基于大语言模型 (LLM) 和并发预测模型的自然语言数据库查询系统(Data-copilot)
✨ 基于大语言模型 (LLM) 和并发预测模型的自然语言数据库查询系统✨ 通过自然语言提问,使用大语言模型智能解析数据库结构,对数据进行智能多表结构化查询和统计计算,根据查询结果智能绘制多种图表。通过并发预测模型智能预测最佳并发量,找到生成成功率和 LLM 调用成本的平衡。
data-copilot-v2
✨ 基于大语言模型 (LLM) 和并发预测模型的自然语言数据库查询系统
通过自然语言提问,使用大语言模型智能解析数据库结构,对数据进行智能多表结构化查询和统计计算,根据查询结果智能绘制多种图表。
通过并发预测模型智能预测最佳并发量,找到生成成功率和 LLM 调用成本的平衡。
引入多线程并发执行,同时多次独立提问,降低 LLM 输出不稳定导致整体生成失败的概率,提高系统稳定性和响应速度。
但是盲目增加并发数量会导致过大的 API 资源和性能浪费。
使用 bert 加 regression 的方式,根据问题难度,预测最佳并发数量(Concurrent) 值。
找到生成成功率和 LLM 调用成本的平衡。
Pywebio 交互式前端网页,不必须 openai api,100%纯 Python 代码。
📝相关论文 https://gitee.com/bytesc/data-copilot-v2-controller/blob/master/paper.pdf
本项目相关仓库
本项目包含两个仓库,本仓库为智能体(Agent)服务。
以下仓库是并发预测模型训练和图形界面:
相关项目
