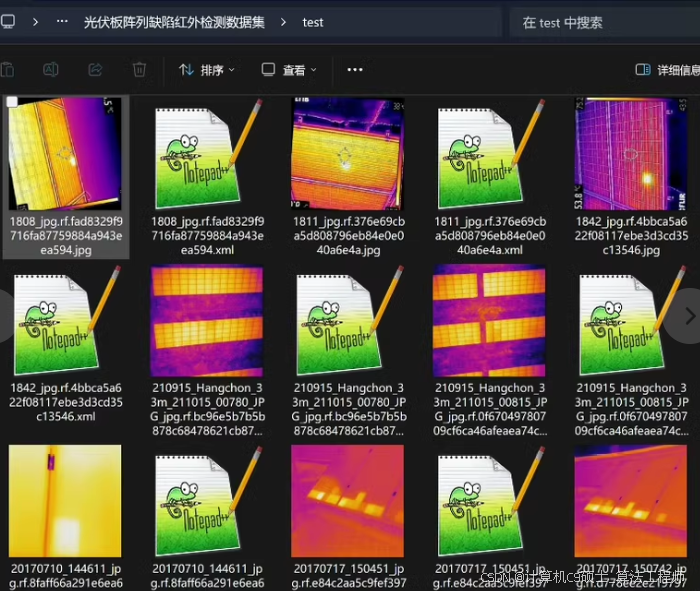
1 输电线路绝缘子红外检测数据集 包含以下2个数据文件: /train:训练集README.txt: 数据说明【数据说明】检测目标以Pascal VOC格式进行标注,未对图像做统一的预处理,大小约为640x512。数据集共包含603+绝缘子红外图像样张,其中train包含603+红外图像样张(带xml标注),可以自行划分训练集和测试集。最后,图像中的目标标签有且仅有1个为Insulators。
2 输电线路过热红外检测数据集 包含以下3个数据文件: /train:训练集 /valid:验证集 README.txt:数据说明 【数据说明】检测目标以Pascal VOC格式进行标注,对每个图像进行以下预处理,统一调整大小为320x240。数据集共包含2393+输电线路过热图像样张,其中train包含2154+红外图像样张(带xml标注),valid包含239+红外图像样张(带xml标注),数据集未做数据增广,也可以自行划分训练集、验证集和测试集。最后,图像中的目标标签有且仅有1个为Overheat。 
3 光伏板缺陷红外检测数据集 包含以下4个数据文件: /train:训练集 /valid:验证集 /test:测试集 README.txt:数据说明 【数据说明】检测目标以Pascal VOC格式进行标注,对每个图像进行以下预处理,统一调整大小为640x640。数据集共包含11599+光伏板红外图像样张,其中train包含11400+红外图像样张(带xml标注),valid包含119+红外图像样张(带xml标注),test包含80+红外图像样张(带xml标注),也可以自行划分训练集、验证集和测试集,数据集的增广方法如下: * Rotation: Between -45° and +45° * Brightness: Between -25% and +25% 最后,目标检测对应的缺陷类别包含2大类,分别为热点和局部热斑。
4 变压器红外检测数据集 包含以下4个数据文件: /train:训练集 /valid:验证集 /test:测试集 README.txt:数据说明 【数据说明】检测目标以Pascal VOC格式进行标注,对每个图像进行以下预处理,统一调整大小为512x512。数据集共包含1972+变压器红外图像样张,其中train包含1705+红外图像样张(带xml标注),valid包含206+红外图像样张(带xml标注),test包含61+红外图像样张(带xml标注),数据集未做数据增广,也可以自行划分训练集、验证集和测试集。 最后,图像中的变压器目标标签共涉及13个类别,分别为Chave_69kV, Chave_H_230kV, Chave_V_230kV, Disjuntor_I_230kV, Disjuntor_I_69kV, Disjuntor_T_230kV, Pararraio_230kV, Pararraio_69kV, TC_230kV, TC_69kV, TP_230kV, TP_69kV和Trafo 
5 开关柜设备红外检测数据集 
包含以下2个数据文件: /train:训练集 /valid:验证集 /test:测试集 README.txt:数据说明 【数据说明】检测目标以Pascal VOC格式进行标注,对每个图像进行以下预处理,统一调整大小为640x640。数据集共包含5527+开关柜设备红外图像样张,其中train包含3882+红外图像样张(带xml标注),valid包含1102+红外图像样张(带xml标注),test包含543+红外图像样张(带xml标注),数据集未做数据增广,也可以自行划分训练集、验证集和测试集。 最后,目标检测对应的设备类别标签共包含9大类,其中主要为MCCB、ACB和Connection,具体释义如下: ACB:空气断路器 CT:电流互感器 Connection:连接器 LA:避雷器 LBS:负荷开关 MCCB:塑壳断路器 PT:电压互感器 VCB:真空断路器 body:柜身
6 变电站绝缘套管红外检测数据集 
包含以下4个数据文件: /train:训练集 /valid:验证集 /test:测试集 README.txt:数据说明 【数据说明】检测目标以Pascal VOC格式进行标注,对每个图像进行以下预处理,统一调整大小为640x640。数据集共包含9900+变压器绝缘套管红外图像样张,其中train包含8560+红外图像样张(带xml标注),valid包含1280+红外图像样张(带xml标注),test包含60+红外图像样张(带xml标注),数据集未做数据增广,也可以自行划分训练集、验证集和测试集。
假设你已经安装好了PyTorch及其依赖项,并且你的数据集已经被整理成了标准的目录结构。
首先,你需要确保你的数据集被组织在一个类似于下面这样的目录结构中:
深色版本
data/
train/
class1/
image1.jpg
image2.jpg
…
class2/
image1.jpg
image2.jpg
…
valid/
class1/
image1.jpg
image2.jpg
…
class2/
image1.jpg
image2.jpg
…
test/
class1/
image1.jpg
image2.jpg
…
class2/
image1.jpg
image2.jpg
…
接下来,我们开始编写代码:
python
深色版本
import os
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from torch.optim import Adam
from torch.nn import CrossEntropyLoss
from torchvision.models import resnet18
设置设备
device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 根据你的数据集调整大小
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
加载数据集
train_data = ImageFolder(root=“path/to/train/data”, transform=transform)
valid_data = ImageFolder(root=“path/to/valid/data”, transform=transform)
test_data = ImageFolder(root=“path/to/test/data”, transform=transform)
创建数据加载器
train_loader = DataLoader(train_data, batch_size=32, shuffle=True)
valid_loader = DataLoader(valid_data, batch_size=32, shuffle=False)
test_loader = DataLoader(test_data, batch_size=32, shuffle=False)
初始化模型
model = resnet18(pretrained=True).to(device)
num_features = model.fc.in_features
model.fc = torch.nn.Linear(num_features, len(train_data.classes)).to(device)
定义损失函数和优化器
criterion = CrossEntropyLoss().to(device)
optimizer = Adam(model.parameters(), lr=0.001)
训练模型
def train_model(model, criterion, optimizer, dataloaders, device, num_epochs=25):
for epoch in range(num_epochs):
print(f’Epoch {epoch}/{num_epochs - 1}‘)
print(’-’ * 10)
for phase in ['train', 'valid']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / len(dataloaders[phase].dataset)
epoch_acc = running_corrects.double() / len(dataloaders[phase].dataset)
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
print()
return model
调用训练函数
dataloaders = {‘train’: train_loader, ‘valid’: valid_loader}
model_trained = train_model(model, criterion, optimizer, dataloaders, device)
测试模型
def test_model(model, dataloader, device):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in dataloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Test Accuracy: {accuracy}%')
test_model(model_trained, test_loader, device)
这段代码展示了如何使用PyTorch和ResNet-18模型进行图像分类的基本流程。请注意,你需要根据自己的数据集调整数据预处理部分以及模型的细节。此外,你还可以添加更多功能,如早停法、学习率衰减等,以提高模型的表现。
为了帮助您更好地理解如何使用这些数据集进行深度学习项目,这里是一个简化的示例,展示如何使用PyTorch框架从头开始建立一个简单的卷积神经网络(CNN)模型,用于图像分类任务。我们将以“光伏板缺陷红外检测数据集”为例,但其他数据集的处理方式类似。
准备环境
确保已安装以下软件包:
Python
PyTorch
torchvision
numpy
matplotlib
你可以使用pip安装它们:
bash
深色版本
pip install torch torchvision numpy matplotlib
导入必要的库
python
深色版本
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
定义数据转换
定义一些变换,例如缩放、归一化等,这对于图像数据非常重要。
python
深色版本
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
加载数据集
假设数据集位于./data目录下,我们可以这样加载它:
python
深色版本
data_dir = ‘./data’
batch_size = 32
train_dataset = datasets.ImageFolder(os.path.join(data_dir, ‘train’), transform=transform)
val_dataset = datasets.ImageFolder(os.path.join(data_dir, ‘valid’), transform=transform)
test_dataset = datasets.ImageFolder(os.path.join(data_dir, ‘test’), transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
构建模型
这是一个非常基础的CNN模型,可以根据需要扩展。
python
深色版本
class Net(nn.Module):
def init(self):
super(Net, self).init()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 2) # 假设只有两种类别
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net()
损失函数和优化器
python
深色版本
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
训练模型
python
深色版本
n_epochs = 10
for epoch in range(n_epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')
验证模型
python
深色版本
correct = 0
total = 0
with torch.no_grad():
for data in val_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(‘Accuracy of the network on the validation set: %d %%’ % (
100 * correct / total))
测试模型
python
深色版本
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(‘Accuracy of the network on the test set: %d %%’ % (
100 * correct / total))
以上代码提供了一个基本的框架,您可以根据具体的项目需求对其进行修改和扩展。注意,实际项目中可能需要更复杂的模型架构、更多的数据预处理步骤以及更精细的调参策略。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 25
25 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)