- 基于大语言模型 (LLM) 的可解释型自然语言数据库查询系统 https://github.com/bytesc/data-copilot-steps
- 基于大语言模型 (LLM) 的自然语言数据库查询系统 (https://github.com/bytesc/data-copilot
- 基于代码生成和函数调用(function call)的大语言模型(LLM)智能体 https://github.com/bytesc/data-copilot-functions
- 基于代码生成的大语言模型 (LLM) 智能体,实现班级自主管理小程序 https://github.com/bytesc/smart-class-back
🔔 如有项目相关问题,欢迎在本项目提出issue,我一般会在 24 小时内回复。
功能简介
- 1, 使用自然语言提问
- 2, 实现多表结构化查询和统计计算
- 3, 实现智能绘制多种类型的图表和交互式图表制作
- 4, 智能解析数据库结构,使用不同的 mysql 数据库无需额外配置
- 4, 支持多线程并发查询
- 5, 能够处理大语言模型表现不稳定等异常情况
- 6, 支持本地离线部署 (需 GPU)
huggingface格式模型 (例如qwen-7b) - 7, 支持
openai格式和 dashscopeqwen的 api 接口
技术创新点
-
通过异常和断言信息回输进行重试提问,改善大语言模型输出表现不稳定的情况。
-
多线程并发提问,提高响应速度和稳定性。
-
使用数据库的 DataFrame 映射进行操作,避免通过诱导大语言模型进行 sql 注入攻击的风险。
-
引入词嵌入模型和向量数据库,替代单纯的正则表达式,解决大语言模型的模糊输出,到确定的系统代码执行的映射难题。
-
✨ 使用 BERT(Bidirectional Encoder Representation from Transformers) 将提问文本和 prompt 向量化,再使用线性回归, Logistic 回归, nn, Transformer 多种模型进行回归,根据提问文本预测合适的并发数量和重试次数,对比不同模型的效果,
演示截图
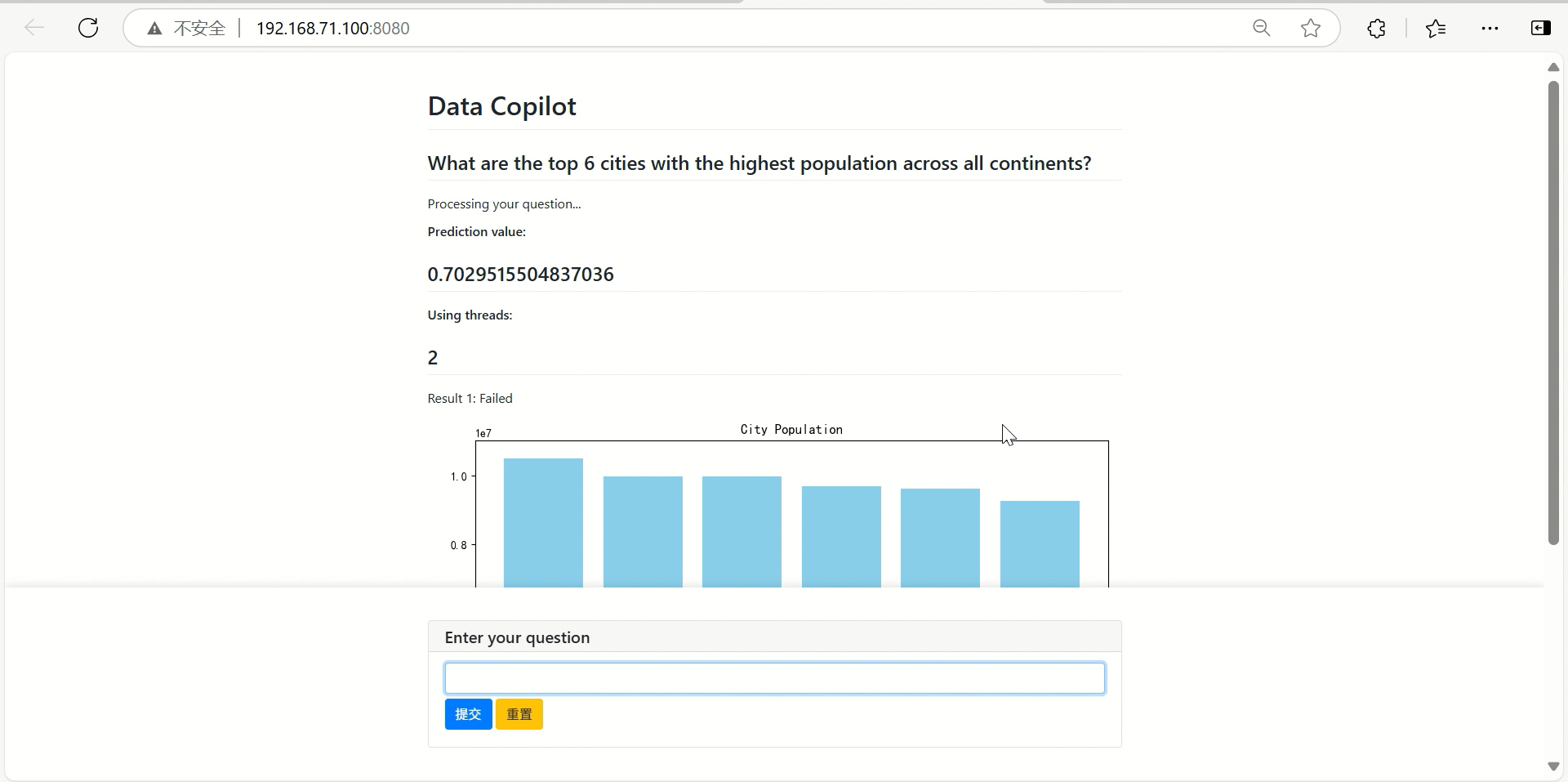
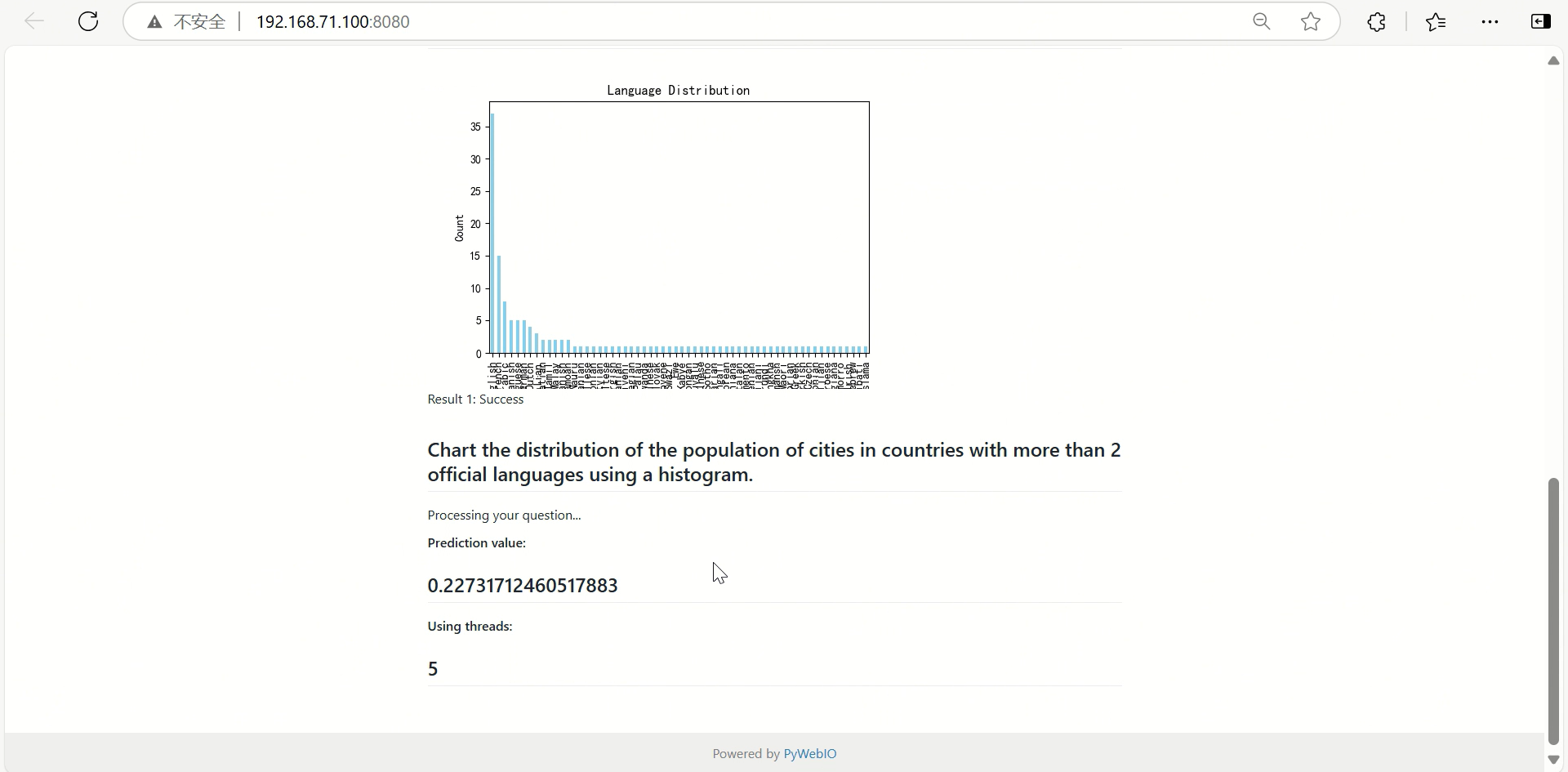
基本技术原理
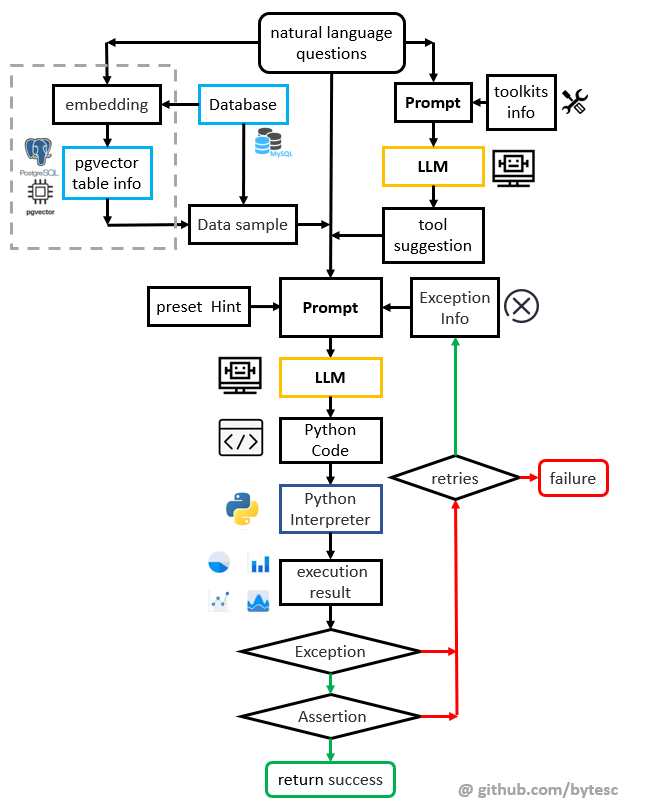
单次生成的基本流程
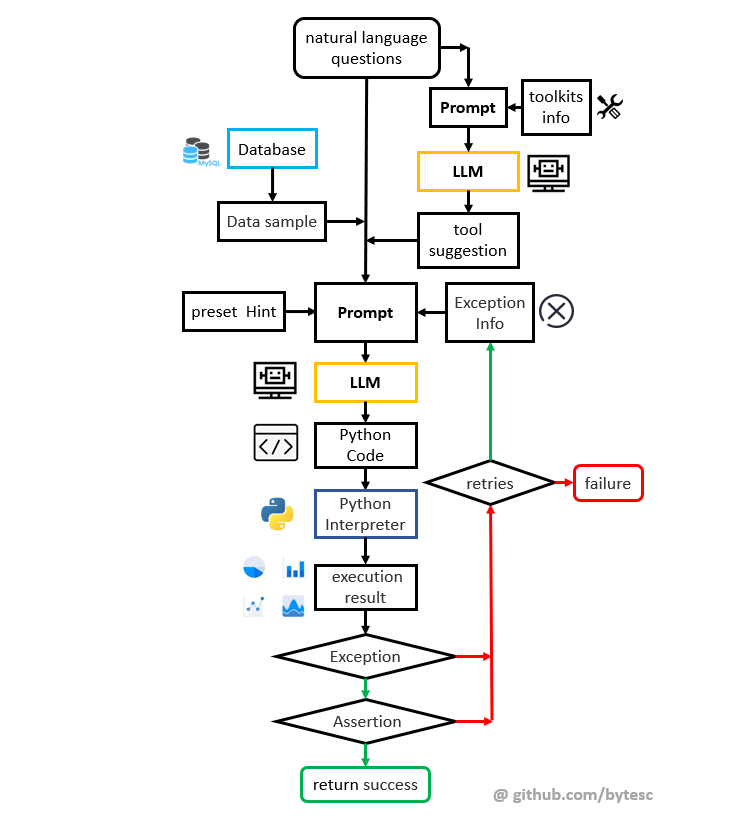
-
自然语言问题输入系统之后,会先和提前预设的工具集描述信息一起合成 prompt 输入 LLM,让 LLM 选择合适的解决问题的工具。
-
从数据库中,获取数据的结构信息(Dataframe 数据摘要)
-
把数据摘要,工具建议信息,输入到 LLM,使其编写 python 代码解决问题。
-
从 LLM 的回答中截取代码,交付 Python 解释器执行。
-
如果代码运行出现异常,把异常信息和问题代码组成新的prompt,回输给 LLM 再次尝试(回到
3)。直到运行成功或超过最大重试次数。 -
如果代码没有运行出现异常,则对程序输出进行断言。如果不是期望的类型,则把断言信息和问题代码组成新的prompt,回输给 LLM 再次尝试(回到
3)。直到断言成功或超过最大重试次数。 -
把成功的代码运行输出(图表)显示到用户界面上,根据输出数据启动交互式绘图界面。
Retries 学习
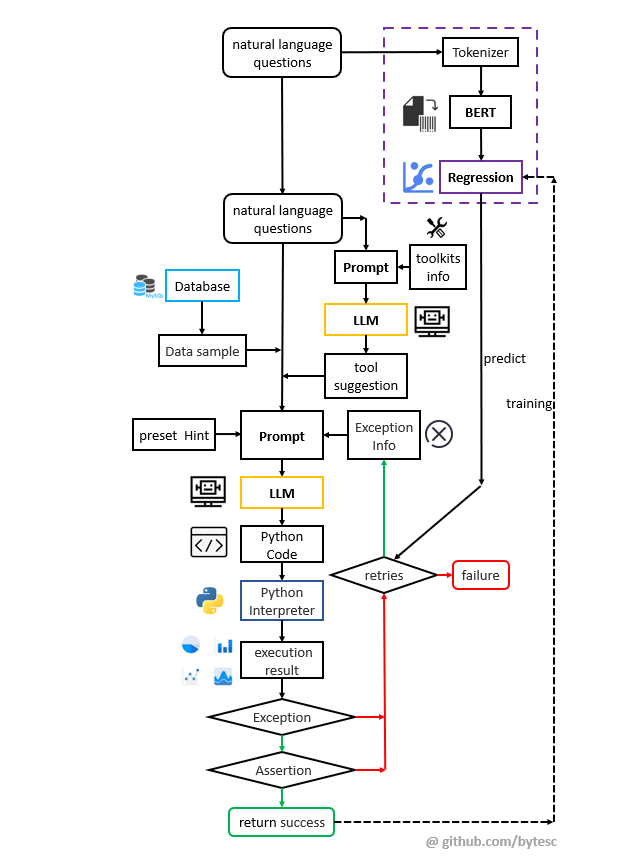
使用 BERT(Bidirectional Encoder Representation from Transformers) 加 regression 的方式,根据问题难度,预测最佳 retries 值。找到生成成功率和重试次数的平衡,提高响应速度。
并发生成控制
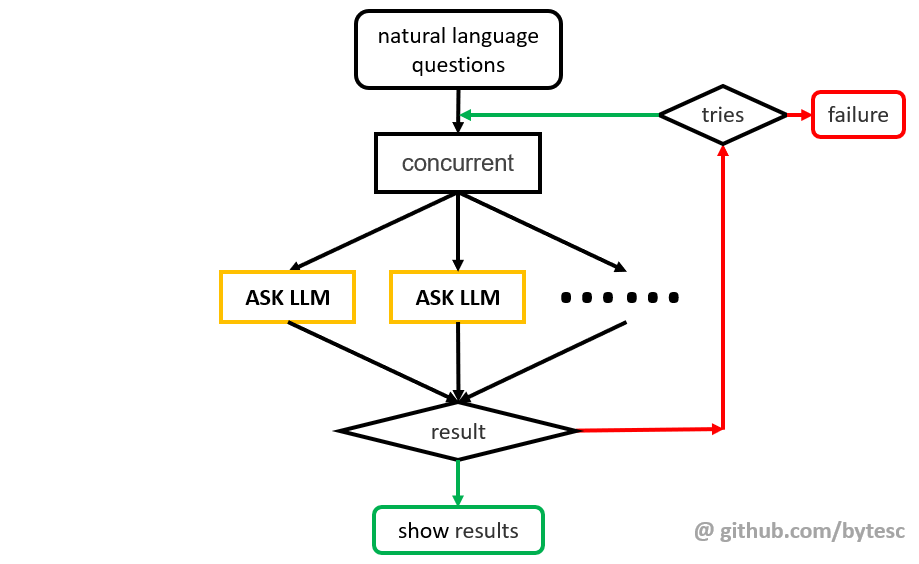
反复的异常和断言回输会导致,prompt 越来越长, LLM 失去注意力,影响生成效果。 LLM 第一次的错误回答也会影响之后的生成。这时从头再来,可能获得更好的结果。
所以引入多线程并发执行,同时多次独立提问,降低 LLM 输出不稳定导致整体生成失败的概率,提高系统稳定性和响应速度。
Concurrent 学习
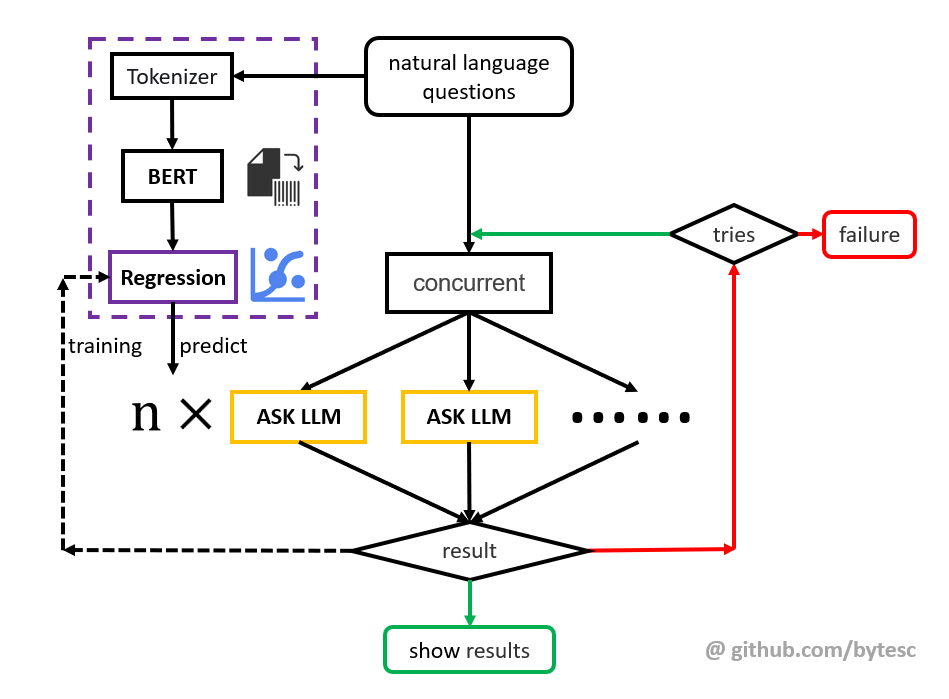
使用 bert 加 regression 的方式,根据问题难度,预测最佳并发数量(Concurrent) 值。找到生成成功率和 LLM 调用成本的平衡,提高响应速度。
如何使用
安装依赖
python 版本 3.9
pip install -r requirement.txt
填写配置信息
./config/config.yaml 是配置信息文件。
数据库配置
连接即可,模型会自动读取数据库结构,无需额外配置
mysql: mysql+pymysql://root:123456@127.0.0.1/data_copilot
# mysql: mysql+pymysql://用户名:密码@地址:端口/数据库名
大语言模型配置
如果使用 dashscope qwen api (推荐)
llm:
model_provider: qwen #qwen #openai
model: qwen1.5-110b-chat
url: ""
# qwen1.5-72b-chat qwen1.5-110b-chat
# qwen-turbo qwen-plus qwen-max qwen-long
# https://dashscope.aliyun.com/
如果使用 openai api (此处填写的是 glm 的 openai 兼容 api)
llm:
model_provider: openai
model: glm-4
url: "https://open.bigmodel.cn/api/paas/v4/"
# glm-4
# https://open.bigmodel.cn
如果需要本地离线部署,相关代码在 ./llm_access/qwen_access.py
获取 apikey
如果从阿里云 dashscope 获取 qwen 大语言模型的 api-key
保存 api-key 到 llm_access/api_key_qwen.txt
如果使用 openai 格式 api 的 api-key
保存 api-key 到 llm_access/api_key_openai.txt
运行
main.py 是项目入口,运行此文件即可启动服务器
python main.py
本仓库为后端 api。可用运行 ask_test.py 进行测试。
python ask_test.py
生成的图表会保存到 .temp.html 或 .temp.png
并发预测模型训练部署,基于 pywebio 的图形界面可见:
未来可能的方向
本项目的难点在于:实现由用户自然语言的模糊提问和大语言模型输出的自然语言回答,到传统非人工智能计算机代码可以处理的确定数据的映射。
本项目目前阶段和其它一些开源实现(例如langchain agent)使用的方法。
都是反复提问以得到大语言模型,以得到尽可能符合预定格式的自然语言回答,然后使用正则表达式匹配数据。
大语言模型虽然有很高的灵活度,可以实现多种复杂的智能数据库查询、统计、绘图功能。
但是其有输入输出规模的致命瓶颈,无法直接处理超长文本或大规模数据集。
因此,在面对大规模数据(例如上百张表)的结构信息时,可能表现不佳。
大语言模型虽然可以一定程度上通过 prompt 控制相对确定的输出格式。
但是其本质仍然是自然语言输出,依然具有大语言模型不稳定的输出特征以及涌现问题。
无法保证返回可以接受的结果,无法保证结果的合理性,准确性。
所以在这一方面的创新,可能是本项目未来可能的发展方向。
向量数据库和词嵌入模型
引入词嵌入模型(例如 text2vec-base-multilingual)和 向量数据库 (例如 PGVector) 可以更好地处理大规模数据。
通过将大规模数据分条转换为向量,将词汇映射到低维向量空间中,从而捕捉词汇之间的语义关系。
并将其存储在向量数据库中,我们可以快速地进行相似性查询、聚类等操作,从而实现对大规模数据的有效处理。
同时,向量数据库中只能匹配到语义上最接近的确定的预存结果,不会出现大语言模型的不稳定情况和涌现问题。
向量数据库和词嵌入模型的加入,可以帮助克服大语言模型表现的不稳定性,以及在处理大规模数据时的限制。
把向量数据库的稳定可靠,和大语言模型的智能灵活结合起来,从而实现对大规模数据的有效而稳定的处理和分析。
相关技术储备代码在 ./pgv/ 文件夹下
相关链接
词嵌入模型:
text2vec-large-chinese huggingface hf-mirror
text2vec-base-multilingual huggingface hf-mirror
向量数据库:
PGVector DockerHub dockerproxy
未完待续…
开源许可证
此翻译版本仅供参考,以 LICENSE 文件中的英文版本为准
MIT 开源许可证:
版权所有 © 2023 bytesc
特此授权,免费向任何获得本软件及相关文档文件(以下简称“软件”)副本的人提供使用、复制、修改、合并、出版、发行、再许可和/或销售软件的权利,但须遵守以下条件:
上述版权声明和本许可声明应包含在所有副本或实质性部分中。
本软件按“原样”提供,不作任何明示或暗示的保证,包括但不限于适销性、特定用途适用性和非侵权性。在任何情况下,作者或版权持有人均不对因使用本软件而产生的任何索赔、损害或其他责任负责,无论是在合同、侵权或其他方面。

魔乐社区(Modelers.cn) 是一个中立、公益的人工智能社区,提供人工智能工具、模型、数据的托管、展示与应用协同服务,为人工智能开发及爱好者搭建开放的学习交流平台。社区通过理事会方式运作,由全产业链共同建设、共同运营、共同享有,推动国产AI生态繁荣发展。
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)